[논문리뷰] Revisiting Image Pyramid Structure for High Resolution Salient Object Detection (InSPyReNet)
ACCV 2022. [Paper] [Github]
Taehun Kim, Kunhee Kim, Joonyeong Lee, Dongmin Cha, Jiho Lee, Daijin Kim
Dept. of CSE, POSTECH
20 Sep 2022
Introduction
저해상도(LR) 이미지에서 Salient Object Detection(SOD)에 대한 많은 성공적인 연구들이 있지만 고해상도(HR) 이미지에 대한 요구가 많다. LR 데이터셋으로 학습된 방법이 입력 크기를 조정하여 HR 이미지에서 괜찮은 결과를 생성한다고 주장할 수 있지만, 예측 이미지의 고주파수 디테일 측면에서 품질은 여전히 낮다. 또한, HR 예측에 대한 이전 연구들은 복잡한 아키텍처를 개발하고 HR 이미지에 힘든 주석을 제안해왔다.
본 논문에서는 고품질 HR 예측을 생성하기 위하여 LR 데이터셋만 사용하는 데 중점을 둔다. 이를 위해 주로 입력 크기에 관계없이 이미지에서 고주파수 디테일을 제공할 수 있는 saliency prediction 구조에 중점을 둔다. 그러나 대부분의 경우 HR 이미지의 effective receptive field (ERF)가 LR 이미지와 다른 문제가 있다. 앞서 언급한 문제를 완화하기 위해 상호 연결되는 두 가지 확실한 솔루션을 제안한다.
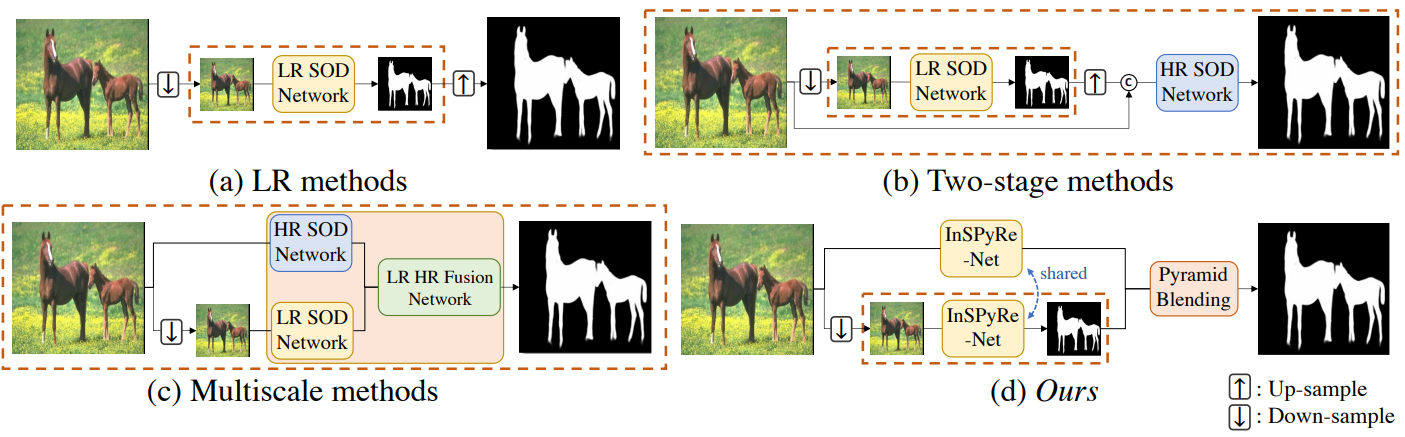
첫 번째는 입력 크기에 관계없이 여러 결과를 병합할 수 있는 네트워크 아키텍처를 설계하는 것이다. 따라서 saliency map의 이미지 피라미드를 예측하는 Inverse Saliency Pyramid Reconstruction Network (InSPyReNet)를 제안한다. 이미지 피라미드는 이미지 블렌딩을 위한 간단하면서도 간단한 방법이므로 saliency map의 이미지 피라미드를 직접 생성하도록 InSPyReNet을 설계한다. 이전 연구에서는 이미 이미지 피라미드 예측을 사용했지만 결과가 구조를 엄격하게 따르지 않아 블렌딩에 사용할 수 없었다 (아래 그림 참조). 따라서 HR 예측을 위한 안정적인 이미지 블렌딩을 가능하게 하는 이미지 피라미드 구조를 보장하기 위해 새로운 아키텍처와 새로운 supervision 테크닉을 제안한다.
 (a) Reverse attention, (b) InSPyReNet, (c) ground-truth
(a) Reverse attention, (b) InSPyReNet, (c) ground-truth
둘째, LR 이미지와 HR 이미지의 ERF 불일치 문제를 해결하기 위해 서로 다른 스케일의 saliency map의 2개의 이미지 피라미드를 중첩하는 inference를 위한 피라미드 블렌딩 테크닉을 설계한다. HR SOD 방법에 대한 최근 연구에서는 이러한 문제를 완화하기 위해 HR 이미지를 LR로 크기를 조정하여 동일한 이미지의 두 가지 다른 스케일을 사용하지만 네트워크가 복잡하고 커야 한다. 단순히 HR 이미지를 InSPyReNet에 전달하거나 다른 LR SOD 네트워크를 사용하는 것은 HR 이미지로 학습되지 않았기 때문에 saliency를 예측하지 못한다. 그럼에도 불구하고 HR 예측에서 고품질 디테일을 향상시킬 가능성이 있다. 강력한 saliency 예측과 LR 및 HR 예측의 디테일을 결합하기 위해 saliency map의 두 이미지 피라미드를 혼합한다.
InSPyReNet은 HR 학습과 HR 데이터셋가 필요하지 않지만 HR 벤치마크에서 고품질 결과를 생성한다. HR 및 LR SOD 벤치마크에 대하여 SOTA 성능을 보여주었으며, 학습 리소스, 주석 품질, 아키텍처 엔지니어링 측면에서 이전 HR SOD 방법보다 더 효율적이다.
