[논문리뷰] Hunyuan3D 2.5: Towards High-Fidelity 3D Assets Generation with Ultimate Details
arXiv 2025. [Paper] [Github]
Tencent Hunyuan3D Team
19 Jun 2025

Introduction
본 논문은 충실도가 높고 디테일한 텍스처가 적용된 3D 에셋 생성을 목표로 하는 강력한 3D diffusion model인 Hunyuan3D 2.5를 소개한다. Hunyuan3D 2.5는 이전 버전인 Hunyuan3D 2.0과 Hunyuan3D 2.1의 2단계 파이프라인을 기반으로 하며, shape 생성과 텍스처 합성 모두에서 상당한 발전을 보여주었다.
Shape 생성 단계에서는 새로운 shape foundation model인 LATTICE를 도입하였다. 이 모델은 모델 크기와 연산 리소스가 증가한 대규모 고품질 데이터셋에서 학습되었다. LATTICE는 모델을 scaling해도 안정적인 성능 향상을 보인다. 가장 큰 모델은 깨끗하고 매끄러운 표면을 유지하면서도 해당 이미지에 정확하게 정렬된 상세하고 선명한 3D shape을 생성하여, 생성된 3D shape과 수작업으로 제작된 3D shape 간의 격차를 크게 줄였다.
텍스처 생성 단계에서는 Hunyuan3D 2.0과 Hunyuan3D 2.1 텍스처 생성 모델을 고충실도 material 생성 프레임워크로 확장하였다. 구체적으로, BRDF 모델을 기반으로 멀티뷰 albedo, metallic, roughness, map을 동시에 생성한다. 이를 통해 생성된 3D 애셋의 표면 반사 특성을 정확하게 표현하고 미세한 표면 분포를 정확하게 시뮬레이션하여 더욱 사실적이고 세부적인 렌더링 결과를 얻을 수 있다. 또한, 텍스처-형상 정렬을 강화하는 2단계 해상도 향상 전략을 도입하여 end-to-end로 시각적 품질을 향상시켰다.
Method
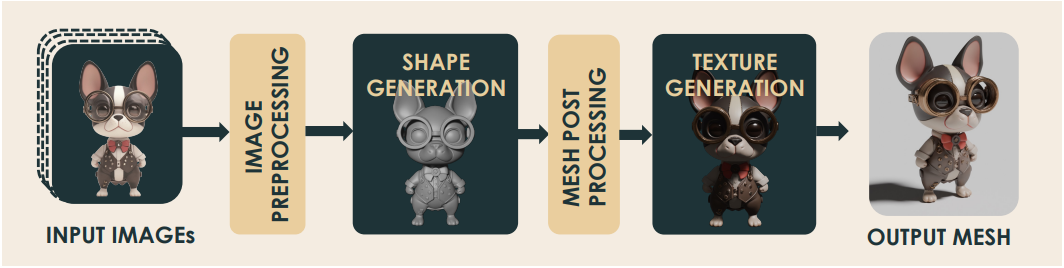
Hunyuan3D 2.5는 Hunyuan3D 2.0과 동일한 아키텍처를 따르는 이미지-3D 생성 모델이다. 입력 이미지는 먼저 이미지 전처리를 통해 배경을 제거하고 적절히 크기가 조정된다. 그런 다음, 입력 이미지를 기반으로 shape 생성 모델이 텍스처가 없는 3D 메쉬를 생성한다. 메쉬에 추가 처리를 하여 normal, UV map 등을 추출한다. 그 후, 텍스처 생성 모델로 텍스처를 생성한다.
1. Detailed Shape Generation
Hunyuan3D 2.5는 새로운 shape 생성 모델인 LATTICE를 도입했다. 이 모델은 단일 이미지 또는 네 개의 멀티뷰 이미지로부터 날카로운 모서리와 매끄러운 표면을 가진 고정밀의 디테일한 shape을 생성할 수 있는 대규모 diffusion model이다. 복잡한 물체를 포함하는 광범위하고 고품질의 3D 데이터셋을 기반으로 학습된 이 모델은 뛰어난 디테일을 생성하도록 설계되었다. 저자들은 효율성을 보장하기 위해 guidance 및 step distillation 기법을 사용하여 inference 시간을 단축하였다.

