[논문리뷰] Image Neural Field Diffusion Models
CVPR 2024. [Paper] [Page]
Yinbo Chen, Oliver Wang, Richard Zhang, Eli Shechtman, Xiaolong Wang, Michael Gharbi
UC San Diego | Google Research | Adobe Research
11 Jun 2024

Introduction
Diffusion model은 GAN의 매력적인 대안이 되었다. Diffusion model은 일반적으로 고정된 차원에서 많은 반복이 필요하므로 픽셀 공간에서 diffusion process를 직접 모델링하는 것은 고해상도 이미지 합성에 비효율적일 수 있다. 보다 효율적인 대안으로 Latent diffusion model (LDM)이 제안되었다. 핵심 아이디어는 오토인코더를 학습하여 다시 디코딩할 수 있는 latent 표현에 이미지를 매핑하고 저차원 latent 표현에 대한 diffusion model을 학습시키는 것이다. 그럼에도 불구하고 LDM의 latent space는 여전히 고정 해상도의 이미지를 나타낸다. 고해상도 이미지를 생성하기 위해 LDM은 일반적으로 먼저 저해상도 이미지를 생성하고 별도의 super-resolution 모델을 사용하여 이를 업샘플링한다.
본 연구에서는 Image Neural Field Diffusion model (INFD)을 제안하였다. INFD는 LDM 프레임워크를 기반으로 하며, 먼저 모든 해상도에서 렌더링될 수 있는 이미지 neural field를 나타내는 latent 표현을 학습한 다음 이 latent 표현에 대한 diffusion model을 학습시킨다. INFD의 주요 과제는 diffusion model이 적용되는 latent space를 학습시키는 것이다.
저자들은 기존 LDM의 오토인코더를 neural field 오토인코더로 변환할 수 있는 간단하고 효과적인 방법을 제안하였다. 저자들은 LIIF를 사용하여 오토인코더를 직접 구현하면 이미지 디테일이 흐려진다는 사실을 발견했으며, latent 표현을 사실적인 고해상도 이미지로 렌더링할 수 있고 이미지 콘텐츠가 다양한 해상도에서 일관되게 렌더링할 수 있는 Convolutional Local Image Function (CLIF)를 제안하였다. INFD의 오토인코더는 LDM을 따라 L1 loss, perceptual loss, GAN loss로 학습되었으며 AnyResGAN과 유사한 멀티스케일 패치로 학습된다.
INFD는 고정된 해상도를 가지는 diffusion model에 비해 몇 가지 주요 이점을 가지고 있다.
- 이미지 크기를 조정하지 않고도 여러 해상도를 가지는 데이터셋에서 구축할 수 있다. 디코더는 모든 해상도와 패치에서 latent 표현을 렌더링할 수 있으며, 전체 이미지를 디코딩하지 않고도 임의의 고해상도의 GT 이미지로 학습시킬 수 있다.
- 다양한 스케일의 고정 해상도 패치에서 GAN loss를 통해 동일한 latent 표현을 학습할 수 있으며, 스케일 전반에 걸쳐 콘텐츠 일관성을 유지할 수 있다. 멀티스케일 학습은 모든 GT 이미지가 고정된 고해상도인 경우에도 고해상도 생성에 도움이 된다.
- 고해상도 생성을 위해 별도의 super-resolution (SR) 모델이 필요하지 않다. Diffusion으로 생성된 저해상도 이미지에는 고해상도 GT가 없기 때문에 별도의 SR 모델은 일반적으로 실제 이미지에 대해 학습되며, 실제 이미지와 생성된 이미지 사이의 도메인 차이로 인해 SR 모델의 성능을 저하시킬 수 있다.
- INFD는 해상도에 구애받지 않는 이미지 prior를 학습한다. 따라서 다양한 스케일로 정의된 일련의 조건들을 사용하여 inverse problem들을 효율적으로 해결하는 데 사용할 수 있다.
