[논문리뷰] HS-Diffusion: Learning a Semantic-Guided Diffusion Model for Head Swapping
arXiv 2022. [Paper]
Qinghe Wang, Lijie Liu, Miao Hua, Qian He, Pengfei Zhu, Bing Cao, Qinghua Hu
ByteDance Inc | Tianjin University
13 Dec 2022
Introduction
이미지 기반 head swapping task는 source head를 다른 source body에 자연스럽게 이어붙이는 것을 목표로 한다. 거의 연구되지 않은 이 task는 두 가지 주요 과제에 직면해 있다.
- 다양한 source들의 머리와 몸을 보존하면서 두 부분이 이어지는 이미지를 생성해야 한다.
- 지금까지 쌍을 이루는 데이터셋과 벤치마크가 없다.
본 논문에서는 이미지 기반 head swapping 프레임워크인 HS-Diffusion을 제안하며, 이 모델은 semantic-guided latent diffusion model (SG-LDM)과 semantic layout generator로 구성된다. Source head와 source body의 semantic layout을 혼합한 다음 transition region을 semantic layout generator로 inpaint하여 coarse한 head swapping을 달성한다. SG-LDM은 blend layout을 조건으로 하여 점진적인 융합 프로세스로 fine한 head swapping을 시행하며, source head와 source body의 고품질 reconstruction을 보존한다.
이를 위해 head-cover augmentation 전략을 학습에 사용하며 기하학적으로 사실적인 이미지를 위해 neck alignment trick을 사용한다. 또한 저자들은 새로운 이미지 기반 head swapping 벤치마크를 만들었으며, 2가지 맞춤 평가 지표인 Mask-FID와 Focal-FID를 제안한다.
Method
두 상반신 이미지 $(x_1, x_2)$와 대응하는 semantic layout $(l_1, l_2)$가 주어지면, $x_1$의 머리와 $x_2$의 몸이 보존된 새로운 융합 이미지 $\tilde{x}$를 생성하는 것이 목표이다. 추가로, transition region은 이어지게 나타나야 한다. 이를 위해 semantic-guided latent diffusion model (SG-LDM)과 semantic layout generator를 각각 학습시켜 함께 head swapping을 할 수 있도록 한다.
이미지 기반 head swapping 파이프라인은 아래 그림과 같다.
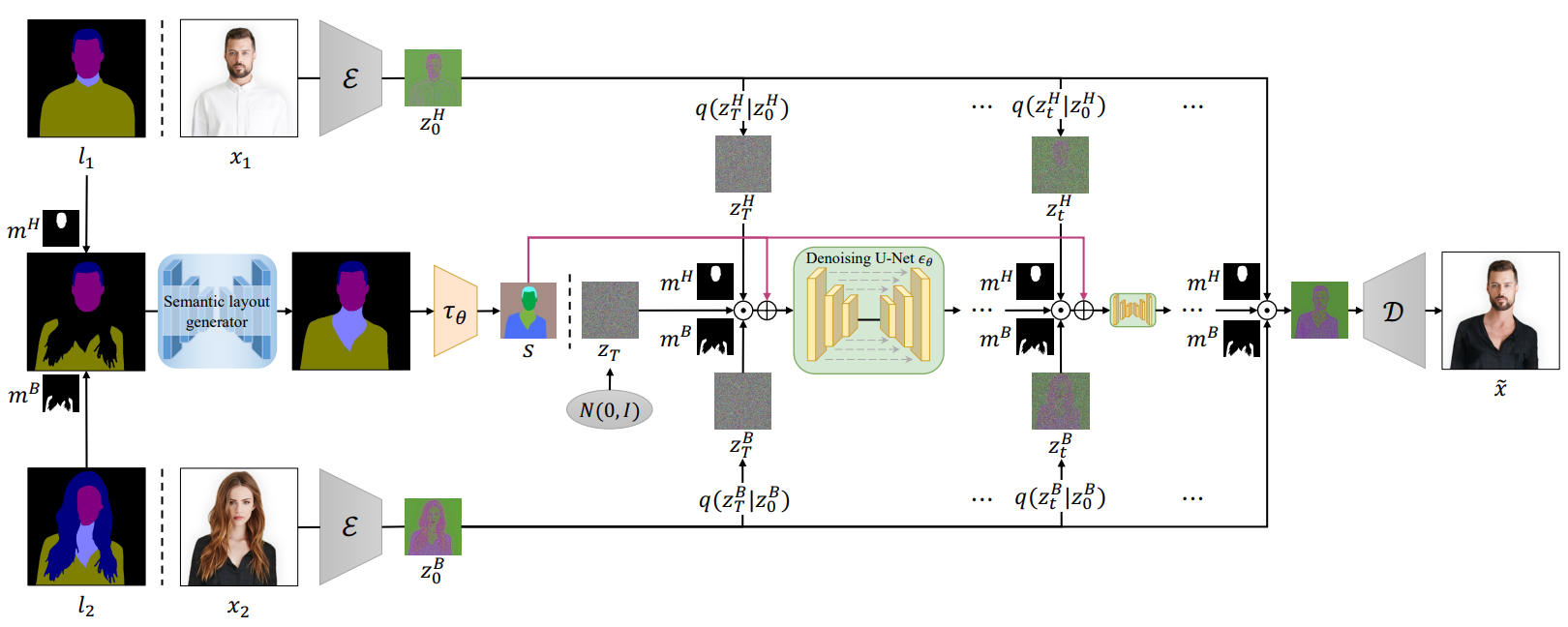
