[논문리뷰] Inception Transformer (iFormer)
NeurIPS 2022. [Paper] [Github]
Chenyang Si, Weihao Yu, Pan Zhou, Yichen Zhou, Xinchao Wang, Shuicheng Yan
Sea AI Lab | National University of Singapore
25 May 2022
Introduction
Transformer는 자연어 처리 (NLP) 도메인을 폭풍으로 몰아넣어 기계 번역 및 질문 답변과 같은 많은 NLP task에서 놀라울 정도로 높은 성능을 달성했다. 이것은 주로 self-attention 메커니즘을 사용하여 데이터의 장거리 종속성을 모델링하는 강력한 능력에 기인한다. 여러 연구들은 컴퓨터 비전 분야에 대한 transformer 버전을 조사하게 되었으며 Vision Transformer (ViT)는 선구자이다. 이 아키텍처는 NLP에서 직접 상속되지만 이미지 패치를 입력으로 사용하여 image classification에 적용된다. 나중에 많은 ViT 변형이 개발되어 성능을 향상시키거나 object detection과 segmentation과 같은 더 넓은 범위의 비전 task로 확장되었다.
ViT와 그 변형들은 주로 장면이나 개체의 글로벌한 모양과 구조를 포함하여 시각적 데이터에서 저주파를 캡처할 수 있는 능력이 높지만 주로 로컬한 경계와 텍스처를 포함하여 고주파를 학습하는 데는 그다지 강력하지 않다. 이는 직관적으로 설명할 수 있다. ViT에서 비중첩 패치 토큰 간에 정보를 교환하는 데 사용되는 주요 작업인 self-attention은 글로벌한 연산이며 데이터에서 로컬한 정보 (고주파)보다 글로벌한 정보 (저주파)를 캡처할 수 있는 능력이 훨씬 더 높다.
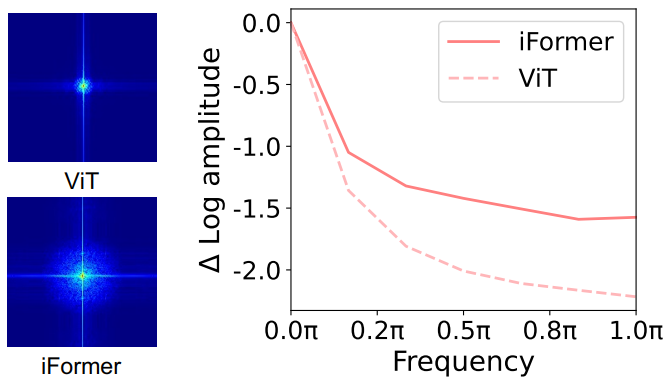
위 그림에서 볼 수 있듯이 푸리에 스펙트럼 (왼쪽)과 푸리에 변환된 feature map의 상대적인 로그 진폭 (오른쪽)은 ViT가 저주파 신호를 잘 포착하지만 고주파 신호는 거의 포착하지 못하는 경향이 있음을 보여준다. 이 관찰은 ViT가 low-pass filter의 특성을 나타내는 경험적 결과와도 일치한다. 이 저주파 선호는 다음과 같은 이유로 ViT의 성능을 손상시킨다.
- 모든 레이어를 채우는 저주파 정보는 로컬 텍스처와 같은 고주파 성분을 저하시키고 ViT의 모델링 능력을 약화시킬 수 있다.
- 고주파 정보는 discriminative하며 classification과 같은 많은 task에 도움이 될 수 있다.
실제로 인간의 시각 시스템은 여러 주파수에서 시각적 기본 feature들을 추출한다. 저주파는 시각적 자극에 대한 글로벌 정보를 제공하고 고주파는 이미지의 로컬 공간 변화를 전달한다. 따라서 시각적 데이터에서 고주파와 저주파를 모두 캡처하기 위한 새로운 ViT 아키텍처를 개발해야 한다.