Methodology
1. Model Architecture
Overall Architecture
Backbone 네트워크에 Res2Net 또는 Swin Transformer를 사용하지만 HR 예측에는 Swin Transformer만 backbone으로 사용한다. UACANet은 backbone feature map의 채널 수를 줄이기 위해 멀티스케일 인코더에 Parallel Axial Attention encoder (PAA-e)를 사용하고, Parallel Axial Attention decoder (PAA-d)를 사용하여 가장 작은 stage (즉, Stage-3)에서 초기 saliency map을 예측한다. Non-local 연산으로 글로벌 컨텍스트를 캡처하고 axial attention 메커니즘 덕분에 효율적이기 때문에 두 모듈을 모두 채택한다.
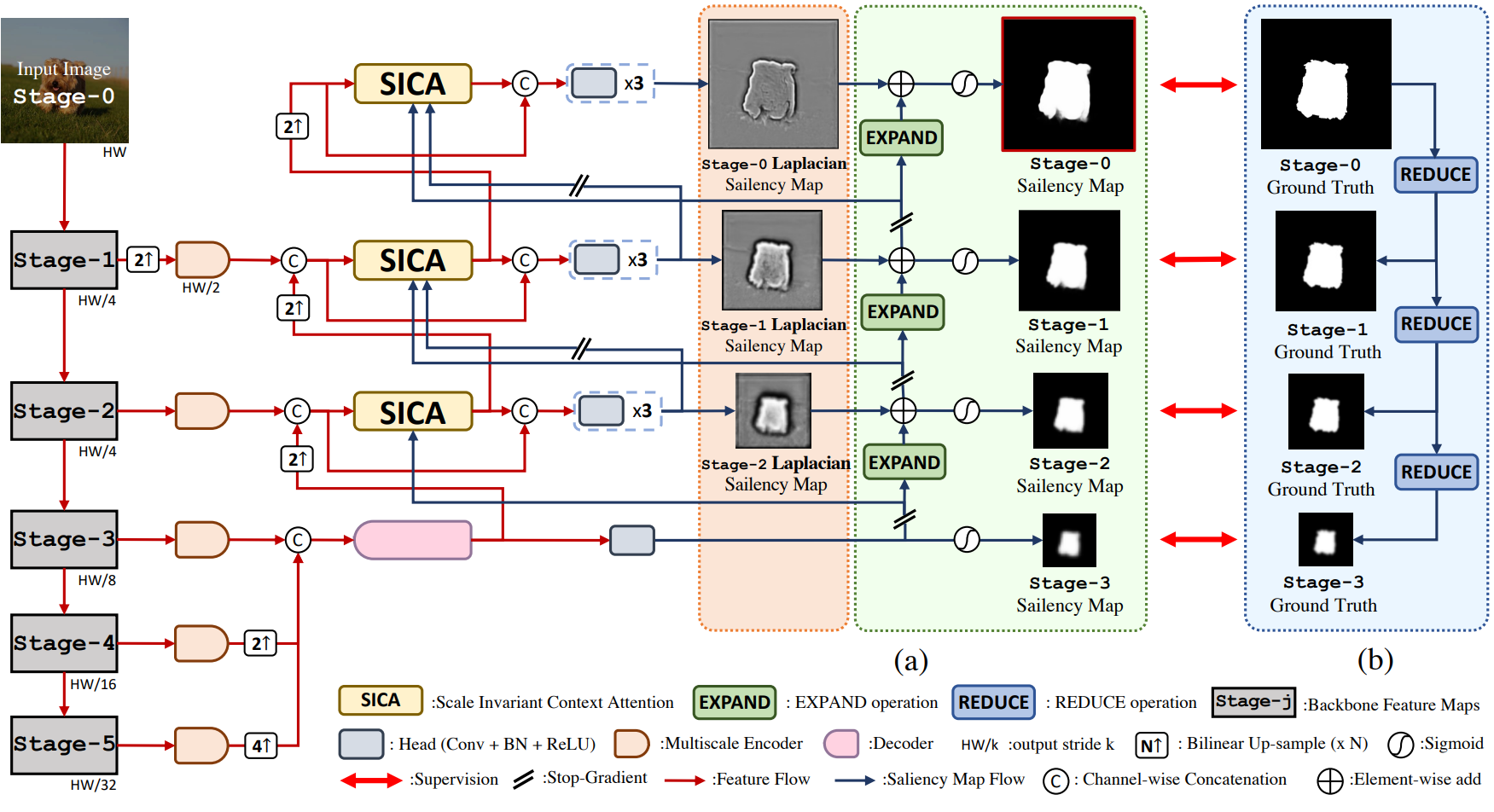
Stage 디자인은 위 그림과 같다. 픽셀 레벨 예측을 위한 이전의 피라미드 기반 방법은 Stage-5에서 시작하여 Stage-2에서 끝났다. 그러나 이전 방법에 대해 재구성해야 할 두 stage가 남아 있어 경계 품질 측면에서 재구성 프로세스가 불완전하다. 따라서 Stage-3에서 시작하는 이미지 피라미드가 충분하며 HR 결과에 대해 가장 낮은 단계인 Stage-0을 만날 때까지 재구성해야 한다. 존재하지 않는 스테이지(Stage-1, Stage-0)의 스케일을 복구하기 위해 적절한 위치에서 bi-linear interpolation을 사용한다.
저자들은 saliency map의 Laplacian 이미지(Laplacian saliency map)를 예측하기 위해 각 stage에 self-attention 기반 디코더인 Scale Invariant Context Attention (SICA)를 배치하였다. 예측된 Laplacian saliency map에서 상위 stage에서 하위 stage로 saliency map을 재구성한다.
Scale Invariant Context Attention
픽셀 단위 예측을 위한 attention 기반 디코더는 공간 차원에 대한 non-local 연산으로 인해 뛰어난 성능을 보여준다. 그러나 입력 이미지의 크기가 학습 설정(ex. 384$\times$384)보다 커지면 적절한 결과를 생성하지 못한다. 이는 입력 이미지의 크기가 충분히 커서 공간 차원에 따라 feature map을 flatten하고 행렬 곱셈을 수행하는 non-local 연산에 대한 학습-inference 불일치가 존재하기 때문이다. 예를 들어 non-local 연산 결과의 크기는 입력 이미지의 공간 차원에 따라 다르다. 또한 non-local 연산의 복잡성은 입력 크기가 증가함에 따라 제곱으로 증가한다.
이를 위해 강력한 Laplacian saliency 예측을 위한 scale invariant context attention 모듈인 SICA를 제안한다.