Method
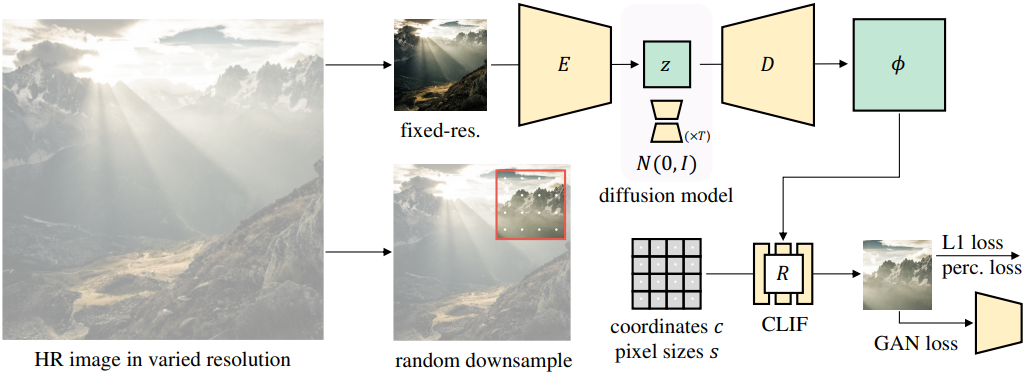
LDM과 유사하게 INFD는 두 단계로 구성된다. 먼저, 이미지를 2D neural field의 latent 표현으로 변환하는 오토인코더를 학습시킨다. 이는 주어진 해상도에서 이미지로 렌더링될 수 있다. 그런 다음, 이 latent space에서 샘플을 생성하기 위해 diffusion model을 학습시킨다.
1. Image Neural Field Autoencoder
첫 번째 단계에서는 학습 데이터셋의 모든 이미지를 이미지 neural field로 변환하기 위해 인코더 $E$, 디코더 $D$, neural field 렌더러 $R$로 구성된 오토인코더를 학습시킨다. 인코더는 RGB 입력 이미지 $I$를 디코더에 의해 디코딩되는 latent code $z = E(I)$에 매핑한다. 최종 이미지를 생성하기 위해 neural field 렌더러가 사용하는 feature $\phi = D(z)$로 변환한다.
Patch-wise decoding
학습 효율성을 위해 전체 이미지를 디코딩하는 것을 피해야 한다. 왜냐하면 GT가 매우 고해상도일 수 있기 때문이다. 따라서 neural field의 좌표 기반 디코딩 속성을 활용하여 일괄 처리가 가능한 혼합 해상도 데이터에서 일정한 크기의 crop으로 학습시킨다. 구체적으로, 무작위로 다운샘플링된 GT에서 고정된 $P \times P$ 해상도 (위 그림의 빨간색 상자)로 무작위 패치 \(p_\textrm{GT}\)를 자른다. \(p_\textrm{GT}\)는 고정된 크기의 패치이기 때문에 전체 GT를 다운샘플링하면 패치 \(p_\textrm{GT}\)가 이미지의 다양한 크기로 영역을 포괄할 수 있다. 이는 로컬한 디테일에서 글로벌 구조에 이르기까지 latent 표현에 대한 다양한 스케일의 supervision을 제공한다. 렌더러 $R$은 latent 표현에서 디코딩된 feature $\phi = D(z)$, 이미지 내에서 패치의 픽셀 중심 좌표 $c$, GT 이미지에 대한 픽셀 크기 $s$를 입력으로 사용하여 출력 패치 $p = R(c, s; \phi)$을 합성한다.
Training objective
L1 loss, perceptual loss \(\mathcal{L}_\textrm{perc}\), GAN loss \(\mathcal{L}_\textrm{GAN}\)의 합을 loss로 사용하여 합성된 패치를 GT와 비교한다. 동시에 discriminator가 $p$와 $p_\textrm{GT}$의 분포를 구별하도록 학습된다.
\[\begin{equation} \mathcal{L}_\textrm{AE} = \| p - p_\textrm{GT} \|_1 + \mathcal{L}_\textrm{perc} (p, p_\textrm{GT}) + \mathcal{L}_\textrm{GAN} (p) \end{equation}\]비교를 용이하게 하기 위해 동일한 인코더와 디코더 아키텍처를 사용하는 LDM의 오토인코더 아키텍처를 따른다. 학습 이미지에는 임의의 해상도가 있으므로 인코더의 입력을 고정 해상도로 리샘플링한다. 이러한 다운샘플링에도 불구하고 여전히 혼합 해상도 레퍼런스들에 대해 학습한다. Vector-quantization (VQ) 레이어는 latent space를 정규화하기 위해 디코더의 첫 번째 레이어 앞에 추가된다.
