[논문리뷰] HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing
CVPR 2022. [Paper] [Page] [Github]
Yuval Alaluf, Omer Tov, Ron Mokady, Rinon Gal, Amit H. Bermano
Blavatnik School of Computer Science, Tel Aviv University
30 Nov 2021

Introduction
GAN, 특히 StyleGAN은 이미지 합성의 표준이 되었다. 의미적으로 풍부한 latent 표현 덕분에 많은 task에서 latent space 조작을 통해 다양하고 표현적인 편집을 용이하게 했다. 그러나 실제 애플리케이션에 이러한 접근 방식을 채택하는 데 있어 중요한 문제는 실제 이미지를 편집하는 능력이다. 실제 사진을 편집하려면 먼저 일반적으로 GAN inversion이라고 하는 프로세스를 통해 해당 latent 표현을 찾아야 한다. Inversion 프로세스는 잘 연구된 문제이지만 여전히 open chanllenge이다.
최근 연구들에서는 왜곡과 편집 가능성 사이의 trade-off를 보여주었다. 이미지를 StyleGAN의 latent space의 잘 작동하는 영역으로 invert시키고 우수한 편집 가능성을 얻을 수 있다. 그러나 이러한 영역은 일반적으로 표현력이 떨어지므로 원본 이미지로 덜 충실하게 재구성된다. 최근 Pivotal Tuning Inversion (PTI) 논문에서는 inversion에 대한 다른 접근 방식을 고려하여 이러한 trade-off를 피할 수 있음을 보여주었다. 입력 이미지를 가장 정확하게 재구성하는 latent code를 검색하는 대신 latent space의 잘 작동하는 영역에 대상 ID를 삽입하기 위해 generator를 fine-tuning한다. 그렇게 함으로써 높은 수준의 편집 가능성을 유지하면서 state-of-the-art 재구성을 보여주었다. 그러나 이 접근 방식은 비용이 많이 드는 generator의 이미지별 최적화에 의존하며 이미지당 최대 1분이 소요된다.
유사한 시간-정확도 trade-off가 고전적인 inversion 접근법에서 관찰될 수 있다. 스펙트럼의 한쪽 끝에서 latent vector 최적화 접근 방식은 인상적인 재구성을 달성하지만 규모 면에서 비실용적이어서 이미지당 몇 분이 걸린다. 반면에 인코더 기반 접근 방식은 풍부한 데이터셋을 활용하여 이미지에서 latent 표현으로의 매핑을 학습한다. 이러한 접근 방식은 순식간에 작동하지만 일반적으로 재구성에 덜 충실하다.
본 논문에서는 PTI의 generator 튜닝 기술을 인코더 기반 접근 방식에 적용하여 인터랙티브한 애플리케이션 영역으로 가져오는 것을 목표로 한다. 주어진 입력 이미지에 대해 generator 가중치를 세분화하는 방법을 학습하는 hypernetwork를 도입하여 이를 수행한다. Hypernetwork는 각 StyleGAN의 convolution layer에 대해 가벼운 feature extractor (ex. ResNet)와 refinement block의 집합으로 구성된다. 각 refinement block은 해당 layer의 convolution filter 가중치에 대한 offset을 예측하는 작업을 담당한다.
이러한 네트워크를 설계하는 데 있어 주요 과제는 정제해야 하는 각 convolution block을 구성하는 파라미터의 수이다. 각 파라미터에 대한 offset을 단순하게 예측하려면 30억 개 이상의 파라미터가 있는 hypernetwork가 필요하다. 이러한 복잡성을 줄이기 위한 몇 가지 방법을 탐색한다.
- 파라미터 간 offset 공유
- 서로 다른 hypernetwork layer 간에 네트워크 가중치 공유\
- depth-wise convolution에서 영감을 받은 접근 방식
마지막으로, hypernetwork를 통과하는 적은 수의 forward pass를 통해 원하는 offset을 점진적으로 예측하는 반복적인 정제 방식을 통해 재구성이 더욱 개선될 수 있음을 관찰한다. 그렇게 함으로써 본 논문의 접근 방식인 HyperStyle은 본질적으로 효율적인 방식으로 generator를 최적화하는 방법을 배운다.
