[논문리뷰] Honeybee: Locality-enhanced Projector for Multimodal LLM
CVPR 2024. [Paper] [Github]
Junbum Cha, Wooyoung Kang, Jonghwan Mun, Byungseok Roh
Kakao Brain
11 Dec 2023

Introduction
이미지를 인식하고 이해하기 위해 LLM을 Large Multimodal Model (LMM)으로 확장하기 위해 visual instruction tuning이 제안되었다. LMM의 주요 아이디어는 비전 인코더와 LLM을 연결하는 projector를 도입하고 비전 인코더와 LLM의 파라미터를 유지하면서 vision instruction 데이터를 사용하여 projector를 학습시키는 것이다. 이를 통해 비전 인코더와 LLM의 사전 학습된 지식과 능력을 보존하고 활용할 수 있다.
LMM에서 projector는 다음 두 가지 측면에서 중요한 역할을 한다.
- 성능: 언어 모델이 이해할 수 있도록 visual feature를 visual token으로 변환하여 비전 인코더와 언어 모델을 연결하므로 visual token의 품질이 LMM의 전반적인 성능에 직접적으로 영향을 미친다.
- 효율성: 대부분의 계산 부담이 언어 모델에 있기 때문에 LMM의 효율성은 언어 모델에 입력되는 visual token의 수에 크게 영향을 받는다.
그러나 projector의 중요성에도 불구하고 기존 연구들에서 projector는 상대적으로 연구되지 않았으며 대부분의 LMM은 단순히 linear projector 또는 abstractor를 채택하였다.

특히 최근 LMM은 linear projector보다 abstractor (ex. resampler, Q-former)를 선호한다. 이는 visual token 수를 유연하게 처리하여 효율성과 성능 간의 적절한 trade-off를 달성하기 위한 다양한 디자인 옵션을 제공하기 때문이다. 그러나 abstractor는 linear projector에 비해 공간 이해 task를 학습하는 데 더 많은 어려움을 겪는다. 이러한 어려움은 abstractor에 locality를 보존하는 디자인이 부족하기 때문이다. 이로 인해 주로 소수의 영역에 집중하게 되므로 공간 이해에 필수적인 세밀한 디테일이 손실된다. 반면, linear projector는 일대일 변환을 통해 visual feature의 모든 로컬 컨텍스트를 보존하는 데 탁월하다.
본 논문은 linear projector의 성능과 abstractor의 효율성 사이에서 보다 유리한 trade-off를 나타내는 새로운 locality가 강화된 projector인 Honeybee를 제안하였다. 구체적으로 locality 모델링에 두 가지 강력한 연산인 convolution과 deformable attention을 사용하여 총 2개의 projector를 제안하였다. 추상화 프로세스에 locality-aware 디자인을 주입하면 복잡한 시각적 정보를 처리하는 LMM의 전반적인 성능 향상을 촉진할 뿐만 아니라 계산 효율성을 활용할 수도 있다.
저자들은 추가로 SOTA LMM을 위한 비밀 레시피도 제공하였다. 최근 LMM 학습에는 여러 instruction 데이터가 포함된다.
- GPT로 만든 instruction-following 데이터셋 (ex. LLaVA)
- Instructization 프로세스가 포함된 비전-언어 task 데이터셋
이러한 데이터셋의 이점을 극대화하기 위해 다각적인 instruction 데이터를 활용하는 방법과 instructization 프로세스를 위한 효과적인 방법에 대한 디자인 선택을 제시하였다.
Honeybee: Locality-enhanced LMM
1. Locality-enhanced Projector
Motivation
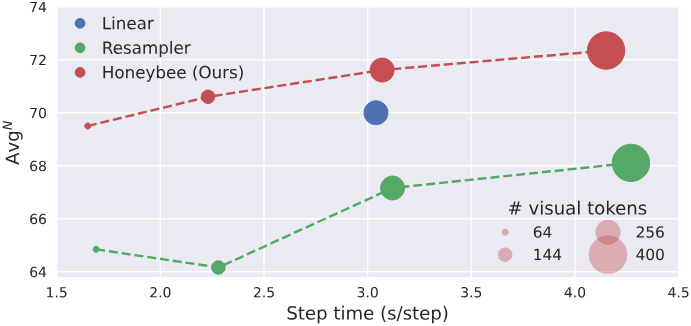
Projector는 비전 모델과 언어 모델을 연결하고 이미지 feature를 언어 모델에서 이해하고 활용할 수 있는 형식으로 변환하므로 매우 중요하다. 그 역할을 고려할 때 projector를 설계할 때 가장 중요한 요소는 결과 visual token 수를 결정하는 유연성이다. Projector에서 생성되는 visual token의 수는 LMM의 효율성과 계산량을 결정한다. 여러 개의 이미지 또는 큰 이미지를 처리하는 경우 확장성을 위해서는 visual token 수를 줄이는 유연성을 통해 효율성을 높이는 것이 필요하다. 이러한 이유로 최근 LMM에서는 linear projector보다 resampler나 Q-former와 같은 abstractor를 선호하게 되었다.
