[논문리뷰] ImageBind: One Embedding Space To Bind Them All
CVPR 2023. [Paper] [Page] [Github]
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, Ishan Misra
Meta AI
9 May 2023

Introduction
하나의 이미지는 많은 경험을 하나로 묶을 수 있다. 해변의 이미지는 파도 소리, 모래의 질감, 바람을 떠올리게 하거나 시에 영감을 줄 수도 있다. 이미지의 이 ‘바인딩’ 속성은 시각적 feature를 이미지와 관련된 모든 감각 경험과 정렬하여 시각적 feature를 학습할 수 있는 많은 supervision 소스를 제공한다. 이상적으로는 하나의 공동 임베딩 공간의 경우 이러한 모든 센서에 정렬하여 시각적 feature를 학습해야 한다. 그러나 이를 위해서는 동일한 이미지 세트와 쌍을 이룬 데이터의 모든 유형 및 조합을 획득해야 하므로 이는 불가능하다.
최근 많은 방법이 텍스트, 오디오 등과 정렬된 이미지 feature를 학습한다. 이러한 방법은 한 쌍의 modality 또는 기껏해야 몇 가지 시각적 modality를 사용한다. 그러나 최종 임베딩은 학습에 사용되는 modality 쌍으로 제한된다. 따라서 동영상-오디오 임베딩은 이미지-텍스트 task에 직접 사용할 수 없으며 그 반대도 마찬가지이다. 진정한 공동 임베딩 학습의 주요 장애물은 모든 modality가 함께 존재하는 대량의 멀티모달 데이터가 없다는 것이다.
본 논문에서는 여러 유형의 이미지 쌍 데이터를 활용하여 하나의 공유 표현 공간을 학습하는 ImageBind를 제시한다. 모든 modality가 서로 동시에 발생하는 데이터셋이 필요하지 않다. 대신, 이미지의 바인딩 속성을 활용하고 각 modality의 임베딩을 이미지 임베딩에 정렬하는 것만으로도 모든 modality에 걸쳐 정렬이 이루어진다. 실제로 ImageBind는 웹스케일의 (이미지, 텍스트) 페어링 데이터를 활용하고 이를 (동영상, 오디오), (이미지, 깊이) 등과 같은 자연적으로 발생하는 페어링 데이터와 결합하여 하나의 공동 임베딩 공간을 학습한다. 이를 통해 ImageBind는 텍스트 임베딩을 오디오, 깊이 등과 같은 다른 modality에 암시적으로 정렬하여 명시적인 semantic 또는 텍스트 페어링 없이 해당 modality에서 zero-shot 인식 능력을 활성화할 수 있다. 또한 CLIP과 같은 대규모 비전-언어 모델로 초기화할 수 있으므로 이러한 모델의 풍부한 이미지 및 텍스트 표현을 활용할 수 있다. 따라서 ImageBind는 학습을 거의 받지 않고도 다양한 modality와 task에 적용할 수 있다.
본 논문은 오디오, 깊이, 열화상, 관성 측정 장치 (IMU) 판독값과 같은 네 가지 새로운 modality에 걸쳐 자연적으로 쌍을 이룬 self-supervised 데이터와 함께 대규모 이미지-텍스트 쌍 데이터를 사용하며, 이러한 modality 각각에 대한 task에 대한 강력한 zero-shot 분류 및 검색 성능을 갖는다. 이러한 속성들은 기본 이미지 표현이 더 강해짐에 따라 향상된다. 오디오 분류 및 검색 벤치마크에서 ImageBind의 새로운 zero-shot 분류는 ESC, Clotho, AudioCaps와 같은 벤치마크에서 직접 오디오-텍스트 supervision으로 학습된 전문가 모델과 일치하거나 능가한다. 또한 ImageBind 표현은 few-shot 평가 벤치마크에서 전문가 supervised 모델보다 성능이 뛰어나다. 마지막으로 ImageBind의 공동 임베딩은 cross-modal 검색, 산술을 통한 임베딩 결합, 이미지에서 오디오 소스 감지, 주어진 오디오 입력 이미지 생성 등을 포함하여 다양한 결합 task에 사용될 수 있다.
Method

