[논문리뷰] One-Step Image Translation with Text-to-Image Models
arXiv 2024. [Paper] [Github]
Gaurav Parmar, Taesung Park, Srinivasa Narasimhan, Jun-Yan Zhu
Carnegie Mellon University | Adobe Research
18 Mar 2024

Introduction
조건부 diffusion model을 사용하면 사용자가 공간적 컨디셔닝 및 텍스트 프롬프트를 기반으로 이미지를 생성할 수 있으므로 장면 레이아웃, 사용자 스케치, 인간 포즈에 대한 정확한 사용자 제어가 필요한 다양한 이미지 합성 애플리케이션이 가능해진다. 이러한 모델들은 엄청난 성공에도 불구하고 두 가지 주요 과제에 직면해 있다.
- Diffusion model의 반복적인 특성으로 인해 inference 속도가 느려지고 실시간 애플리케이션이 제한된다.
- 모델 학습에는 대규모 쌍을 이루는 데이터셋을 선별해야 하는 경우가 많으며, 이로 인해 많은 애플리케이션에 상당한 비용이 발생하지만 다른 애플리케이션에는 실행 불가능하다.
본 논문에서는 페어링된 설정과 페어링되지 않은 설정 모두에 적용할 수 있는 one-step image-to-image translation 방법을 소개한다. 본 논문의 방법은 inference step 수를 1로 줄이면서 기존 조건부 diffusion model과 시각적으로 비슷한 매력적인 결과를 달성하였다. 더 중요한 것은 이미지 쌍 없이 학습될 수 있다는 것이다. 핵심 아이디어는 SD-Turbo와 같은 사전 학습된 텍스트 조건부 one-step diffusion model을 적대적 학습 목적 함수를 통해 새로운 도메인 및 task에 효율적으로 적용하는 것이다.
안타깝게도 ControlNet과 같은 표준 diffusion 어댑터를 one-step 설정에 직접 적용하는 것은 덜 효과적이다. 기존 diffusion model과 달리 one-step 모델에서는 noise map이 출력 구조에 직접적인 영향을 미친다. 결과적으로 추가 어댑터 branch를 통해 noise map과 입력 조건을 모두 공급하면 네트워크에 대한 정보가 충돌하게 된다. 특히 쌍이 없는 경우에는 이 전략으로 인해 학습이 끝날 때 원래 네트워크가 무시된다. 또한 SD-Turbo 모델의 다단계 파이프라인(인코더-UNet-디코더)에 의한 불완전한 재구성으로 인해 이미지 변환 중에 입력 이미지의 많은 시각적 디테일이 손실된다. 이러한 디테일 손실은 입력이 실제 이미지일 때 특히 눈에 띄고 중요하다.
본 논문은 이러한 과제를 해결하기 위해 입력 이미지 구조를 유지하면서 SD-Turbo 가중치를 활용하는 새로운 generator 아키텍처를 제안하였다.
- UNet의 noise 인코더 branch에 컨디셔닝 정보를 직접 공급한다. 이를 통해 네트워크는 noise map과 입력 제어 간의 충돌을 피하면서 새로운 제어에 직접 적응할 수 있다.
- 세 가지 개별 모듈인 인코더, UNet, 디코더를 하나의 end-to-end로 학습 가능한 아키텍처로 통합한다. 이를 위해 LoRA를 사용하여 원래 네트워크를 새로운 제어 및 도메인에 적응시켜 overfitting 및 fine-tuning 시간을 줄인다.
- 입력의 고주파 디테일을 보존하기 위해 zero-conv를 통해 인코더와 디코더 사이의 skip connection을 통합한다.
본 논문의 아키텍처는 CycleGAN이나 pix2pix와 같은 조건부 GAN 목적 함수를 위한 plug-and-play model 역할을 하므로 다목적아다. 본 논문은 text-to-image 모델을 사용하여 one-step image translation을 달성한 최초의 논문이다.
