[논문리뷰] Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
ICML 2023 Oral. [Paper] [Github]
Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer
Meta AI, FAIR | Georgia Tech | Johns Hopkins University
1 Jun 2023

Introduction
Vision Transformer (ViT)는 컴퓨터 비전에서 여러 task를 지배해 왔다. 구조적으로 단순하지만 정확성과 확장성으로 인해 오늘날에도 여전히 인기 있는 선택이다. 게다가 단순하기 때문에 Masked Autoencoder (MAE)와 같은 강력한 pretraining 전략을 사용할 수 있어 ViT를 계산적으로, 데이터 효율적으로 학습할 수 있다.
그러나 이러한 단순성에는 비용이 따른다. 네트워크 전체에서 동일한 공간 해상도와 채널 수를 사용함으로써 ViT는 파라미터를 비효율적으로 사용한다. 이는 이전의 “계층적” 또는 “멀티스케일” 모델과 대조적이다. 이러한 모델들은 초반에는 간단한 feature, 높은 공간 해상도, 적은 채널을 사용하고, 후반에는 복잡한 feature, 낮은 공간 해상도, 많은 채널을 사용한다.
이러한 계층적 디자인을 사용하는 Swin 또는 MViT와 같은 여러 도메인별 ViT가 도입되었다. 그러나 이러한 모델들은 ViT가 어려움을 겪는 ImageNet-1K에서 supervised learning을 사용하여 SOTA 결과를 얻기 위해 특수 모듈을 추가함에 따라 점점 더 복잡해졌다. 이러한 변경 사항은 좋은 FLOPs의 효과적인 모델을 생성하지만, 추가된 복잡성으로 인해 모델이 전반적으로 더 느려진다.
저자들은 많은 부분이 실제로 불필요하다고 주장한다. ViT는 초기 patchify 연산 후 inductive bias가 없기 때문에 많은 변경 사항은 수동으로 공간적인 inductive bias를 추가하는 데 사용된다. 하지만 대신 모델이 이러한 inductive bias를 학습하도록 할 수 있다면 아키텍처 속도를 늦출 필요가 없다. 특히 MAE pretraining은 ViT에 공간적 추론을 가르치는 데 매우 효과적인 도구로 입증되었다. 게다가 MAE pretraining은 sparse하며 일반적인 supervised learning보다 4~10배 더 빠를 수 있어 정확도 이상의 측면에서 이미 여러 도메인에서 바람직한 대안이 되었다.
저자들은 간단한 전략으로 이 가설을 테스트하였다. 몇 가지 구현 트릭을 사용하여 기존의 계층적 ViT (ex. MViTv2)를 가져와 MAE로 학습시키고 불필요한 구성 요소를 조심스럽게 제거하였다. MAE를 이 새로운 아키텍처에 맞게 조정하면 정확도를 높이는 동시에 모든 transformer가 아닌 구성 요소를 단순화하거나 제거할 수 있음을 발견했다. 그 결과, 불필요한 요소가 없는 매우 효율적인 모델이 탄생했으며, convolution, shifted window, cross-shaped window, decomposed relative position embedding이 전부 없다.
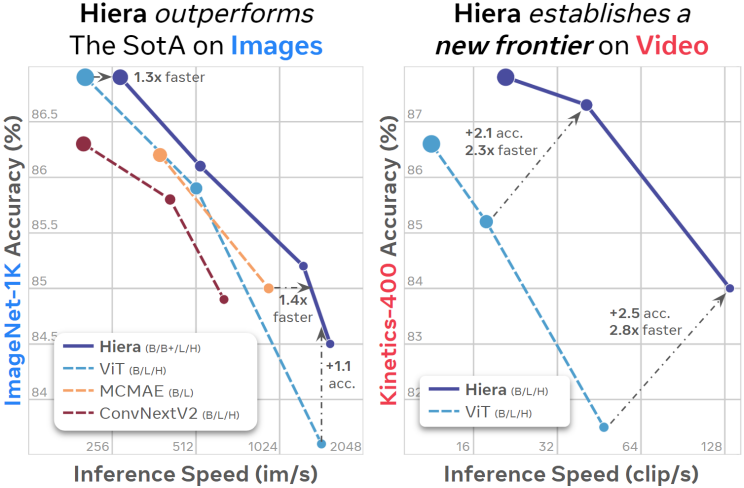
본 논문의 Hierarchical Vision Transformer (Hiera)는 여러 모델 크기, 도메인, task에서 이전 방법들보다 빠르고 정확한 순수하고 간단한 계층적 ViT이다. Hiera는 이미지에 대한 SOTA보다 성능이 뛰어나며 동영상에 대한 이전 방법들을 크게 능가한다.
