[논문리뷰] HiddenSinger: High-Quality Singing Voice Synthesis via Neural Audio Codec and Latent Diffusion Models
arXiv 2023. [Paper] [Page]
Ji-Sang Hwang, Sang-Hoon Lee, Seong-Whan Lee
Korea University
12 Jun 2023

Introduction
Singing voice synthesis(SVS) 시스템은 악보에서 고품질의 노래 음성을 생성하는 것을 목표로 한다. 생성 모델의 최근 발전으로 딥 러닝 기반 SVS 시스템이 빠르게 개발되어 고성능이 되었다. 대부분의 SVS 시스템은 먼저 acoustic model을 사용하여 악보에서 mel-spectrogram과 같은 중간 음향 표현을 합성한다. 그 후 별도로 학습된 보코더가 생성된 표현을 오디오로 변환한다.
그러나 기존의 2단계 SVS 시스템은 특정 제한 사항에 직면해 있다. 이러한 시스템은 미리 정의된 중간 표현에 의존하므로 latent 학습을 적용하여 오디오 생성을 개선하기 어렵다. 또한, 예측된 중간 표현이 ground-truth 중간 표현과 다르기 때문에 학습-inference 불일치 문제가 발생한다. 이러한 문제를 해결하기 위해 end-to-end 간 SVS 시스템인 VISinger는 variational inference를 사용하여 오디오를 직접 합성한다.
기존 시스템이 오디오 품질을 개선할 수 있지만 몇 가지 과제가 남아 있다.
- SVS 시스템은 고음질 오디오를 합성하기 위해 고차원 오디오 또는 선형 spectrogram이 필요하므로 고차원 공간에서 높은 계산 비용이 발생한다.
- 학습-inference 불일치 문제는 end-to-end 시스템에서 지속된다. 오디오의 사후 분포와 악보의 사전 분포 사이에 차이가 존재하여 생성된 노래 음성에서 부정확한 피치와 잘못된 발음이 발생한다. 또한 Normalizing Flows 기반 시스템은 역방향으로 학습되지만 정방향으로 inference를 수행한다.
- SVS 시스템은 학습을 위해 오디오-악보 코퍼스가 필요하며, 고품질 쌍 데이터셋을 얻는 데 시간이 많이 걸린다.
본 논문은 앞서 언급한 문제를 해결하기 위해 뉴럴 오디오 코덱과 latent diffusion model (LDM)을 활용한 고품질 SVS 시스템인 HiddenSinger를 제안한다. 본 논문의 접근 방식에는 합성 프로세스를 향상시키기 위한 여러 구성 요소가 포함된다. 먼저 오디오를 압축된 latent 표현으로 효율적으로 인코딩할 수 있는 오디오 오토인코더를 도입하여 더 낮은 차원의 latent space를 만든다. 또한 오디오 오토인코더에서 residual vector quantization (RVQ)를 채택하여 임의의 고분산 latent space를 정규화한다. 그 후, LDM의 강력한 생성 능력을 사용하여 오디오 오토인코더를 통해 오디오로 변환되는 악보에 따라 latent 표현을 생성한다. 또한 오디오만 포함된 가창 음성 데이터를 활용하는 unsupervised 가창 음성 학습 프레임워크를 제안한다.
HiddenSinger는 오디오 품질 측면에서 이전 SVS 모델을 능가한다. 또한, 제안된 unsupervised 가창 음성 학습 프레임워크인 HiddenSinger-U를 사용하여 페어링되지 않은 데이터로 표현되는 speaker에 대해서도 고품질의 가창 음성을 합성할 수 있다.
HiddenSinger
본 논문에서는 고품질의 노래 음성 오디오를 위해 뉴럴 오디오 코덱과 latent diffusion을 이용한 SVS 시스템을 제안한다. 고충실도 오디오 생성과 계산 효율성을 위해 residual vector quantization (RVQ)를 사용하는 오디오 오토인코더를 도입한다. 또한 latent generator에서 LDM을 채택하여 오디오 오토인코더에 의해 오디오로 변환되는 악보에 따라 latent 표현을 생성한다. 또한 HiddenSinger를 악보 없이 모델을 학습시킬 수 있는 HiddenSinger-U로 확장한다.