- $(l_1, l_2)$를 head mask $m^H$와 body mask $m^B$로 혼합한다.
- Semantic layout generator로 혼합된 layout의 transition region을 inpaint한다.
- $\mathcal{N} (0,I)$에서 $z_T$를 샘플링한 뒤 forward noising process로 샘플링한 $z_T^H$와 $z_T^B$를 혼합하며, 이는 이후의 denoising step에서도 동일하다.
- 혼합된 noise를 semantic latent representation $s$와 concat하여 각 denoising step에 조건으로 사용한다.
- SG-LDM으로 $z_T$에서 $z_0$로 denoise하고 $\tilde{x}$로 디코딩한다.
1. Semantic-Guided LDM
Latent Diffusion Model은 semantic layout을 condition guidance로 하여 이미지를 생성하도록 학습시킬 수 있다.
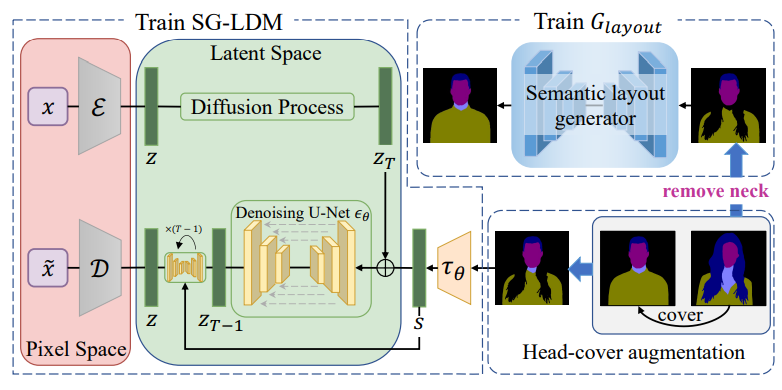
위 그림에서 볼 수 있듯이 SG-LDM은 세 부분으로 이루어져 있다.
- 사전 학습된 autoencoder $(\mathcal{E}, \mathcal{D})$
- Denoising U-Net $\epsilon_\theta$
- 조건 인코더 $\tau_\theta$
구체적으로, 인코더 $\mathcal{E}$는 상반신 이미지 $x$를 latent code $z$로 인코딩하고 디코더 $\mathcal{D}$는 $z$에서 상반신 이미지를 reconstruct한다. 고품질 reconstruction을 통해 diffusion process는 저차원 latent space에서 작동할 수 있다. $z_t$는
\[\begin{equation} z_t = \sqrt{\vphantom{1} \bar{\alpha}_t}z_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon \end{equation}\]으로 직접 샘플링한다. $\tau_\theta$는 layout $l$을 semantic guidance로서 latent representation $s$로 인코딩한 다음 $z_t$와 concat되어 각 denoising step에서 $\epsilon_\theta$의 입력으로 주어진다. $(\mathcal{E}, \mathcal{D})$의 공간 레벨의 inductive bias의 이점을 활용하여 denoising U-Net $\epsilon_\theta$를 2D convolution layer로 구성할 수 있다. $\epsilon_\theta$는 latent space에서 효율적으로 저차원 공간 레벨 표현에 더 집중할 것이며, 이는 재가중된 variational lower bound에 의해 최적화된다.
