[논문리뷰] Inversion-Free Image Editing with Natural Language
CVPR 2024. [Paper] [Page] [Github]
Sihan Xu, Yidong Huang, Jiayi Pan, Ziqiao Ma, Joyce Chai
University of Michigan | UC Berkeley
7 Dec 2023

Introduction
최근 이미지 합성은 diffusion model (DM)에 의해 주도되었다. DM의 성공의 핵심 요소는 다양한 조건을 통합하는 능력이다. DM을 기반으로 하는 Consistency Model (CM)은 noise가 있는 샘플을 동일한 초기값에 대한 궤적을 따라 직접 매핑하여 효율성을 해결하였다.
실제 이미지를 편집하기 위해 텍스트 기반 DM을 사용하는 것에 있어 DDIM inversion을 기반으로 한 inversion 기반 편집이 일반적인 패러다임으로 확립되었다. 주요 방법들은 forward source latent들을 DDIM inversion 궤적에 맞추는 최적화 기반 inversion을 채택하였다. 효율성과 일관성 문제를 해결하기 위해 source branch와 target branch를 개별적으로 분리하고 target branch의 궤적을 반복적으로 보정하는 dual-branch 방법이 도입되었다.
그러나 inversion 기반 편집 방법은 실시간 및 실제 언어 기반 이미지 편집에서 여전히 한계에 직면해 있다.
- 일반적으로 일련의 앵커로 inversion branch를 획득하기 위해 긴 inversion 프로세스에 의존한다.
- 광범위한 최적화나 target branch 조정 방법을 사용하더라도 일관성과 충실성 사이의 균형을 맞추는 것은 여전히 어려운 일이다.
- CM을 사용한 효율적인 일관성 샘플링과 호환되지 않는다.
본 논문은 이 문제들을 해결하기 위해 편집에 inversion 프로세스가 실제로 필요한지부터 시작하였다. 저자들은 초기 샘플을 알고 있을 때 denoising step이 multi-step consistency 샘플링과 동일한 형식을 취하는 특별한 분산 schedule이 존재한다는 것을 보였다. 이것을 Denoising Diffusion Consistency Model (DDCM)이라고 부르며 이를 통해 inversion 프로세스를 제거할 수 있다. 또한 텍스트 기반 편집을 위해 attention 제어 메커니즘을 통합하는 tuning-free 방법인 Unified Attention Control (UAC)를 제시하였다. 이를 결합하여 이미지의 무결성과 inversion을 손상시키지 않고 복잡한 수정을 처리하면서 엄격한 semantic 변경과 그렇지 않은 semantic 변경 모두에 대해 일관되고 충실하게 편집하는 inversion-free editing (InfEdit) 프레임워크를 제시하였다. InfEdit은 다양한 편집 작업에서 강력한 성능을 보여주며 A40 GPU 하나에서 3초 미만의 inference time을 유지한다.
Denoising Diffusion Consistent Models

Diffusion model의 denoising step은 다음과 같다.
분산 schedule을 $\sigma_t = \sqrt{1 - \alpha_{t-1}}$로 두면 두 번째 항이 사라진다.
\[\begin{aligned} z_{t-1} = \;& \sqrt{\alpha_{t-1}} \bigg( \frac{z_t - \sqrt{1 - \alpha_t} \epsilon_\theta (z_t, t)}{\sqrt{\alpha_t}} \bigg) & (\textrm{predicted } z_0)\\ &+ \sqrt{1 - \alpha_{t-1}} \epsilon_t & (\textrm{random noise}) \end{aligned}\]여기서 다음과 같은 $f$를 생각할 수 있다.
\[\begin{equation} f(z_t, t; z_0) = \frac{z_t - \sqrt{1 - \alpha_t \epsilon^\prime (z_t, t; z_0)}}{\sqrt{\alpha_t}} \end{equation}\]이미지 편집의 경우 $z_0$를 알고 있으며 이를 반영하여 $\epsilon_\theta$를 더 일반적인 $\epsilon^\prime$으로 대체한 것이다. $f$를 사용한 denoising step은 다음과 같다.
\[\begin{equation} z_{t-1} = \sqrt{\alpha_{t-1}} f(z_t, t; z_0) + \sqrt{1 - \alpha_{t-1}} \epsilon_t \end{equation}\]이는 Latent Consistency Model (LCM)의 Multistep Latent Consistency Sampling step과 동일하다.