Hunyuan3D 2.5는 scaling을 통해 전례 없는 수준의 세밀한 디테일을 생성할 수 있게 되었다. 위 예시에서 볼 수 있듯이, Hunyuan3D 2.5는 정확한 손가락 개수, 상세한 자전거 바퀴 패턴, 심지어 넓은 화면 내 그릇 모양까지 수작업으로 구현한 디자인에 근접한 수준의 정확도를 달성하였다. 또한, 기존 모델들은 특히 복잡한 물체의 경우 매끄럽고 깨끗한 표면을 유지하면서 날카로운 모서리를 생성하는 데 어려움을 겪는 경우가 많지만, Hunyuan3D 2.5는 탁월한 균형을 이룬다.
2. Realistic Texture Generation
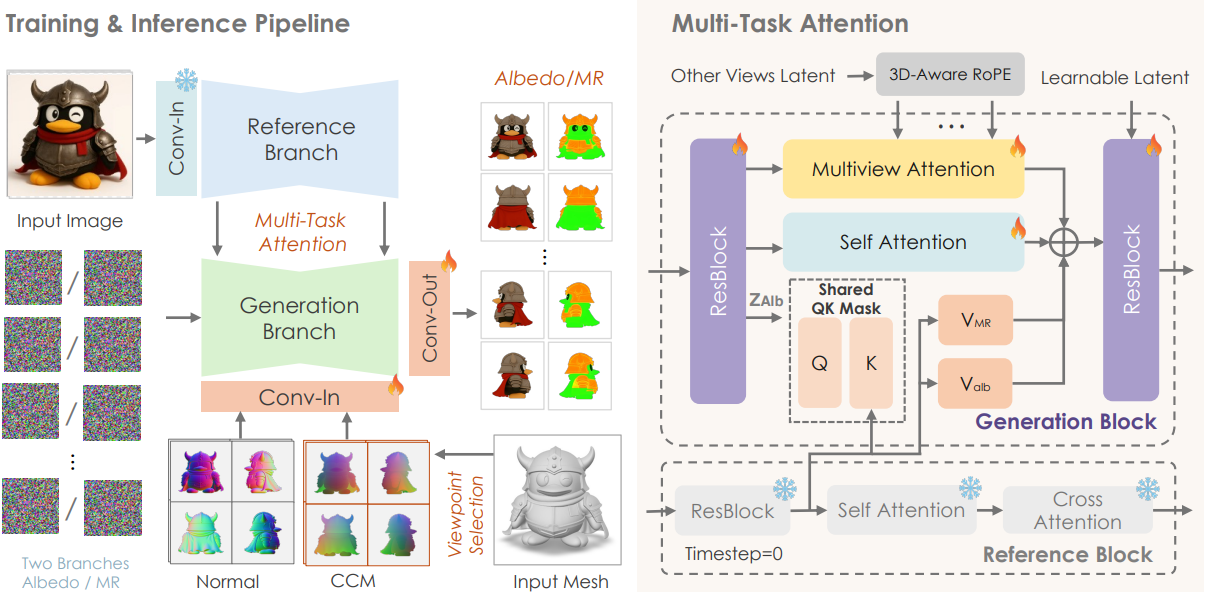
Hunyuan3D 2.5에서는 새로운 material 생성 프레임워크를 제안하였다. 이 프레임워크는 Hunyuan3D 2.1의 멀티뷰 PBR 텍스처 생성 아키텍처를 기반으로 확장되었다. 본 모델은 3D 메쉬로 렌더링된 normal map과 CCM (canonical coordinate map)을 형상 조건으로, 레퍼런스 이미지를 guidance로 사용하여 고품질 PBR material map을 텍스처로 생성한다. 3D-aware RoPE를 상속하여 시점 간 일관성을 향상시켜 매끄러운 텍스처 맵을 생성한다.
