[논문리뷰] Segment Anything in High Quality (HQ-SAM)
NeurIPS 2023. [Paper] [Github]
Lei Ke, Mingqiao Ye, Martin Danelljan, Yifan Liu, Yu-Wing Tai, Chi-Keung Tang, Fisher Yu
ETH Zürich | HKUST | Dartmouth College
2 Jun 2023

Introduction
다양한 객체를 정확하게 분할하는 것은 광범위한 장면 이해의 기본이다. 수십억 규모의 마스크 레이블로 학습된 Segment Anything Model (SAM)이 최근 일반 이미지 분할을 위한 기본 비전 모델로 출시되었다. SAM은 점, bounding box, 대략적인 마스크로 구성된 프롬프트를 입력으로 사용하여 다양한 시나리오에서 광범위한 객체, 부분, 시각적 구조를 분할할 수 있다. Zero-shot segmentation 능력은 간단한 프롬프트를 통해 수많은 애플리케이션에서 사용할 수 있기 때문에 패러다임의 급격한 변화를 가져왔다.
SAM은 인상적인 성능을 달성했지만 분할 결과는 많은 경우 여전히 만족스럽지 않다. 특히 SAM은 다음과 같은 두 가지 주요 문제를 안고 있다.
- 종종 얇은 객체 구조의 분할을 무시하는 경우가 많다.
- 깨진 마스크나 까다로운 케이스에 큰 오차가 발생한다.
이는 SAM이 얇은 구조를 잘못 해석하는 것과 관련이 있는 경우가 많다. 이러한 유형의 오차는 자동화된 주석이나 이미지/동영상 편집과 같이 SAM의 적용 가능성과 효율성을 심각하게 제한한다.
본 논문은 SAM의 강력한 zero-shot 능력과 유연성을 손상시키지 않으면서 매우 어려운 케이스에서도 매우 정확한 segmentation mask를 예측할 수 있는 HQ-SAM을 제안하였다. 효율성과 zero-shot 성능을 유지하기 위해 SAM에 0.5% 미만의 파라미터를 추가하여 고품질 분할 능력을 확장하는 최소한의 적응만을 허용한다.
SAM 디코더를 직접 fine-tuning하거나 새로운 디코더 모듈을 도입하면 zero-shot segmentation 성능이 심각하게 저하된다. 따라서 본 논문은 zero-shot 성능을 완전히 보존하기 위해 기존 학습된 SAM 구조와 긴밀하게 통합하고 재사용하는 HQ-SAM 아키텍처를 제안하였다. 먼저, 원래 프롬프트와 출력 토큰과 함께 SAM의 마스크 디코더에 입력되는 학습 가능한 HQ 출력 토큰을 설계하였다. 원래 출력 토큰과 달리 HQ 출력 토큰과 관련 MLP layer는 고품질 segmentation mask를 예측하도록 학습되었다. 둘째, SAM의 마스크 디코더 feature만 재사용하는 대신 HQ 출력 토큰은 정확한 마스크 디테일을 얻기 위해 개선된 feature들로 작동한다. 특히 SAM의 마스크 디코더 feature들을 ViT 인코더의 초기 및 나중 feature map과 융합하여 글로벌한 semantic 컨텍스트와 로컬한 fine-grained feature들을 모두 사용한다. 학습 중에는 사전 학습된 전체 SAM 파라미터를 동결하고 HQ 출력 토큰, 관련 3-layer MLP, 작은 feature 융합 블록만 업데이트한다.
정확한 segmentation을 학습하려면 복잡하고 세부적인 기하학적 구조를 가진 다양한 객체에 대한 정확한 마스크 주석이 포함된 데이터셋이 필요하다. SAM은 1,100만 개의 이미지가 포함된 SA-1B 데이터셋에서 학습하였으며, 여기에는 SAM과 유사한 모델에 의해 자동으로 생성된 11억 개의 마스크가 포함된다. 그러나 이 광범위한 데이터셋을 사용하면 상당한 비용이 나타나며 원하는 고품질 마스크 생성을 달성하지 못한다. 결과적으로 저자들은 HQSeg-44K라는 새로운 데이터셋을 구성하였으며, 4.4만 개의 매우 세밀한 이미지 마스크 주석이 포함되어 있다. HQSeg-44K는 1,000개 이상의 다양한 semantic 클래스를 포괄하는 매우 정확한 마스크 라벨과 6개의 기존 이미지 데이터셋을 병합하여 구성된다. 소규모 데이터셋과 최소한의 통합 아키텍처 덕분에 HQ-SAM은 8개의 RTX 3090 GPU에서 단 4시간 만에 학습할 수 있다.