$f$를 consistency function으로 간주할 수 있도록 self-consistency를 만들기 위해, 즉
\[\begin{equation} f(z_t, t; z_0) = z_0 \end{equation}\]이 되도록 방정식을 풀 수 있으며 $\epsilon^\prime$은 parameterization 없이 계산할 수 있다.
\[\begin{equation} \epsilon^\textrm{cons} = \epsilon^\prime (z_t, t; z_0) = \frac{z_t - \sqrt{\alpha_t} z_0}{\sqrt{1 - \alpha_t}} \end{equation}\]따라서 $z_t$가 신경망의 예측 없이 ground-truth $z_0$를 직접 가리키고 $z_{t−1}$이 consistency model처럼 이전 step $z_t$에 의존하지 않는 non-Markovian forward process가 만들어진다. 이것을 Denoising Diffusion Consistency Model (DDCM)이라고 부른다.
1. DDCM for Virtual Inversion
DDCM은 기존 DDIM inversion이나 inversion 기반 이미지 편집 방법들과 달리 명시적인 inversion 연산이 없는 이미지 재구성 모델이다. 임의의 noise에서 forward process를 시작할 수 있고 multi-step consistency sampling을 지원하므로 최고의 효율성을 달성한다. 또한 $z_{t-1}$은 이전 step $z_t$가 아닌 ground-truth $z_0$에만 의존하므로 원본 이미지와 재구성된 이미지 간의 정확한 일관성을 보장한다. Inversion이 없는 특성으로 인해 이 방법을 Virtual Inversion이라고 한다. Algorithm 1에 설명된 대로 parameterization 없이 프로세스 전반에 걸쳐 $z = z_0$이 보장된다.

2. DDCM for Inversion-Free Image Editing
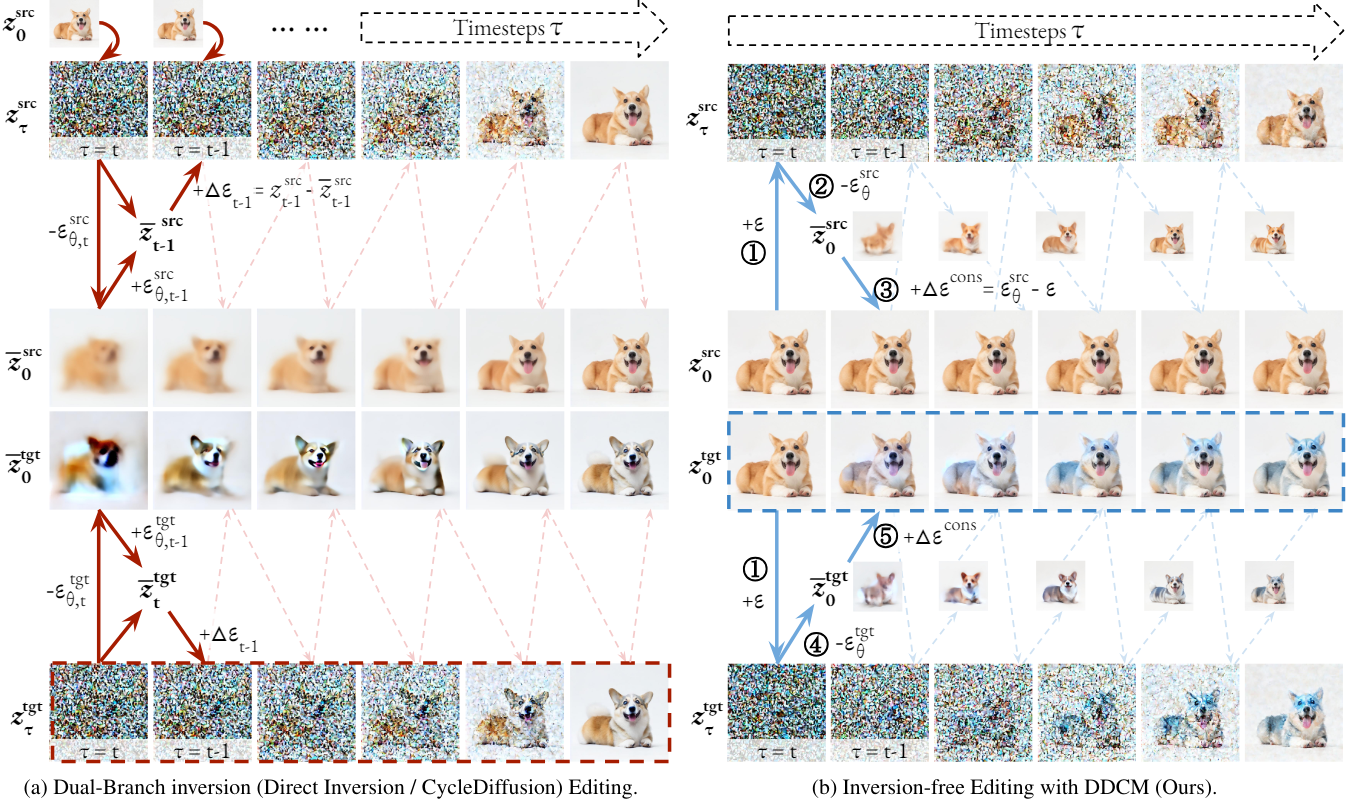