CNN은 일반적인 비전 task를 위한 가장 기본적인 backbone이다. ViT와 달리 receptive field 내의 로컬한 convolution을 통해 더 많은 로컬 정보를 다루므로 고주파 표현을 효과적으로 추출한다. 최근 연구에서는 상호보완적 이점을 고려하여 CNN과 ViT를 통합했다. 일부 방법은 convolution과 attention layer를 직렬 방식으로 쌓아 로컬 정보를 글로벌 컨텍스트에 주입하였다. 불행하게도 이 직렬 방식은 하나의 레이어에서 글로벌 또는 로컬 중 하나의 의존성 (dependency) 유형만 모델링하고 로컬한 모델링 중에 글로벌 정보를 폐기하거나 글로벌한 모델링 중에 로컬 정보를 폐기한다. 다른 연구들은 입력의 글로벌 및 로컬 의존성을 동시에 학습하기 위해 병렬 attention과 convolution을 채택하였다. 그러나 채널의 일부는 로컬 정보 처리용이고 다른 하나는 글로벌 모델링용이므로 현재 병렬 구조는 각 분기에서 모든 채널을 처리할 경우 정보 중복성이 있다.
본 논문은 이 문제를 해결하기 위해 고주파 신호를 캡처하는 CNN의 장점을 ViT에 접목한 간단하고 효율적인 Inception Transformer (iFormer)를 제안한다. iFormer의 핵심 구성 요소는 Inception token mixer이다. 이 Inception mixer는 데이터에서 고주파와 저주파를 모두 캡처하여 주파수 스펙트럼에서 ViT의 인식 능력을 강화하는 것을 목표로 한다. 이를 위해 Inception mixer는 먼저 채널 차원을 따라 입력 feature를 분할한 다음 분할된 성분들을 각각 고주파 믹서와 저주파 믹서에 공급한다. 여기서 고주파 믹서는 max-pooling 연산과 병렬 convolution 연산으로 구성되는 반면 저주파 믹서는 ViT에서 self-attention으로 구현된다. 이러한 방식으로 iFormer는 해당 채널에서 특정 주파수 정보를 효과적으로 캡처할 수 있으므로 일반 ViT와 비교하여 넓은 주파수 범위 내에서 보다 포괄적인 feature를 학습할 수 있다.
또한 하위 레이어는 종종 더 많은 로컬 정보가 필요한 반면 상위 레이어는 더 많은 글로벌 정보를 원한다. 이는 인간의 시각 시스템과 마찬가지로 고주파 성분의 디테일이 하위 레이어에서 시각적 기본 feature를 캡처하고 점진적으로 로컬 정보를 수집하여 입력을 전반적으로 이해하는 데 도움이 되기 때문이다. 이에 영감을 받아 저자들은 frequency ramp 구조를 설계하였다. 특히, 하위 레이어에서 상위 레이어로 점차 더 많은 채널 차원을 저주파 믹서에 공급하고 더 적은 채널 차원을 고주파 믹서에 공급한다. 이 구조는 모든 레이어에서 고주파 및 저주파 성분을 절충할 수 있다.
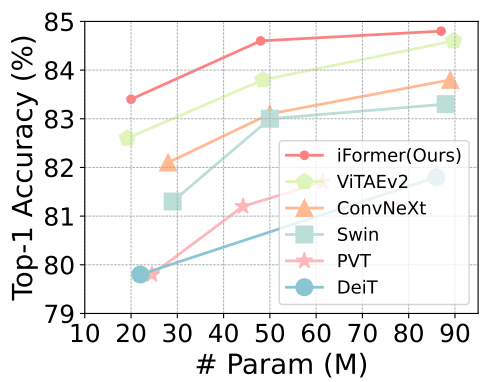
iFormer는 image classification, object detection, segmentation을 포함한 여러 비전 task에서 SOTA ViT와 CNN을 능가한다. 위 그래프에서 볼 수 있듯이 ImageNet-1K에서 iFormer는 다양한 모델 크기로 인기 있는 프레임워크보다 일관되게 개선되었다. 또한, iFormer는 COCO detection과 ADE20K segmentation에 대한 최근 프레임워크보다 성능이 뛰어나다.
Method
1. Revisit Vision Transformer
먼저 Vision Transformer를 다시 살펴보자. 비전 task의 경우 transformer는 먼저 입력 이미지를 일련의 토큰으로 분할하고 각 패치 토큰은 \(\{x_1, x_2, \cdots, x_N\}\) 또는 $X \in \mathbb{R}^{N \times C}$로 표시되는 hidden 표현 벡터로 project된다. 여기서 $N$은 패치 토큰의 수이고 $C$는 feature의 차원이다. 그런 다음 모든 토큰이 위치 임베딩과 결합되어 Multi-Head Self-Attention (MSA)과 Feed-Forward Network (FFN)을 포함하는 Transformer 레이어로 공급된다.