Multi-Channel Material Generation.
저자들은 세 가지 material map (albedo, MR)에 대한 학습 가능한 임베딩을 도입하였다. 이 중 MR 채널은 metallic과 roughness를 결합한 표현이다. 구체적으로, 세 개의 독립적인 임베딩 \(\textbf{E}_\textrm{albedo}, \textbf{E}_\textrm{mr}, \textbf{E}_\textrm{normal} \in \mathbb{R}^{16 \times 1024}\)를 초기화한 후 cross-attention layer를 통해 각 채널에 주입한다. 임베딩과 attention 모듈은 학습 가능하므로 네트워크가 세 가지 분포를 개별적으로 효과적으로 모델링할 수 있다.
각 채널은 상당한 도메인 간극을 보이지만, semantic 정렬부터 픽셀 수준의 정렬까지 다양한 수준에서 공간적 대응 관계를 유지하는 것이 매우 중요하다. 따라서 저자들은 생성된 albedo와 metallic-roughness (MR) 간의 공간적 정렬을 보장하는 dual-channel attention 메커니즘을 제안하였다.
저자들이 reference attention 모듈을 체계적으로 검토한 결과, 여러 채널 사이의 정렬 오차의 주요 원인은 attention mask의 정렬 오차에 있음을 발견했다. 따라서 output 계산에서 value 계산을 변경하면서 의도적으로 여러 채널 간에 attention mask를 공유했다. 구체적으로, 기본 색상 branch는 레퍼런스 이미지와 의미적으로 가장 유사한 정보를 포함하고 있으므로 (두 이미지 모두 RGB 색상 공간에 존재), 기본 색상 채널에서 계산된 attention mask를 활용하여 다른 두 branch의 reference attention을 유도한다.
\[\begin{aligned} M_\textrm{attn} &= \textrm{Softmax} \left( \frac{Q_\textrm{albedo} K_\textrm{ref}^\top}{\sqrt{d}} \right) \\ z_\textrm{albedo}^\textrm{new} &= z_\textrm{albedo} + \textrm{MLP}_\textrm{albedo} [M_\textrm{attn} \cdot V_\textrm{albedo}] \\ z_\textrm{MR}^\textrm{new} &= z_\textrm{MR} + \textrm{MLP}_\textrm{MR} [M_\textrm{attn} \cdot V_\textrm{MR}] \end{aligned}\]이 디자인은 생성된 albedo feature와 MR feature가 레퍼런스 이미지 정보의 guidance를 받으면서 공간적 일관성을 유지할 수 있도록 한다. 이 프레임워크를 기반으로, material 속성과 조명 성분의 분리를 강화하기 위해 학습 과정에서 illumination-invariant consistency loss를 통합했다.
텍스처-형상 정렬
텍스처와 형상의 정렬은 3D 애셋의 시각적 무결성과 미적 품질에 중대한 영향을 미친다. 그러나 정밀한 텍스처-형상 정렬은 상당한 어려움을 수반하며, 특히 복잡하고 폴리곤이 많은 형상의 경우 더욱 그렇다. 분석 결과, 고해상도 이미지는 VAE 압축 손실을 완화하는 동시에 풍부한 고주파 형상 디테일을 보존하여 형상 컨디셔닝을 크게 향상시킨다는 것이 핵심이다. 그러나 고해상도 멀티뷰 이미지로 학습하는 데는 상당한 메모리 리소스가 필요하며, 이는 학습 중 시점 수를 줄여야 하고, 결과적으로 모델의 dense-view inference 성능을 저하시킨다.