1. Audio Autoencoder
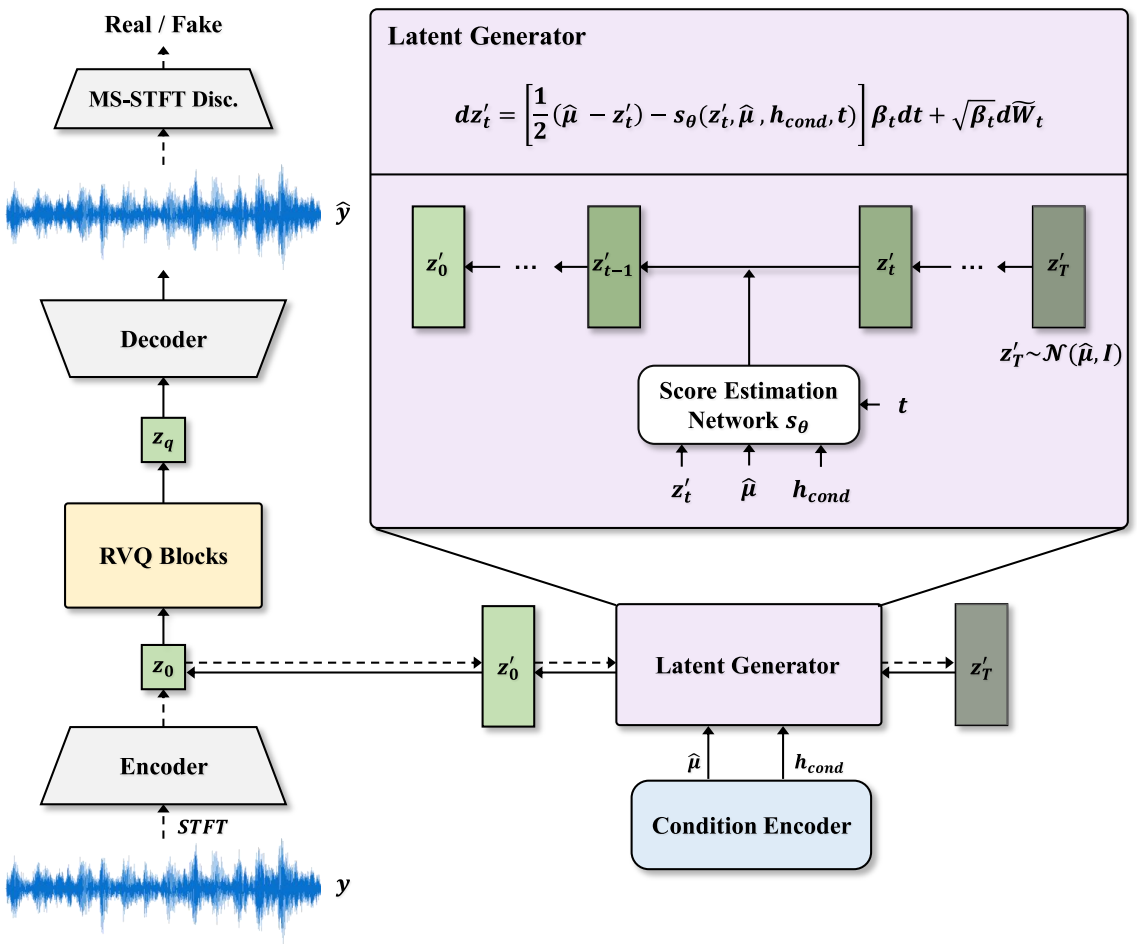
효율적인 코딩과 고품질 오디오 생성을 위해 오디오를 오디오 코덱으로 압축하는 오디오 오토인코더를 도입하여 저차원 표현을 제공한다. 오디오 오토인코더는 위 그림과 같이 인코더, RVQ 블록, 디코더의 세 가지 모듈로 구성된다.
인코더
인코더는 고차원 선형 spectrogram을 입력으로 사용하고 오디오 $y$에서 연속적인 저차원 latent 표현 $z_0$를 추출한다. Latent space는 latent space의 임의의 높은 분산을 피하기 위해 vector quantization (VQ)를 통해 정규화된다. LDM을 사용하여 샘플링을 수행한 이전 연구에서는 VQ-정규화된 latent space에서 학습된 모델이 KL-정규화된 latent space보다 더 나은 품질을 달성했음을 보여주었다. 그러나 기존의 VQ는 양자화된 벡터가 파형의 여러 feature를 나타내야 하기 때문에 고충실도 오디오 재구성에 충분하지 않다. 따라서 효율적인 오디오 압축을 위해 연속적인 latent 표현 $z_0$에 RVQ를 적용한다.
RVQ 블록
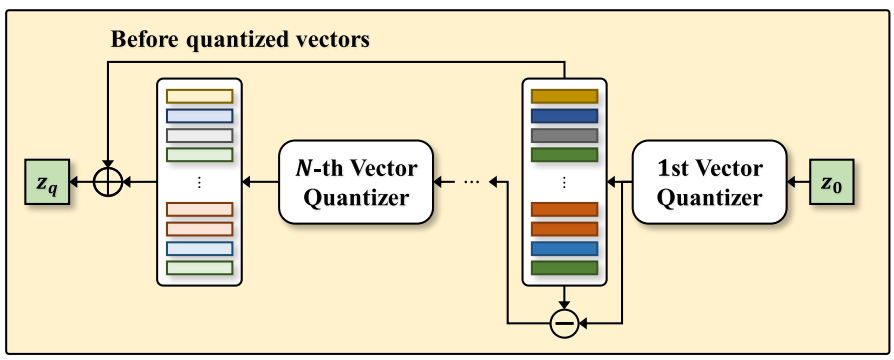
위 그림에 표시된 것처럼 첫 번째 vector quantizer는 latent 표현 $z_0$를 코드북에서 가장 가까운 항목으로 discretize한다. 그런 다음 residual이 계산된다. 다음 quantizer는 두 번째 코드북과 함께 사용되며, 이 과정은 quantizer의 수 $C$만큼 반복된다. Quantizer의 수는 계산 비용과 코딩 효율성 간의 균형과 관련이 있다. 각 quantizer에 대한 코드북을 학습하기 위해 Soundstream에 설명된 학습 절차를 따른다. 또한 코드북 학습을 안정화하기 위해 다음과 같은 commitment loss를 적용한다. 가중치가 낮은 commitment loss는 학습 중에 RVQ 블록을 수렴하는 데 도움이 된다.
