[논문리뷰] Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
arXiv 2025. [Paper] [Github]
Tencent Hunyuan3D Team
21 Jan 2025

Introduction
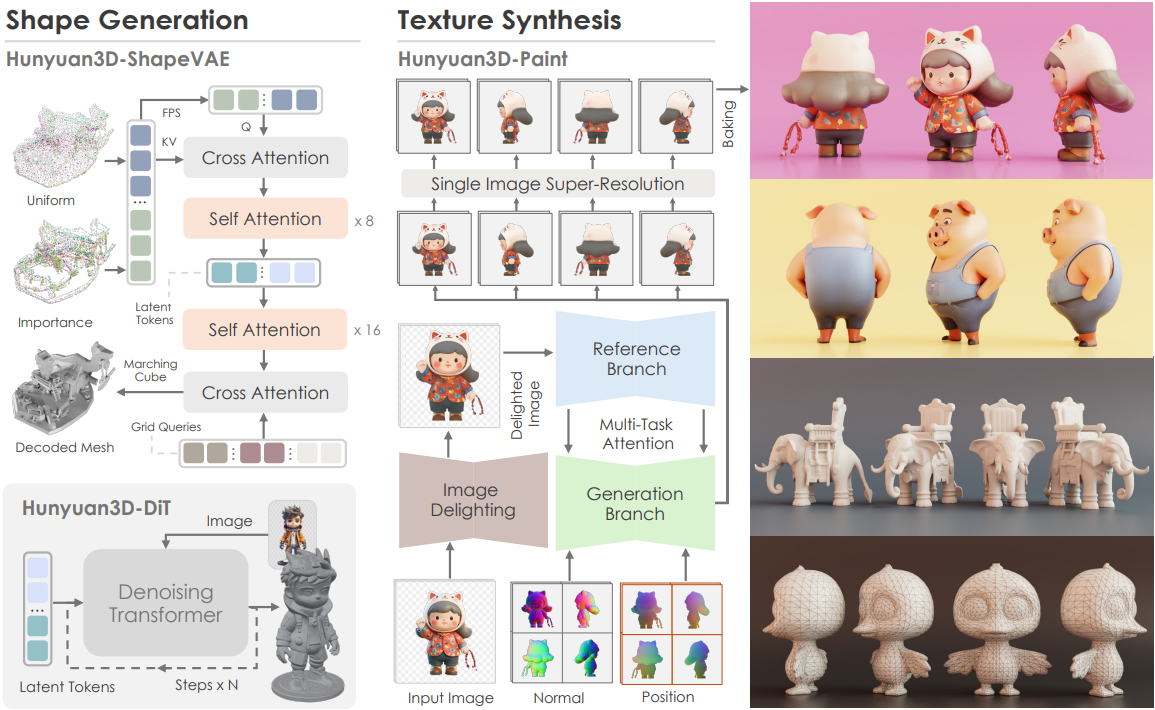
Hunyuan3D 2.0은 3D 에셋 생성 시스템으로, shape 생성을 위한 Hunyuan3D-DiT와 텍스처 합성을 위한 Hunyuan3D-Paint로 구성된다.
Hunyuan3D-DiT는 대규모 flow-based diffusion model로 설계되었다. 먼저 메쉬 표면에서의 중요도 샘플링을 사용하여 오토인코더인 Hunyuan3D-ShapeVAE를 학습시킨다. 그런 다음, flow matching 목적 함수를 사용하여 VAE의 latent space에 dual-single stream transformer를 구축한다. Hunyuan3D-Paint는 메쉬를 조건으로 하는 새로운 멀티뷰 생성 파이프라인이며, 멀티뷰 이미지를 전처리하고 고해상도 텍스처 맵으로 베이킹하는 여러 정교한 기법으로 구성된다.
Generative 3D Shape Generation
Hunyuan3D 2.0은 latent diffusion model을 아키텍처로 사용하며, 두 부분으로 구성된다.