저자들은 이러한 문제를 해결하기 위해, 계산적 타당성을 유지하면서 텍스처-형상 정렬 품질을 점진적으로 향상시키는 2단계 해상도 향상 전략을 제안하였다. 첫 번째 단계에서는 Hunyuan3D 2.0을 따라 6-view 512$\times$512 이미지를 사용하는 기존의 멀티뷰 학습 방식을 사용한다. 이 단계는 멀티뷰 일관성 및 기본적인 텍스처-형상 대응을 위한 견고한 기반을 구축한다.
두 번째 단계에서는 모델이 첫 번째 단계의 멀티뷰 학습 효과를 유지하면서도 고품질 디테일을 포착할 수 있도록 하는 줌인 학습 전략을 사용한다. 구체적으로, 학습 과정에서 레퍼런스 이미지와 멀티뷰에서 생성된 이미지를 무작위로 확대한다. 이 방식을 통해 모델은 처음부터 고해상도 학습을 완전히 수행하지 않고도 세밀한 텍스처 디테일을 학습할 수 있으며, 이를 통해 고해상도 멀티뷰 학습과 관련된 메모리 제약을 피할 수 있다.
Inference 시에는 최대 768$\times$768 해상도의 멀티뷰 이미지를 활용하며, 효율적인 고품질 생성을 위해 UniPC 샘플러로 가속화한다.
Evaluation
1. Shape Generation
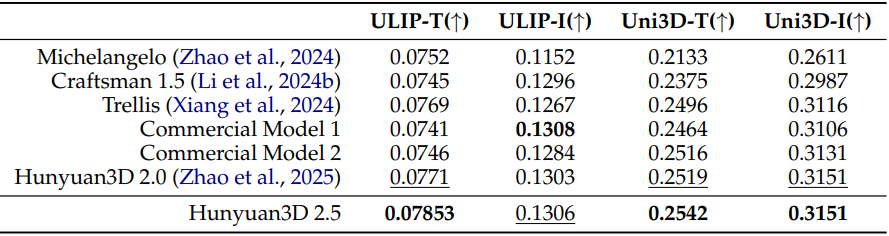
다음은 shape 생성 성능을 비교한 결과이다.

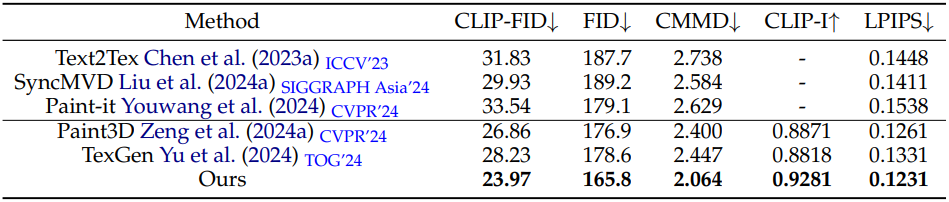
2. Texture Generation
다음은 텍스처 생성 성능을 비교한 결과이다.

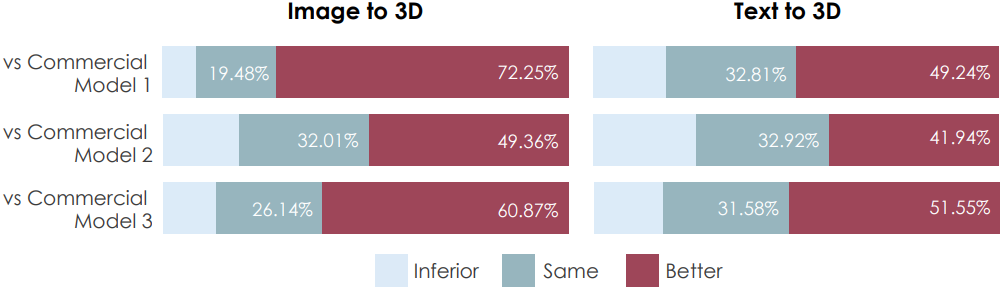
다음은 user study 결과이다.