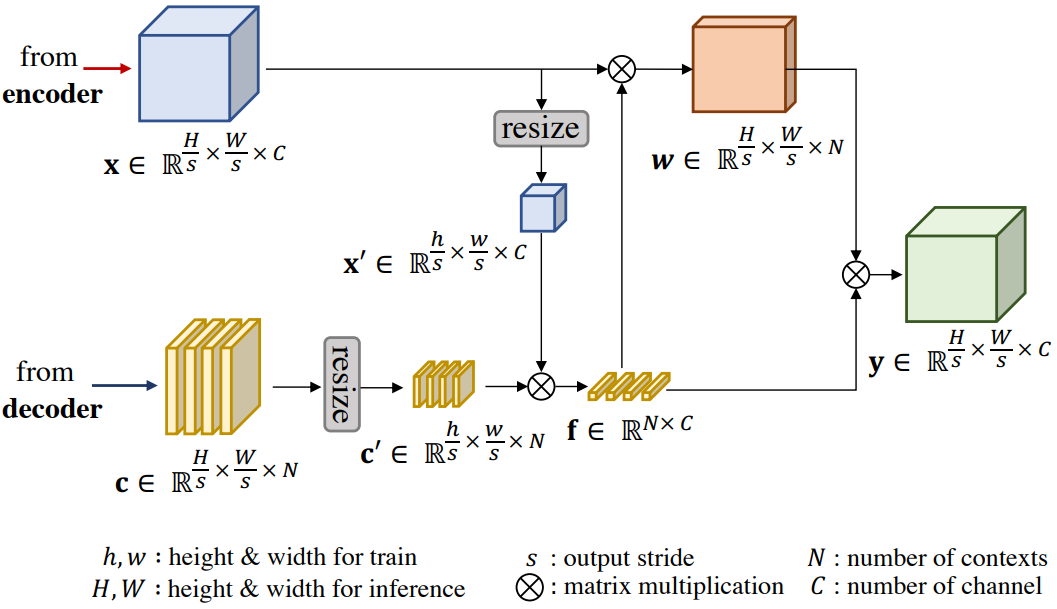
위 그림과 같이 SICA의 전반적인 동작은 OCRNet을 따른다. 개체 영역 표현을 계산하면 학습-inference 불일치가 발생하므로 학습 시의 모양 $(h, w)$에 따라 입력 feature map $x$와 context map $c$의 크기를 조정한다. 학습 단계에서 이미지는 이미 고정된 모양으로 재구성되었으므로 크기를 조정할 필요가 없다. Context map은 OCRNet과 달리 부족한 saliency map에만 접근이 가능하기 때문에 여러 context map을 생성한다. SICA를 사용하면 HR 이미지에 대해 Laplacian saliency map을 보다 정확하게 계산할 수 있으므로 HR 예측에 피라미드 블렌딩을 적용할 수 있다.
Inverse Saliency Pyramid Reconstruction
Laplacian pyramid는 low-pass filtering된 이미지와 원본 이미지의 차이를 스케일별로 저장하는 이미지 압축 기법이다. Laplacian 이미지는 low-pass filtering된 신호의 나머지, 즉 고주파 디테일로 해석할 수 있다. 저자들은 이 기술에서 영감을 받아 경계 디테일에 집중하고 saliency map을 가장 작은 stage에서 원래 크기로 재구성하기 위해 Laplacian pyramid를 구성하도록 네트워크를 수정하였다. 초기 saliency map에 대한 최상위 stage (Stage-3)의 saliency map으로 시작하고 Laplacian saliency map에서 고주파수 디테일을 집계한다.
$j$번째 stage의 saliency map과 Laplacian saliency map을 각각 $S^j$와 $U^j$로 나타내자. $j + 1$번째 stage에서 $j$번째 stage까지 saliency map을 재구성하기 위해 다음과 같은 EXPAND 연산을 적용한다.
\[\begin{equation} S_e^j (x, y) = 4 \sum_{m=-3}^m \sum_{n=-3}^3 g(m, n) \cdot S^{j+1} \bigg( \frac{x-m}{2}, \frac{y-n}{2} \bigg) \end{equation}\]여기서 $(x, y) \in \mathcal{I}^j$는 픽셀 좌표이고 $\mathcal{I}^j$는 Stage-j의 격자 도메인이다. 또한 $g(m, n)$은 커널 크기와 표준 편차가 경험적으로 각각 7과 1로 설정된 가우시안 필터이다. Saliency 디테일을 복원하기 위해 다음과 같이 SICA의 Laplacian saliency map을 추가한다.
\[\begin{equation} S^j = S_e^j + U^j \end{equation}\]가장 낮은 stage인 Stage-0을 얻을 때까지 이 과정을 반복하고 이를 최종 예측으로 사용한다.
2. Supervision Strategy and Loss Functions
여러 step의 사이드 출력이 있는 네트워크를 supervise하는 일반적인 방법은 각 step의 예측에 대해 bi-linear interpolation을 사용하고 ground-truth 정보를 사용하여 loss function을 계산하는 것이다. 그러나 상위 stage에서 예측된 saliency map은 공간 차원이 작기 때문에 특히 개체의 경계 영역에 대해 불일치가 발생할 수 있다. 대신 각 step에 적절한 ground-truth를 제공하도록 선택한다. 이를 위해 ground-truth의 이미지 피라미드를 만든다. 먼저, 다음과 같은 REDUCE 연산을 사용하여 $G^{j-1}$에서 Stage-j에 대한 ground-truth $G^j$를 얻는다.
\[\begin{equation} G^j (x, y) = \sum_{m=-3}^3 \sum_{n=-3}^3 g(m, n) \cdot G^{j-1} (2x + m, 2y + n) \end{equation}\]가장 큰 스케일에서 네트워크의 각 stage에 대한 ground-truth를 얻을 때까지 ground-truth를 분해한다.