기존의 dual-branch inversion 방법은 $t$에서 source branch와 inversion branch 사이의 실제 거리로 $z_t^\textrm{tgt}$를 반복적으로 보정하여 target branch에서 편집을 수행한다. Target branch에서 source branch를 그대로 유지하여 충실한 재구성을 보장하는 반면, 보정된 $z_t^\textrm{tgt}$는 $z_t^\textrm{stc}$로부터 source branch의 일관성을 보장한다. 하지만 이 과정에서 $z_0^\textrm{src}$와 $z_0^\textrm{tgt}$ 사이의 눈에 띄는 차이가 발생한다. 또한 현재의 모든 inversion 기반 방법은 LCM을 사용하는 효율적인 consistency sampling과 호환되지 않는다.
DDCM은 dual-branch 패러다임을 채택한 InfEdit 프레임워크를 도입하여 이러한 제한 사항을 해결하였다. InfEdit 방법의 핵심은 branch를 따라 $z_t^\textrm{tgt}$가 아닌 초기값 $z_0^\textrm{tgt}$을 직접 보정하는 것이다. InfEdit은 랜덤한 terminal noise
\[\begin{equation} z_{\tau_1}^\textrm{src} = z_{\tau_1}^\textrm{tgt} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \end{equation}\]에서 시작한다. Source branch는 명시적인 inversion 없이 DDCM 샘플링 프로세스를 따르며 $\epsilon^\textrm{cons}$와 \(\epsilon_\theta^\textrm{src}\) 사이의 거리 \(\Delta \epsilon^\textrm{cons}\)를 직접 계산한다. Target branch의 경우 먼저 \(\epsilon_\theta^\textrm{tgt}\)를 계산하여 \(\bar{z}_0^\textrm{tgt}\)를 예측한 다음 예측된 target의 초기값을 동일한 \(\Delta \epsilon^\textrm{cons}\)로 보정한다.

InfEdit은 기존 inversion 기반 편집 방법의 여러 한계점들을 해결한다.