여기서 $z_{0,c}$는 $c$번째 quantizer의 residual 벡터를 나타내고 $q_c (z_{0,c})$는 $c$번째 코드북에서 가장 가까운 entry를 나타낸다.
디코더
디코더는 오디오 코덱에서 파형 $\hat{y} = G(z_q)$을 생성한다. 생성된 \(\hat{x}_\textrm{mel}\)과 ground-truth mel-spectrograms $x_\textrm{mel}$ 사이의 reconstruction loss \(\mathcal{L}_\textrm{recon}\)을 계산하여 디코더의 학습 효율성을 개선한다. \(\mathcal{L}_\textrm{recon}\)은 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{recon} = \| x_\textrm{mel} - \hat{x}_\textrm{mel} \|_1 \end{equation}\]또한 생성된 오디오의 품질을 개선하기 위해 적대적 학습을 채택한다. 다중 해상도 spectrogram discriminator를 확장하는 multi-scale STFT (MS-STFT) 기반 discriminator를 사용한다. MS-STFT discriminator는 실수부와 허수부를 모두 포함하는 multi-scale 복소수 STFT에서 작동한다. MS-STFT discriminator는 디코더를 효율적으로 학습하고 multi-period discriminator와 multi-scale discriminator의 조합보다 더 나은 품질의 오디오 합성을 용이하게 한다. 또한, GAN 학습을 위한 perceptual loss인 feature matching loss \(\mathcal{L}_\textrm{fm}\)을 채택한다.
\[\begin{aligned} \mathcal{L}_\textrm{adv} (D) &= \mathbb{E} [ (D(y) - 1)^2 + D (G(z_q))^2 ] \\ \mathcal{L}_\textrm{adv} (G) &= \mathbb{E} [ (D (G(z_q)) - 1)^2 ] \\ \mathcal{L}_\textrm{fm} (G) &= \mathbb{E} \bigg[ \sum_{l=1}^L \frac{1}{N_l} \| D_l (y) - D_l (G (z_q)) \|_1 \bigg] \end{aligned}\]여기서 $z_q$는 양자화된 latent 표현을 나타내고, $L$은 discriminator $D$의 총 레이어 수, $N_l$은 feature의 수를 나타내고 $D_l$은 discriminator의 $l$번째 레이어에서 feature map 맵을 추출한다.
Auxiliary Multi-task Learning
오디오 코덱에서 언어 및 음향 정보의 능력을 향상시키기 위해 가사 예측기와 음-피치 예측기를 기반으로 하는 보조 task를 도입한다. 각 예측기는 압축된 latent 표현 $z_q$를 사용하여 프레임 레벨의 타겟 feature를 예측한다. 예측된 feature와 타겟 feature 사이의 connectionist temporal classification (CTC) loss를 계산한다. 악보가 포함된 쌍을 이룬 데이터셋에만 CTC loss를 적용한다.
최종 loss
\[\begin{aligned} \mathcal{L}_\textrm{gen} =\;& \mathcal{L}_\textrm{adv} (G) + \lambda_\textrm{recon} \mathcal{L}_\textrm{recon} + \lambda_\textrm{emb} \mathcal{L}_\textrm{emb} \\ &+ \lambda_\textrm{fm} \mathcal{L}_\textrm{fm} (G) + \lambda_\textrm{lyrics} \mathcal{L}_\textrm{lyrics} + \lambda_\textrm{note} \mathcal{L}_\textrm{note} \end{aligned}\]2. Condition Encoder
저자들은 diffusion model을 가이드하기 위해 조건 인코더를 제시하였다. 조건 인코더는 가사 인코더, 멜로디 인코더, 향상된 조건 인코더, prior estimator를 포함한다.
가사 인코더
가사 인코더는 위치 임베딩이 있는 음소 레벨의 가사 시퀀스를 입력으로 받은 다음 가사 표현을 추출한다. 가사 시퀀스를 음소 레벨의 가사 시퀀스로 변환하기 위해 문자소-음소 도구를 사용한다.
멜로디 인코더
악보에서 적절한 멜로디로 노래하는 목소리를 생성하는 멜로디 인코더를 도입한다. 악보를 사용하기 전에 음표를 음소 레벨의 음표 시퀀스로 나눈다. 한국어 음절은 일반적으로 초성, 중성, 종성으로 구성된다. 이전의 한국 SVS 시스템을 따라 최대 3개의 프레임에 초성과 종성을 할당하고 나머지는 중성으로 간주한다.