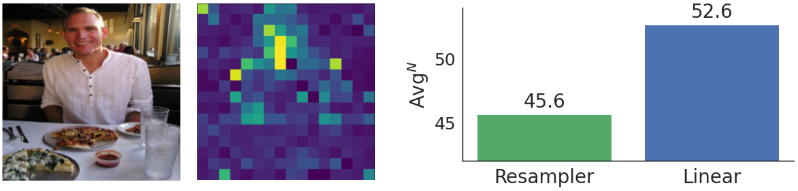
그러나 저자들은 resampler가 linear projector에 비해 공간 이해 task를 처리하는 데 어려움을 겪는다는 것을 관찰했다. Linear projector는 손실 없이 일대일 projection을 통해 visual feature의 모든 로컬 컨텍스트를 유지한다. 반면 resampler는 주로 몇 가지 영역의 정보를 요약하면서 일부 로컬한 영역의 디테일은 잠재적으로 간과하는 경향이 있다. 이러한 차이가 공간 이해 성능에 큰 영향을 미친다.
이러한 관찰을 바탕으로 저자들은 visual token 수에 대한 유연성을 제공하고 로컬 컨텍스트를 효과적으로 보존한다는 두 원칙에 따라 두 가지 새로운 projector인 C-Abstractor와 D-Abstractor를 제안하였다. 두 새로운 projector는 visual token 수 관리의 유연성을 통한 계산 효율성과 같은 abstractor의 장점을 유지하는 동시에 로컬 feature의 보존도 향상시키도록 설계되었다. 이러한 개선 사항은 복잡한 시각 정보를 처리하는 데 있어 LMM의 전반적인 성능을 향상시킬 뿐만 아니라 계산 효율성의 이점도 제공한다.
Architecture
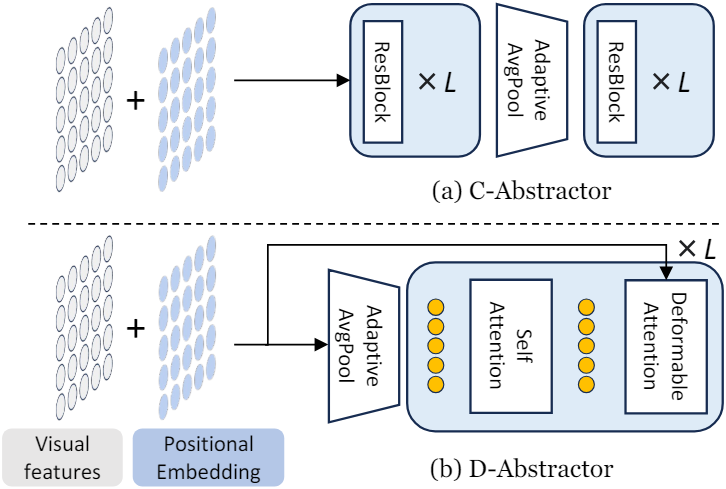
C-Abstractor
Convolution은 로컬 컨텍스트를 모델링하는 데 가장 성공적인 아키텍처이다. 저자들은 효과적인 로컬 컨텍스트 모델링을 위해 Convolutional Abstractor인 C-Abstractor를 설계하였다. C-Abstractor는 $L$개의 ResNet block, adaptive average pooling, 또 다른 $L$개의 ResNet block으로 구성된다. 이 디자인을 사용하면 visual feature를 임의의 제곱수의 visual token으로 추상화할 수 있으며 원래 visual feature 수보다 더 많은 visual feature에 projection할 수도 있다.