- DDCM 샘플링을 사용하면 이전 방법에서 필요했던 inversion branch 앵커를 버리고 상당한 양의 계산을 절약할 수 있다.
- 기존 dual-branch 방법은 시간이 지남에 따라 $z_t^\textrm{tgt}$를 보정하여 샘플링 과정에서 오차가 누적되는 반면 InfEdit는 $z_0^\textrm{tgt}$를 직접 개선하여 오차가 누적되지 않는다.
- InfEdit은 LCM을 사용하는 효율적인 consistency sampling과 호환되므로 몇 step만으로 이미지를 효율적으로 샘플링할 수 있다.
Unifying Attention Control for Language-Guided Editing
언어 기반 편집의 경우 텍스트 조건에 대한 미묘한 이해를 얻고 텍스트와 이미지 사이에서 보다 세밀한 상호 작용을 촉진하는 것이 어렵다. Prompt-to-Prompt (P2P)는 $\epsilon_\theta$에서 텍스트와 이미지 사이의 상호 작용이 발생한다는 사실을 알아차리고 언어 프롬프트와 더 정확하게 일치하는 noise \(\bar{\epsilon}_\theta^\textrm{tgt}\)를 계산하기 위한 일련의 attention 제어 방법을 제안하였다. InfEdit의 맥락에서 attention 제어는 원래 예측된 target noise $\epsilon_\theta^\textrm{tgt}$를 \(\bar{\epsilon}_\theta^\textrm{tgt}\)로 개선한다.
U-Net의 각 기본 block에는 cross-attention 모듈과 self-attention 모듈이 포함되어 있다. 공간적 feature는 query $Q$에 linear projection된다. Cross-attention에서는 텍스트 feature가 key $K$와 value $V$에 linear projection된다. Self-attention에서는 key $K$와 value $V$도 linear projection된 공간적 feature에서 얻는다. Attention 메커니즘은 다음과 같다.
\[\begin{equation} \textrm{Attention} (K, Q, V) = MV = \textrm{softmax} \bigg( \frac{QK^\top}{\sqrt{d}} \bigg) V \end{equation}\]$M_{ij}$는 픽셀 $i$의 $j$번째 토큰 값을 집계하기 위해 가중치를 결정하는 attention map이며, $d$는 $K$와 $Q$의 차원이다.
본 논문에서는 두 가지 유형의 semantic 변화에 대해 Unified Attention Control (UAC) 프로토콜을 도입하였다.
- 시각적 feature나 배경과 같은 rigid semantic change를 cross-attention을 통해 제어
- 객체 추가/제거, 새로운 동작 방식, 객체의 물리적 상태 변화와 같은 non-rigid semantic change를 mutual self-attention을 통해 제어
1. Cross-Attention Control
P2P 논문에서는 cross-attention layer가 초기 step에서도 픽셀의 공간 구조와 프롬프트의 단어 사이의 상호 작용을 포착할 수 있음을 관찰했다. 이를 통해 생성된 이미지의 cross-attention map을 원본 이미지의 cross-attention map으로 대체함으로써 엄격한 semantic 변화를 편집하기 위한 cross-attention을 제어할 수 있다.
글로벌 attention 개선
$z_t$와 source 및 target branch 모두에 대한 프롬프트가 주어지면 레이어들에 대해 평균화된 attention map $M_t$를 계산한다. Source attention map과 target attention map을 각각 $M_t^\textrm{src}$와 $M_t^\textrm{tgt}$라 하자. 공통 디테일을 나타내기 위해 타겟 프롬프트의 $i$번째 단어가 소스 프롬프트의 $j$번째 단어에 해당함을 나타내는 alignment function $A(i) = j$를 도입한다. P2P를 따라 공통 토큰에 $M_t^\textrm{src}$을 주입하여 $M_t^\textrm{tgt}$을 개선한다.
\[\begin{equation} \textrm{Refine} (M_t^\textrm{src}, M_t^\textrm{tgt})_{i,j} = \begin{cases} (M_t^\textrm{tgt})_{i,j} & \quad \textrm{if } A(j) = \textrm{None} \\ (M_t^\textrm{src})_{i,A(j)} & \quad \textrm{otherwise} \\ \end{cases} \end{equation}\]이렇게 하면 요청된 변경 사항이 적용되는 동안 소스 프롬프트의 공통 정보가 target으로 정확하게 전송된다.