Method
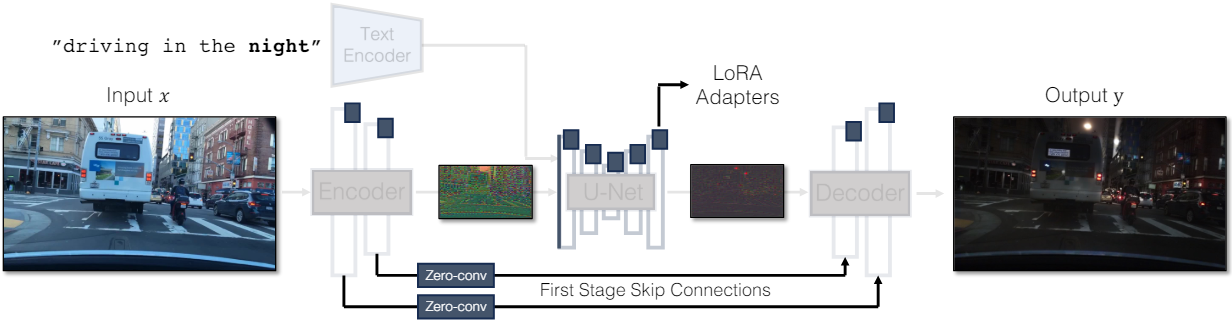
1. Adding Conditioning Input
Text-to-image 모델을 image translation 모델로 변환하려면 먼저 입력 이미지 $x$를 모델에 통합하는 효과적인 방법을 찾아야 한다.

Noise와 조건부 입력 간의 충돌. 조건부 입력을 diffusion model에 통합하기 위한 일반적인 전략 중 하나는 추가 어댑터 branch를 도입하는 것이다. 즉, Stable Diffusion 인코더의 가중치를 사용하거나 가벼운 네트워크를 랜덤 초기화하여 또다른 인코더인 조건 인코더(Condition Encoder)를 초기화한다. 조건 인코더는 입력 이미지 $x$를 가져와서 residual connection을 통해 사전 학습된 Stable Diffusion 모델에 대한 여러 해상도의 feature map을 출력한다. 이 방법은 diffusion model 제어에 있어 놀라운 결과를 가져왔다. 그럼에도 불구하고 위 그림에서 볼 수 있듯이 두 개의 인코더를 사용하여 noise map과 입력 이미지를 처리하는 것은 one-step 모델의 맥락에서 문제가 발생한다. Multi-step 모델과 달리 one-step 모델의 noise map은 생성된 이미지의 레이아웃과 포즈를 직접 제어하며 종종 입력 이미지의 구조와 모순된다. 따라서 디코더는 각각 별개의 구조를 나타내는 두 residual feature를 받으므로 학습 과정이 더욱 어려워진다.
직접적인 컨디셔닝 입력. 또한 사전 학습된 모델에 의해 생성된 이미지의 구조가 noise map $z$에 의해 크게 영향을 받는다. 따라서 컨디셔닝 입력을 네트워크에 직접 공급해야 한다. Backbone 모델이 새로운 조건에 적응할 수 있도록 U-Net의 다양한 레이어에 여러 LoRA 가중치를 추가한다.
2. Preserving Input Details
물체가 여러 개이거나 복잡한 장면에서 latent diffusion model (LDM) 사용을 방해하는 주요 문제는 디테일이 손실된다는 것이다.

디테일이 손실되는 이유. LDM의 이미지 인코더는 입력 이미지의 가로 세로를 8배로 압축하는 동시에 채널 수를 3에서 4로 늘린다. 이 디자인은 diffusion model의 학습 및 inference 속도를 높인다. 그러나 입력 이미지의 세밀한 디테일을 보존해야 하는 image translation task에는 적합하지 않을 수 있다. 이 문제를 위 그림에서 설명한다. 입력된 주간 운전 이미지(왼쪽)를 skip connection을 사용하지 않는 아키텍처(가운데)를 사용하여 야간 운전 이미지로 변환하면 텍스트, 거리 표지판, 멀리 있는 자동차 등 세밀한 디테일은 유지되지 않는다. 반면 skip connection을 통합하는 아키텍처를 사용하면 (오른쪽) 이러한 복잡한 디테일을 훨씬 더 잘 유지하는 이미지가 생성된다.