Loss function의 경우 픽셀 위치 기반 가중치 전략을 사용하는 binary cross entropy (BCE) loss $\mathcal{L}^{wbce}$를 사용한다. 또한 생성된 Laplacian saliency map이 피라미드 구조를 따르도록 하기 위해 REDUCE 연산을 통해 $S^{j-1}$을 $j$번째 단계인 $\tilde{S}^j$로 분해한다. 그런 다음 다음과 같은 pyramidal consistency loss $\mathcal{L}^{pc}$를 사용하여 $S^j$와 $\tilde{S}^j$ 사이의 유사성을 강화한다.
\[\begin{equation} \mathcal{L}^{pc} (S^j, \tilde{S}^j) = \sum_{(x,y) \in \mathcal{I}^j} \| S^j (x,y) - \tilde{S}^j (x,y) \|_1 \end{equation}\]$\mathcal{L}^{pc}$는 학습 프로세스를 통해 이미지 피라미드의 구조를 따르도록 하위 stage의 saliency map을 정규화한다. 전체 loss function $\mathcal{L}$은 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L} (S, G) = \sum_{j=0}^3 \lambda_j \mathcal{L}^{wbce} (S^j, G^j) + \eta \sum_{j=0}^2 \lambda_j \mathcal{L}^{pc} (S^j, \tilde{S}^j) \end{equation}\]여기서 $\eta$는 $10^{-4}$로 설정되고 $\lambda_j$는 stage 간 loss 크기의 균형을 맞추기 위해 $4^j$로 설정된다.
마지막으로, SICA의 saliency map 입력을 위한 Stop-Gradient를 포함하고 더 높은 stage에서 재구성 프로세스를 포함하여 각 stage의 saliency 출력이 학습하는 동안 각 스케일에 집중하고 inference 시에만 서로에게 영향을 미치도록 한다. 이 전략은 상위 stage에 영향을 미치는 하위 stage의 기울기 흐름을 명시적으로 방지하여 stage별 ground-turth 방식을 권장한다. 따라서 고주파수 디테일에 대한 supervision은 개체의 추상적인 모양만 갖도록 의도된 상위 stage 디코더에 영향을 미치지 않는다. 이 전략은 멀티스케일 방식 측면에서 성능에 영향을 미칠 수 있지만 멀티스케일 인코더와 SICA에 대해 여러 stage의 feature map을 사용하여 이 문제를 보완한다.
3. Pyramid Blending

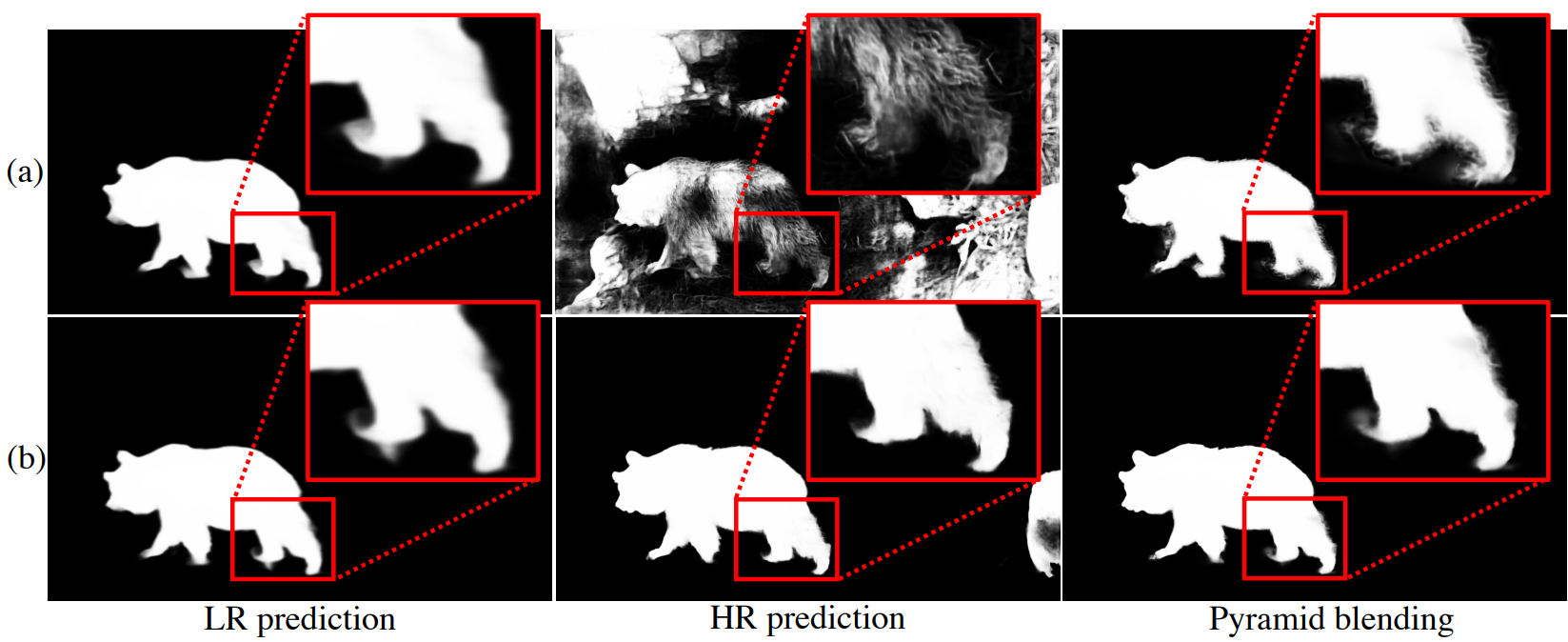
SICA는 다양한 이미지 크기에 대한 saliency 예측을 가능하게 하지만 이미지가 커지면 여전히 ERF 불일치가 존재한다(위 그림 참조). 고맙게도 saliency pyramid 출력에 대한 매우 간단한 애플리케이션 중 하나는 서로 다른 입력에서 여러 saliency pyramid를 조립하는 것이다.