HyperStyle과 기존 generator 튜닝 방식의 관계는 인코더와 최적화 inversion 방식의 관계와 유사하다고 볼 수 있다. 인코더가 학습된 네트워크를 통해 원하는 latent code를 찾는 것처럼 hypernetwork는 이미지별 최적화 없이 원하는 generator를 효율적으로 찾는다.
Method
1. Preliminaries
GAN inversion task를 해결할 때 본 논문의 목표는 주어진 대상 이미지 $x$에 대한 재구성 왜곡을 최소화하는 latent code를 식별하는 것이다.
\[\begin{equation} \hat{w} = \underset{w}{\arg \min} \mathcal{L} (x, G(w; \theta)) \end{equation}\]여기서 $G(w; \theta)$는 사전 학습된 generator $G$에 의해 latent $w$로 생성된 이미지이다. $\mathcal{L}$은 loss이며, 일반적으로 $L_2$나 LPIPS를 사용한다. 위 식을 최적화로 푸는 것은 일반적으로 이미지당 몇 분이 소요된다. Inference 시간을 줄이기 위해서는 인코더 $E$를 대규모 이미지셋 \(\{x^i\}_{i=1}^N\)에서
\[\begin{equation} \sum_{i=1}^N \mathcal{L} (x^i, G (E (x^i); \theta)) \end{equation}\]을 최소화하도록 학습시킬 수 있다. 이로 인해 빠른 inference 절차 $\hat{w} = E(x)$가 생성된다. Latent 조작 $f$는 편집된 이미지 $G(f(\hat{w}); \theta)$를 얻기 위해 inverted code $\hat{w}$에 적용될 수 있다.
최근에 PTI는 StyleGAN의 latent space의 잘 작동하는 영역에 새로운 ID를 주입할 것을 제안하였다. 대상 이미지가 주어지면 최적화 프로세스를 사용하여 대략적인 재구성으로 이어지는 초기 잠재 \(\hat{w}_{init} \in \mathcal{W}\)를 찾는다. 그런 다음 동일한 latent가 특정 이미지를 더 잘 재구성하도록 generator 가중치가 조정되는 fine-tuning이 이어진다.
\[\begin{equation} \hat{\theta} = \underset{\theta}{\arg \min} \mathcal{L}(x, G(\hat{w}_{init}; \theta)) \end{equation}\]여기서 $\hat{\theta}$는 새로운 generator 가중치를 나타낸다. 최종 재구성은 초기 inversion과 수정된 가중치를 활용하여 \(\hat{y} = G(\hat{w}_{init}; \hat{\theta})\)으로 얻을 수 있다.
2. Overview
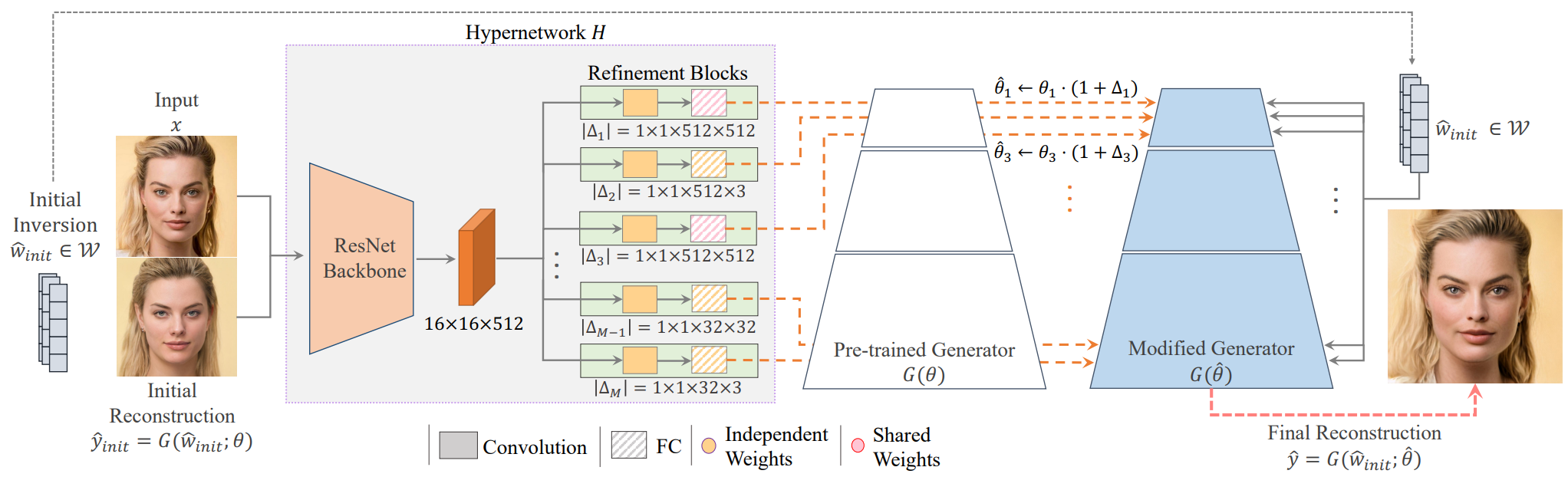