\[\begin{equation} \mathcal{L}_{LDM} = \mathbb{E}_{z, s, \epsilon \sim \mathcal{N} (0,I), t} [\| \epsilon - \epsilon_\theta (z_t, t, s) \|_2^2] \end{equation}\]$\epsilon_\theta$는 semantic guidance $s$에 대하여 임의의 시간 $t$에서의 $z_t$에 포함된 noise $\epsilon$을 예측하도록 학습된다. \(\mathcal{L}_{LDM}\)이 수렴한다면 $z_T \sim \mathcal{N}(0,I)$를 $z_0$로 반복적으로 denoise하고 그런 다음 $z_0$를 디코딩하면 상반신 이미지를 생성할 수 있다.
Latent representation $z_0^H$와 $z_0^B$를 mask $(m^H, m^B)$로 바로 혼합할 수 있다. 하지만, 목 크기가 머리와 몸에 맞아야 하고 배경 영역은 transition region을 고려해야 하므로 $x_1$ 또는 $x_2$의 목과 배경 영역을 적용할 수 없다. 따라서 저자들은 불완전한 transition region과 배경 영역을 적응적으로 확장하거나 축소하도록 하였다. 제안된 semantic layer generator를 사용하여 condition guidance로서 혼합된 semantic layout을 얻을 수 있으며, 이 semantic layout은 denoising을 guide하는 그럴듯한 의미 정보를 제공한다.
저자들은 Blended diffusion model에서 영감을 받아 SG-LDM으로 head swapping을 수행하는 점진적인 융합 전략을 디자인하였다. 구체적으로, 먼저 $z_T \sim \mathcal{N}(0,I)$를 랜덤하게 샘플링하고 forward noising process로 $z_T^H$와 $z_T^B$를 얻는다. $z_T^H$와 $z_T^B$는 같은 noise 레벨의 이미지 manifold의 noise로 생각할 수 있다. 그런 다음 두 noise를 mask로 혼합한다.
\[\begin{equation} \hat{z}_t = z_t^H \odot m^H + z_t^B \odot m^B + z_t \odot m^r \\ m^r = 1 - m^H - m^B \end{equation}\]$m^r$은 나머지 영역을 의미한다. \(\hat{z}_T\)가 manifold에서 빗나갈 수 있지만 다음 denoising step이 \(\hat{z}_T\)의 통합되지 않은 영역을 융합하고 추가로 $z_{T-1}$을 $T-1$ noising level에서의 manifold로 보낸다. 점진적인 융합 프로세스 중에는 $z_t$에서 $m_r$을 생성하기 위한 기본 레퍼런스를 제공하면서 $z_t$의 $m^H$와 $m^B$는 forward noising process로 유도된다. Semantic guidance 하에서 $z_t$의 $m^r$은 $m^H$와 $m^B$를 일치시키도록 경계들을 조화롭게 만든다. 마지막에 통합된 $z_0$를 얻을 수 있으며 잘 이어진 이미지 $\tilde{x}$로 디코딩할 수 있다.
2. Head-cover Augmentation
Source body 이미지에서 머리카락이 목과 몸을 덮는 경우를 시뮬레이션하기 위하여 효과적인 head-cover augmentation 전략을 디자인하여 SG-LDM과 semantic layout generator를 각각 학습시킨다. 학습 데이터셋에서 랜덤하게 $(l_1, l_2)$를 샘플링하고 $l_2$의 머리 영역을 사용하여 $l_1$의 목과 몸 영역을 덮는다. 그런 다음 덮힌 영역은 배경 클래스로 대체된다. $(l_1, l_2)$가 머리, 목, 몸 영역의 스케일이 다르기 때문에 $l_2$는 머리와 목 영역으로 덮히거나 그대로일 것이다.