MSA에서 attention 기반 믹서는 모든 패치 토큰 간에 정보를 교환하므로 모든 레이어에서 글로벌 의존성을 집계하는 데 강력하게 집중한다. 그러나 글로벌 정보의 과도한 전파는 저주파 표현을 강화할 것이다. 이는 실제로 ViT의 성능을 손상시킨다. 로컬 텍스처와 같은 고주파 성분을 악화시키고 ViT의 모델링 능력을 약화시킬 수 있기 때문이다. 시각적 데이터에서 고주파 정보도 discriminative하며 많은 task에 도움이 될 수 있다. 따라서 본 논문은 이 문제를 해결하기 위해 아래 그림과 같이 간단하고 효율적인 Inception Transformer를 제안하였으며, Inception mixer와 frequency ramp 구조라는 두 가지 주요 신규 기능이 있다.
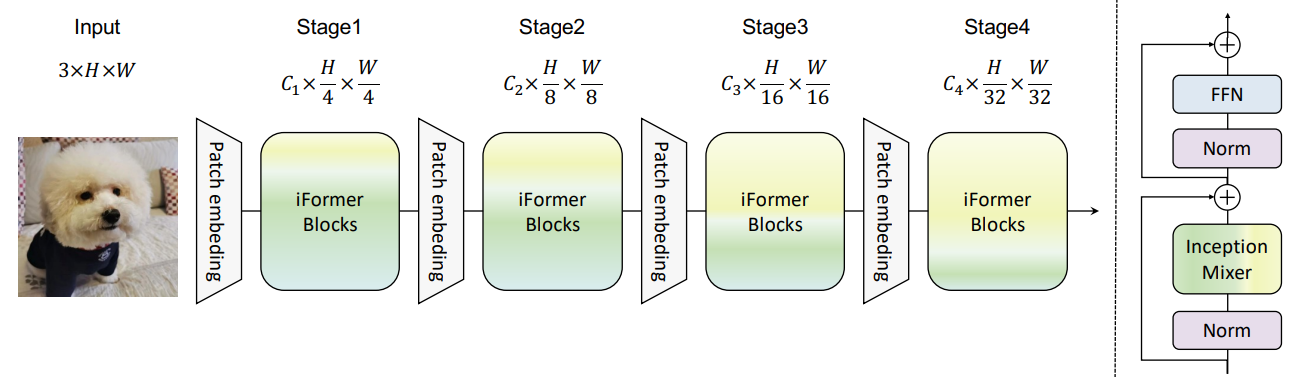
2. Inception token mixer

본 논문은 transformer에서 고주파 표현을 추출하기 위하여 CNN의 강력한 능력을 접목하기 위한 Inception mixer를 제안하였다. 자세한 아키텍처는 위 그림에 나와 있다. 토큰 믹서는 여러 분기가 있는 Inception 모듈에서 많은 영감을 받았기 때문에 “Inception”이라는 이름을 사용한다. 이미지 토큰을 MSA mixer에 직접 공급하는 대신 Inception mixer는 먼저 이미지 토큰을 분할한다. 채널 차원을 따라 입력 feature를 입력 한 다음 분할된 성분들을 고주파 믹서와 저주파 믹서에 각각 공급한다. 여기서 고주파 믹서는 max-pooling 연산과 병렬 convolution 연산으로 구성되며 저주파 믹서는 self-attention으로 구현된다.
입력 feature map $X \in \mathbb{R}^{N \times C}$가 주어지면 채널 차원을 따라 $X$를 $X_h \in \mathbb{R}^{N \times C_h}$와 $X_l \in \mathbb{R}^{N \times C_l}$로 분해한다. 여기서 $C_h + C_l = C$이다. 그런 다음 $X_h$와 $X_l$은 각각 고주파 믹서와 저주파 믹서에 할당된다.