본 논문의 목표는 이미지를 사용하여 함께 묶음으로써 모든 modality에 대한 단일 공동 임베딩 공간을 학습하는 것이다. 이미지 임베딩에 각 modality의 임베딩을 정렬한다 (ex. 웹 데이터를 사용하여 텍스트를 이미지로, 캡처한 동영상 데이터를 사용하여 IMU에서 동영상으로). 결과 임베딩 공간은 특정 쌍에 대한 학습 데이터를 보지 않고 modality 쌍을 자동으로 연결하는 강력한 zero-shot 동작을 가진다. 접근 방식은 위 그림과 같다.
1. Binding modalities with images
ImageBind는 modality 쌍 $(\mathcal{I}, \mathcal{M})$을 사용하여 하나의 공동 임베딩을 학습한다. 여기서 $\mathcal{I}$는 이미지를 나타내고 $\mathcal{M}$은 또 다른 modality이다. 광범위한 semantic 개념에 걸친 (이미지, 텍스트) 쌍이 있는 대규모 웹 데이터셋을 사용한다. 또한 오디오, 깊이, 열화상, 관성 측정 장치 (IMU)와 같은 다른 modality를 이미지와 함께 자연스럽고 self-supervised 방식으로 페어링한다.
관찰이 정렬된 modality 쌍 $(\mathcal{I}, \mathcal{M})$을 고려하자. 이미지 \(I_i\)와 다른 modality $M_i$에서의 해당 관찰이 주어지면 정규화된 임베딩으로 인코딩한다.
\[\begin{equation} q_i = f (I_i), \quad k_i = g (M_i) \end{equation}\]여기서 $f$, $g$는 신경망이다. 임베딩과 인코더는 InfoNCE loss를 사용하여 최적화된다.
\[\begin{equation} L_{\mathcal{I}, \mathcal{M}} = - \log \frac{exp (q_i^\top k_i / \tau)}{\exp (q_i^\top k_i / \tau) + \sum_{j \ne i} \exp (q_i^\top k_j / \tau)} \end{equation}\]여기서 $\tau$는 softmax 분포의 부드러움을 제어하는 스칼라 temperature이고 $j$는 ‘negative’라고도 하는 관련 없는 관측치를 나타낸다. Mini-batch의 모든 예 $j \ne i$를 negative로 고려한다. Loss는 공동 임베딩 공간에서 임베딩 $q_i$와 $k_i$를 더 가깝게 만들고 따라서 $\mathcal{I}$와 $\mathcal{M}$을 정렬한다. 실제로는 대칭적인 loss \(L_{\mathcal{I}, \mathcal{M}} + L_{\mathcal{M}, \mathcal{I}}\)를 사용한다.
Emergent alignment of unseen pairs of modalities
ImageBind는 이미지와 쌍을 이루는 modality, 즉 $(\mathcal{I}, \mathcal{M})$ 형식의 쌍을 사용하여 각 modality $\mathcal{M}$의 임베딩을 이미지의 임베딩에 정렬한다. \((\mathcal{I}, \mathcal{M}_1)\)과 \((\mathcal{I}, \mathcal{M}_2)\) 쌍만 사용하여 학습하더라도 두 쌍의 modality \((\mathcal{M}_1, \mathcal{M}_2)\)를 정렬하는 임베딩 공간에서 행동을 관찰한다. 이 행동을 통해 학습 없이 다양한 zero-shot과 cross-modal 검색 작업을 수행할 수 있다. (오디오, 텍스트) 쌍의 단일 샘플을 관찰하지 않고 SOTA zero-shot 텍스트-오디오 분류 결과를 달성한다.
2. Implementation Details
ImageBind는 개념적으로 단순하며 다양한 방식으로 구현될 수 있다. 본 논문은 의도적으로 유연하고 효과적인 연구와 쉬운 채택을 허용하는 바닐라 구현을 선택하였다.
Encoding modalities
모든 modality 인코더에 Transformer 아키텍처를 사용한다. 이미지에 ViT를 사용한다. 다음으로 이미지와 동영상에 동일한 인코더를 사용한다. ViT의 patch projection layer를 일시적으로 팽창시키고 2초에서 샘플링된 2프레임의 동영상 클립을 사용한다. 오디오를 인코딩하고 16kHz로 샘플링된 2초 오디오를 128개의 mel-spectrogram bin을 사용하여 spectrogram으로 변환한다. Spectrogram도 이미지와 같은 2D 신호이므로 패치 크기가 16이고 stride가 10인 ViT를 사용한다. 열화상 이미지와 깊이 이미지를 1채널 이미지로 취급하고 ViT를 사용하여 인코딩한다. 스케일 불변성을 위해 깊이를 disparity map으로 변환한다. $X$축, $Y$축, $Z$축에 걸친 가속도계와 자이로스코프 측정으로 구성된 IMU 신호를 추출한다. 5초 클립을 사용하여 커널 크기가 8인 1D convolution을 사용하여 project되는 2천 timestep IMU 판독값을 생성한다. 결과 시퀀스는 Transformer를 사용하여 인코딩된다. 마지막으로 CLIP의 텍스트 인코더 디자인을 따른다.
이미지, 텍스트, 오디오, 열화상, 깊이 이미지, IMU에 별도의 인코더를 사용한다. InfoNCE에서 정규화되고 사용되는 고정 크기 $d$ 차원 임베딩을 얻기 위해 각 인코더에 modality별 linear projection head를 추가한다. 학습 용이성 외에도 이 설정을 사용하면 사전 학습된 모델 (ex. CLIP 또는 OpenCLIP을 사용하는 이미지 및 텍스트 인코더)을 사용하여 인코더의 부분 집합을 초기화할 수 있다.
Experiments
오디오, 깊이, 열화상, IMU에 대하여 emergent zero-shot 분류를 위한 데이터셋은 다음과 같다.
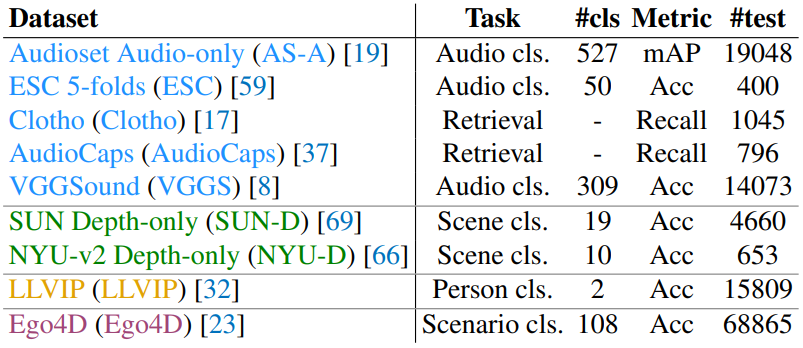
1. Emergent zero-shot classification
다음은 emergent zero-shot 분류 결과이다. 텍스트 프롬프트를 사용한 경우 파란색파란색으로 표시되어 있다.