D-Abstractor
Convolution은 로컬 컨텍스트 모델링에서 성공적인 개념이지만 locality에 대해 지나치게 엄격한 inductive bias를 도입한다. 따라서 저자들은 유연성을 유지하면서 추상화 중에 resampler의 위치 인식을 향상시키는 Deformable attention 기반의 Abstractor인 D-Abstractor를 제안하였다. 특히, deformable attention은 영역적 컨텍스트를 보존하는 데 도움이 된다. 각 학습 가능한 쿼리는 레퍼런스 포인트와 그 근처에 초점을 맞춘 샘플링 오프셋들을 사용하여 2D 좌표 기반 샘플링 프로세스를 통해 visual feature를 수집한다. 그 대신 본 논문에서는 레퍼런스 포인트를 수동으로 초기화하여 전체 feature map에 균일하게 분포시킨다. 이 방법을 통해 D-Abstractor는 주어진 이미지에 대해 세밀하고 포괄적인 정보를 캡처할 수 있다.
2. Training
2단계 파이프라인으로 Honeybee를 학습시킨다.
- 비전-언어 정렬을 위한 사전 학습: 비전 인코더와 LLM을 고정하고 제안된 projector 학습에 중점을 둔다. 이미지-텍스트 데이터 (ex. BlipCapFilt, COYO)를 사용하는 사전 학습을 통해 LMM은 시각적 단서가 텍스트 설명과 어떻게 일치하는지에 대하여 이해할 수 있다.
- Visual instruction tuning: Projector와 LLM을 공동 학습시켜 instruction-following 능력을 향상시키고 보다 깊은 시각적 이해를 달성한다. Instruction-following을 위해 두 개의 GPT로 만든 instruction-following 데이터셋인 LLaVA와 ShareGPT를 활용한다. 또한 아래 표에 나열된 광범위한 데이터셋을 템플릿으로 instructize하여 사용한다.

Hidden Recipe for Visual Instruction Tuning
SOTA LMM을 학습시키기 위한 명확한 방법은 여전히 불분명하다. 템플릿 기반 instructization와 함께 기존 데이터셋을 사용하는 instruction tuning이 유익하다는 것은 널리 알려져 있지만, instructization 프로세스의 디테일은 아직 탐구되지 않았다. 즉, 데이터셋 선택, 활용, 조합 전략에 관한 질문이 계속 남아 있다. 본 논문은 5가지 관점으로 이러한 측면을 명확히 하는 것을 목표로 하였다.
데이터셋 조합
최근 LMM 연구에서는 다양한 범위의 데이터셋이 사용되었다. 그러나 특정 task에 중요한 데이터셋을 식별하기 위한 포괄적인 분석이 수반되지 않았다. 저자들은 데이터셋을 여러 task 그룹으로 분류한 다음 instruction tuning 과정에서 각 task 그룹을 순차적으로 제외하여 벤치마크 성능의 변화를 살펴보았다.
데이터셋 밸런싱
LMM 학습에 다양한 데이터셋을 사용할 수 있지만 데이터셋마다 크기가 크게 다르다. 또한 LMM을 학습할 때 사전 학습된 LLM에 대한 지식을 보존하기 위해 학습 iteration을 제한하는 것이 일반적이다. 결과적으로, 짧은 학습 동안 다양한 학습을 극대화하려면 학습 데이터셋의 적절한 균형을 맞추는 것이 중요하다. 저자들은 이를 조사하기 위해 4가지 서로 다른 밸런싱 전략을 비교하였다.
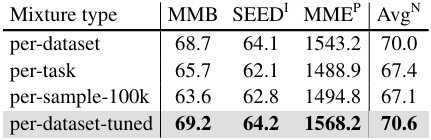
- per-dataset: 각 데이터셋에 대한 균일 샘플링
- per-task: 각 task에 대한 균일 샘플링
- per-sample-100k: 각 샘플에 대한 균일 샘플링. 각 데이터셋의 최대 크기는 10만이다.
- per-dataset-tuned: 데이터셋별 전략을 기반으로 경험적으로 조정된 밸런싱
템플릿 세분성
기존 데이터셋을 instruction 형식으로 변환하기 위해 사전 정의된 템플릿을 사용하는 것이 일반적이지만 이러한 템플릿을 적용하기 위한 적절한 세분성은 명확하게 설정되어 있지 않다. 저자들은 템플릿 세분성이 서로 다른 두 가지 접근 방식을 비교하였다.