로컬 attention 혼합
추가로 blended diffusion 메커니즘을 적용한다. 구체적으로, target 혼합 단어 $w^\textrm{tgt}$와 source 혼합 단어 $w^\textrm{src}$를 사용하며, 각각 semantic을 추가해야 하는 타겟 프롬프트의 단어와 semantic을 보존해야 하는 소스 프롬프트의 단어이다. 시간 $t$에서 latent $z_t^\textrm{tgt}$를 다음과 같이 혼합한다.
\[\begin{aligned} m^\textrm{tgt} &= \textrm{Threshold} [M_t^\textrm{tgt} (w^\textrm{tgt}), a^\textrm{tgt}] \\ m^\textrm{src} &= \textrm{Threshold} [M_t^\textrm{src} (w^\textrm{src}), a^\textrm{src}] \\ z_t^\textrm{tgt} &= (1 - m^\textrm{tgt} + m^\textrm{src}) \odot z_t^\textrm{src} + (m^\textrm{tgt} - m^\textrm{src}) \odot z_t^\textrm{tgt} \end{aligned}\]여기서 $m^\textrm{tgt}$와 $m^\textrm{src}$는 각각 threshold $a^\textrm{tgt}$와 $a^\textrm{src}$를 각 attention mask에 사용하여 얻은 바이너리 마스크이다.
\[\begin{equation} \textrm{Threshold} (M, a)_{i,j} = \begin{cases} 1 & \quad M_{i,j} \ge a \\ 0 & \quad M_{i,j} < a \end{cases} \end{equation}\]Cross-attention 제어 스케줄링
전체 샘플링 과정에 걸쳐 cross-attention 제어를 적용하면 공간적 일관성에 지나치게 집중하게 되어 의도한 변경 사항을 캡처할 수 없게 된다. 따라서 P2P를 따라 $\tau_c$ 이전의 초기 step에서만 cross-attention 제어를 수행한다.
\[\begin{equation} \textrm{CrossEdit}(M_t^\textrm{src}, M_t^\textrm{tgt}, t) = \begin{cases} \textrm{Refine} (M_t^\textrm{src}, M_t^\textrm{tgt}) & \quad t \ge \tau_c \\ M_t^\textrm{tgt} & \quad t < \tau_c \end{cases} \end{equation}\]2. Mutual Self-Attention Control
Cross-attention 제어의 한계 중 하나는 non-rigid 편집이 불가능하다는 것이다. MasaCtrl은 객체의 레이아웃이 self-attention query에서 대략적으로 형성되어 타겟 프롬프트에 따라 non-rigid semantic change를 다룰 수 있음을 관찰했다. 핵심 아이디어는 self-attention의 원래 $Q^\textrm{tgt}$, $K^\textrm{tgt}$, $V^\textrm{tgt}$를 사용하여 초기 step에서 타겟 프롬프트와 구조적 레이아웃을 합성하는 것이다. 그런 다음 $Q^\textrm{tgt}$를 사용하여 $K^\textrm{src}$, $V^\textrm{src}$에서 semantic하게 유사한 콘텐츠를 쿼리한다.
Non-rigid semantic changes 제어
MasaCtrl은 바람직하지 않은 non-rigid change 문제로 어려움을 겪으며, 여러 물체와 복잡한 배경이 있는 경우 원본 이미지와 심각한 불일치를 초래한다. 이는 self-attention 제어 전체에서 $Q^\textrm{tgt}$가 사용되기 때문이다. 초기 step을 가이드하기 위해 타겟 프롬프트에 의존하는 대신 source self-attention의 $Q^\textrm{src}$, $K^\textrm{src}$, $V^\textrm{src}$를 사용하여 구조적 레이아웃을 형성한다.