Method
1. Preliminaries: SAM
SAM은 세 가지 모듈로 구성된다.
- 이미지 인코더: 이미지 feature 추출을 위한 대규모 ViT 기반 backbone으로, 공간 크기 64$\times$64에 이미지를 임베딩한다.
- 프롬프트 인코더: 마스크 디코더에 제공하기 위해 입력 포인트, 박스, 마스크의 인터랙티브한 위치 정보를 인코딩한다.
- 마스크 디코더: 2-layer transformer 기반 디코더이며, 추출된 이미지 임베딩과 최종 마스크 예측을 위한 프롬프트 토큰을 모두 사용한다.
SAM 모델은 자동으로 생성된 10억 개 이상의 마스크와 1,100만 개의 이미지를 포함하는 대규모 SA-1B 데이터셋에서 학습되었다. 따라서 SAM은 추가 학습 없이도 새로운 데이터에 대한 가치 있고 강력한 zero-shot 일반화를 보여준다. 그러나 SA-1B에서 2 epochs 동안 ViT-H 기반 SAM을 분산적으로 학습하려면 256개 이미지의 대규모 batch size를 갖춘 256개의 GPU가 필요하기 때문에 SAM 학습은 매우 비용이 많이 든다.
2. HQ-SAM
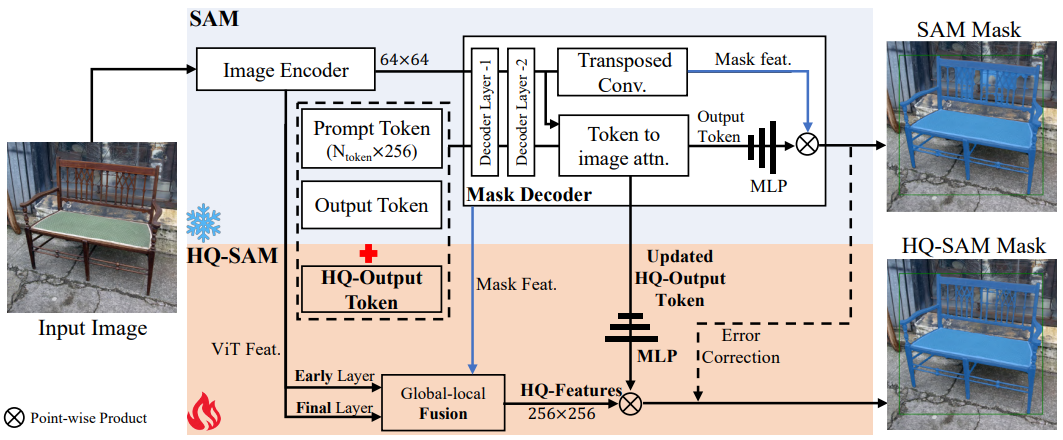
2.1 고품질 출력 토큰
본 논문은 SAM의 마스크 품질 향상을 위한 효율적인 토큰 학습을 제안하였다. 위 그림에서 볼 수 있듯이 SAM의 원래 마스크 디코더 디자인에서는 출력 토큰이 마스크 예측에 채택되어 동적 MLP 가중치를 예측한 다음 마스크 feature들과 point-wise product를 수행한다. HQ-SAM에서 SAM의 마스크 품질을 향상시키기 위해 SAM의 대략적인 마스크를 입력으로 직접 사용하는 대신 고품질 마스크 예측을 위한 HQ-Output 토큰과 새로운 마스크 예측 레이어를 도입한다.
SAM의 마스크 디코더를 재사용하고 수정함으로써 새로운 학습 가능한 HQ 출력 토큰(1$\times$256)이 SAM의 출력 토큰(4$\times$256)과 프롬프트 토큰($N_\textrm{prompt} \times 256$)과 concatenate되어 마스크 디코더의 입력으로 사용된다. 원래 출력 토큰과 유사하게 각 attention layer에서 HQ-Output 토큰은 먼저 다른 토큰과 함께 self-attention을 수행한 다음 feature 업데이트를 위해 token-to-image와 image-to-token attention을 모두 수행한다. HQ-Output 토큰은 각 디코더 레이어의 다른 토큰이 공유하는 point-wise MLP를 사용한다. 업데이트된 HQ 출력 토큰은 두 개의 디코더 레이어를 통과한 후 글로벌 이미지 컨텍스트, 프롬프트 토큰의 중요한 기하학적 및 유형 정보, 기타 출력 토큰의 마스크 정보에 액세스할 수 있다. 마지막으로, 새로운 3-layer MLP를 추가하여 업데이트된 HQ 출력 토큰에서 동적 convolutional kernel을 생성한 다음 고품질 마스크 생성을 위해 융합된 HQ feature를 사용하여 공간적으로 point-wise product를 수행한다.