HyperStyle은 위 그림 2와 같이 generator에 수정된 가중치를 효율적으로 제공하여 ID 주입 연산을 수행하는 것을 목표로 한다. 이미지 $x$, 가중치 $\theta$로 parameterize된 generator $G$, 초기 inverted latent code \(\hat{w}_{init} \in \mathcal{W}\)로 시작한다. 이러한 가중치와 \(\hat{w}_{init}\)를 사용하여 초기 재구성 이미지 \(\hat{y}_{init} = G(\hat{w}_{init}; \theta)\)를 생성한다. 이러한 latent code를 얻기 위해 상용 인코더를 사용한다.
본 논문의 목표는 $\hat{\theta}$에 대한 목적 함수를 최소화하는 새로운 가중치 집합을 예측하는 것이다. 이를 위해 이러한 가중치를 예측하는 hypernetwork $H$를 사용한다. Hypernetwork가 원하는 수정을 추론하는 데 도움을 주기 위해 대상 이미지 $x$와 초기 대략적인 이미지 재구성 \(\hat{y}_{init}\)을 모두 입력으로 전달한다.
따라서 예측된 가중치는 \(\hat{\theta} = H(\hat{y}_{init}, x)\)로 주어진다. 재구성의 왜곡을 최소화하기 위해 대규모 이미지 컬렉션에 대해 $H$를 학습시킨다.
\[\begin{equation} \sum_{i=1}^N \mathcal{L} (x^i, G (\hat{w}_{init}^i; H (\hat{y}_{init}^i, x^i))) \end{equation}\]Hypernetwork의 예측이 주어지면 최종 재구성은 \(\hat{y} = G(\hat{w}_{init}; \hat{\theta})\)로 얻을 수 있다.
초기 latent code는 StyleGAN latent space의 잘 작동하는 (즉, 편집 가능한) 영역 내에 있어야 한다. 이를 위해 사전 학습된 e4e 인코더를 hypernetwork 학습 내내 고정된 $\mathcal{W}$에 사용한다. 이러한 code를 조정하면 원래 generator에 사용된 것과 동일한 편집 기술을 적용할 수 있다.
실제로 새로운 generator 가중치를 직접 예측하는 대신 hypernetwork는 원래 가중치에 대한 offset 집합을 예측한다. 또한 ReStyle을 따르고 hypernetwork를 통해 적은 수의 pass (ex. 5)를 수행하여 예측된 가중치 offset을 점진적으로 fine-tuning하여 더 높은 충실도의 inversion을 생성한다.
어떤 의미에서 HyperStyle은 generator를 최적화하는 방법을 배우는 것으로 볼 수 있지만 효율적인 방식으로 수행한다. 또한 generator를 수정하는 방법을 학습함으로써 HyperStyle은 영역을 벗어난 경우에도 이미지를 generator에 가장 잘 투사하는 방법을 결정할 수 있는 더 많은 자유를 얻었다. 이는 기존 latent space로의 인코딩으로 제한되는 표준 인코더와 대조된다.