High-frequency mixer
저자들은 maximum filter의 예리한 민감도와 convolution 연산의 세부적인 인식을 고려하여 고주파 성분 학습을 위한 병렬 구조를 제안하였다. 입력 $X_h$를 채널을 따라 $X_{h1} \in \mathbb{R}^{N \times \frac{C_h}{2}}$와 $X_{h2} \in \mathbb{R}^{N \times \frac{C_h}{2}}$로 나눈다. $X_{h1}$은 max-pooling과 linear layer로 임베딩되고 $X_{h2}$는 linear layer와 depthwise convolution layer로 공급된다.
\[\begin{equation} Y_{h1} = \textrm{FC} (\textrm{MaxPool} (X_{h1})) \\ Y_{h2} = \textrm{DwConv} (\textrm{FC} (X_{h2})) \end{equation}\]여기서 $Y_{h1}$와 $Y_{h2}$는 고주파 믹서의 출력이다. 저주파 및 고주파 믹서의 출력은 채널 차원을 따라 concat된다.
\[\begin{equation} Y_c = \textrm{Concat} (Y_l, Y_{h1}, Y_{h2}) \end{equation}\]$Y_l$ 계산 시 업샘플링 연산은 다른 포인트와 관계없이 보간할 각 위치에 가장 가까운 포인트의 값을 선택하므로 인접한 토큰 사이에 과도한 smoothness가 발생한다. 저자들은 이 문제를 극복하기 위해 퓨전 모듈을 설계하였다. 즉, 이전 transformer에서와 같이 위치별로 작동하는 cross-channel linear layer를 유지하면서 패치 간에 정보를 교환하는 depthwise convolution이다. 최종 출력은 다음과 같이 표현할 수 있다.
\[\begin{equation} Y = \textrm{FC} (Y_c + \textrm{DwConv} (Y_c)) \end{equation}\]일반 transformer와 마찬가지로 iFormer에는 Feed-Forward Network (FFN)이 장착되어 있으며 위의 Inception token mixer (ITM)도 통합되어 있다. LayerNorm (LN)은 ITM과 FFN 전에 먼저 적용된다. 따라서 Inception Transformer 블록은 다음과 같이 정의된다.
\[\begin{equation} Y = X + \textrm{ITM} (\textrm{LN} (X)) \\ H = Y + \textrm{FFN} (\textrm{LN} (Y)) \end{equation}\]Low-frequency mixer
저주파 믹서에 대한 모든 토큰 간에 정보를 전달하기 위해 multi-head self-attention (MSA)을 사용한다. 글로벌 표현을 학습하기 위한 attention의 강력한 능력에도 불구하고 feature map의 큰 해상도는 하위 레이어에서 많은 계산 비용을 초래한다. 따라서 attention 연산 작업 전에 $X_l$의 공간 규모를 줄이기 위해 average pooling layer를 사용하고 attention 후에 원래 공간 차원을 복구하기 위해 업샘플링 레이어를 사용한다. 이 디자인은 계산 오버헤드를 크게 줄이고 attention 연산이 글로벌 정보를 포함하는 데 집중하도록 한다. 이 분기는 다음과 같이 정의할 수 있다.
\[\begin{equation} Y_l = \textrm{Upsample} (\textrm{MSA} (\textrm{AvePooling} (X_l))) \end{equation}\]여기서 $Y_l$은 저주파 믹서의 출력이다. 풀링 레이어와 업샘플링 레이어의 커널 크기와 보폭은 처음 두 stage에서만 2로 설정된다.
3. Frequency ramp structure
일반적인 비전 프레임워크에서 하위 레이어는 고주파수 디테일을를 캡처하는 데 더 많은 역할을 수행하는 반면 상위 레이어는 저주파 글로벌 정보, 즉 ResNet의 계층적 표현을 모델링하는 데 더 많은 역할을 한다. 인간과 마찬가지로 고주파 성분의 디테일을 캡처함으로써 하위 레이어는 시각적 기본 feature를 캡처할 수 있으며 점진적으로 로컬 정보를 수집하여 입력을 전체적으로 이해할 수 있다. 저자들은 이에 영감을 받아 상위 레이어로 갈수록 점진적으로 더 많은 채널 차원을 저주파 믹서에 할당하고 고주파 믹서에 더 적은 채널 크기를 남기는 frequency ramp 구조를 설계하였다. 특히, backbone에는 채널 및 공간 차원이 다른 4개의 stage가 있다. 각 블록에 대해 고주파 성분과 저주파 성분, 즉 $\frac{C_h}{C} + \frac{C_l}{C} = 1$인 $\frac{C_h}{C}$와 $\frac{C_l}{C}$의 균형을 더 잘 맞추기 위해 채널 비율을 정의한다. 제안된 frequency ramp 구조에서 $\frac{C_h}{C}$는 얕은 층에서 깊은 층으로 갈수록 점진적으로 감소하며, $\frac{C_l}{C}$는 점진적으로 증가한다. 따라서 유연한 frequency ramp 구조를 통해 iFormer는 모든 레이어에서 고주파 성분과 저주파 성분을 효과적으로 절충할 수 있다.