- fine-grained: 각 데이터셋에 고유한 템플릿을 적용
- coarse-grained: 동일한 task 카테고리 내의 데이터셋에 공유 템플릿을 적용
템플릿 다양성
GPT로 만든 대화 데이터셋이 등장하기 전에는 템플릿 다양성을 확보하는 것이 중요했으며, 입력 반전 전략과 함께 미리 정의된 다양한 템플릿을 사용하는 경우가 많았다. 그러나 GPT로 만든 데이터셋의 도입으로 인해 템플릿의 다양성에 대한 강조가 줄어들었다. GPT로 만든 데이터셋의 맥락에서 여러 템플릿과 입력 반전 기술을 사용하는 것의 정확한 역할과 중요성은 아직 잘 알려져 있지 않다. 저자들은 단일 템플릿, 다중 템플릿, 입력 반전이 있는 다중 템플릿을 비교하였다.
Multi-turn 템플릿
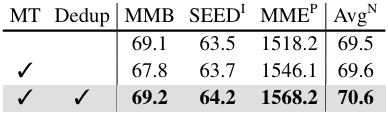
이미지당 여러 QA 쌍이 있는 VQA 데이터셋에서 볼 수 있듯이 기존 데이터셋을 활용할 때 하나의 이미지에 대해 여러 입력-대상 쌍을 찾는 것이 일반적이다. Mutli-turn 전략은 이러한 쌍을 대화와 유사한 하나의 multi-turn 예시로 병합한다. 그러나 이 접근 방식은 의미상 중첩된 입력-대상 쌍을 하나의 예로 병합할 수 있으며, 특히 LMM의 autoregressive 학습에서 답변을 찾는 데 있어 단순한 shortcut을 잠재적으로 장려할 수 있다. 이를 완화하기 위해 multi-turn 턴 예제에서 의미상 중복된 입력-타겟 쌍을 제거하여 shortcut 학습을 방지하는 추가 중복 제거 전략을 도입하였다.
Experiments
- 구현 디테일
- LLM: Vicuna-v1.5 (7B, 13B)
- 비전 인코더: CLIP ViTL/14
- 해상도: 7B는 224, 13B는 336
- 마지막 레이어 대신 뒤에서 두 번째 레이어의 feature를 사용
1. Analysis on Locality-Enhanced Projector
다음은 projector에 따른 공간 이해 능력을 비교한 표이다.
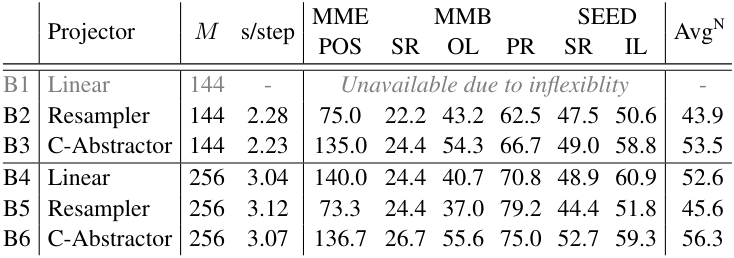
- POS: mean Position
- SR: Spatial Relationship
- OL: Object Localization
- PR: Physical Relation
- IL: Instance Location
- AvgN: 6가지 task의 정규화된 평균
- $M$: visual token 수
- s/step: 사전 학습 시 하나의 step에 대한 실행 시간
2. Hidden Recipe for Visual Instruction Tuning
다음은 데이터 조합에 대한 결과이다.
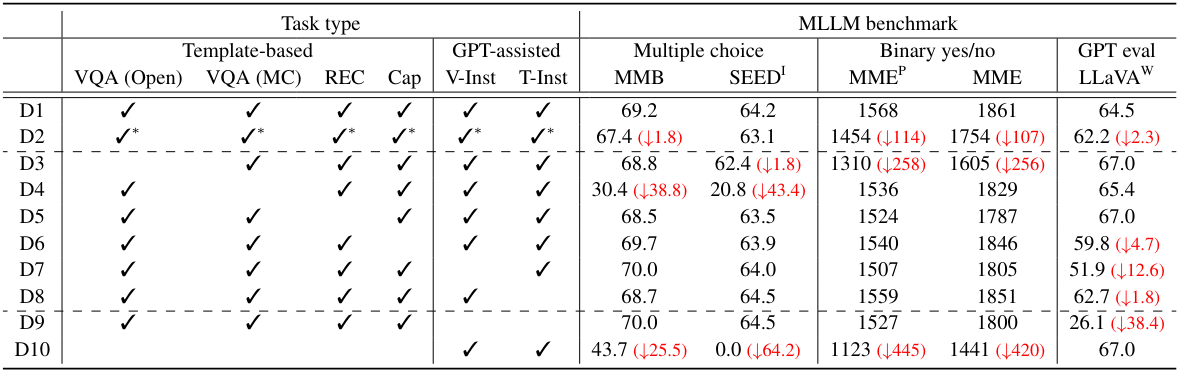
- VQA (Open): open-ended visual question answering
- VQA (MC): visual question answering with multiple choice
- REC: referring expression comprehension
- Cap: captioning
- V-Inst: visual instruction
- T-Inst: text-only instruction-following
✓*</br>: 각 task 타입에 하나의 데이터셋만 사용
다음은 (왼쪽) 데이터셋 밸런싱과 (오른쪽) instruction tuning vs. multi-task learning에 대한 결과이다.