따라서 여러 스케일의 head-cover augmentation은 학습의 다양성을 보장하고 최대한 많은 케이스를 시뮬레이션할 수 있다. 제안된 augmentation은 효과적으로 semantic layer generator가 불완전한 layout을 inpaint하도록 보장하며, semantic 레벨의 coarse한 head swapping에 사용될 수 있다. 게다가 SG-LDM에 transition region을 생성하는 self-regulation 능력을 부여하므로 fine한 head swapping에 사용될 수 있다.
3. Semantic Layout Generator
SG-LDM의 그럴듯한 semantic guidance를 제공하기 위하여 저자들은 semantic layout generator $G_{layout}$을 self-supervised 방식으로 학습되는 nested U-Net 아키텍처로 디자인하였다. 보다 구체적으로, 제안된 head-cover augmentation을 도입하고 입력 semantic layout $l$의 목 영역을 추가로 제거한다. Transition region에 주목하고 나머지 영역을 그대로 두기 위하여 focus map의 아이디어를 사용하여 $G_{layout}(l)$을 위한 추가 출력 채널 $m_{focus}$을 추가하였다. 최종 출력 $\tilde{l}$은
\[\begin{equation} \tilde{l} = m_{focus} \odot \hat{l} + (1 - m_{focus}) \odot l \end{equation}\]로 얻어지며, $\hat{l}$은 $G_{layout}(l)$의 나머지 채널이다. 따라서 $G_{layout}$이 transition region을 적응적으로 inpaint하도록 하며, 이는 pixel-wise cross-entropy loss와 LSGAN loss로 최적화된다.
\[\begin{equation} \mathcal{L}_{layout} = \lambda_1 \mathcal{L}_{CE} + \lambda_2 \mathcal{L}_{GAN} \end{equation}\]$\lambda_1$과 $\lambda_2$는 trade-off 파라미터이다. argmax 함수가 미분 불가능하므로 Gumbel-softmax reparameterization trick을 사용하여 생성된 semantic layout을 이산화하며, 이를 통해 discriminaotr에서 $G_{layout}$으로 기울기가 흐를 수 있게 된다. 또한, 생성된 semantic layout은 학습 초기에 가짜로 판별되기 쉬우므로 이산화는 이러한 상황을 피하는 데 유용하다.
$(l_1, l_2)$가 $m^H$와 $m^B$로 바로 혼합되면 $G_{layout}$은 coarse한 head swapping을 위해 혼합된 layout의 불완전한 transition region을 inpaint할 수 있다. $G_{layout}$이 제공한 그럴듯한 semantic guidance에 기반하여 SG-LDM은 각 denoising process에서 경계 픽셀들을 적응적으로 finetuning하여 fine한 head swapping을 시행한다. 저자들은 쌍으로 된 head swapping 데이터셋 없이 두 가지 self-supervised 모델 (SG-LDM과 $G_{layout}$)으로 이 어려운 문제를 해결했다.
4. Neck Alignment Trick
Face alignment은 데이터셋의 머리 크기를 같은 수준으로 정규화하고 자동으로 같은 위치로 얼굴들을 정렬한다. 하지만 얼굴이 정렬된 두 이미지 $(x_1, x_2)$의 원점이 다르면 다음 그림과 같이 목 사이의 수평 편차가 존재할 수 있으며, 이는 head swapping 결과의 현실성에 영향을 준다.
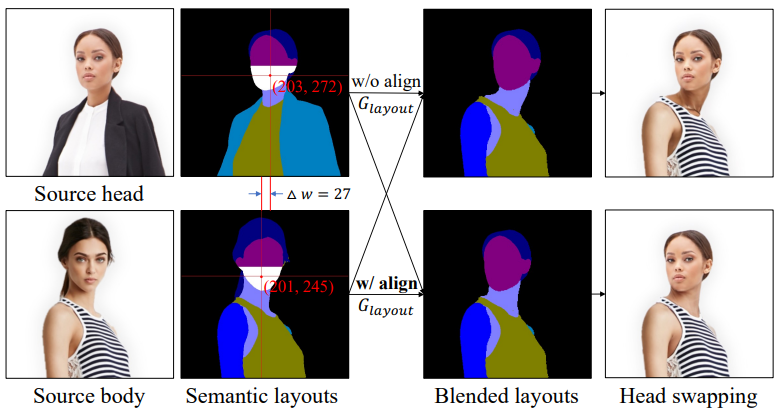
목 부위가 가슴 피부와 구별하기 어렵고 종종 옷에 의해 가려지는 문제가 있으므로 목 부위의 편차를 직접적으로 해결할 수는 없다. 다행히 얼굴 아래쪽 (코 아래의 얼굴 영역)은 거의 가려지지 않으며 중심 좌표가 전체 머리 위치를 대략적으로 나타낼 수 있다.
