[논문리뷰] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture (I-JEPA)
CVPR 2023. [Paper] [Post] [Github]
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas
Meta AI (FAIR) | McGill University | Mila, Quebec AI Institute | New York University
19 Jan 2023
Introduction
컴퓨터 비전에는 이미지의 self-supervised learning을 위한 두 가지 일반적인 접근 방식, 즉 불변성 (invariance) 기반 방법과 생성 방법이 있다.
불변성 기반 사전 학습 방법은 동일한 이미지의 두 개 이상의 view에 대해 유사한 임베딩을 생성하도록 인코더를 최적화한다. 이미지 view는 일반적으로 랜덤 스케일링, cropping, color jittering 등 수작업으로 만든 data augmentation 세트를 사용하여 구성된다. 이러한 사전 학습 방법은 높은 sementic 수준의 표현을 생성할 수 있지만 특정 다운스트림 task나 심지어 데이터 분포가 다른 사전 학습 task에 해로울 수 있는 강한 편향을 도입하기도 한다. 다양한 수준의 추상화가 필요한 task에 대해 이러한 편견을 일반화하는 방법이 불분명한 경우가 많다. 예를 들어 image classification과 instance segmentation에는 동일한 불변성이 필요하지 않다. 또한 이러한 이미지별 augmentation을 오디오와 같은 다른 modality로 일반화하는 것은 간단하지 않다.
인지 학습 이론은 생물학적 시스템에서 표현 학습의 이면에 있는 메커니즘은 감각 입력 반응을 예측하기 위한 내부 모델의 적응이라고 제안했다. 이 아이디어는 입력의 일부를 제거하거나 손상시키고 손상된 내용을 예측하는 방법을 학습하는 self-supervised 생성 방법의 핵심이다. 특히, mask-denoising 접근 방식은 픽셀 또는 토큰 레벨에서 입력으로부터 랜덤하게 마스킹된 패치를 재구성하여 표현을 학습한다. 마스킹된 사전 학습 task는 view 불변성 접근 방식보다 사전 지식이 덜 필요하며 이미지 modality 이상으로 쉽게 일반화된다. 그러나 결과 표현은 일반적으로 semantic 수준이 낮으며 기존 평가 (ex. linear-probing)와 semantic classification task에 대한 supervision이 제한된 전송 설정에서 불변성 기반 사전 학습 성능이 저조하다. 결과적으로 이러한 방법의 이점을 최대한 활용하려면 보다 복잡한 적응 메커니즘 (ex. end-to-end fine-tuning)이 필요하다.

본 연구에서는 이미지 변환을 통해 인코딩된 추가 사전 지식을 사용하지 않고 self-supervised 표현의 semantic 수준을 향상시키는 방법을 탐구한다. 이를 위해 이미지 기반 공동 임베딩 예측 아키텍처 (Image-based Joint-Embedding Predictive Architecture, I-JEPA)를 도입한다. I-JEPA의 기본 개념은 추상 표현 공간에서 누락된 정보를 예측하는 것이다. 예를 들어 단일 컨텍스트 블록이 주어지면 동일한 이미지에서 다양한 타겟 블록의 표현을 예측한다. 여기서 타겟 표현은 학습된 타겟 인코더 네트워크에 의해 계산된다.
픽셀/토큰 공간에서 예측하는 생성 방법과 비교하여 I-JEPA는 불필요한 픽셀 레벨 디테일이 잠재적으로 제거되는 추상 예측 타겟을 사용하여 모델이 더 많은 semantic feature를 학습하도록 유도한다. I-JEPA가 semantic 표현을 생성하도록 가이드하는 또 다른 핵심 디자인 선택은 multi-block masking 전략이다. 특히, 정보를 주는 컨텍스트 블록을 사용하여 이미지에서 충분히 큰 타겟 블록을 예측하는 것의 중요성을 보여준다.