Experiments
1. Results on image classification
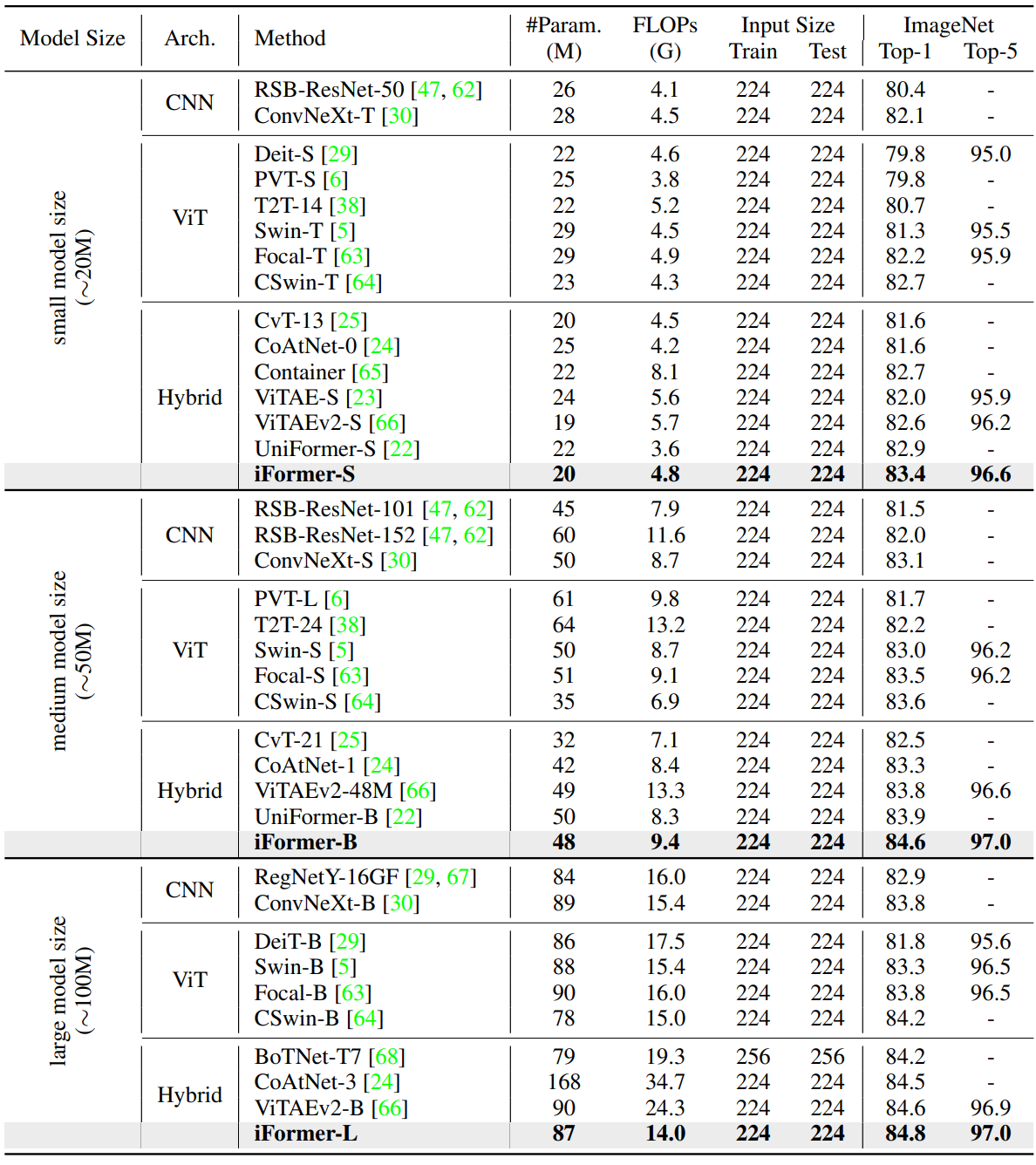
다음은 ImageNet-1K에서의 여러 모델들을 비교한 표이다.