3. Designing the HyperNetwork
StyleGAN generator는 약 3천만 개의 파라미터를 포함한다. 한편으로, hypernetwork가 표현력이 있어서 재구성을 향상시키기 위해 이러한 파라미터를 제어할 수 있기를 바란다. 반면에 너무 많은 파라미터를 제어하면 적용할 수 없는 네트워크가 되어 학습에 상당한 리소스가 필요하다. 따라서 hypernetwork의 설계는 표현력과 학습 가능한 파라미터의 수 사이의 섬세한 균형이 필요하다.
StyleGAN의 $l$번째 convolution layer의 가중치를 \(\theta_l = \{\theta_l^{i,j}\}_{i,j = 0}^{C_l^{out}, C_l^{in}}\)으로 표시한다. 여기서 $\theta_l^{i,j}$는 $i$ 번째 filter에서 $j$번째 채널의 가중치를 나타낸다. $C_l^{out}$은 각각 $C_l^{in}$ 채널을 포함하는 총 filter 수를 나타낸다. $M$을 총 레이어 수라고 하면 generator 가중치는 \(\{\theta_l\}_{l=1}^M\)로 표시된다. Hypernetwork는 각 수정된 layer에 대해 offset $\Delta_l$을 생성한다. 그런 다음 이러한 offset에 해당 layer 가중치 $\theta_l$을 곱하고 channel-wise로 원래 가중치에 추가한다.
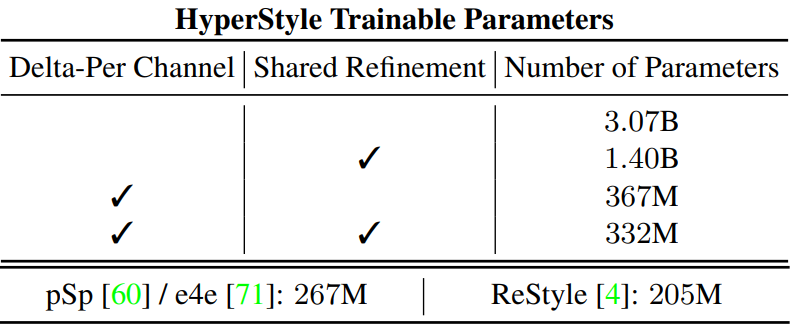
\[\begin{equation} \hat{\theta}_{l}^{i, j} = \theta_l^{i,j} \cdot (1 + \Delta_l^{i,j}) \end{equation}\]채널당 offset을 학습하면 각 generator 파라미터에 대한 offset을 예측하는 것과 비교하여 hypernetwork 파라미터의 수가 88% 감소한다.
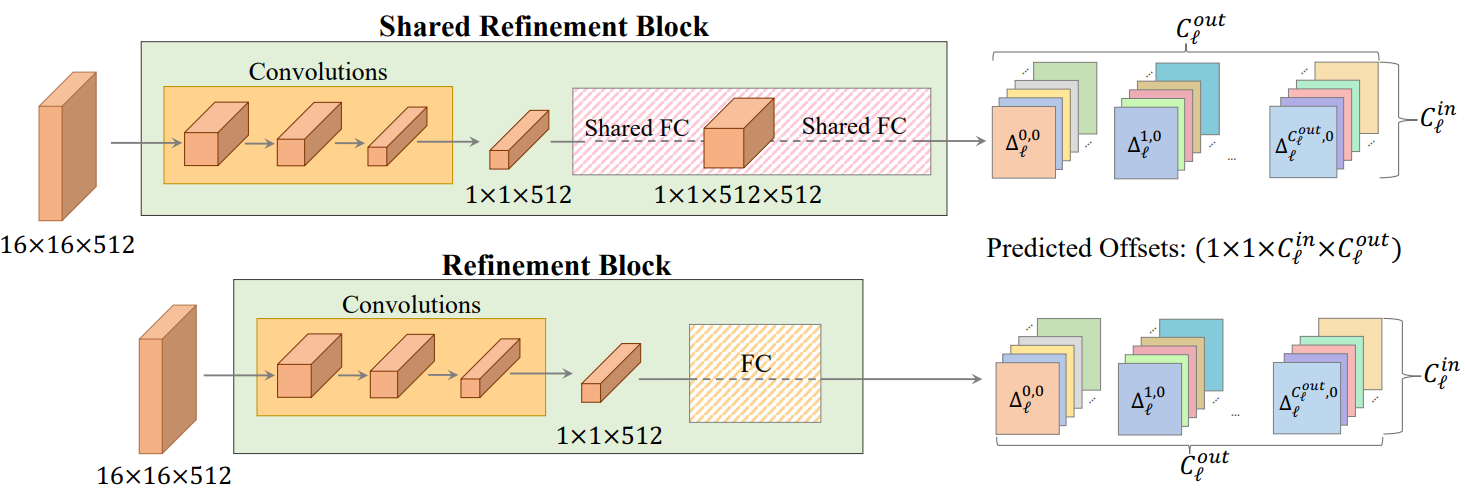
입력 이미지를 처리하기 위해 6채널 입력 $x^i, y_{init}^i$를 받고 16$\times$16$\times$512 feature map을 출력하는 ResNet34 백본을 통합한다. 이 공유 backbone 다음에는 각각 단일 generator layer의 변조를 생성하는 refinement block의 집합이 이어진다. 크기 $k_l \times k_l \times C_l^{in} \times C_l^{out}$의 파라미터 $\theta_l$이 있는 레이어 $l$을 생각해보자. 여기서 $k_l$은 커널 크기이다. 해당 refinement block은 backbone에서 추출한 feature map을 받고 $1 \times 1 \times C_l^{in} \times C_l^{out}$ 크기의 offset을 출력한다. Offset은 $\theta_l$의 $k_l \times k_l$ 커널 차원과 일치하도록 복제된다. 마지막으로 레이어 $l$의 새로운 가중치를 업데이트한다. Refinement block은 위 그림에 설명되어 있다.