- Hunyuan3D-ShapeVAE: 폴리곤 메쉬로 표현된 3D 에셋을 latent space의 연속적인 토큰 시퀀스로 압축하는 오토인코더
- Hunyuan3D-DiT: 사용자가 제공한 이미지에서 물체 토큰 시퀀스를 예측하기 위해 ShapeVAE의 latent space에서 학습된 flow-based diffusion model
1. Hunyuan3D-ShapeVAE
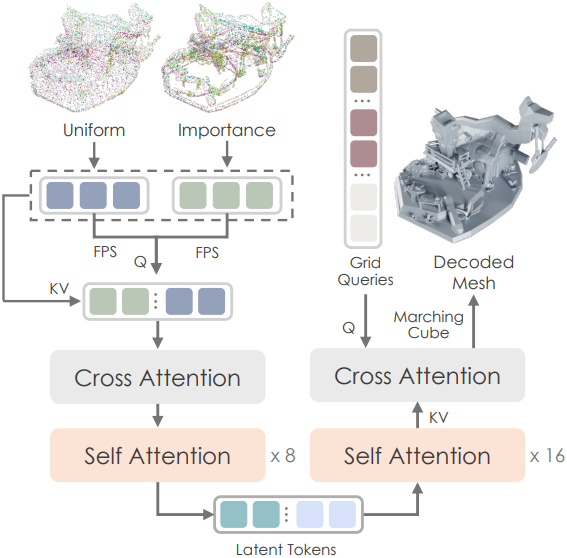
Hunyuan3D-ShapeVAE는 3DShape2VecSet에서 제안한 3D 형상에 대한 컴팩트 신경망 표현인 벡터 세트를 사용한다. Michelangelo를 따라, 형상 압축 및 디코딩을 위해 variational encoder-decoder transformer를 사용한다. 또한, 3D 형상 표면에서 샘플링된 포인트 클라우드의 3D 좌표와 normal 벡터를 인코더의 입력으로 선택하고, 디코더가 3D 형상의 SDF를 예측하도록 한다. 이 SDF는 marching cube 알고리즘을 통해 삼각형 메쉬로 디코딩될 수 있다.
중요도 샘플링 기반 포인트 쿼리 인코더
인코더 \(\mathcal{E}_s\)는 3D 형상을 특징짓기 위해 대표적인 feature들을 추출하는 것을 목표로 한다. 저자들의 첫 번째 디자인은 attention 기반 인코더를 사용하여 3D 형상 표면에서 균일하게 샘플링된 포인트 클라우드를 인코딩하였다. 그러나 이 디자인은 일반적으로 복잡한 물체의 디테일을 재구성하는 데 실패한다. 이러한 어려움은 형상 표면 영역들의 복잡성 차이에 기인한다. 따라서 균일하게 샘플링된 포인트 클라우드 외에, 메쉬의 모서리와 꼭짓점에서 더 많은 포인트를 샘플링하는 중요도 샘플링 방법을 설계하여 복잡한 영역을 설명하는 데 더욱 완전한 정보를 제공한다.
- 입력 메쉬에서 균일하게 샘플링된 표면 포인트 클라우드 $P_u \in \mathbb{R}^{M \times 3}$와 중요도 샘플링된 표면 포인트 클라우드 $P_i \in \mathbb{R}^{N \times 3}$를 수집한다.
- 포인트 쿼리를 얻기 위해, $P_u$와 $P_i$에 각각 Farthest Point Sampling (FPS)을 적용하여 $Q_u \in \mathbb{R}^{M^\prime \times 3}$와 $Q_i \in \mathbb{R}^{N^\prime \times 3}$를 얻는다.
- $P_u$와 $P_i$를 concat하여 $P \in \mathbb{R}^{(M + N) \times 3}$을 얻고, $Q_u$와 $Q_i$를 concat하여 $Q \in \mathbb{R}^{(M^\prime + N^\prime) \times 3}$을 얻는다.
- $P$와 $Q$에 Fourier positional encoding과 linear projection을 각각 순차적으로 적용하여 $X_p \in \mathbb{R}^{(M + N) \times d}$와 $X_q \in \mathbb{R}^{(M^\prime + N^\prime) \times d}$로 인코딩한다.