인코더와 디코더를 연결. 입력 이미지의 세밀한 디테일을 캡처하기 위해 인코더와 디코더 네트워크 사이에 skip connection을 추가한다. 구체적으로, 인코더 내의 각 다운샘플링 블록 다음에 4개의 중간 activation을 추출하고 이를 1$\times$1 zero-convolution layer를 통해 처리한 다음 디코더의 대응되는 업샘플링 블록에 공급한다. 이 방법을 사용하면 프로세스 전반에 걸쳐 복잡한 디테일을 유지할 수 있다.
3. Unpaired Training
모든 실험의 기본 네트워크로 one-step inference가 가능한 Stable Diffusion Turbo v2.1를 사용한다. 구체적으로, 쌍이 없는 데이터셋 \(X = \{x \in \mathcal{X} \}, Y = \{y \in \mathcal{Y}\}\)가 주어지면 소스 도메인 $\mathcal{X} \subset \mathbb{R}^{H \times W \times 3}$의 이미지를 원하는 타겟 도메인 $\mathcal{Y} \subset \mathbb{R}^{H \times W \times 3}$로 변환하는 것이 목표이다.
두 가지 변환 함수 $G(x, c_Y): X \rightarrow Y$와 $G(y, c_X): Y \rightarrow X$가 존재한다. 두 변환 모두 동일한 네트워크 $G$를 사용하지만 캡션 $c_X$와 $c_Y$는 다르다. 예를 들어 주간 운전 이미지에서 야간 운전 이미지로 번환하는 경우 $c_X$는 낮에 운전, $c_Y$는 밤에 운전을 의미한다. 대부분의 레이어를 동결하로 유지하고 첫 번째 convolution layer와 추가된 LoRA 어댑터만 학습한다.
Perceptual loss를 사용한 cycle consistency. Cycle consistency loss \(\mathcal{L}_\textrm{cycle}\)은 각 소스 이미지 $x$에 대해 두 개의 변환 함수로 이를 다시 복구하도록 강제한다.
\[\begin{aligned} \mathcal{L}_\textrm{cycle} &= \mathbb{E}_x [\mathcal{L}_\textrm{rec} (G(G(x, c_Y), c_x), x)] \\ &+ \mathbb{E}_y [\mathcal{L}_\textrm{rec} (G(G(y, c_X), c_Y), y)] \end{aligned}\]\(\mathcal{L}_\textrm{rec}\)는 L1 차이와 LPIPS의 조합으로 나타낸다.
Adversarial loss. 출력이 타겟 도메인과 일치하도록 장려하기 위해 두 도메인 모두에 대해 adversarial loss를 사용한다. 해당 도메인에 대해 번환된 이미지와 실제 이미지를 분류하는 것을 목표로 하는 두 개의 discriminator인 \(\mathcal{D}_X\)와 \(\mathcal{D}_Y\)를 사용한다. 두 discriminator 모두 Vision-Aided GAN의 권장 사항에 따라 CLIP 모델을 backbone으로 사용한다. Adversarial loss는 다음과 같이 정의된다.
\[\begin{aligned} \mathcal{L}_\textrm{GAN} &= \mathbb{E}_y [\log \mathcal{D}_Y (y)] + \mathbb{E}_x [\log (1 - \mathcal{D}_Y (G (x, c_Y)))] \\ &+ \mathbb{E}_y [\log \mathcal{D}_X (x)] + \mathbb{E}_y [\log (1 - \mathcal{D}_X (G (y, c_X)))] \end{aligned}\]전체 목적함수. 전체 목적함수는 세 가지 loss, 즉 cycle consistency loss \(\mathcal{L}_\textrm{cycle}\), adversarial loss \(\mathcal{L}_\textrm{GAN}\), identity regularization loss \(\mathcal{L}_\textrm{idt}\)로 구성된다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{cycle} + \lambda_\textrm{idt} \mathcal{L}_\textrm{idt} + \lambda_\textrm{GAN} \mathcal{L}_\textrm{GAN} \\ \textrm{where} \quad \mathcal{L}_\textrm{idt} = \mathbb{E}_x [\mathcal{L}_\textrm{rec} (G (x, c_X), x)] + \mathbb{E}_y [\mathcal{L}_\textrm{rec} (G (y, c_Y), y)] \end{equation}\]4. Extensions
본 논문은 쌍이 없는 데이터셋에 대한 학습에 초점을 맞추고 있지만, 쌍을 이루는 데이터로부터 학습하거나 다양한 출력을 생성하는 등 다른 유형의 GAN 목적 함수를 학습하기 위한 두 가지 확장도 보여주었다.