Method
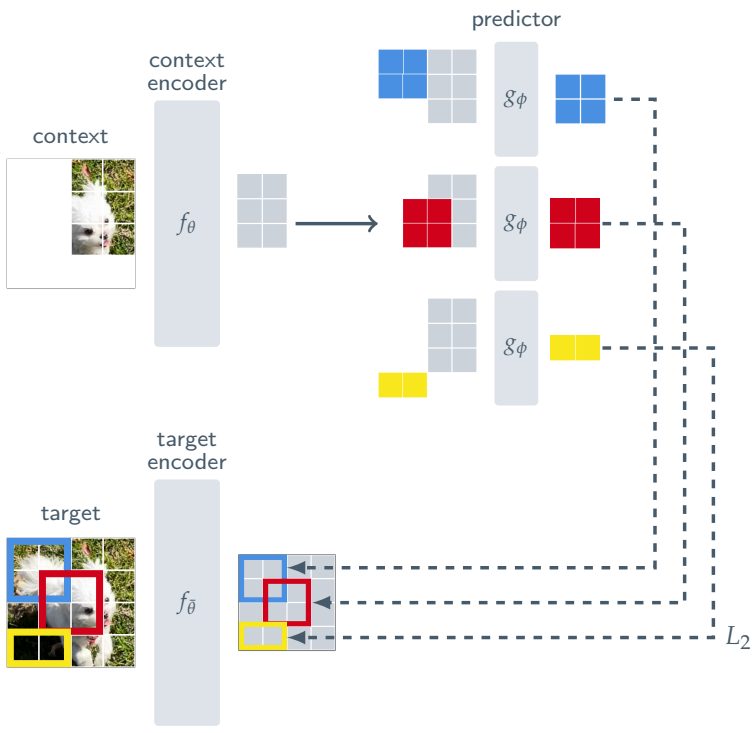
위 그림은 이미지 기반 공동 임베딩 예측 아키텍처 (I-JEPA)를 묘사한다. 전반적인 목적 함수 주어진 컨텍스트 블록에서 동일한 이미지의 다양한 타겟 블록 표현을 예측한다. 본 논문은 컨텍스트 인코더, 타겟 인코더, predictor에 ViT 아키텍처를 사용한다. ViT는 transformer 레이어 스택으로 구성되며, 각 레이어는 self-attention 연산과 이어지는 fully-connected MLP로 구성된다. 인코더/predictor 아키텍처는 masked autoencoder (MAE) 방법을 연상시킨다. 그러나 한 가지 주요 차이점은 I-JEPA 방법은 비생성적이며 예측이 표현 공간에서 이루어진다는 것이다.
Targets
I-JEPA에서 타겟은 이미지 블록의 표현에 해당한다. 입력 이미지 $y$가 주어지면 이를 $N$개의 겹치지 않는 패치 시퀀스로 변환하고 이를 타겟 인코더 $f_{\bar{\theta}}$에 공급하여 해당 패치 레벨 표현 \(s_y = \{s_{y_1}, \ldots, s_{y_N}\}\)을 얻는다. 여기서 $s_{y_k}$는 $k$번째 패치와 관련된 표현이다. Loss를 위한 타겟을 얻기 위해 타겟 표현 $s_y$에서 $M$개의 (겹칠 수도 있는) 블록을 무작위로 샘플링한다. $i$번째 블록에 해당하는 마스크를 $B_i$라 하고, 패치 레벨 표현을 \(s_y (i) = \{s_{y_j}\}_{j \in B_i}\)로 표시한다. 일반적으로 $M$을 4로 설정하고 (0.75, 1.5) 범위의 랜덤 종횡비와 (0.15, 0.2) 범위의 랜덤 크기로 블록을 샘플링한다. 타겟 블록은 입력이 아닌 타겟 인코더의 출력을 마스킹하여 얻는다. 이러한 구별은 높은 semantic 수준의 타겟 표현을 보장하는 데 중요하다.