학습 가능한 파라미터의 수를 더 줄이기 위해 원본 hypernetwork에서 영감을 받은 Shared Refinement Block을 도입한다. 이러한 출력 head는 입력 feature map을 다운 샘플링하는 데 사용되는 독립적인 convolution layer로 구성된다. 그런 다음 여러 generator layer에서 공유되는 두 개의 fully-connected layer가 이어진다. 여기서 fully-connected layer의 가중치는 차원이 $3 \times 3 \times 512 \times 512$인 toRGB가 아닌 layer, 즉 가장 큰 generator convolutional block에서 공유된다. 이를 통해 출력 head 간의 정보 공유를 허용하여 재구성 품질을 향상시킨다.
Shared Refinement Blocks와 채널별 예측을 결합한 최종 구성에는 naive한 하이퍼네트워크보다 27억 개 적은 파라미터(~89%)가 포함된다. 다양한 hypernetwork 변형의 총 파라미터 수는 아래 표와 같다.
Which layers are refined?
정제할 레이어를 선택하는 것이 매우 중요하다. 보다 의미 있는 generator 가중치에 hypernetwork를 집중시키면서 출력 차원을 줄일 수 있다. 한 번에 하나의 ID를 invert하므로 affine transformation layer에 대한 모든 변경 사항은 convolution 가중치의 각 재조정으로 재생산된다. 또한 저자들은 toRGB layer를 변경하면 GAN의 편집 능력이 손상된다는 사실을 발견했다. 저자들은 toRGB layer를 수정하면 픽셀별 텍스처와 색상이 주로 변경되고 포즈와 같은 글로벌한 편집에서 잘 변환되지 않는 변경 사항이 있다고 가정한다. 따라서 toRGB가 아닌 convolution만 수정하도록 제한한다.
마지막으로, Generator layer를 각각 생성된 이미지의 서로 다른 측면을 제어하는 coarse, middle, fine의 세 가지 디테일 레벨로 나눈다. 초기 inversion은 대략적인 디테일을 캡처하는 경향이 있으므로 hypernetwork를 middle 및 fine generator layer에 대한 출력 offset으로 추가로 제한한다.