쌍을 이루는 데이터셋에 대한 학습. Edge나 스케치를 이미지로 변환하는 등의 쌍을 이루는 설정에 네트워크 $G$를 적용한다. 이러한 쌍을 이루는 버전을 pix2pix-Turbo라고 부른다. 쌍을 이루는 설정에서 하나의 번환 함수 $G(x, c): X \rightarrow Y$를 학습하는 것을 목표로 한다. 목적 함수는 다음 세 가지를 함꼐 사용한다.
- 재구성 loss \(\mathcal{L}_\textrm{rec}\)
- 타겟 도메인에 대한 GAN loss
- CLIP text-image alignment loss \(\mathcal{L}_\textrm{CLIP}\)
다양한 출력 생성. 다양한 출력을 생성하는 것은 sketch-to-image와 같은 많은 image translation task에서 중요하다. 그러나 다양한 출력을 생성하기 위한 one-step 모델을 사용하는 것은 종종 무시되는 추가적인 입력 noise를 사용해야 하기 때문에 어려운 일이다. 따라서 이미 다양한 출력을 생성하고 있는 사전 학습된 모델에 feature와 모델 가중치를 보간(interpolation)하여 다양한 출력을 생성한다. 구체적으로, interpolation 계수 $\gamma$가 주어지면 다음과 같은 세 가지 변경을 수행한다.