Approach
본 논문의 목표는 무엇보다도 간단한 강력하고 효율적인 멀티스케일 ViT를 만드는 것이다. 저자들은 비전 task에서 높은 정확도를 얻기 위해 convolution, shifted window, attention bias와 같은 특수 모듈이 필요하지 않다고 주장한다. 이러한 특수 모듈들은 일반 ViT에 없는 강력한 공간적 bias를 추가하기 때문에 제거하기 어려워 보일 수 있다.
그러나 저자들은 다른 전략을 사용하였다. 복잡한 구조적 변경을 통해 공간적인 inductive bias를 추가하는 대신, 강력한 pretext task를 통해 이러한 inductive bias를 모델에 학습시킨다. 이 아이디어의 효능을 보이기 위해 저자들은 기존의 계층적 ViT를 가져와 강력한 pretext task로 학습시키는 동안 특수 모듈들을 제거하였다.
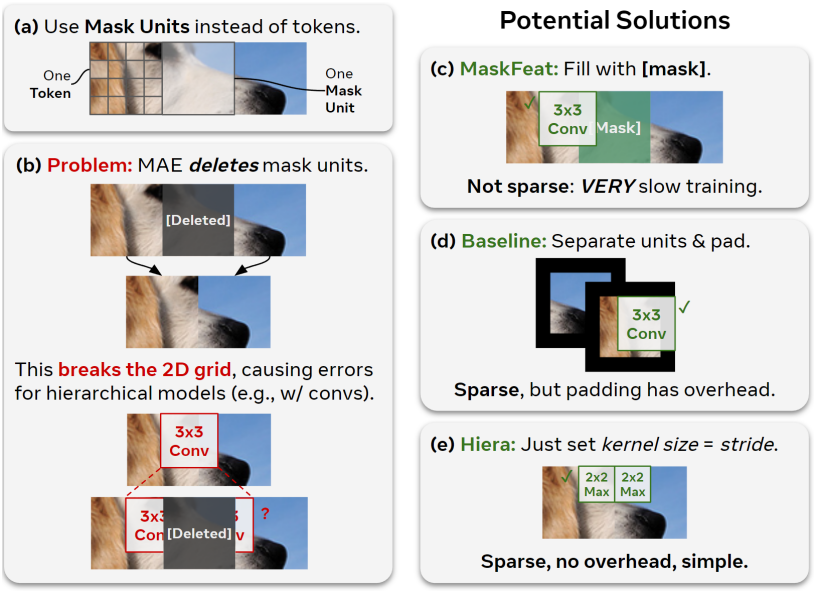
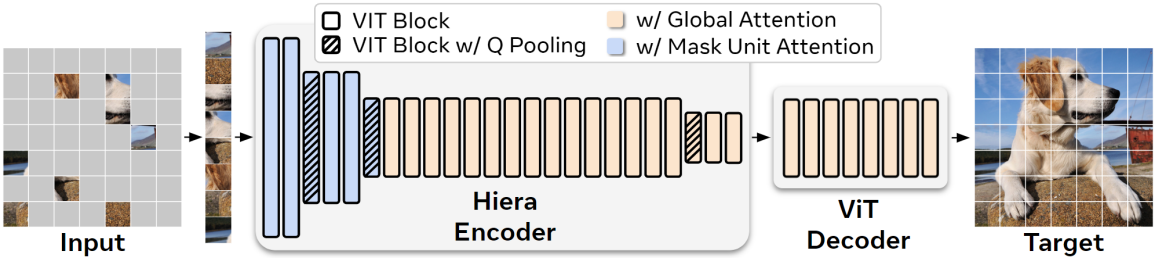
Pretext task의 경우, Masked Autoencoder (MAE)를 사용하는데, 이는 네트워크가 마스킹된 입력 패치를 재구성함으로써 다운스트림 task에 대한 localization 능력을 ViT에 학습시키는 데 효과적이다. MAE pretraining은 sparse하다. 즉, 마스킹된 토큰은 다른 마스킹된 이미지 모델링 접근 방식에서처럼 덮어쓰는 대신 제거된다. 이는 pretraining을 효율적으로 만들지만, 기존 계층적 모델이 의존하는 2D 그리드를 깨기 때문에 문제를 일으킨다. 게다가 MAE는 개별 토큰을 마스킹하는데, ViT의 경우 큰 16$\times$16 패치이지만 대부분의 계층적 모델의 경우 작은 4$\times$4 패치만 마스킹한다.