4. Iterative Refinement
Inversion 품질을 더욱 향상시키기 위해 Only a Matter of Style 논문에서 제안한 반복적인 정제 방식을 채택한다. 이를 통해 단일 이미지 inversion을 위해 hypernetwork를 통해 여러 pass를 수행할 수 있다. 추가된 각 단계를 통해 hypernetwork는 예측된 가중치 offset을 점진적으로 fine-tuning하여 더 강력한 표현력과 더 정확한 inversion을 얻을 수 있다.
T번의 pass를 수행한다. 첫 번째 pass의 경우 초기 재구성 \(\hat{y}_0 = G(\hat{w}_{init}; \theta)\)를 사용한다. 각 refinement step $t ≥ 1$에 대해 수정된 가중치 $\hat{\theta}_t$와 업데이트된 재구성 \(\hat{y}_t = G(\hat{w}_{init}; \hat{\theta}_t)\)를 얻는 데 사용되는 offset 집합 \(\Delta_t = H(\hat{y}_{t-1}, x)\)를 예측한다. Step $t$에서의 가중치는 모든 이전 step에서 누적된 변조로 정의된다.
\[\begin{equation} \hat{\theta}_{l, t} := \theta \cdot (1 + \sum_{i=1}^t \Delta_{l, i}) \end{equation}\]Refinement step 수는 학습 중에 $T = 5$로 설정된다. 각 refinement step에서 loss를 계산한다. \(\hat{w}_{init}\)은 반복 프로세스 중에 고정된 상태로 유지된다. 최종 반전 $\hat{y}$는 마지막 step에서 얻은 재구성이다.
5. Training Losses
인코더 기반 방법과 유사하게 학습은 이미지 space 재구성 목적 함수에 따라 진행된다. 픽셀별 $L_2$ loss와 LPIPS perceptual loss의 가중합을 사용한다. 얼굴 도메인의 경우 얼굴 신원을 보존하기 위해 사전 학습된 얼굴 인식 네트워크를 사용하여 신원 기반 유사성 loss을 추가로 적용한다. 