2. Neural Field Renderer
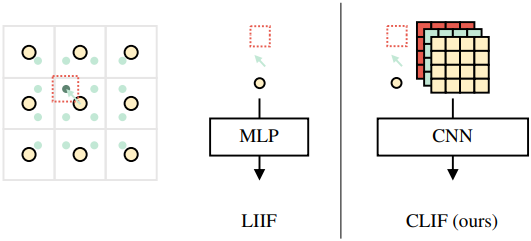
렌더러 $R$은 Convolutional Local Image Function (CLIF)라고 불리는 neural field 좌표 기반 디코더이다. CLIF로 이미지 패치를 디코딩하기 위해 각 쿼리 포인트 $c$ (녹색 점)는 feature map $\phi$ (노란색 점)에서 공간적으로 가장 가까운 feature 벡터를 가져온다. 가장 가까운 feature 벡터를 쿼리 좌표 $c$와 픽셀 크기 $s$와 concatenate한 다음 CNN을 사용하여 쿼리 정보 그리드를 처리하여 RGB 이미지를 출력한다.
직관적으로 concatenate된 feature는 한 점의 field 정보이다. 쿼리 좌표와 픽셀 크기를 변경하면 어떤 해상도에서도 이미지를 디코딩할 수 있다. LIIF는 유사한 정보로 디코딩하지만 포인트별 feature를 사용한다. 이것이 현실적인 고주파 디테일을 생성하는 LIIF의 능력을 제한한다. CLIF는 더 많은 로컬 feature 컨텍스트를 활용하여 이 문제를 해결한다. CLIF 렌더러는 스케일 일관성을 갖도록 학습되었다. 즉, 다양한 해상도에서 디코딩할 때 디테일이 일관된다.
3. Latent diffusion
오토인코더가 학습되면 학습 데이터셋의 모든 이미지 $I$를 latent 표현 $z$에 매핑하고 DDPM 목적 함수를 최적화하여 diffusion model을 학습시킨다.
\[\begin{equation} \mathcal{L}_\textrm{DM} = \mathbb{E}_{z \sim E(I), t, \epsilon} [\| \epsilon_\theta (\sqrt{\vphantom{1} \bar{\alpha}_t} z + \sqrt{1 - \bar{\alpha}_t} \epsilon, t) - \epsilon \|^2 ] \end{equation}\]학습 후에는 인코더를 삭제할 수 있다. Diffusion model은 latent 표현 $z$를 생성하며, 이는 $\phi = D(z)$로 디코딩되고 픽셀 좌표에 의해 지정된 해상도로 렌더링된다.
4. Patchwise Image Generation
효율성을 위해 작은 패치로 학습되었음에도 불구하고 INFD는 고해상도 이미지를 생성할 수 있다. 이를 위해 먼저 샘플링된 $z$에서 글로벌 feature map $\phi$를 생성한 다음 해당 좌표에서 렌더러를 쿼리하여 큰 이미지의 하위 타일들을 생성한다. 타일 경계의 불연속성을 피하기 위해 CLIF의 receptive field보다 큰 고정 padding size로 각 타일의 쿼리 영역을 확장한다. 그런 다음 출력 타일을 같은 양만큼 자르고 타일들을 하나로 조립한다. 렌더러는 완전히 convolutional하므로 메모리가 충분하다면 이미지를 한 번에 생성할 수도 있다.
Experiments
- 데이터셋: FFHQ, Mountains
- 구현 디테일
- 인코더 입력 해상도: 256$\times$256
- latent 표현 해상도: 64$\times$64
- CLIF의 receptive field: 8
- $\phi$: 128 채널$\times$256$\times$256
- 패치 크기: $P$ = 256
1. Comparison to LDM
다음은 FFHQ 데이터셋에서 SR 모델을 사용한 LDM과 INFD를 비교한 결과이다.