SAM을 직접 fine-tuning하거나 대규모 정제 후 네트워크를 추가하는 대신 SAM 출력 토큰의 마스크 오차를 수정하기 위해 HQ 출력 토큰과 관련 3-layer MLP만 학습시킬 수 있다. 이는 기존의 고품질 segmentation 모델과는 완전히 다르다. 저자들은 광범위한 실험을 통해 효율적인 토큰 학습의 두 가지 주요 이점을 확인하였다.
- 이 전략은 원래 SAM에 비해 무시할 만한 파라미터만 도입하면서 SAM의 마스크 품질을 크게 향상시켜 HQ-SAM 학습을 굉장히 시간 및 데이터 효율적으로 만든다.
- 학습된 토큰과 MLP layer는 특정 데이터셋의 주석 편향을 가리기 위해 과적합(overfitting)되지 않으므로 기존 지식을 잊어버리지 않고 새 이미지에 대해 SAM의 강력한 zero-shot segmentation 능력을 유지한다.
2.2 고품질 feature들을 위한 글로벌-로컬 융합
또한 매우 정확한 분할에는 풍부한 글로벌 semantic 컨텍스트와 로컬한 경계 디테일이 모두 포함된 입력 이미지 feature가 필요하다. 마스크 품질을 더욱 향상시키기 위해 SAM의 마스크 디코더 feature에서 상위 레벨 객체 컨텍스트와 하위 레벨 경계/가장자리 정보를 모두 강화한다. SAM의 마스크 디코더 feature를 직접 사용하는 대신 다음과 같이 SAM 모델의 여러 단계에서 feature를 추출하고 융합하여 새로운 고품질 feature (HQ-Features)을 구성한다.
- 보다 일반적인 이미지 가장자리/경계 세부 정보를 캡처하는 64$\times$64 크기의 SAM ViT 인코더의 초기 레이어 로컬 feature
- 더 많은 글로벌 이미지 컨텍스트 정보를 갖는 64$\times$64 크기의 SAM ViT 인코더의 최종 레이어 글로벌 feature
- 강력한 마스크 모양 정보가 포함되어 있으며 출력 토큰에서도 공유되는 256$\times$256 크기의 SAM 마스크 디코더의 마스크 feature
초기 레이어 로컬 feature는 구체적으로 ViT 인코더의 첫 번째 global attention block 이후의 feature를 추출하며, ViT-Large 기반 SAM의 경우 이는 총 24개 블록에 대한 6번째 블록 출력이다.
입력 HQ-Feature를 얻기 위해 먼저 transposed convolution을 통해 초기 레이어와 최종 레이어의 인코더 feature를 256$\times$256으로 업샘플링한다. 그런 다음 간단한 convolution을 거쳐 element-wise 방식으로 이 세 가지 유형의 feature를 더한다. 이 글로벌-로컬 feature 융합은 간단하면서도 효과적이며 작은 메모리 공간과 계산 부담으로 디테일을 보존하는 segmentation 결과를 생성한다.
3. Training and Inference of HQ-SAM
- 학습 데이터 구성
- SA-1B에 대한 추가 학습 대신 44,320개의 매우 정확한 이미지 마스크 주석이 포함된 새로운 학습 데이터셋인 HQSeg-44K를 구성
- SA-1B 데이터셋에는 자동으로 생성된 마스크 레이블만 포함되어 있어 복잡한 구조를 가진 객체에 대한 매우 정확한 수동 주석이 누락되어 있음
- DIS (train set), ThinObject-5K (train set), FSS-1000, ECSSD, MSRA10K, DUT-OMRON을 포함한 6개의 기존 이미지 데이터셋 컬렉션을 매우 세밀한 마스크 라벨링과 함께 활용
- 1,000개 이상의 다양한 semantic 클래스 포함
- 학습 디테일
- 학습 가능한 파라미터: HQ-Output 토큰, 관련 3-layer MLP, HQ-Feature 융합을 위한 3개의 간단한 convolution
- Bounding box, 무작위로 샘플링된 포인트, 대략적인 마스크 입력을 포함한 혼합 유형의 프롬프트를 샘플링
- GT 마스크의 경계 영역에 임의의 Gaussian noise를 추가하여 degrade된 마스크를 생성
- 다양한 객체 스케일에 대한 일반화를 위해 large-scale jittering을 사용
- learning rate: 0.001 (10 epochs learning rate 감소)
- epochs: 12
- 총 batch size: 32
- 8개의 Nvidia GeForce RTX 3090 GPU에서 학습하는 데 4시간 소요
- Inference
- HQ-Output 토큰의 마스크 예측을 사용
- 256$\times$256에서 SAM 마스크(출력 토큰)와 예측 마스크(HQ-Output 토큰)의 예측 logit을 합산한 다음 1024$\times$1024로 업샘플링
아래 표는 ViT-L 기반의 SAM과 HQ-SAM의 학습과 inference를 비교한 표이다.