Context

I-JEPA의 목표는 단일 컨텍스트 블록에서 타겟 블록 표현을 예측하는 것이다. I-JEPA에서 컨텍스트를 얻기 위해 먼저 (0.85, 1.0) 범위의 랜덤 배율과 단위 종횡비를 사용하여 이미지에서 하나의 블록 $x$를 샘플링한다. 컨텍스트 블록 $x$와 연관된 마스크를 $B_x$로 표시한다. 타겟 블록은 컨텍스트 블록과 독립적으로 샘플링되므로 상당한 중복이 발생할 수 있다. 자명하지 않은 예측을 보장하기 위해 컨텍스트 블록에서 겹치는 영역을 제거한다. 위 그림은 실제로 다양한 컨텍스트와 타겟 블록의 예를 보여준다. 다음으로, 마스킹된 컨텍스트 블록 $x$는 컨텍스트 인코더 $f_\theta$를 통해 공급되어 해당 패치 레벨 표현 \(s_x = \{s_{x_j}\}_{j \in B_x}\)를 얻는다.
Prediction
컨텍스트 인코더의 출력 $s_x$가 주어지면 $M$개의 타겟 블록 표현 $s_y (1), \ldots, s_y (M)$을 예측하려고 한다. 이를 위해 타겟 마스크 $B_i$에 해당하는 주어진 타겟 블록 $s_y (i)$에 대해 predictor $g_\phi (\cdot, \cdot)$는 컨텍스트 인코더 $s_x$의 출력과 예측하려는 각 패치에 대한 마스크 토큰 \(\{m_j\}_{j \in B_i}\)을 입력으로 사용한다. 그리고 패치 레벨 예측
\[\begin{equation} \hat{s}_y (i) = \{ \hat{s}_{y_j} \}_{j \in B_i} = g_\phi (s_x, \{m_j\}_{j \in B_i}) \end{equation}\]를 출력한다. 마스크 토큰은 위치 임베딩이 추가된 학습 가능한 공유 벡터에 의해 parameterize된다. $M$개의 타겟 블록에 대해 예측을 하고 싶기 때문에 predictor를 $M$번 적용하고, 매번 예측하려는 타겟 블록 위치에 해당하는 마스크 토큰을 조정하고 예측 \(\hat{s}_y (1), \ldots, \hat{s}_y (M)\)을 얻는다.
Loss
Loss는 단순히 예측된 패치 레벨 표현 \(\hat{s}_y (i)\)와 타겟 패치 레벨 표현 $s_y (i)$ 사이의 평균 L2 거리이다.
\[\begin{equation} \frac{1}{M} \sum_{i=1}^M D (\hat{s}_y (i), s_y (i)) = \frac{1}{M} \sum_{i-1}^M \sum_{j \in B_i} \| \hat{s}_{y_j} - s_{y_j} \|_2^2 \end{equation}\]Predictor의 파라미터 $\phi$와 컨텍스트 인코더의 파라미터 $\theta$는 기울기 기반 최적화를 통해 학습되는 반면, 타겟 인코더의 파라미터 $\bar{\theta}$는 컨텍스트 인코더 파라미터의 exponential moving average (EMA)를 통해 업데이트된다. 타겟 인코더의 EMA 사용은 ViT를 사용하여 JEA를 학습하는 데 필수적인 것으로 입증되었으며 I-JEPA에서도 마찬가지이다.
Experiments
1. Image Classification
ImageNet-1K
다음은 ImageNet-1k에서의 선형 평가 결과이다.