이 두 가지 문제를 모두 해결하기 위해 토큰과 “mask unit”을 구별한다. Mask unit는 MAE 마스킹을 적용한 해상도인 반면 토큰은 모델의 내부 해상도이다. 본 논문에서는 32$\times$32 픽셀 영역을 마스킹한다. 즉, 하나의 mask unit은 네트워크 시작 시 8$\times$8 토큰이다. 이 구별을 한 후에는 영리한 트릭을 사용하여 mask unit을 다른 토큰과 분리된 연속된 것으로 처리하여 계층적 모델을 평가할 수 있다. 따라서 기존 계층적 ViT와 함께 MAE를 사용할 수 있다.
1. Preparing MViTv2
저자들은 mask unit으로 분리하고 각각 padding하였을 때 영향을 가장 적게 받는 작은 3$\times$3 kernel을 사용하는 MViTv2를 기본 아키텍처로 선택했다. 다른 transformer를 선택해도 비슷한 결과를 얻을 수 있다.
MViTv2
MViTv2는 계층적 모델이며, 4 stage에 걸쳐 멀티스케일 표현을 학습한다. 채널 용량은 작지만 공간 해상도가 높은 low-level feature를 모델링하는 것으로 시작한 다음, 각 stage에서 채널 용량을 늘리고 공간 해상도를 줄여 점점 더 복잡한 high-level feature를 모델링한다.
MViTv2의 주요 특징은 attention pooling으로, 여기서 feature는 로컬하게 집계된다. 일반적으로 3$\times$3 convolution을 사용하여 self-attention을 계산하기 전에 집계한다. Attention pooling에서 $K$와 $V$는 처음 두 stage에서 계산을 줄이기 위해 pooling되고, $Q$는 공간 해상도를 줄여 한 stage에서 다음 stage로 전환하기 위해 pooling된다.
또한 MViTv2는 absolute position embedding 대신 decomposed relative position embedding을 사용하며, attention 블록 내에서 pooling된 $Q$ 토큰 사이를 건너뛸 수 있는 residual pooling connection을 가지고 있다. 기본적으로 MViTv2의 pooling attention은 다운샘플링이 필요하지 않더라도 stride 1의 convolution을 포함한다.
MAE 적용
MViTv2는 총 3번 2$\times$2로 다운샘플링하고 토큰 크기로 4$\times$4 픽셀을 사용하기 때문에 32$\times$32 크기의 mask unit을 사용한다. 이렇게 하면 각 mask unit이 stage 1, 2, 3, 4에서 각각 64, 16, 4, 1개의 토큰에 해당하므로 각 mask unit이 각 stage에서 최소한 하나의 고유한 토큰을 커버할 수 있다. 그런 다음 convolution kernel이 삭제된 토큰으로 유입되지 않도록 mask unit을 batch 차원으로 이동하여 pooling을 위해 분리한 다음 (즉, 각 mask unit을 이미지 처리) 나중에 이동을 취소하여 self-attention이 여전히 글로벌하도록 한다.
2. Simplifying MViTv2
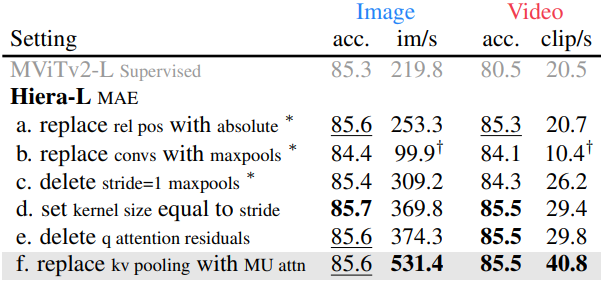
MAE로 학습시키면서 MViTv2의 필요 없는 구성 요소를 제거한다. 위 표에서 볼 수 있듯이 모든 구성 요소를 제거하거나 단순화하면서도 ImageNet-1K classification에서 높은 정확도를 유지할 수 있다. 저자들은 MViTv2-L을 사용하여 변경 사항이 스케일에 맞게 작동하도록 하였다.
Relative Position Embedding
MViTv2는 ViT의 absolute position embedding을 각 block의 attention에 추가된 더 강력한 relative position embedding으로 바꾸었다. Relative position embedding은 MAE로 학습할 때 필요하지 않으며, absolute position embedding보다 훨씬 느리다.
Convolution 제거
다음으로, 잠재적으로 불필요한 오버헤드를 추가하는 convolution들을 제거하는 것을 목표로 하였다. 먼저 저자들은 모든 convolution을 maxpool로 대체하려고 시도하였지만, 이것 자체로 상당히 비용이 많이 든다. 또한 모든 추가 stride=1 convolution이 maxpool로 대체되어 feature에 상당한 영향을 미치고, 이로 인해 이미지에서 정확도를 1% 이상 떨어뜨렸다.