멜로디 인코더는 음표 피치, 음표 길이, 음표 템포 임베딩 시퀀스와 위치 임베딩의 concatenation으로부터 멜로디 표현을 추출한다. 음표 피치 시퀀스는 음표 피치 임베딩으로 변환된다. 음표 길이 임베딩 시퀀스는 고정된 길이 토큰 집합으로 표현되며, 그 중 해상도는 특정 음표 길이 (ex. 1/64 음표)로 표시된다. 음표 템포는 분당 비트 수로 계산되며 템포 임베딩으로 인코딩된다.
향상된 조건 인코더
향상된 조건 인코더는 가사 인코더와 멜로디 인코더의 출력 합계를 인코딩하여 더 많은 정보를 제공하는 조건 표현 $h_\textrm{cond}$를 제공한다. 두 표현을 합산하기 전에 음표 길이에 따라 프레임 레벨로 확장된다. 향상된 조건 인코더는 합성된 노래 음성의 발음을 효과적으로 안정화한다.
3. Latent Generator
오디오 오토인코더의 latent 표현을 생성하기 위해 latent generator에서 LDM을 채택한다. Latent 표현 \(\hat{z}_0\)는 LDM을 사용하여 샘플링되며, 생성된 latent 표현 \(\hat{z}_0\)는 오디오 오토인코더에서 오디오 코덱으로 변환된다. 또한 latent 표현은 샘플링을 용이하게 하기 위해 정규화된다.
데이터 기반 Prior
생성 능력을 향상시키기 위해 잠재 확산 모델에서 데이터 기반 prior를 사용한다. 이전 연구들은 데이터 기반 prior의 사용이 복잡한 데이터와 알려진 prior 사이의 궤적을 근사화하는 데 도움이 된다는 것을 입증했다. Grad-TTS를 따라 diffusion model을 설계하여 표준 Gaussian noise에서의 denoising보다 더 쉬운 타겟 \(z'_0\)에 가까운 noise에서의 denoising을 시작한다. 조건 인코더의 prior estimator를 사용하여 조건 표현 \(h_\textrm{cond}\)에서 $\hat{\mu}$를 예측한다. $\hat{\mu}$를 평균이 이동된 가우시안 분포 $\mathcal{N}(\hat{\mu}, I)$로 간주하기 위해 정규화된 latent \(z'_0\)과 예측된 $\hat{\mu}$ 사이에 negative log-likelihood loss \(\mathcal{L}_\textrm{prior}\)를 적용한다.
Latent Diffusion Model
Diffusion process는 데이터 기반의 prior과 함께 forward SDE (확률 미분 방정식)을 사용하여 정의된다. Forward SDE는 정규화된 latent 표현 \(z'_0\)을 Gaussian noise로 변환한다.
\[\begin{equation} dz'_t = \frac{1}{2} (\hat{\mu} - z'_t) \beta_t dt + \sqrt{\beta_t} d W_t \end{equation}\]여기서 $W_t$는 표준 브라운 운동이고 $\beta_t$는 음이 아닌 미리 정의된 noise schedule이다. 해는 다음과 같이 표현된다.
\[\begin{aligned} z'_t =\;& (I - \exp (- \frac{1}{2} \int_0^t \beta_s ds)) \hat{\mu} + \exp (- \frac{1}{2} \int_0^t \beta_s ds) z'_0 \\ &+ \int_0^t \sqrt{\beta_s} \exp (- \frac{1}{2} \int_s^t \beta_u du) dW_s \end{aligned}\]Ito 적분의 속성에 따르면 transition 밀도 \(p_t (z'_t \vert z'_0)\)는 다음과 같이 가우시안 분포이다.
\[\begin{aligned} p_t(z'_t \vert z'_0) &\sim \mathcal{N} (z'_t; \rho_t, \lambda_t) \\ \rho_t &= (I - \exp (- \frac{1}{2} \int_0^t \beta_s ds)) \hat{\mu} + \exp (- \frac{1}{2} \int_0^t \beta_s ds) z'_0 \\ \lambda_t &= I - \exp (- \int_0^t \beta_s ds) \end{aligned}\]정규화된 latent 표현 \(z'_0 \sim p_0 (z')\)를 얻기 위해 reverse process를 SDE solver로 정의한다. Score 추정 네트워크 $s_\theta$를 사용하여 다루기 힘든 score를 근사화한다.
\[\begin{aligned} dz'_t =\;& \bigg[ \frac{1}{2} (\hat{\mu} - z'_t) - s_\theta (z'_t, \hat{\mu}, h_\textrm{cond}, t) \bigg] \beta_t dt \\ &+ \sqrt{\beta_t} d \tilde{W}_t, \qquad t \in [0, 1] \end{aligned}\]여기서 \(\tilde{W}_t\)는 역 브라운 운동이다.