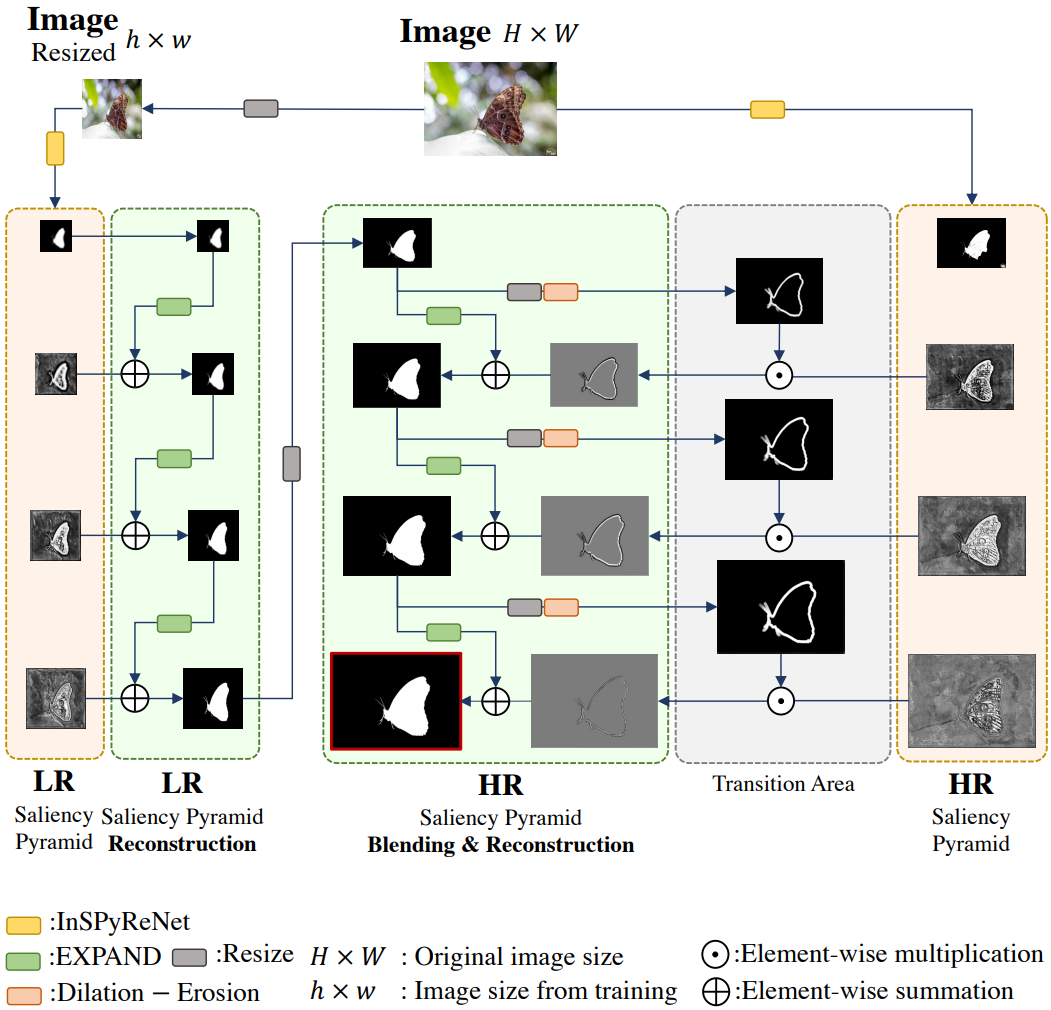
먼저 위 그림과 같이 원본 이미지와 크기 조정된 이미지, 즉 LR 및 HR saliency pyramid에 대해 InSPyReNet으로 saliency pyramid를 생성한다. 그런 다음 HR 피라미드에서 saliency map을 재구성하는 대신 LR 피라미드의 가장 낮은 stage부터 시작한다. 직관적으로 말하면 LR 피라미드는 HR 피라미드로 확장되어 7단계 saliency pyramid를 구성한다.
HR 피라미드 재구성의 경우 이전 stage의 saliency map에 대한 dilation 및 erosion 연산을 계산하고 이를 빼서 Laplacian saliency map의 전환 영역을 얻고 곱한다. 전환 영역은 HR 피라미드에서 원하지 않는 noise를 필터링하는 데 사용된다. 적용해야 하는 경계 디테일이 경계 영역 주변에만 존재해야 하기 때문이다. InSPyReNet을 학습하기 때문에 LR 피라미드에는 필요하지 않으며 saliency pyramid의 결과는 일관성이 보장된다.
Experiments
- 데이터셋: DUTS-TR
- 구현 디테일
- ImageNet-1K로 사전 학습된 Res2Net이나 ImageNet-22K로 사전 학습된 Swin Transformer 사용
- 학습 시 이미지는 384$\times$384 크기로 resize하여 사용
- Augmentation
- 랜덤 scale (0.75 ~ 1.25) 후 원본 크기로 resize
- 랜덤 회전 (-10도 ~ 10도)
- 랜덤 image enhancement (contrast, sharpness, brightness)
- Batch size: 6
- 최대 epochs: 50
- Optimizer: Adam
- Learning rate: initial $10^{-5}$, poly decay, linear warmup 12,000 iteration
1. Ablation Studies
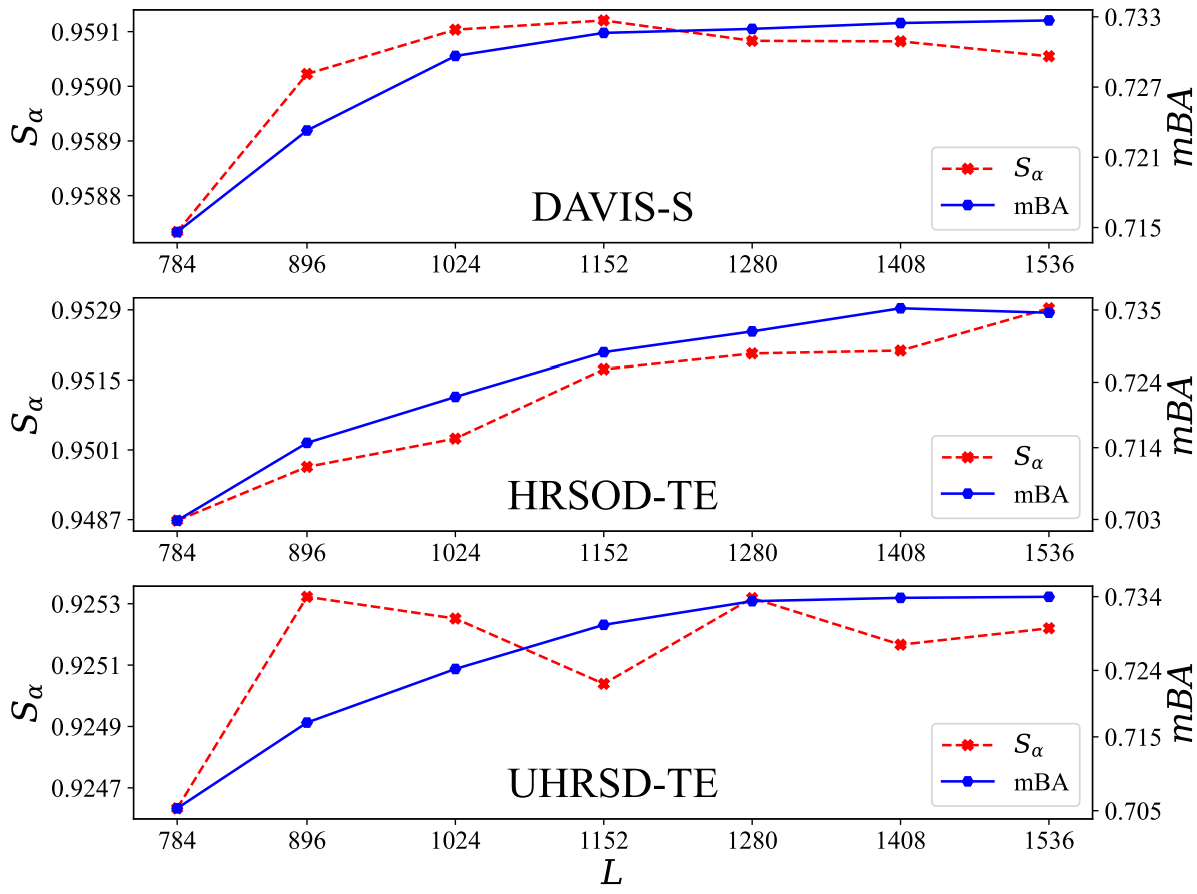
Resizing Factor $L$
다음은 3가지 HR 벤치마크에서 $L$에 따른 성능을 나타낸 그래프이다.