여기서 추가 stride=1 maxpool을 삭제하면 이전의 정확도로 거의 돌아가며, 이미지의 경우 모델 속도를 22%, 동영상의 경우 27% 높인다. 이 시점에서 남아 있는 유일한 pooling layer는 stage 시의 $Q$ pooling과 처음 두 스테이지의 $KV$ pooling이다.
Overlap 제거
나머지 maxpool들은 여전히 3$\times$3의 kernel size를 가지고 있어서 학습과 inference 중에 separate-and-pad 트릭을 사용해야 한다. 그러나 이러한 maxpool kernel이 겹치지 않도록 하면 이 문제를 완전히 피할 수 있다. 즉, 각 maxpool의 stride와 같은 kernel size를 설정하면 separate-and-pad 트릭 없이도 sparse한 MAE pretraining을 사용할 수 있다. 이렇게 하면 padding이 필요 없기 때문에 이미지에서는 모델 속도가 20%, 동영상에서는 12% 빨라지고 정확도도 높아진다.
Attention Residual 제거
MViTv2는 $Q$와 출력 사이의 attention layer에 residual connection을 추가하여 pooling attention 학습을 돕는다. 그러나 지금까지 레이어 수를 최소화하여 attention을 더 쉽게 학습할 수 있도록 했기 때문에 이 residual connection을 안전하게 제거할 수 있다.
Mask Unit Attention

이 시점에서 남은 유일한 전문 모듈은 attention pooling이다. $Q$ pooling은 계층적 모델을 유지하는 데 필요하지만 $KV$ pooling은 처음 두 stage에서 attention 행렬의 크기를 줄이기 위해 존재한다. 이를 완전히 제거할 수 있지만 네트워크의 계산 비용이 상당히 증가한다. 대신 mask unit 내의 로컬 attention으로 대체한다.
MAE pretraining 중에 이미 네트워크 시작 부분에서 mask unit을 분리해야 한다. 따라서 토큰은 attention에 도착하면 unit별로 이미 깔끔하게 그룹화된다. 그러면 오버헤드 없이 unit 내에서 로컬 attention을 수행할 수 있다. 이 “mask unit attention”은 attention pooling과 같이 글로벌이 아닌 로컬이지만, $K$와 $V$는 글로벌 attention이 유용하지 않은 처음 두 stage에서만 pooling되었다. 따라서 이러한 변경은 정확도에 영향을 미치지 않지만 처리량을 상당히 증가시킨다.
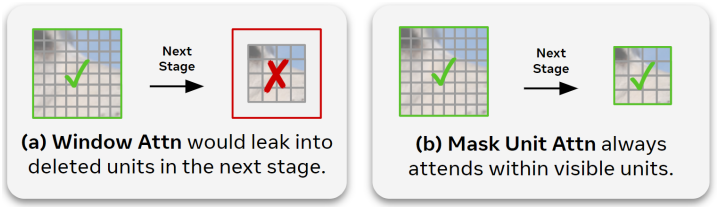
Mask unit attention은 window 크기를 현재 해상도의 mask unit 크기에 맞추기 때문에 window attention과 다르다. Window attention은 네트워크 전체에서 고정된 크기를 가지며, 다운샘플링 후 삭제된 토큰으로 누출된다.
Hiera
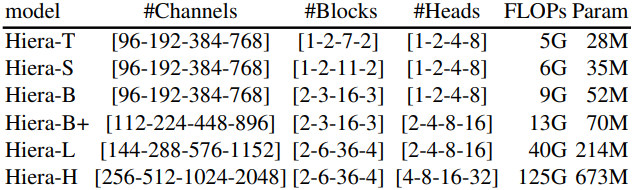
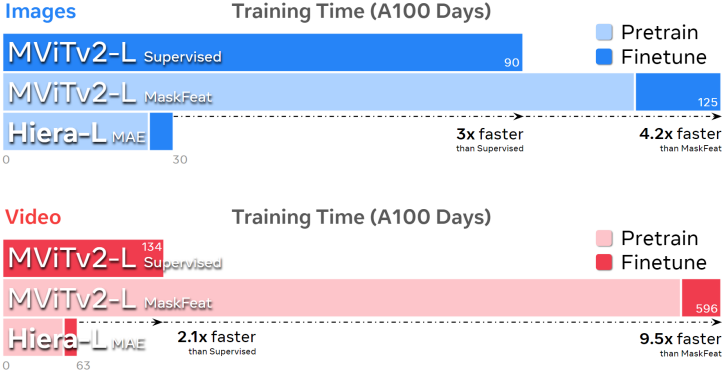
이러한 변경의 결과로 매우 간단하고 효율적인 모델이 탄생했으며, 이를 Hiera라고 부른다. Hiera는 MViTv2보다 이미지에서 2.4배, 동영상에서 5.1배 빠르며 실제로 MAE 덕분에 더 정확하다. 또한 Hiera는 sparse pretraining을 지원하므로 결과를 매우 빠르게 얻을 수 있다. Hiera-L은 supervised learning으로 학습시킨 MViTv2-L보다 이미지에서 3배, 동영상에서 2.1배 더 빠르게 학습된다.