- Gaussian noise와 인코더 출력을 결합한다. Generator $G(x, z, \gamma)$는 입력 이미지 $x$, noise map $z$, 계수 $\gamma$를 입력을 사용한다. $G(x, z, \gamma)$는 먼저 noise $z$와 인코더 출력을 $\gamma$를 사용하여 선형적으로 결합한다. 그런 다음 결합된 신호를 U-Net에 공급한다.
- $\theta = \theta_0 + \gamma \cdot \Delta \theta$에 따라 LoRA 어댑터 가중치와 skip connection의 출력을 조정한다. $\theta_0$는 원래 가중치이고 $\Delta \theta$는 새로 추가된 가중치이다.
- $\gamma$에 따라 재구성 loss를 조정한다.
$\gamma = 0$은 사전 학습된 모델의 stochastic한 동작에 해당하며, 이 경우 재구성 loss가 적용되지 않는다. $\gamma = 1$은 deterministic한 변환에 해당한다.
Experiments
- 데이터셋
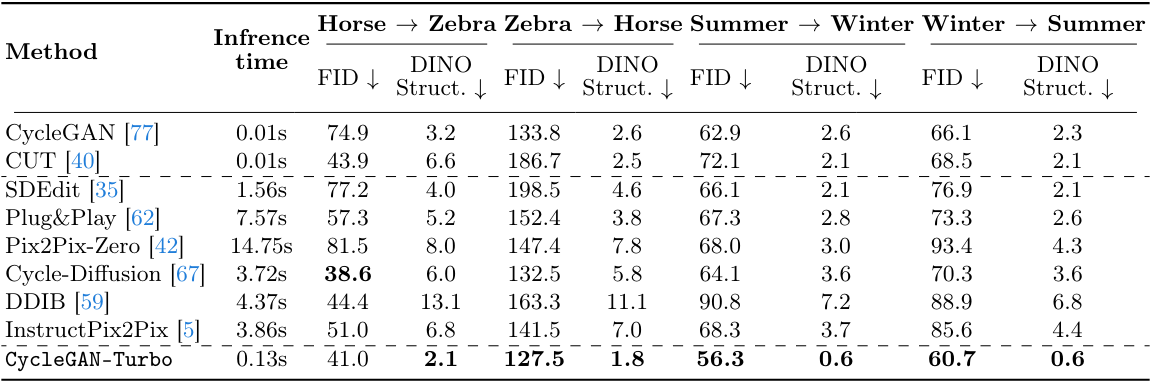
- CycleGAN 데이터셋 (256$\times$256): Horse $\leftrightarrow$ Zebra, Yosemite Summer $\leftrightarrow$ Winter
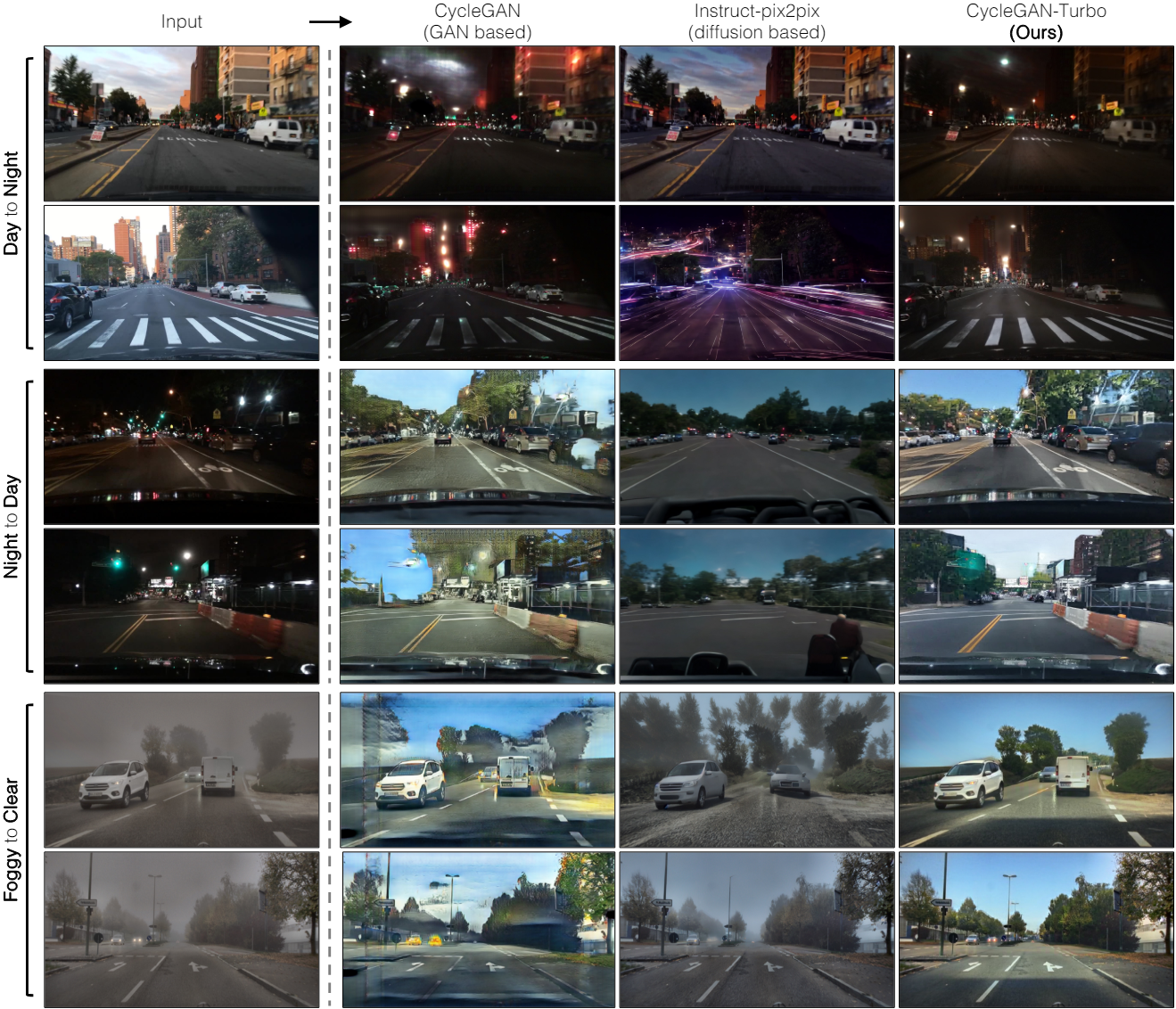