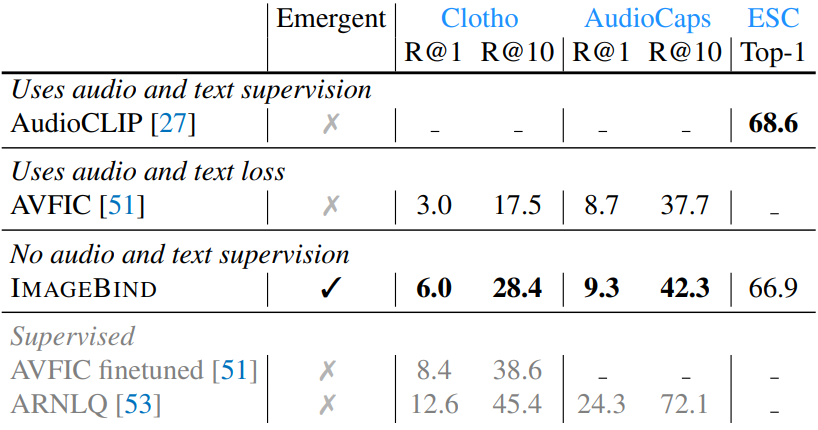
2. Comparison to prior work
다음은 emergent zero-shot 오디오 검색 및 분류 결과이다.
다음은 MSR-VTT 1K-A에서의 zero-shot 텍스트 기반 검색 결과이다.