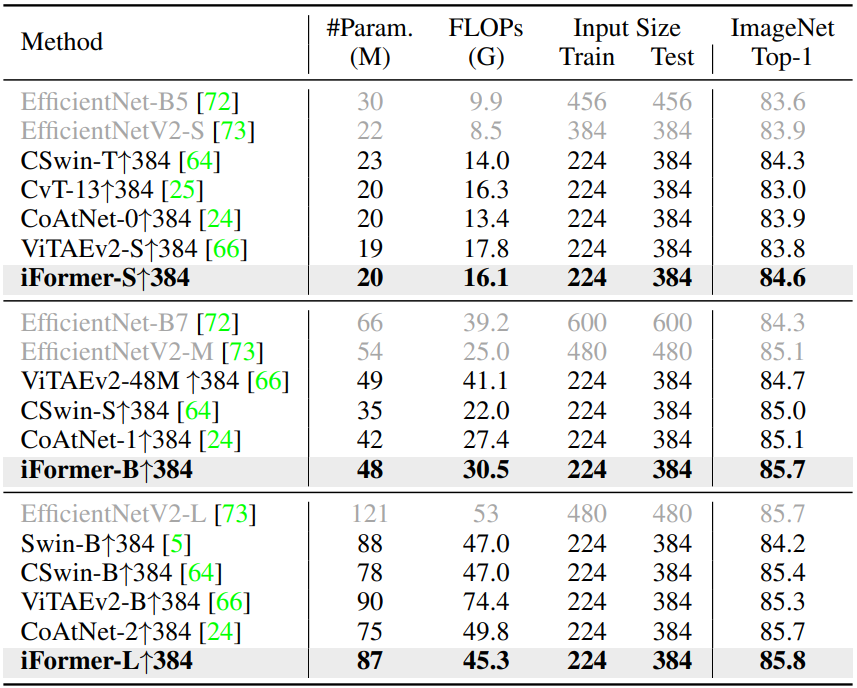
다음은 더 큰 해상도에서의 fine-tuning 결과를 비교한 표이다.
2. Results on object detection and instance segmentation
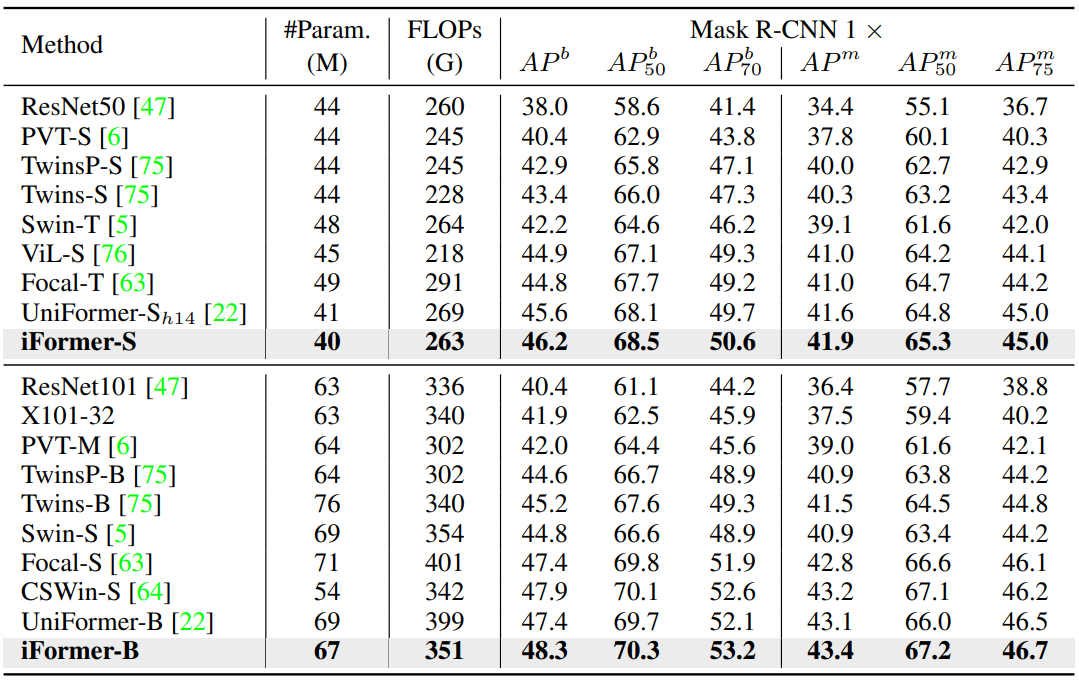
다음은 COCO val2017에서의 object detection과 instance segmentation 결과를 비교한 표이다.