얼굴이 아닌 도메인에 대해 MoCo 기반 유사성 loss를 적용한다. 최종 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_2 (x, \hat{y}) + \lambda_\textrm{LPIPS} \mathcal{L}_\textrm{LPIPS} (x, \hat{y}) + \lambda_{sim} \mathcal{L}_{sim} (x, \hat{y}) \end{equation}\]Experiments
- 데이터셋: FFHQ (train), CelebA-HQ (test), Stanford Cars, AFHQ Wild
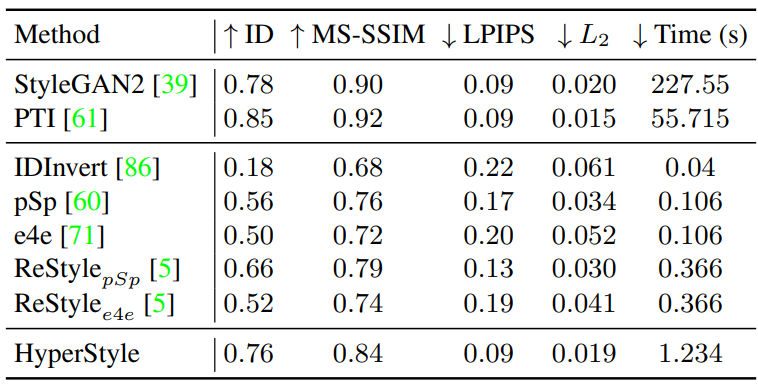
1. Reconstruction Quality
Qualitative Evaluation

Quantitative Evaluation
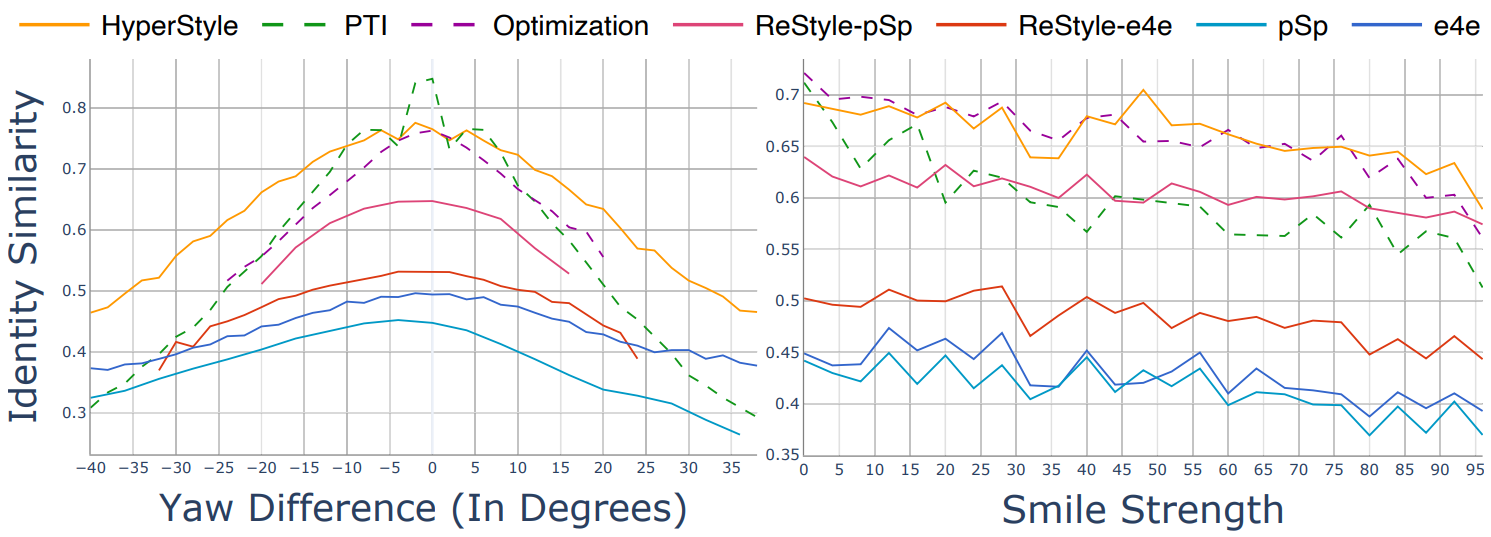
2. Editability via Latent Space Manipulations
Qualitative Evaluation

Quantitative Evaluation
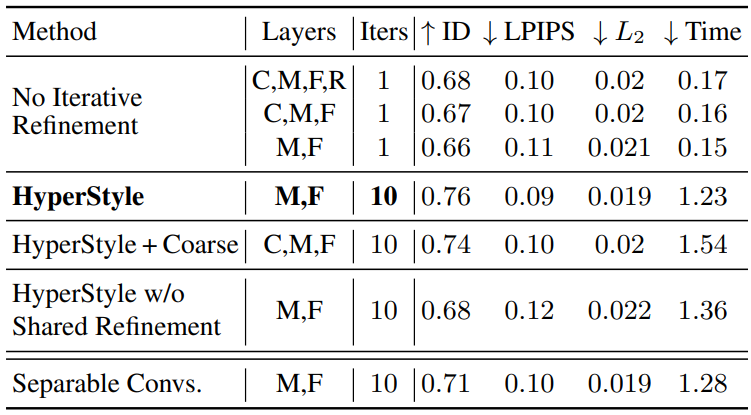
3. Ablation Study
다음은 ablation study 결과를 나타낸 표이다. Layers의 C, M, F, R은 각각 coarse, medium, fine, toRGB를 의미한다.
4. Additional Applications
Domain Adaptation
다음은 FFHQ에서 학습된 HyperStyle이 예측한 가중치 offset을 fine-tuning된 generator(ex. Toonify, StyleGAN-NADA)를 수정하는 데 적용한 예시이다.

Editing Out-of-Domain Images
실제 이미지에 대해서만 학습된 HyperStyle을 generator fine-tuning 학습 중에 관찰되지 않는 까다로운 스타일로 성공적으로 일반화한 예시이다.