다음과 같이 noisy한 latent \(z'_t\)의 로그 밀도의 추정 기울기의 예상 값을 계산한다.
\[\begin{aligned} \mathcal{L}_\textrm{diff} &= \mathbb{E}_{z'_0, z'_t, t} [\| s_\theta (z'_t, \hat{\mu}, h_\textrm{cond}, t) - \nabla_{z'_t} \log p_t (z'_t \vert z'_0) \|_2^2 ] \\ &= \mathbb{E}_{z'_0, z'_t, t} [\| s_\theta (z'_t, \hat{\mu}, h_\textrm{cond}, t) + \lambda_t^{-1} \epsilon_t \|_2^2 ], \qquad \epsilon_t \in \mathcal{N} (0,I) \\ \end{aligned}\]또한 샘플링 중에 데이터 기반 prior 분포 \(\mathcal{N}(\hat{\mu}, \tau^{-1} I)\)에 대해 temperature 파라미터 $\tau > 1$를 채택하여 latent generator가 품질을 유지하도록 한다.
다음 목적 함수에 따라 latent generator와 조건 인코더를 공동으로 최적화한다.
\[\begin{equation} \mathcal{L}_\textrm{lg} = \mathcal{L}_\textrm{diff} + \lambda_\textrm{prior} \mathcal{L}_\textrm{prior} \end{equation}\]여기서 \(\lambda_\textrm{prior}\)는 prior loss \(\mathcal{L}_\textrm{prior}\)를 위한 loss 가중치이다.
4. Unsupervised Singing Voice Learning Framework
기존의 SVS 모델은 학습을 위해 짝을 이룬 데이터 (오디오-악보 코퍼스)가 필요하다. 또한 이러한 모델은 zero-shot 적응과 같은 특별한 기술 없이는 학습되지 않은 speaker의 노래 음성을 합성할 수 없다. 제안된 모델을 unsupervised 노래 음성 학습 프레임워크인 HiddenSinger-U로 확장하여 짝을 이루는 데이터셋 수집의 어려움을 완화한다. 이 프레임워크를 사용하면 모델이 학습 중에 레이블이 지정되지 않은 데이터를 사용할 수 있다.
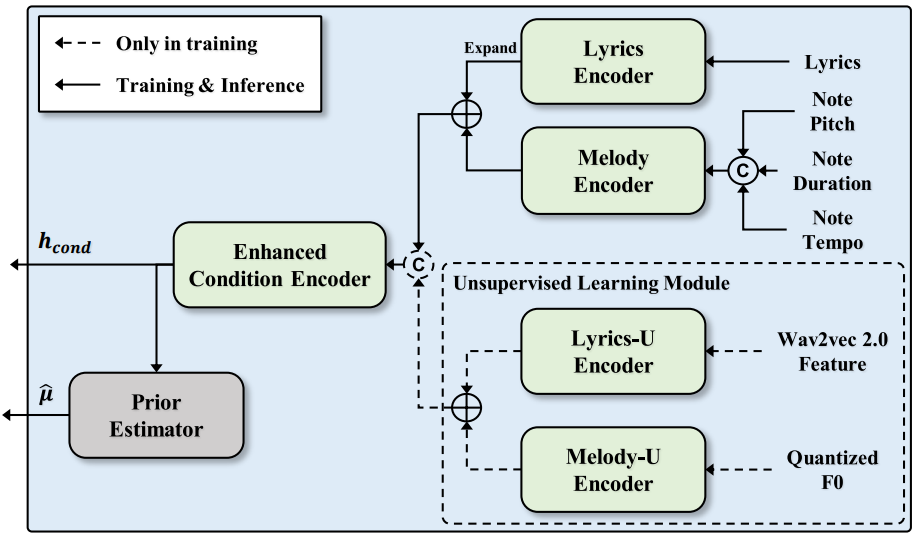
위 그림과 같이 unsupervised 가사 및 멜로디 표현을 모델링하기 위해 조건 인코더에 두 개의 추가 인코더를 도입한다.
- Unsupervised 가사 인코더 (lyrics-U encoder)
- Unsupervised 멜로디 인코더 (melody-U encoder)
또한 제안된 프레임워크에서 contrastive learning을 사용한다.
Lyrics-U Encoder
언어 정보에 대해 self-supervised 음성 표현 방법을 사용한다. 이전 연구들에서는 self-supervised 모델의 중간 레이어의 음성 표현에 음성 정보가 포함되어 있음을 입증했다. 따라서 음성 정보는 타겟 오디오에서 self-supervised 표현을 추출하여 활용할 수 있다. 타겟 오디오에서 speaker 정보를 완화하기 위해 self-supervised 표현을 추출하기 전에 정보 섭동을 수행한다. 정보 섭동으로 인해 self-supervised 모델은 음성 정보만 추출하는 데 집중하게 된다. 그 후, lyrics-U encoder는 self-supervised 표현을 프레임 레벨의 unsupervised 가사 표현으로 인코딩한다.
Melody-U Encoder
SVS 모델은 여전히 노래하는 목소리를 합성하기 위해 타겟 오디오의 멜로디 정보가 필요하다. 먼저 오디오에서 기본 주파수($F0$)를 추출하여 멜로디 정보를 추출한다. 그런 다음 $F0$을 양자화하고 이를 피치 임베딩으로 인코딩하여 타겟 오디오에서 speaker 정보를 모호하게 한다. 그 후, melody-U encoder는 피치 임베딩을 수행하여 프레임 레벨의 unsupervised 멜로디 표현을 추출한다.