- $X_p$를 key와 value로, $X_q$를 query로 하여 cross-attention을 수행한다.
- 8개의 self-attention layer를 통과시켜 $H_s \in \mathbb{R}^{(M^\prime + N^\prime) \times d}$로 feature 표현을 향상시킨다.
- VAE 디자인을 사용하기 때문에, $H_s$에 추가 linear projection을 적용하여 latent shape embedding $Z_s$의 평균 $E(Z_s) \in \mathbb{R}^{(M^\prime + N^\prime) \times d_0}$와 분산 $\textrm{Var}(Z_s) \in \mathbb{R}^{(M^\prime + N^\prime) \times d_0}$을 예측한다.
디코더
디코더 \(\mathcal{D}_s\)는 인코더의 latent shape embedding $Z_s$로부터 3D neural field를 재구성한다.
- Projection layer로 latent shape embedding의 차원 $d_0$에서 transformer의 차원 $d$로 차원을 다시 변환한다.
- 여러 self-attention layer를 통과시킨다.
- 3D 그리드 $Q_g \in \mathbb{R}^{(H \times W \times D) \times 3}$을 query로 사용한 cross-attention을 통해 3D neural field $F_g \in \mathbb{R}^{(F_n \times W \times D) \times d}$를 얻는다.
- Neural field에 대한 또 다른 linear projection을 사용하여 SDF \(F_\textrm{sdf} \in \mathbb{R}^{(F_0 \times W \times D) \times 1}\)을 얻는다.
얻은 SDF는 marching cube 알고리즘을 사용하여 삼각형 메쉬로 디코딩할 수 있다.
학습 전략
모델 학습에 여러 loss를 사용한다.
- Reconstruction loss: 예측된 SDF \(\mathcal{D}_s (x \vert Z_s)\)와 GT $\textrm{SDF}(x)$ 사이의 MSE loss
- KL-divergence loss \(\mathcal{L}_\textrm{KL}\): Latent space를 컴팩트하고 연속적으로 만들어 diffusion model의 학습을 용이하게 함
완전한 SDF에 dense한 계산이 필요하기 때문에 인해, reconstruction loss는 공간 및 형상 표면에서 무작위로 샘플링된 포인트에 대한 loss의 기대값으로 계산된다. 전체 학습 손실 \(\mathcal{L}_r\)은 다음과 같다.
\[\begin{equation} \mathcal{L}_r = \mathbb{E}_{x \in \mathbb{R}^3} [\textrm{MSE} (\mathcal{D}_s (x \vert Z_s), \textrm{SDF}(x))] + \gamma \mathcal{L}_\textrm{KL} \end{equation}\]학습 과정에서는 모델 수렴 속도를 높이기 위해 다중 해상도 전략을 활용한다. 이 전략에서는 latent 토큰 시퀀스의 길이가 미리 정의된 집합에서 무작위로 샘플링된다. 시퀀스가 짧을수록 계산 비용이 감소하고, 시퀀스가 길수록 재구성 품질이 향상된다. 가장 긴 시퀀스 길이는 3072로, 세밀하고 선명한 디테일을 가진 고해상도 생성을 지원할 수 있다.
2. Hunyuan3D-DiT
Hunyuan3D-DiT는 주어진 이미지 프롬프트에 따라 고정확도, 고해상도의 3D shape을 생성하는 것을 목표로 하는 flow-based diffusion model이다.