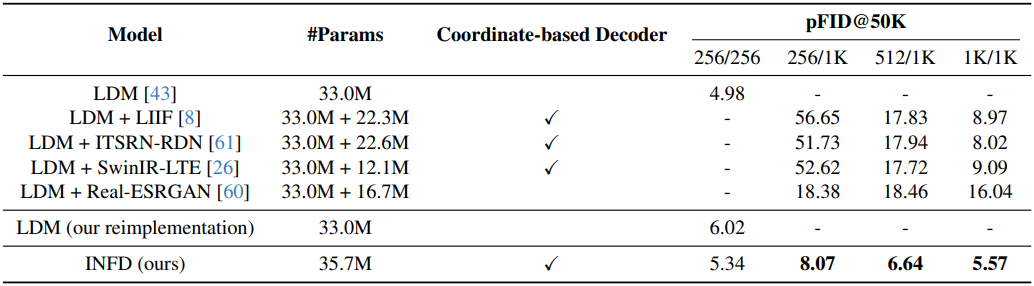
다음은 Mountains 데이터셋에서 SR 모델을 사용한 LDM과 INFD를 비교한 표이다.
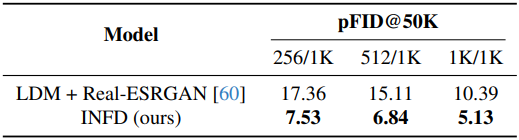
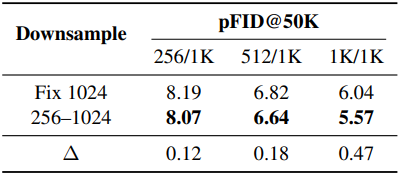
2. Effect of scale-varied training
다음은 랜덤 다운샘플링 전략을 고정 해상도로 학습한 경우와 비교한 표이다.
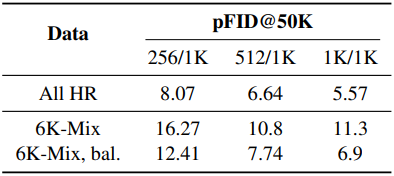
3. Training with limited high-resolution images
다음은 제한된 수의 고해상도 이미지를 사용하여 학습한 결과이다. 대부분의 이미지는 저해상도 256이고, 5천 개의 이미지는 512~1024이고, 1천 개의 이미지 (1.4%)는 1024이다.
4. Inverse problems with conditions at any scale
다음은 멀티스케일 조건들로 inverse problem을 해결한 예시들이다. 해당 영역을 디코딩하고 이를 224$\times$224에서 작동하는 사전 학습된 CLIP 모델에 전달하고 텍스트 프롬프트에 대한 CLIP 유사도를 최대화한다. 이를 통해 추가 학습 없이도 레이아웃을 이미지로 생성할 수 있다.

5. Qualitative results for text to image generation
다음은 Stable Diffusion으로부터 fine-tuning한 INFD와 추가 SR 모델을 사용하는 Stable Diffusion을 비교한 샘플들이다.

6. Scale-consistency of CLIF
다음은 AnyResGAN과 CLIF 렌더러의 스케일 일관성을 비교한 것이다.

7. Comparison to any-resolution GANs
다음은 AnyResGAN과 INFD의 생성 결과를 비교한 것이다.

Limitations
- 현재 방법은 학습 데이터가 스케일에 일관성이 있다고 가정하였다. 즉, 저해상도 이미지는 다운샘플링된 고해상도 이미지와 동일한 분포를 따른다고 가정한다. 이 가정은 잡음이 많고 압축된 저해상도 이미지와 깨끗한 고해상도 이미지가 함께 포함된 데이터셋에 의해 위반된다.
- Text-to-image 합성의 경우, 본 논문의 모델은 고해상도 이미지가 포함된 LAION 데이터셋의 작은 부분집합에 대한 기존 Stable Diffusion 체크포인트에서 fine-tuning되었다. 이로 인해 두 가지 문제가 발생한다.
- 사전 학습 데이터셋에는 잡음이 있는 이미지가 포함되어 있지만 fine-tuning에 사용된 고해상도 데이터셋에는 깨끗한 이미지만 포함되어 있다. 이는 스케일 일관성 가정을 위반한다. 결과적으로, 상세한 고해상도 이미지를 생성하기 위해 “4k”와 같은 추가 프롬프트가 필요하다.
- Fine-tuning에 사용된 데이터셋은 모든 물체의 카테고리를 다루지 않으므로 일부 물체에서 모델의 성능이 떨어질 수 있다.
- 현재 인코더는 고정 해상도의 이미지에 대해 작동하며, 매우 높은 해상도에서 때때로 고주파 영역에서 아티팩트를 생성한다.