Mutual self-attention 제어 스케줄링
이 mutual self-attention 제어는 $\tau_s$ 이후의 step에 적용된다.
\[\begin{equation} \textrm{SelfEdit} (\{Q^\textrm{src}, K^\textrm{src}, V^\textrm{src}\}, \{Q^\textrm{tgt}, K^\textrm{tgt}, V^\textrm{tgt}\}, t) = \begin{cases} \{Q^\textrm{src}, K^\textrm{src}, V^\textrm{src}\} & \quad t \ge \tau_s \\ \{Q^\textrm{tgt}, K^\textrm{tgt}, V^\textrm{tgt}\} & \quad t < \tau_s \end{cases} \end{equation}\]3. Unified Attention Control

위 그림에서 볼 수 있듯이 cross-attention 제어와 mutual self-attention 제어를 순차적으로 결합하면 좋지 못한 결과를 초래할 수 있으며 특히 글로벌 attention 개선에 실패한다. 본 논문은 이 문제를 해결하기 위해 Unified Attention Control (UAC) 프레임워크를 도입하였다. UAC는 타겟 이미지에서 원하는 구성과 구조 정보를 호스팅하는 중간 역할을 하는 추가 layout branch를 통해 cross-attention 제어와 mutual self-attention 제어를 통합한다.
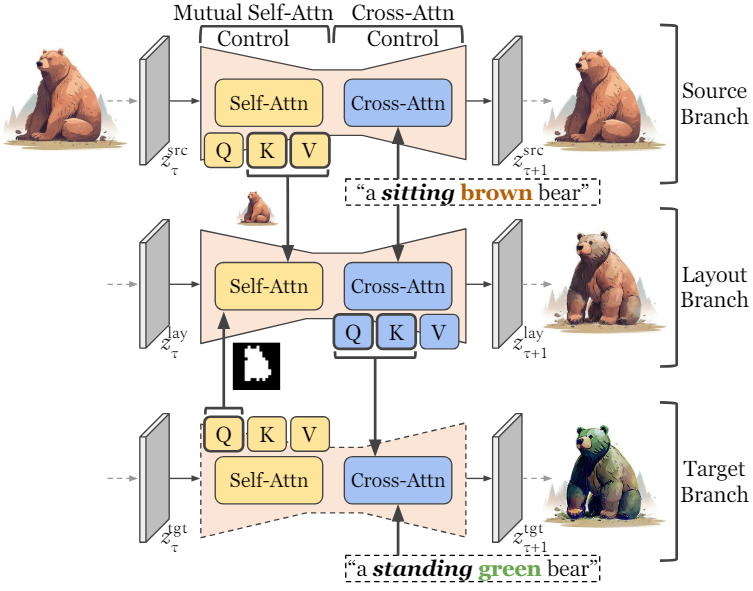
UAC 프레임워크는 위와 같다. 먼저 $z_t^\textrm{src}$와 $z_t^\textrm{tgt}$에 대한 mutual self-attention 제어를 하고 출력을 layout branch의 $z_t^\textrm{lay}$에 할당한다. 이어서 $M_t^\textrm{tgt}$에 대한 semantic 정보를 개선하기 위해 $M_t^\textrm{lay}$와 $M_t^\textrm{tgt}$에 cross-attention 제어가 적용된다. Layout branch의 출력 $z_0^\textrm{lay}$는 요청된 non-rigid change (ex. standing)을 반영하는 동시에 non-rigid 콘텐츠의 semantic (ex. brown)을 유지한다. Target branch의 출력 $z_0^\textrm{tgt}$는 요청된 non-rigid change (ex. green)을 반영하면서 $z_0^\textrm{lay}$의 구조적 레이아웃을 기반으로 구축된다.