네트워크 구조
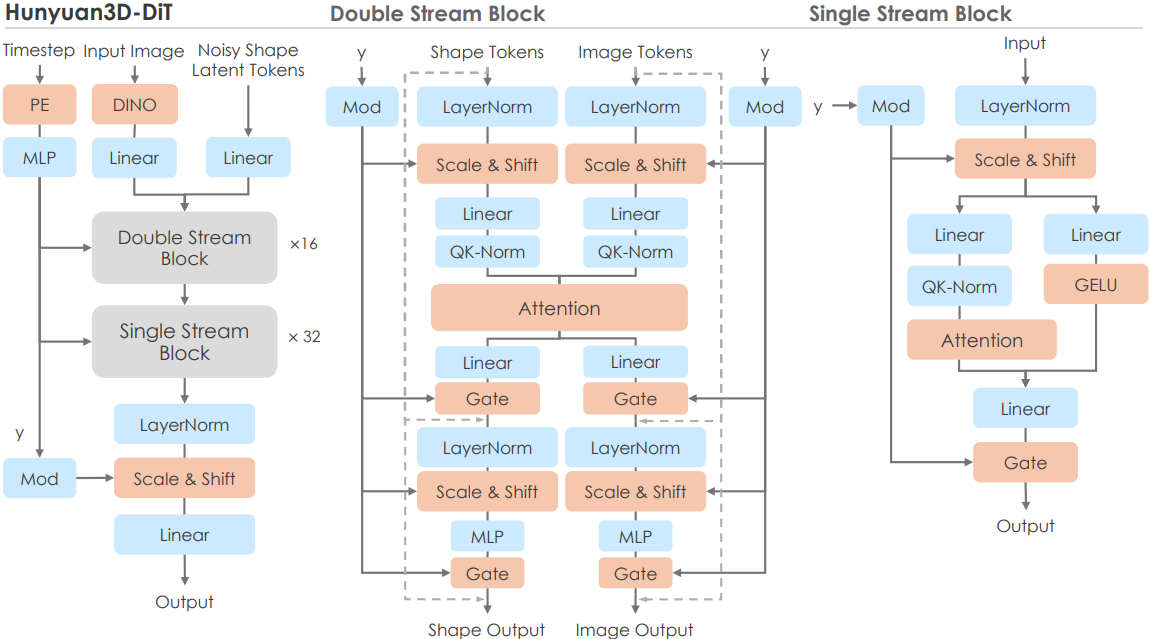
저자들은 FLUX에서 영감을 얻어 dual-single stream 네트워크 구조를 채택했다. Dual stream 블록에서는 latent 토큰과 조건 토큰이 별도의 QKV projection, MLP 등으로 처리된 후 attention 연산 내에서 상호 작용한다. Single stream 블록에서는 latent 토큰과 조건 토큰이 concat된 후 spatial attention과 채널 attention에 의해 병렬로 처리된다. Timestep의 임베딩은 modulation module에만 사용한다. 또한 시퀀스에서 ShapeVAE의 특정 latent 토큰이 3D 그리드의 고정된 위치에 해당하지 않으므로 latent 시퀀스의 위치 임베딩을 생략한다. 대신 3D latent 토큰의 내용 자체가 3D 그리드에서 생성된 모양의 위치/점유를 파악하는 역할을 하며, 이는 특정 위치에 있는 내용을 예측하는 역할을 하는 이미지/비디오 생성과 다르다.
조건 주입
사전 학습된 이미지 인코더를 사용하여 마지막 레이어의 head 토큰을 포함한 패치 시퀀스의 조건부 이미지 토큰을 추출한다. 이미지의 세밀한 디테일을 포착하기 위해 DINOv2 Giant와 같은 큰 이미지 인코더와 518$\times$518의 큰 입력 이미지 크기를 사용한다. 또한, 입력 이미지의 배경을 제거하고, 물체의 크기를 통일된 크기로 조정하고, 물체를 중앙에 배치하고, 배경을 흰색으로 채운다. 이를 통해 배경의 부정적인 영향을 제거하고 입력 이미지의 유효 해상도를 높일 수 있다.