Contrastive Learning
쌍으로 된 표현 (ex. 가사와 가사 표현) 사이의 차이으로 인해 HiddenSinger-U를 최적화하기 위해 목적 함수 \(\mathcal{L}_\textrm{lg}\)만 사용하는 것은 불충분하다. 일치를 최대화하고 쌍을 이룬 표현 간의 비 유사성에 페널티를 주기 위해 다음과 같이 쌍을 이룬 데이터에 대해 contrastive loss를 도입한다.
\[\begin{aligned} \mathcal{L}_{\textrm{cont}_\ast} &= \sum_{t=1}^T \frac{\exp (\cos (h_\ast^{(t)}, \tilde{h}_\ast^{(t)}) / \tau_\textrm{cont})}{\sum_{\xi_{[k \ne t]}} \exp (\cos (h_\ast^{(t)}, h_\ast^{(k)}) / \tau_\textrm{cont})} \\ &+ \sum_{t=1}^T \frac{\exp (\cos (\tilde{h}_\ast^{(t)}, h_\ast^{(t)}) / \tau_\textrm{cont})}{\sum_{\xi_{[k \ne t]}} \exp (\cos (\tilde{h}_\ast^{(t)}, \tilde{h}_\ast^{(k)}) / \tau_\textrm{cont})} \end{aligned}\]여기서 $\cos (\cdot, \cdot)$은 두 쌍의 코사인 거리이며, \(\tau_\textrm{cont}\)는 temperature이다. $\xi_{[k \ne t]}$는 negative sample로 사용되는 임의의 시간 인덱스 집합이다. Contentvec을 따라 negative sample에 대한 각 쌍 표현 내에서 일치하지 않는 여러 프레임을 무작위로 선택한다. 각 유형의 표현 $h_\ast \in [h_\textrm{lyric}, h_\textrm{melody}]$에 대해 contrastive loss를 적용한다. 쌍을 이룬 표현 사이의 차이는 목적 함수 \(\mathcal{L}_\textrm{lg}\)에서 contrastive 항 \(\mathcal{L}_{\textrm{cont}_\ast}\)를 채택하여 줄일 수 있다.
Experiment
- 데이터셋
- 다음색 가이드보컬 데이터
- 157.39시간 분량의 4000개의 한국어 노래-악보 쌍
- 오디오를 2마디씩 잘라 총 93,127개의 샘플로 사용 (89,186 / 1,975 / 1.966)
- 내부 노래 음성 데이터셋 (HiddenSinger-U 학습에만 사용)
- 3.30시간 분량의 316개의 한국어 노래 (악보 없음)
- 총 1,326개의 샘플 (1,130 / 99 / 97)
- 다음색 가이드보컬 데이터
- 전처리
- 학습 디테일
- 오디오 오토인코더
- AdamW, learning rate = $2 \times 10^{-4}$, $\beta_1 = 0.8$, $\beta_2 = 0.99$, weight decay = 0.01