Experiments
1. Ablation Experiments
다음은 4가지 세밀한 segmentation 데이터셋에서의 HQ-Output 토큰에 대한 ablation study 결과이다.
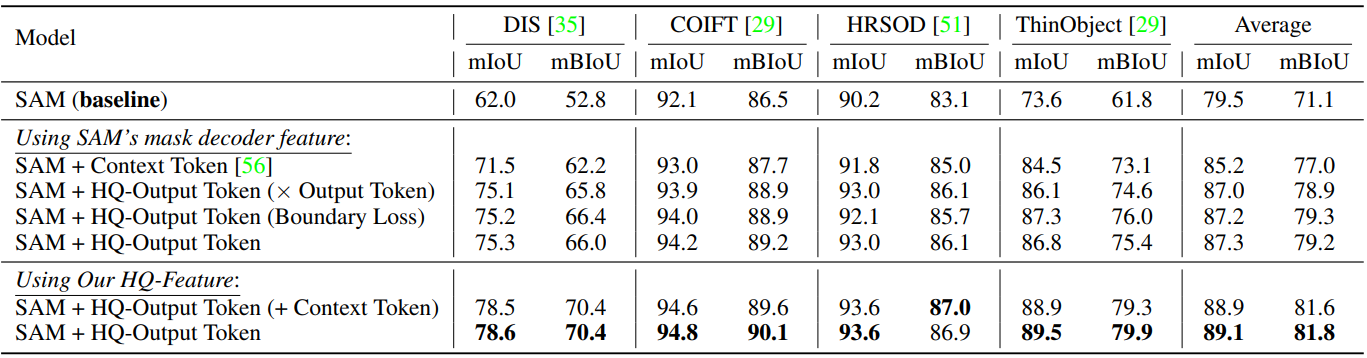
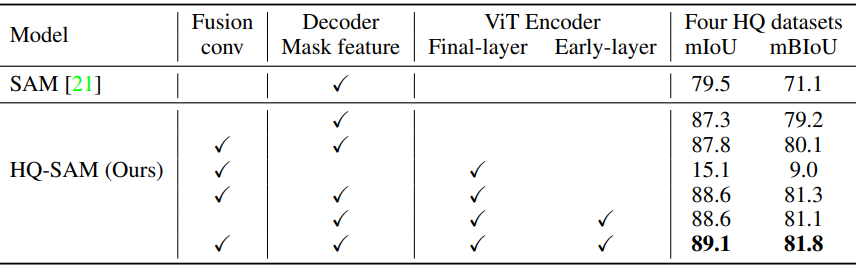
다음은 HQ-Feature 소스에 대한 ablation study 결과이다.
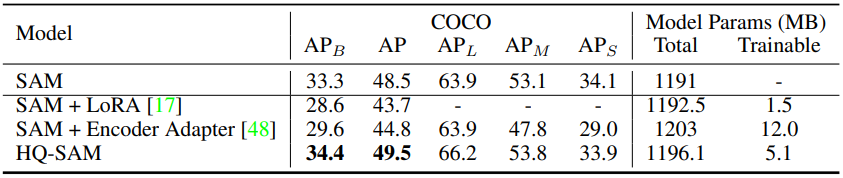
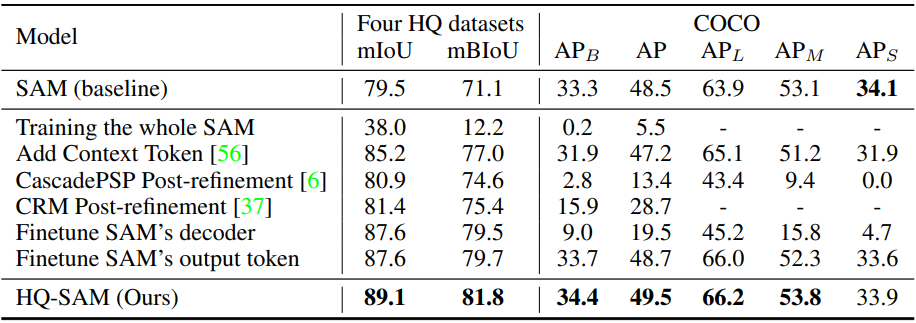
다음은 모델 fine-tuning 및 추가 후처리 방법과 비교한 표이다.