학습 & inference
모델 학습에는 flow matching 목적 함수를 활용한다. 구체적으로, flow matching은 먼저 Gaussian 분포와 데이터 분포 사이의 확률 밀도 경로를 정의한 후, 샘플 $x_t$가 데이터 $x_1$ 방향으로 이동하는 속도장 $u_t$를 예측하도록 모델을 학습시킨다. 본 논문에서는 다음과 같은 affine 경로를 채택하였다.
\[\begin{equation} x_t = (1 − t) \times x_0 + t \times x_1, \quad u_t = x_1 − x_0 \end{equation}\]따라서 학습 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathbb{E}_{t \sim \mathcal{U}(0,1), x_0, x_1} [\| u_\theta (x_t, c, t) - u_t \|_2^2 ] \end{equation}\]Inference 시에는 먼저 시작점 $x_0 \sim \mathcal{N}(0, 1)$을 무작위로 샘플링하고 1차 오일러 ODE solver를 사용하여 diffusion model $x_1$을 계산한다.
Generative Texture Map Synthesis
텍스처가 없는 3D 메쉬와 이미지 프롬프트가 주어졌을 때, 고해상도의 매끄러운 텍스처 맵을 생성하는 것을 목표로 한다. 텍스처 맵은 보이는 영역에서 이미지 프롬프트와 일치해야 하며, 멀티뷰 일관성을 유지하고, 입력 메쉬와 조화를 이루어야 한다.
이러한 목표를 달성하기 위해, 다음과 같은 3단계 프레임워크를 사용한다.
- 전처리 단계
- 멀티뷰 이미지 합성 단계 (Hunyuan3D-Paint)
- DMM 기반 텍스처 베이킹 단계
1. Pre-processing
이미지 Delighting 모듈
레퍼런스 이미지는 일반적으로 사용자가 수집했든 T2I 모델에서 생성했든 강렬하고 다양한 조도와 그림자를 보인다. 이러한 이미지를 멀티뷰 생성 프레임워크에 직접 입력하면 조도와 그림자가 텍스처 맵에 베이킹될 수 있다. 이 문제를 해결하기 위해, 멀티뷰 생성 전에 image-to-image 방식으로 입력 이미지에 delighting을 적용한다.
구체적으로, 저자들은 이러한 이미지 delighting 모델을 학습시키기 위해 대규모 3D 데이터셋을 수집하고 무작위 HDRI environment map과 균일한 백색광 아래에서 렌더링하여 쌍별 이미지 데이터를 형성하였다. 이 이미지 delighting 모델을 활용하여 멀티뷰 생성 모델은 백색광 조명 이미지에 대해 완전히 학습될 수 있으며, 조도에 불변한 텍스처 합성이 가능해 진다.
시점 선택 전략

실제 적용에서 텍스처 생성 비용을 줄이기 위해, 즉 최소 시점 수로 가장 넓은 텍스처 영역을 생성하기 위해, 효과적인 텍스처 합성을 지원하는 형상 기반 시점 선택 전략을 사용한다. 형상 표면의 커버리지를 고려하여 8~12개의 시점을 휴리스틱하게 선택한다. 처음에는 형상의 대부분을 포함하는 4개의 직교 시점을 기준으로 설정한다. 이후 greedy search 방식을 사용하여 새로운 시점을 반복적으로 추가한다. 구체적인 과정은 Algorithm 1과 같으며, 이 알고리즘의 커버리지 함수는 다음과 같이 정의된다.
(\(\mathcal{UV}_\textrm{cover} (v, \textbf{M})\)은 입력 뷰 $v$와 메쉬 $\textbf{M}$을 기반으로 UV space에서 뒤덮는 texel 집합을 반환하는 함수, \(\mathcal{A}_\textrm{area}\)는 주어진 뒤덮는 texel 집합에 따라 뒤덮는 면적을 계산하는 함수)
이러한 접근 방식은 멀티뷰 생성 모델이 보이지 않는 영역이 더 많은 시점에 집중하도록 유도하여 텍스처 인페인팅의 부담을 덜어준다.