SICA and pyramid blending
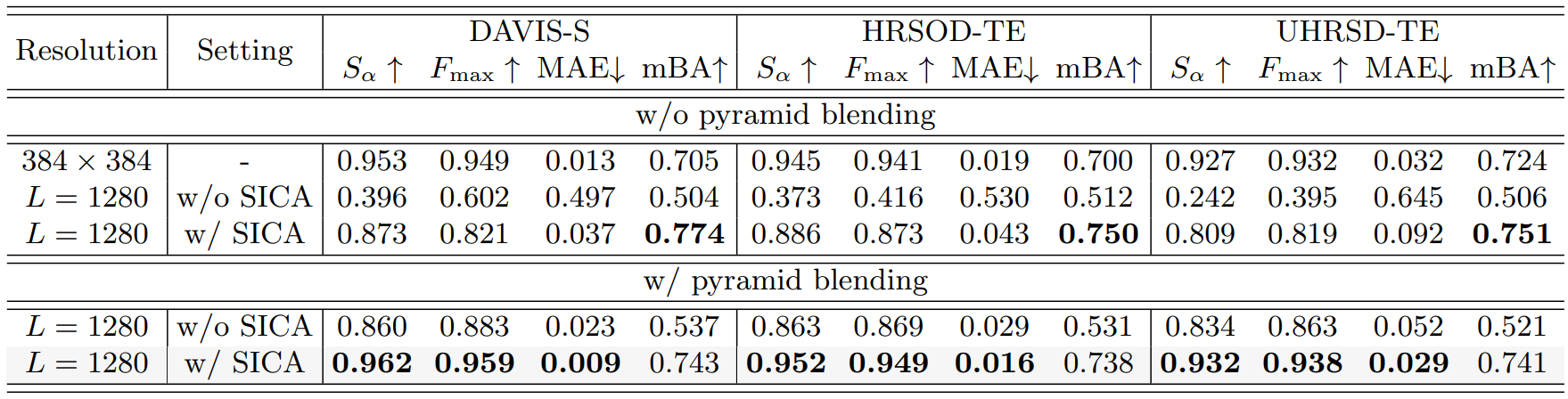
다음은 3가지 HR 벤치마크에서의 SICA와 피라미드 블렌딩에 대한 ablation study 결과이다.
2. Comparison with State-of-the-Art methods
Quantitative Comparison
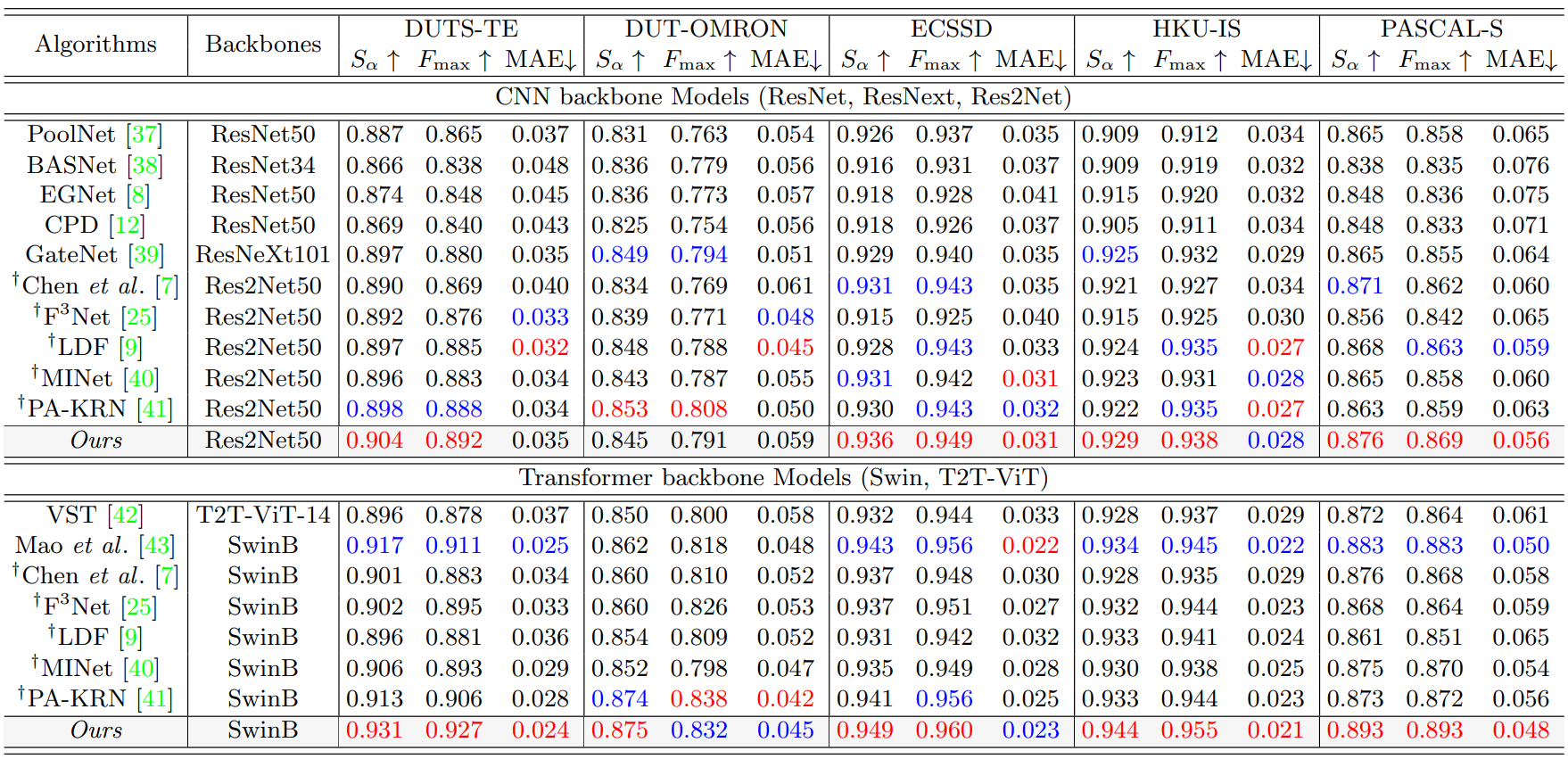
다음은 5가지 LR 벤치마크에서의 정량적 결과이다.