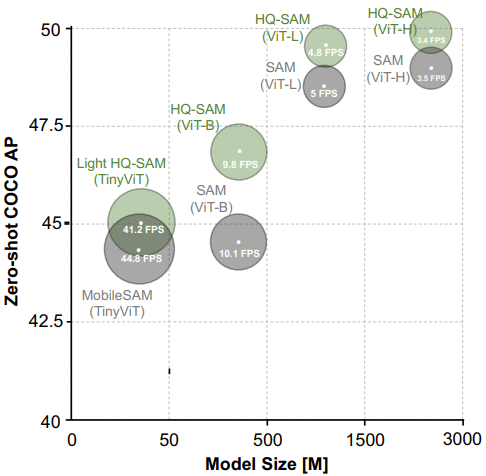
다음은 SAM과 HQ-SAM의 recall rate를 비교한 그래프이다.

2. Zero-shot Comparison with SAM
다음은 UVO에서의 zero-shot 오픈월드 instance segmentation 결과를 비교한 표이다.

다음은 고품질 BIG 벤치마크에서의 zero-shot segmentation 결과를 비교한 표이다.

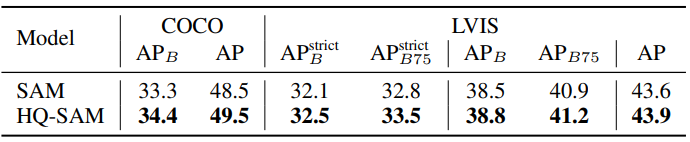
다음은 COCO와 LVISv1에서의 zero-shot instance segmentation 결과를 비교한 표이다.
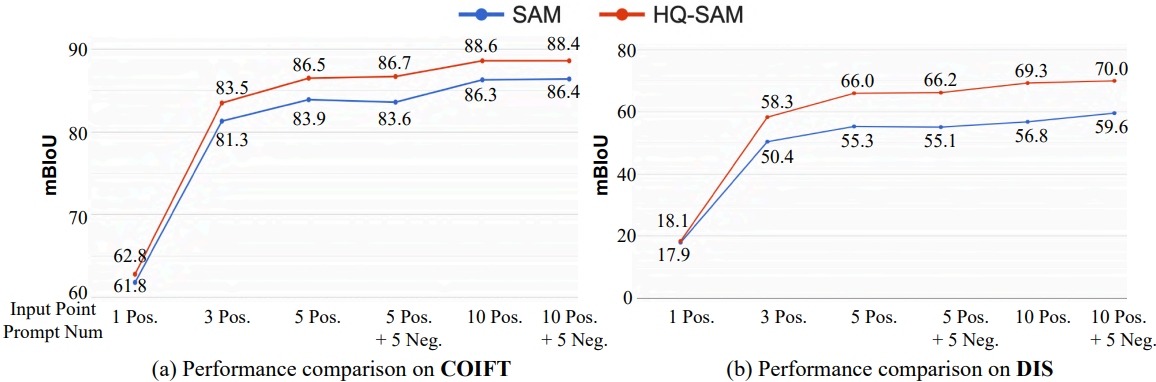
다음은 COIFT와 DIS에서의 interactive segmentation 결과를 비교한 그래프이다.
다음은 HQ-YTVIS에서의 zero-shot 동영상 instance segmentation 결과를 비교한 표이다.

다음은 SAM의 원래 토큰과 HQ-Output 토큰의 마지막 디코더 레이어의 cross-attention map을 비교한 것이다.

다음은 SAM(위)과 HQ-SAM(아래)의 시각적 결과를 비교한 것이다.

다음은 HQSeg-44K를 사용한 Adapter Tuning과 LoRA를 HQ-SAM과 비교한 표이다.