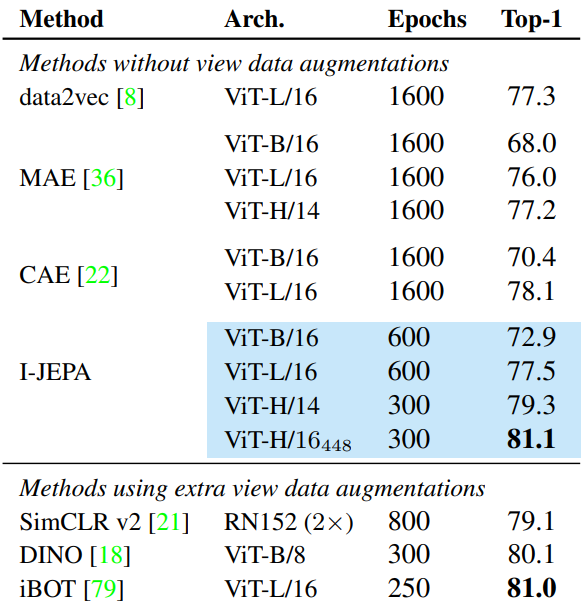
다음은 ImageNet-1k에서 1%의 레이블만 사용한 semi-supervised 평가 결과이다.
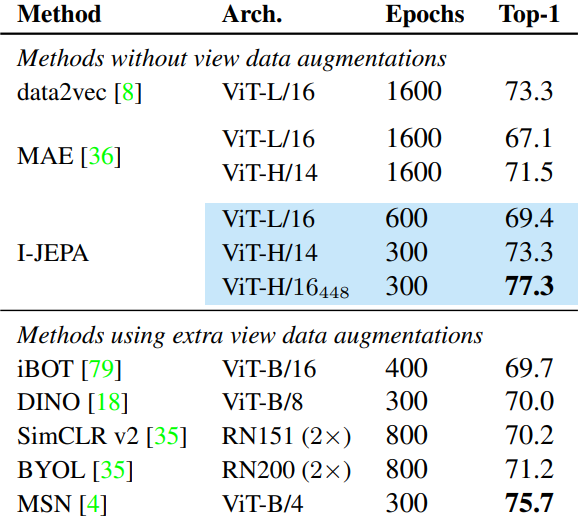
다음은 다운스트림 이미지 분류 task에 대한 선형 평가 결과이다.
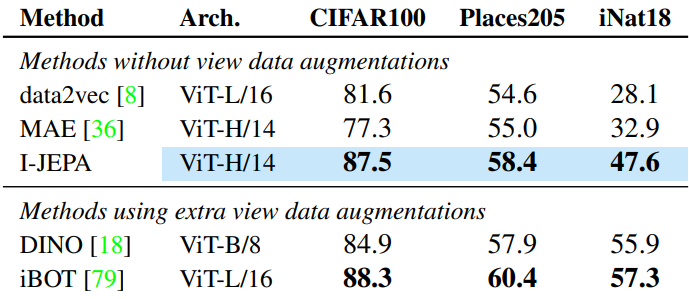
2. Local Prediction Tasks
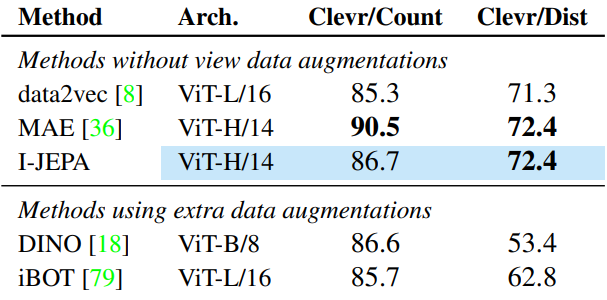
다음은 object counting (Clevr/Count)과 depth prediction (Clevr/Dist)을 포함한 low-level task에 대한 선형 평가 결과이다.