- 효율성을 위해 windowed generator training을 채택
- 언어적 feature를 캡처하기 위해 인코더의 입력으로 window 크기가 128프레임인 파형의 세그먼트를 무작위로 추출
- 디코더는 32프레임의 window 크기로 양자화된 latent 표현 $z_q$의 무작위로 슬라이스된 세그먼트를 취함
- ground-truth 오디오의 해당 오디오 세그먼트를 학습 타겟으로 사용
- 4개의 NVIDIA RTX A6000 GPU로 학습
- batch size는 GPU당 32개, 최대 100만 step까지 학습
- 조건 인코더 & latent generator
- AdamW, learning rate = $5 \times 10^{-5}$, $\beta_1 = 0.8$, $\beta_2 = 0.99$, weight decay = 0.01
- 효율적인 학습을 위해 window 크기가 128프레임인 latent 표현 $z_0$의 세그먼트를 무작위로 추출
- 2개의 NVIDIA RTX A6000 GPU로 학습
- batch size는 GPU당 32개, 최대 200만 step까지 학습
- 오디오 오토인코더
- 구현 디테일
- 오디오 오토인코더
- 인코더: non-causal WaveNet residual block
- 디코더: HiFi-GAN V1 generator
- Quantizer 30개 사용 (코드북 크기 1024, 128차원)
- 조건 인코더
- 각 인코더는 Glow-TTS를 따라 상대적 위치 임베딩을 포함하는 4개의 feed-forward Transformer (FFT) block
- 각 FFT 블록은 attention head가 2개, hidden size가 192, 커널 크기가 9
- Prior estimator는 하나의 linear layer
- Latent generator
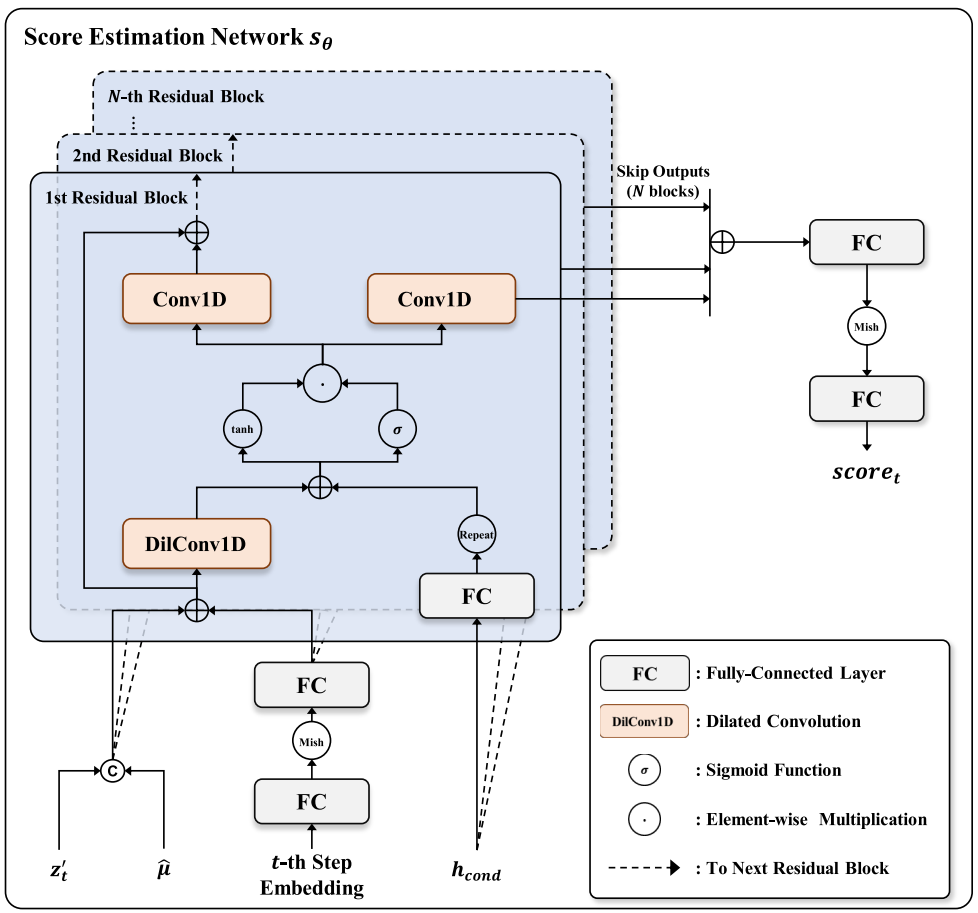
- non-causal WaveNet 기반 denoiser 아키텍처 (아래 그림 참조)
- dilated convolution layer는 20개, residual 채널은 256개, 커널 크기는 3, dilation은 1
- $\beta_0 = 0.05$, $\beta_1 = 20$, $T = 1$, $\tau = 1.5$
- Unsupervised Learning Module
- lyrics-U encoder와 melody-U encoder는 가사 인코더와 멜로디 인코더와 동일한 아키텍처
- 사전 학습된 XLS-R의 12번째 레이어에서 self-supervised 표현을 추출
- $F0$를 128개의 간격으로 양자화하여 speaker 정보를 완화
- 오디오 오토인코더
1. Singing Voice Synthesis
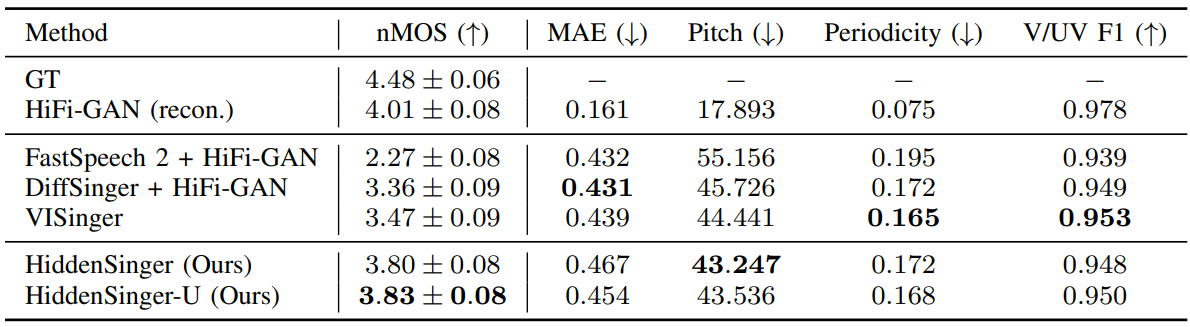
다음은 테스트 데이터셋에 대한 지표를 비교한 표이다. HiddenSinger-U는 같은 데이터셋에서 학습되었으며 10%의 데이터는 레이블이 지정되지 않았다.