Experiments
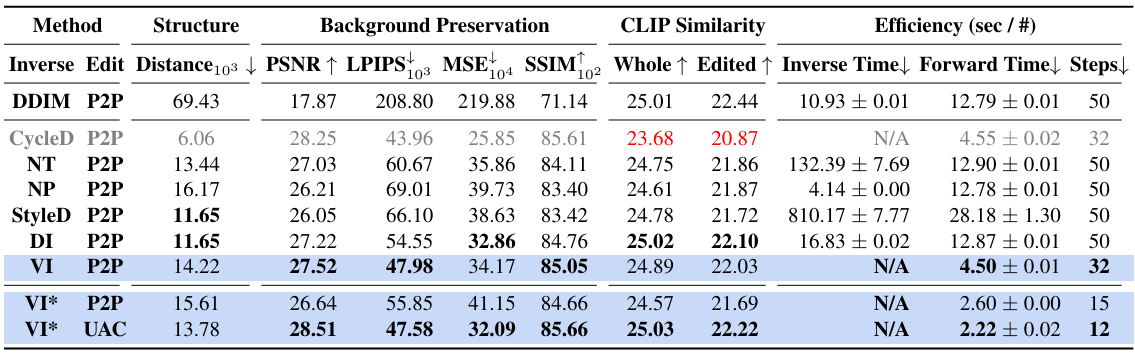
1. Inversion vs. Inversion-Free Comparison
다음은 PIE-bench에서 기존 inversion 기반 편집 방법들과 InfEdit을 비교한 결과이다.

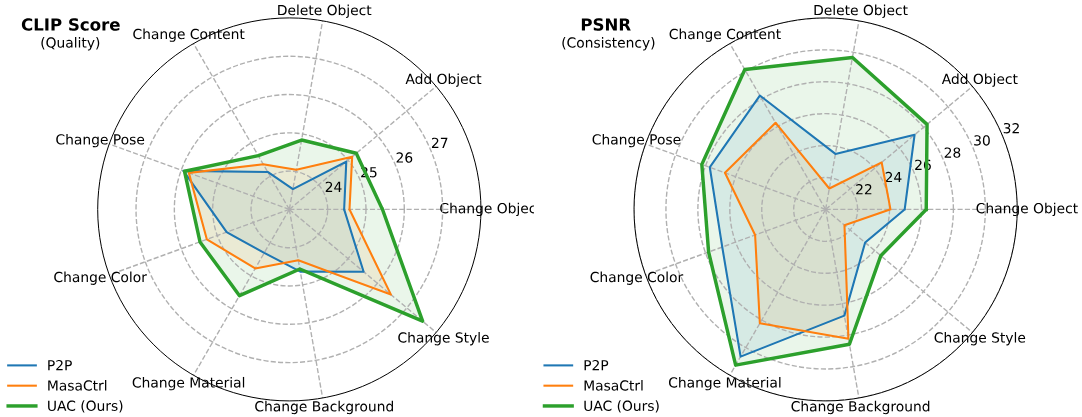
2. Attention Control Comparison
다음은 InfEdit과 기존 방법들의 편집 성능을 비교한 결과이다.

3. Image-to-Image Translation Tasks
다음은 image-to-image translation 성능을 기존 방법들과 비교한 표이다.

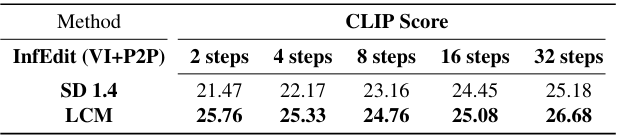
4. Computational Efficiency Ablation수
다음은 backbone에 따른 InfEdit의 CLIP score를 비교한 표이다. LCM을 backbone으로 사용하는 경우 더 적은 step으로 높은 CLIP score를 달성한다.