3. Scalability
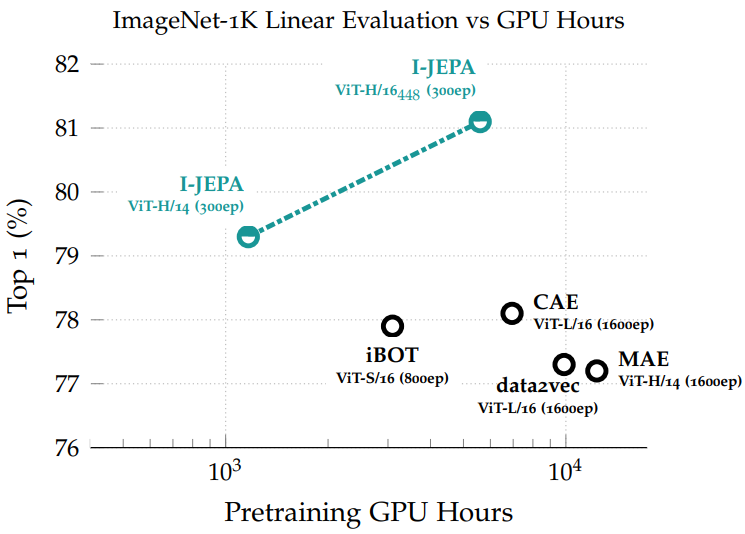
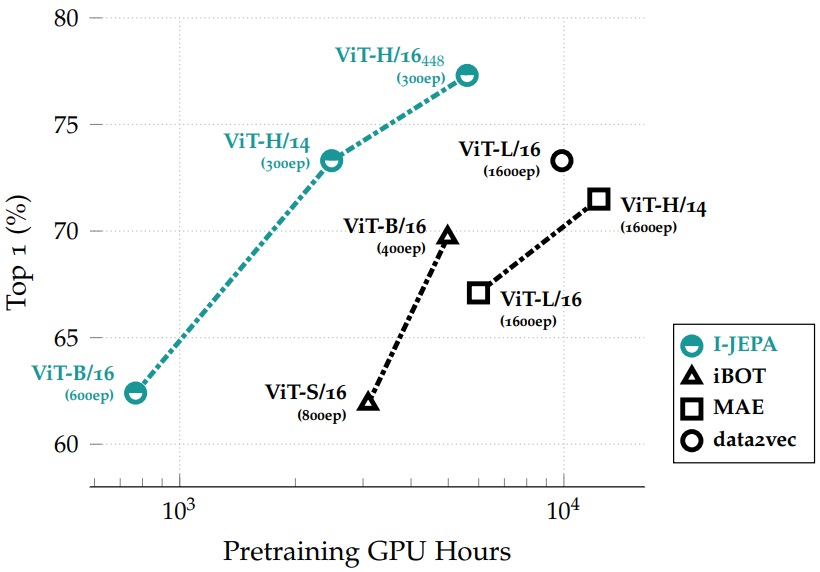
다음은 ImageNet-1k에서 1%의 레이블만 사용한 semi-supervised 평가 결과를 사전 학습 GPU 시간의 함수로 나타낸 그래프이다.
다음은 데이터셋 크기와 모델 크기에 대한 ablation 결과이다.

4. Predictor Visualizations
다음은 I-JEPA predictor 표현을 시각화한 것이다.

5. Ablations
다음은 타겟에 대한 ablation 결과이다.

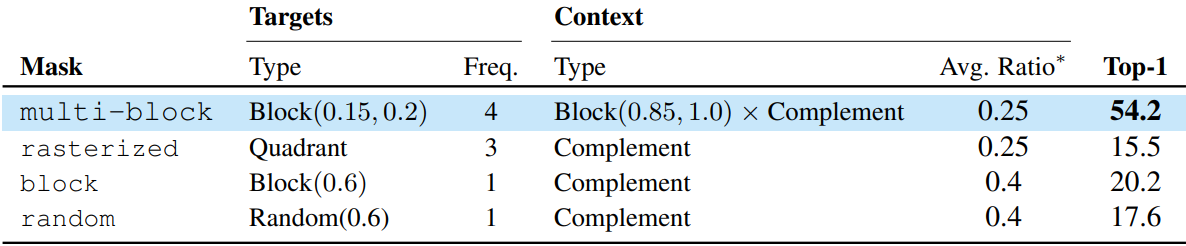
다음은 마스킹 전략에 대한 ablation 결과이다. “Avg. Ratio”는 이미지의 총 패치 수에 대한 컨텍스트 블록의 평균 패치 수이다.