2. Hunyuan3D-Paint
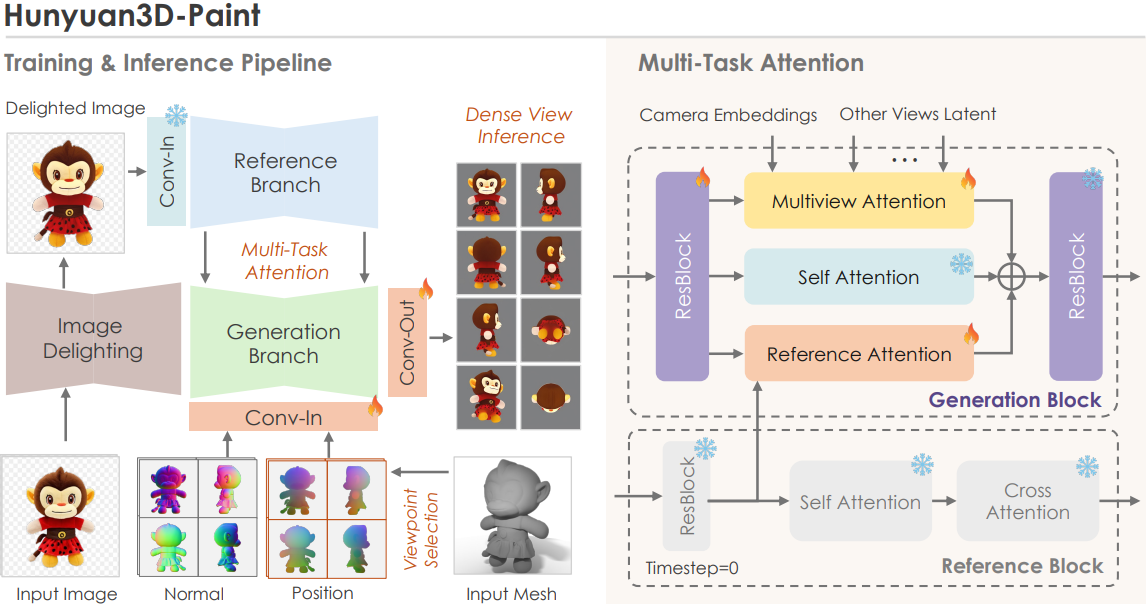
형상 기반 멀티뷰 이미지 생성은 텍스처 합성 프레임워크의 핵심 구성 요소이다. 이미지 기반 텍스처 합성의 맥락에서, 멀티뷰 이미지 생성 모델은 이미지 정렬, 기하학적 추종, 멀티뷰 일관성을 달성하기 위해 세심하게 디자인되어야 한다.
이중 스트림 이미지 컨디셔닝 Reference-Net
Hunyuan3D-Paint는 reference-net 컨디셔닝 접근법을 변형하여 사용한다. 구체적으로, 생성 브랜치와 동기화된 noise가 추가된 feature 대신, 레퍼런스 이미지의 원본 VAE feature를 레퍼런스 브랜치에 직접 입력하여 이미지 디테일을 최대한 유지한다. 이 feature에는 noise가 없으므로, 입력 이미지 정보를 충실하게 유지하기 위해 레퍼런스 브랜치의 timestep을 0으로 설정한다.
또한, 3D 렌더링 데이터셋에서 발생하는 잠재적인 스타일 편향을 정규화하기 위해, 공유 가중치 reference-net을 폐기하고, 원본 SD2.1 가중치의 가중치를 고정한다. 고정 가중치 reference-net은 생성된 이미지 분포를 고정하는 소프트 정규화 역할을 하여 렌더링된 이미지 분포로 이동하는 것을 방지하고, 실제 이미지 컨디셔닝 성능을 크게 향상시킨다.
이 두 가지 방식을 함께 사용하여 이중 스트림 이미지 컨디셔닝 전략을 형성한다. 각 self-attention 모듈 이전에 feature 캐시를 캡처하여 zero-noised 노이즈 이중 스트림 이미지 컨디셔닝 reference-net를 활용한다. 이 feature 캐시는 reference attention 모듈을 통해 멀티뷰 diffusion model에 입력된다.