3. Results on semantic segmentation
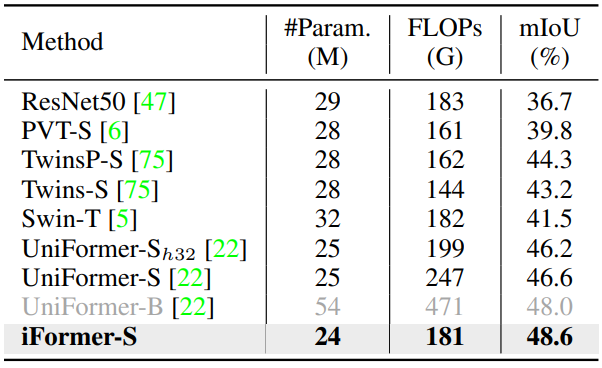
다음은 ADE20K에서 semantic FPN을 사용한 semantic segmentation 결과이다.
4. Ablation study and visualization
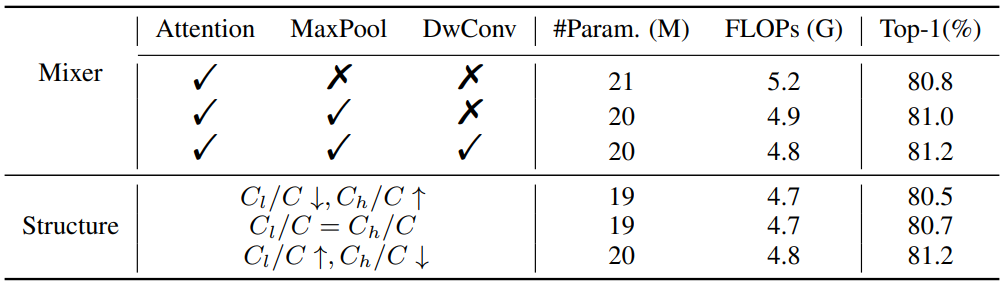
다음은 ImageNet-1K에서의 Inception mixer와 frequency ramp 구조에 대한 ablation study 결과이다.
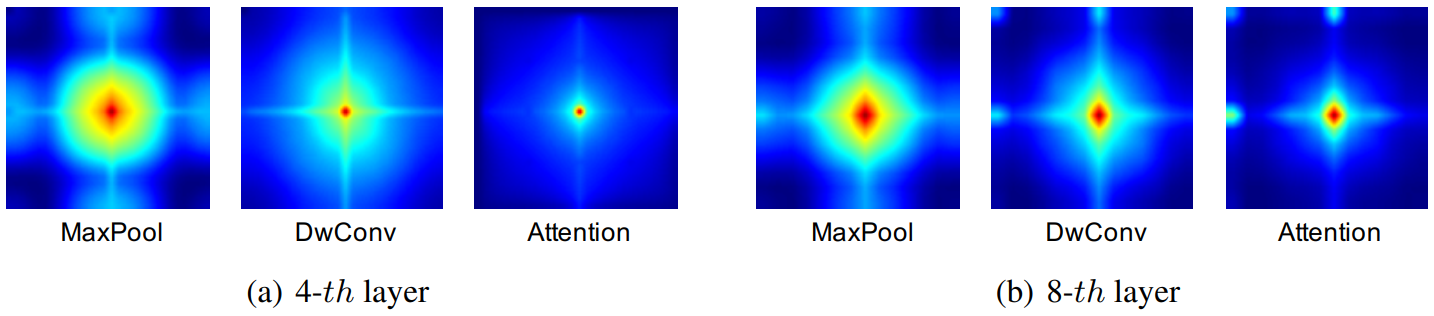
다음은 Inception mixer 내의 MaxPool, DwConv, Attention의 푸리에 스펙트럼이다.
다음은 ImageNet에서 학습된 Swin-T와 iFormer-S의 Grad-CAM activation map이다.

Limitation
- Frequency ramp 구조에서 수동으로 정의된 채널 비율, 즉 각 iFormer 블록에 대한 $\frac{C_h}{C}$와 $\frac{C_l}{C}$가 필요하므로 다양한 task에서 더 잘 정의하려면 풍부한 경험이 필요하다.
- 계산 상의 제약으로 인해 ImageNet-21K와 같은 대규모 데이터셋에서는 학습되지 않는다.