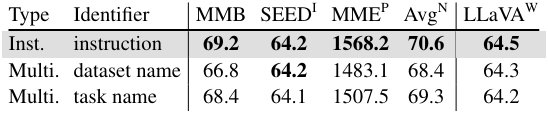
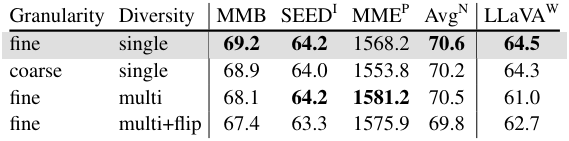
다음은 (왼쪽) 템플릿 세분성 및 다양성과 (오른쪽) multi-turn 및 중복 제거 전략에 대한 결과이다.
3. Putting It Altogether
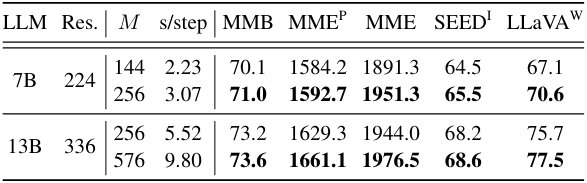
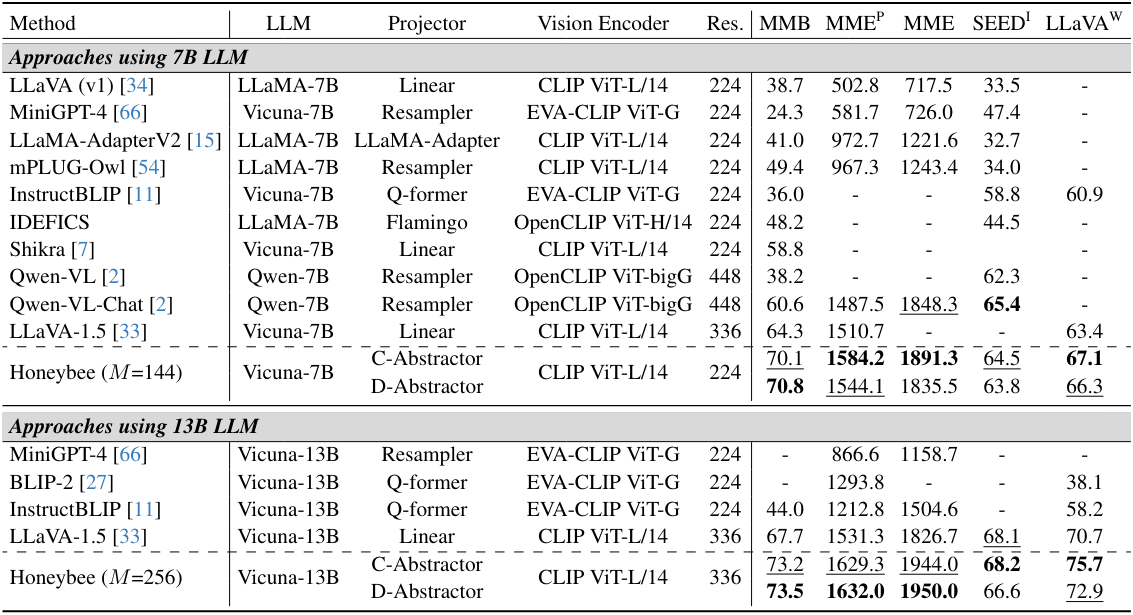
다음은 SOTA LMM과 비교한 표이다.
다음은 C-Abstractor의 visual token 수 $M$을 늘렸을 때의 결과이다.