Multi-task Attention Mechanism
저자들은 이미지 diffusion model이 레퍼런스 이미지를 기반으로 멀티뷰 이미지를 생성할 수 있도록 기존의 self-attention과 함께 두 개의 추가 attention 모듈을 도입하였다. Reference attention 모듈은 레퍼런스 이미지를 멀티뷰 diffusion process에 통합한다. 반면, multiview attention 모듈은 생성된 시점 간의 일관성을 보장한다. 이러한 멀티뷰 기능으로 인해 발생할 수 있는 잠재적 충돌을 완화하기 위해, 저자들은 두 개의 추가 attention 모듈을 병렬 구조로 디자인하였다.
\[\begin{equation} Z_\textrm{MVA} = Z_\textrm{SA} + \lambda_\textrm{ref} \cdot \textrm{Softmax} \left( \frac{Q_\textrm{ref} K_\textrm{ref}^\top}{\sqrt{d}} \right) V_\textrm{ref} + \lambda_\textrm{mv} \cdot \textrm{Softmax} \left( \frac{Q_\textrm{mv} K_\textrm{mv}^\top}{\sqrt{d}} \right) V_\textrm{mv} \end{equation}\](\(Z_\textrm{SA}\)는 고정 가중치 self-attention에서 계산된 feature, \(Q_\textrm{ref}\), \(K_\textrm{ref}\), \(V_\textrm{ref}\)와 \(Q_\textrm{mv}\), \(K_\textrm{mv}\), \(V_\textrm{mv}\)는 각각 reference attention과 multiview attention의 query, key, value)
형상 및 뷰 컨디셔닝
텍스처 맵 합성의 또 다른 고유한 특징은 형상을 따라야 한다는 것이다. 저자들은 효과적인 학습을 위해, 형상 조건과 noise를 직접 concat하는 간편한 구현 방식을 선택했다. 먼저, 두 가지 시점에 무관한 형상 조건인 멀티뷰 canonical normal map과 canonical coordinate maps (CCM)을 사전 학습된 VAE에 입력하여 geometric feature를 얻는다. 이 feature들은 latent noise와 concat되어 diffusion model의 convolution layer로 전달된다.
저자들은 형상 컨디셔닝 외에도, 멀티뷰 diffusion model의 시점 단서를 강화하기 위해 파이프라인에 학습 가능한 카메라 임베딩을 도입했다. 구체적으로, 미리 정의된 각 시점에 고유한 unsigned integer를 할당하고, 학습 가능한 시점 임베딩 레이어를 설정하여 해당 unsigned integer를 feature 벡터에 매핑한 후 멀티뷰 diffusion model에 주입한다.
3. Texture Baking
Dense-view inference
잠재적인 self-occlusion은 멀티뷰 이미지 생성 프레임워크 내 텍스처 합성에서 중요한 과제이며, 특히 형상 생성 모델에서 생성된 불규칙한 형상을 처리할 때 더욱 그렇다. 이 문제는 텍스처 합성을 두 단계 프레임워크로 모델링할 것을 요구한다.
- 멀티뷰 이미지 생성
- Self-occlusion으로 인해 발생한 공백을 채우기 위한 간단한 인페인팅
본 논문의 프레임워크에서는 멀티뷰 생성 단계에서 dense-view inference를 통해 두 번째 단계의 인페인팅 부담을 줄인다. 효과적인 dense-view inference를 위해, 모델이 모든 프리셋 시점을 접할 수 있도록 하는 view dropout 전략을 도입하여 모델의 3D 인식 능력과 일반화를 향상시킨다. 구체적으로, 총 44개의 프리셋 시점 중 6개의 시점을 무작위로 선택하여 멀티뷰 diffusion backbone 네트워크에 batch 입력으로 사용한다. Inference 단계에서 프레임워크는 임의의 시점들에 대한 이미지를 출력하여 dense-view inference를 지원할 수 있다.
단일 이미지 super-resolution
텍스처 품질을 향상시키기 위해, 다양한 시점에서 생성된 각 이미지에 사전 학습된 단일 이미지 super-resolution 모델을 적용한다. 이러한 단일 이미지 super-resolution 접근법은 이미지에 큰 변화를 주지 않기 때문에 멀티뷰 일관성을 유지한다.