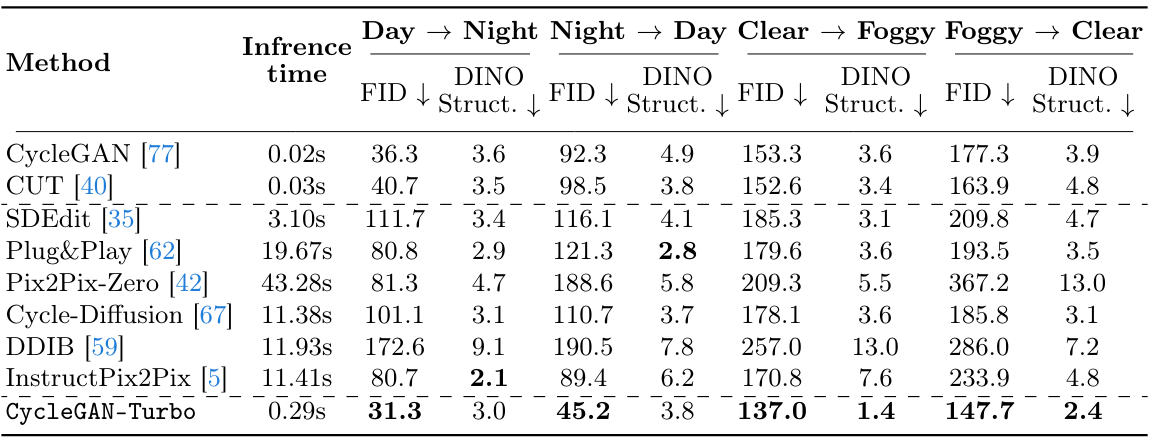
- BDD100k, DENSE (512$\times$512): day $\leftrightarrow$ night, clear $\leftrightarrow$ foggy
1. Comparison to Unpaired Methods
다음은 256$\times$256 CycleGAN 데이터셋에서 다른 방법들과 비교한 결과이다.

다음은 512$\times$512 운전 데이터셋에서 다른 방법들과 비교한 결과이다.
다음은 사람의 선호도를 평가한 표이다.

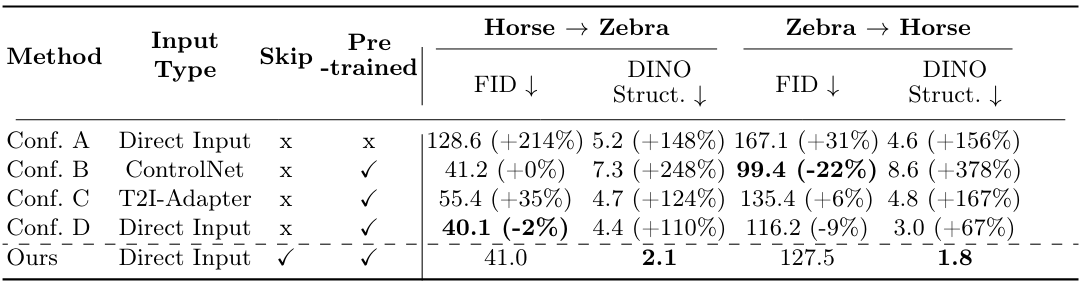
2. Ablation Study
다음은 ablation study 결과이다.

3. Extensions
다음은 쌍을 이루는 edge-to-image task (512$\times$512)에 대한 비교 결과이다.

다음은 다양한 출력을 생성하는 예시이다.

Limitations
- Backbone 모델인 SD-Turbo는 classifier-free guidance를 사용하지 않기 때문에 guidance의 강도를 지정할 수 없다.
- 아티팩트를 줄이는 편리한 방법인 negative prompt를 지원하지 않는다.
- Cycle consistency loss와 고용량 generator를 사용한 모델 학습은 메모리 집약적이다.