Experiments
1. MAE Ablations
다음은 MAE pretraining에 대한 ablation 결과이다. (Hiera-L)

2. Video Results
다음은 (왼쪽) Kinetics-400, (오른쪽 위) Kinetics-600, (오른쪽 아래) Kinetics-700에서의 결과를 각각 비교한 표이다.
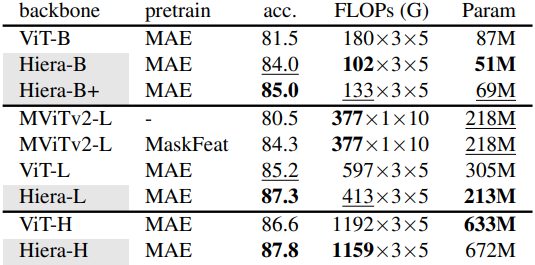

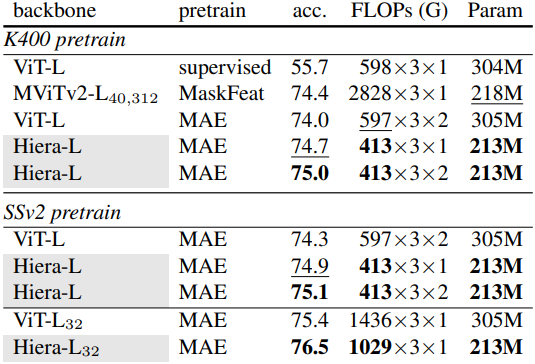
다음은 (왼쪽) Something-Something-v2에서의 classification 성능과 (오른쪽) AVA v2.2에서의 action detection 성능을 각각 비교한 표이다.

3. Image Results
다음은 ImageNet-1K에서의 classification 성능을 비교한 표이다.
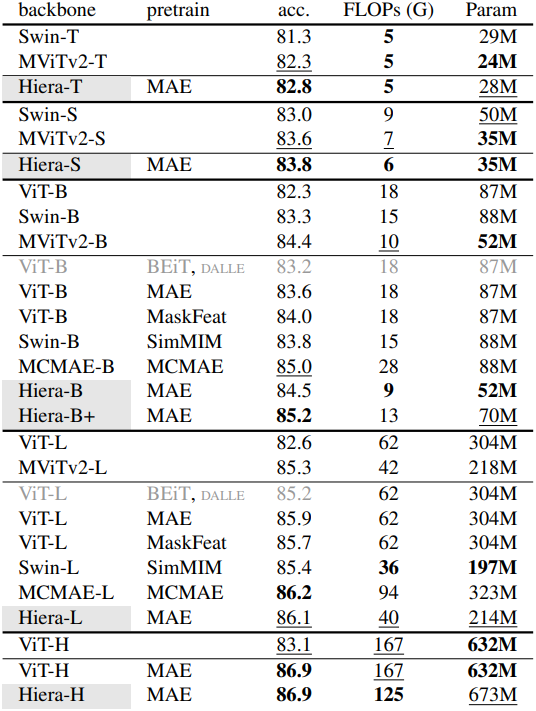
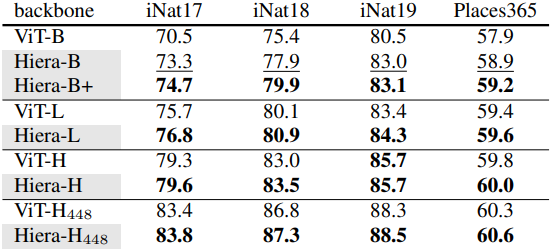
다음은 (왼쪽) iNaturalists와 Places에서의 transfer learning 성능과 (오른쪽) Mask-RCNN을 사용한 COCO object detection 및 segmentation 성능을 각각 비교한 표이다.