따라서 $(l_1, l_2)$의 두 중심 좌표 사이의 수평 편차 $\Delta w$를 측정하고 source head를 이동시켜 source body와 정렬한다. 이는 목의 위쪽 경계를 정렬하는 것과 같다. 이 트릭은 neck alignment 문제를 파라미터 학습 없이 해결하며 하위 모델이 더 사실적인 결과를 생성하도록 보장한다. 또한, 머리가 회전할 수 있기 때문에 두 source 이미지의 얼굴 원점이 다르더라도 이 트릭은 결과의 기하학적 현실성을 향상시킨다.
Experiment
- 데이터셋: Stylish-Humans-HQ Dataset (SHHQ-1.0)
- 39,942개의 full-body 이미지가 몸 중앙으로 정렬되어 있음
- face alignment 테크닉으로 데이터셋을 재처리하고 상반신만 잘라내어 사용
- SOTA human parsing method인 SCHP을 사용하여 상반신 이미지의 semantic layout을 얻음
- 학습 셋 35,942개, 테스트 셋 4,000개
- Implementation Details
- latent code의 downsampling factor $f = 4$ (LDM의 가장 좋은 세팅)
- Adam optimizer ($\beta_1 = 0.5$, $\beta_2 = 0.999$)
- $\lambda_1 = 1$, $\lambda_2 = 0.2$
- 8개의 NVIDIA V100 GPU 사용
Mask-FID: 머리와 몸 영역을 마스킹하고 inpainting 영역을 노출하도록 설정한 다음 FID 계산.
Focal-FID: 생성된 transition region이 상반신 이미지의 중앙에 위치하므로 중간 1/2 영역을 수평적, 수직적으로 잘라내고 FID를 계산.
1. Comparison
Qualitative comparison

Quantitative comparison

(상반신 SHHQ256 데이터셋에서 측정)
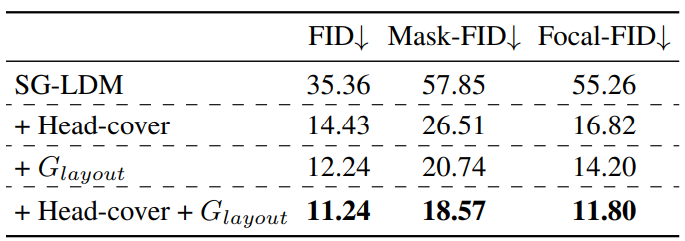
2. Ablation Study
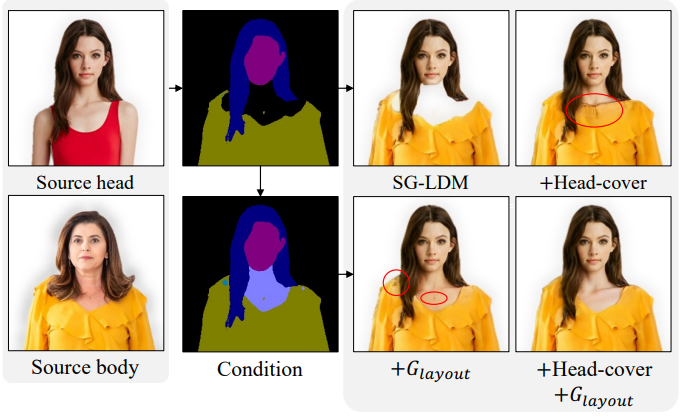
3. Head Replacement with Fake
실제 이미지 $x$의 머리를 가짜로 교채하고 싶은 경우, 머리와 목 영역의 $z_T$만 $\mathcal{N}(0,I)$에서 랜덤하게 샘플링한 다음 보존된 몸 영역 $z_t^B$와 혼합하면 된다.