3. Few-shot classification
다음은 오디오와 깊이에 대한 few-shot 분류 결과를 나타낸 그래프이다.

4. Analysis and Applications
다음은 이미지 임베딩과 오디오 임베딩을 더한 후 이미지 검색에 사용하는 예시이다.

다음은 오디오 쿼리를 사용한 object detection의 예시이다.

Ablation Study
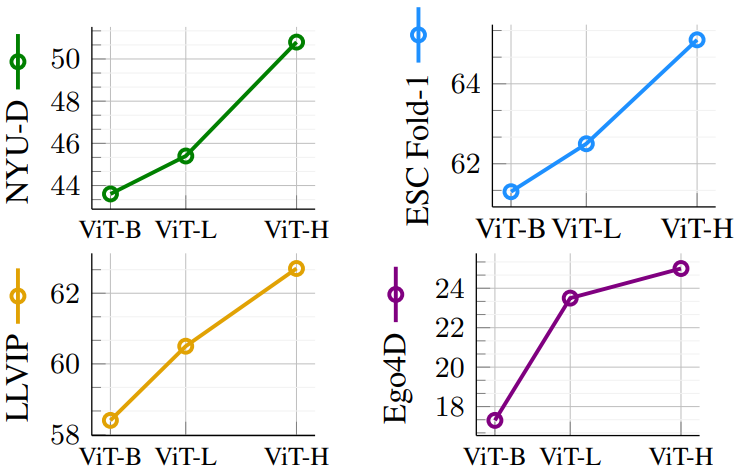
1. Scaling the Image Encoder
다음은 이미지 인코더 크기에 따른 emergent zero-shot 분류 결과이다.
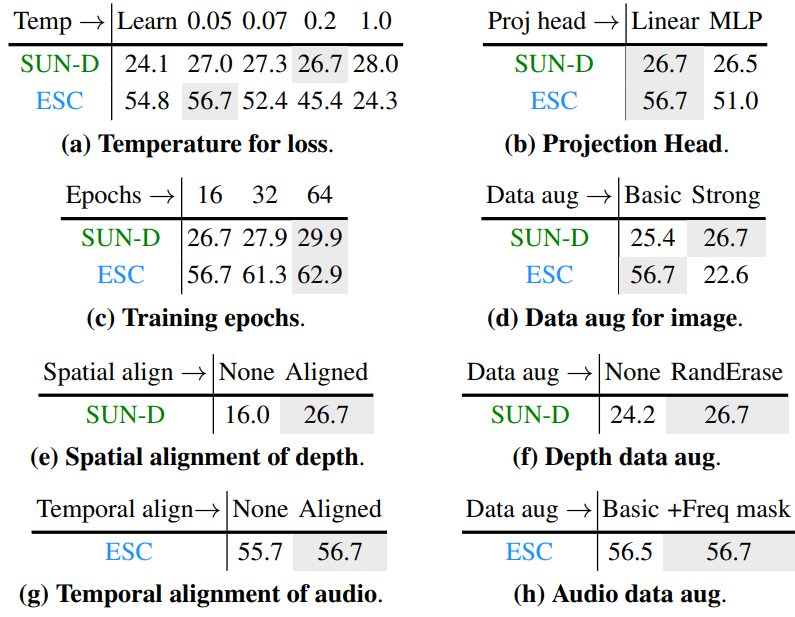
2. Training Loss and Architecture
다음은 학습 loss와 아키텍처에 대한 ablation 결과이다.
다음은 오디오 인코더와 깊이 인코더의 용량에 대한 영향을 나타낸 표이다.

다음은 batch size에 대한 효과를 나타낸 표이다.
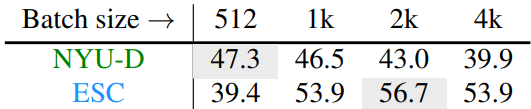
다음은 ImageBind를 평가 도구로 사용할 때의 결과이다.

Limitations
- ImageBind의 임베딩은 특정 다운스트림 task 없이 학습되므로 전문가 모델의 성능이 뒤떨어진다.
- ImageBind는 연구 프로토타입이며 실제 애플리케이션에 쉽게 사용할 수 없다.