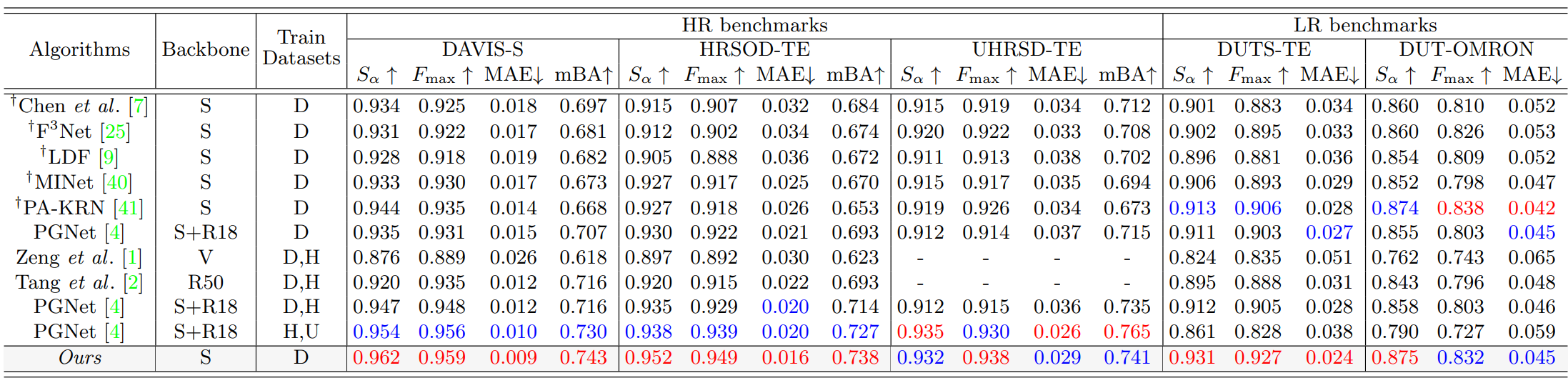
다음은 3가지 HR 벤치마크와 2가지 LR 벤치마크에서의 정량적 결과이다.
Qualitative Comparison
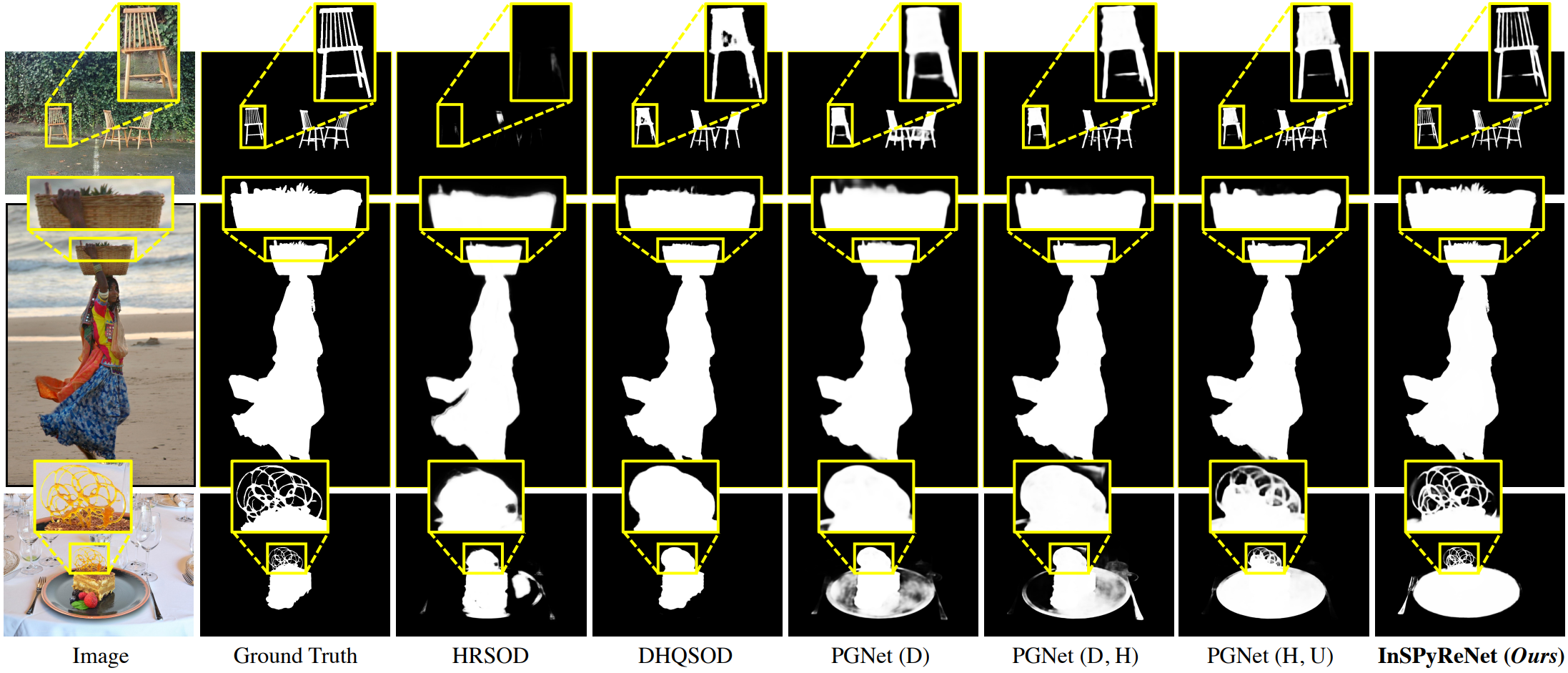
다음은 HRSOD-TE에서 InSPyReNet (SwinB)를 SOTA HR 방법들과 정성적으로 비교한 결과이다.