텍스처 인페인팅
합성된 멀티뷰 이미지를 텍스처 맵으로 펼친 후에도 UV 텍스처에는 완전히 덮이지 않은 작은 패치들이 남아 있다. 이 문제를 해결하기 위해 직관적인 인페인팅 방식을 사용한다. 먼저, 기존 UV 텍스처를 vertex 텍스처에 projection한다. 그런 다음, 연결된 텍스처 vertex들의 텍스처의 가중치 합을 계산하여 각 UV texel의 텍스처를 쿼리한다. 가중치는 texel과 vertex 사이의 거리의 역수로 설정된다.
Evaluations
- 구현 디테일
- base model: Stable Diffusion 2 v-model의 ZSNR checkpoint
- 입력 이미지 해상도: 512$\times$512
- 총 step 수: 8만
- batch size: 48
- learning rate: $5 \times 10^{-5}$ (1000 warm-up step, ZSNR의 trailing scheduler 사용)
1. 3D Shape Generation
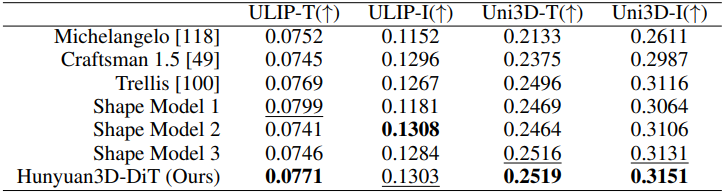
다음은 VAE의 shape 재구성 능력을 비교한 결과이다.


다음은 shape 생성 능력을 비교한 결과이다.

2. Texture Map Synthesis
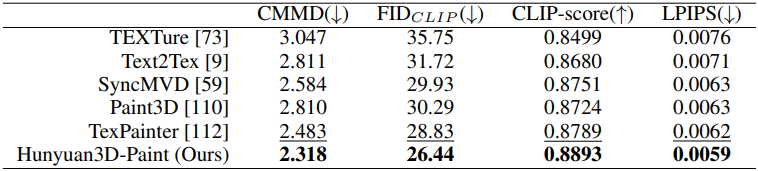
다음은 텍스처 맵 합성 능력을 비교한 결과이다.

다음은 동일한 메쉬에 대해 여러 텍스처 맵을 생성한 예시들이다.

3. Textured 3D Assets Generation
다음은 텍스처가 있는 3D 에셋 생성 능력을 비교한 결과이다.


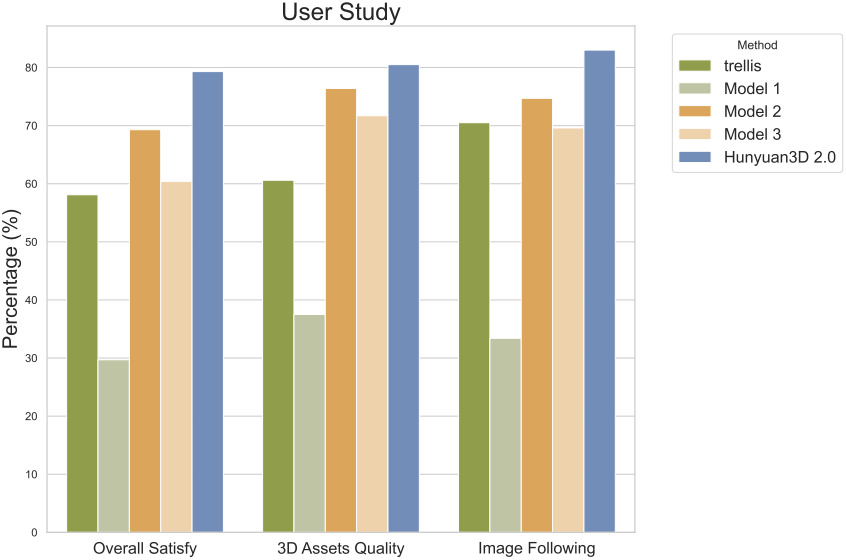
다음은 user study 결과이다.