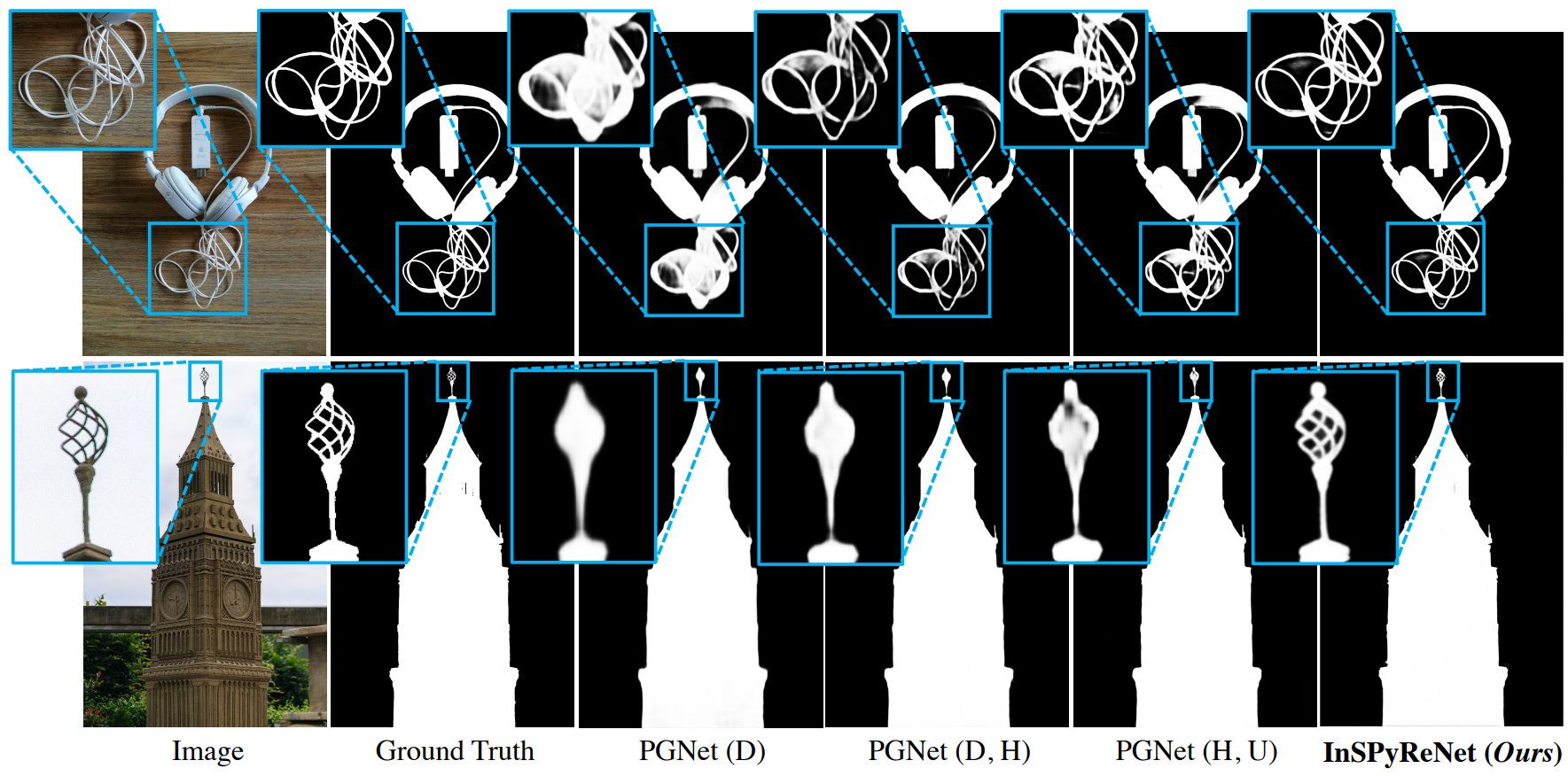
다음은 UHRSD-TE에서 InSPyReNet (SwinB)를 PGNet과 정성적으로 비교한 결과이다.
Discussion
저자들은 다음과 같은 이유로 HR 벤치마크에 Res2Net50을 사용하지 않았다.
(a): Res2Net50 backbone, (b): SwinB backbone
위 그림에서 볼 수 있듯이 Res2Net50 backbone의 HR 예측은 수많은 불필요한 아티팩트가 있는 saliency map을 생성한다. 이는 CNN backbone이 학습 데이터셋에 크게 의존하는 ERF 크기에 취약하기 때문이다. 전통적인 CNN backbone과 달리 Fast Fourier Convolution 또는 ConvNeXt와 같은 위의 문제를 최소화하기 위한 연구들이 많이 있다. 이러한 방법들은 HR 예측을 위해 이러한 아티팩트를 줄이는 데 도움이 되지만 디테일 재구성에는 충분하지 않다. 그러나 SwinB와 같은 Vision Transformer는 ERF가 더 크고 글로벌 종속성에 대한 non-local 연산으로 구성되어 본 논문의 방법에 적합하다. 따라서 HR 예측에서도 일부 false positive를 보여주지만 피라미드 블렌딩을 통해 경계의 디테일을 향상시키면서 쉽게 제거할 수 있다.