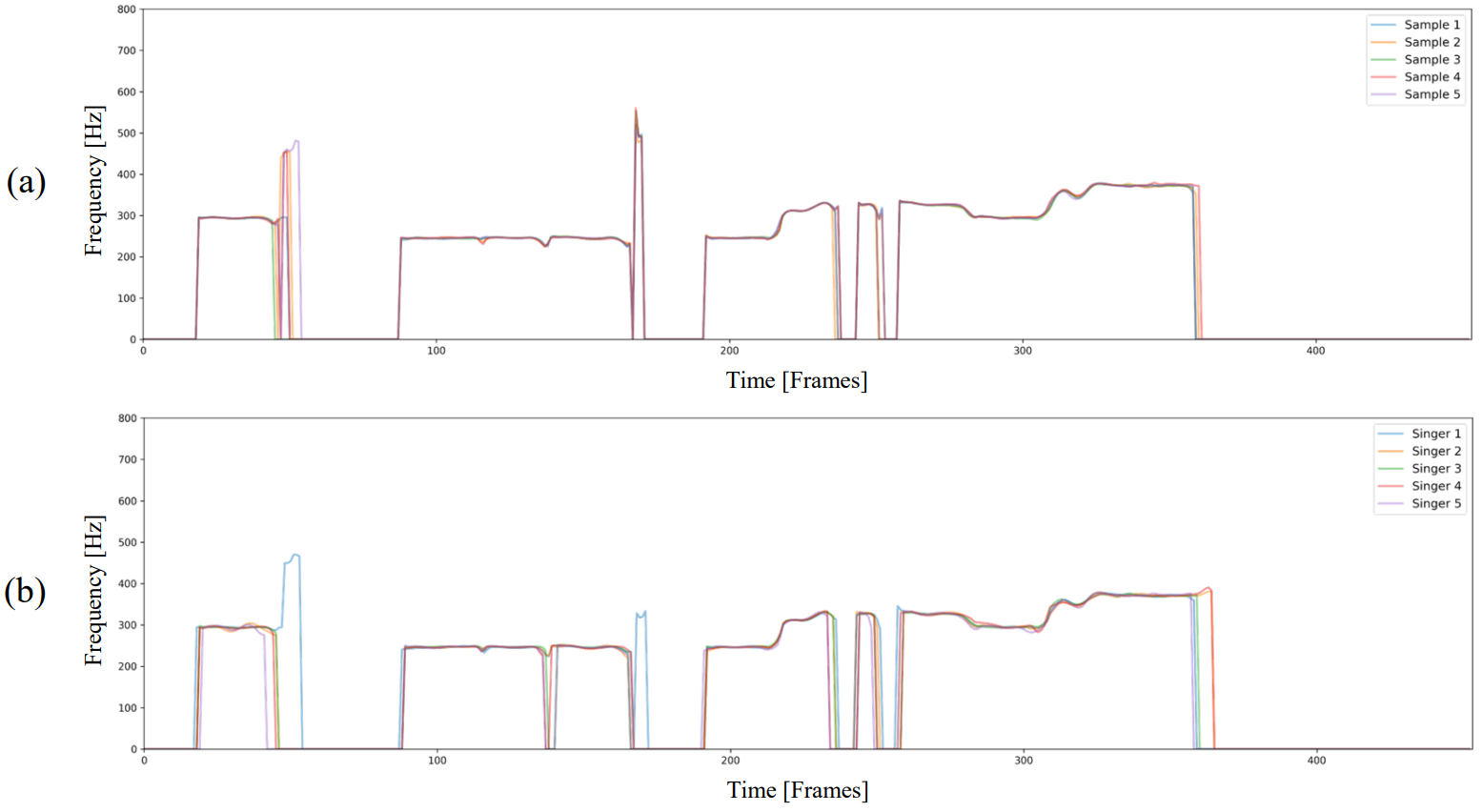
다음은 생성된 F0 contour를 시각화한 것이다. (a)는 같은 악보로 5개의 inference에 대한 합성된 음성의 F0 contour이다. (b)는 같은 악보로 5명의 speaker에 대해 합성된 음성의 F0 contour이다.
다음은 다양한 시스템에서 생성된 샘플들을 시각화한 것이다.

2. Audio Autoencoder
다음은 재구성된 오디오에 대하여 비교한 표이다.

다음은 다양한 정규화 방법을 사용한 latent generator에 대한 비교 결과이다.

3. Unsupervised Singing Voice Learning Framework
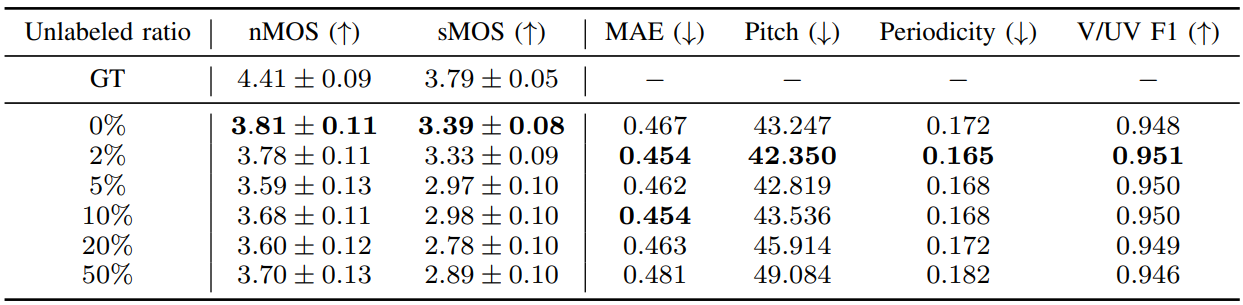
다음은 레이블이 지정되지 않은 비율에 따른 결과이다.
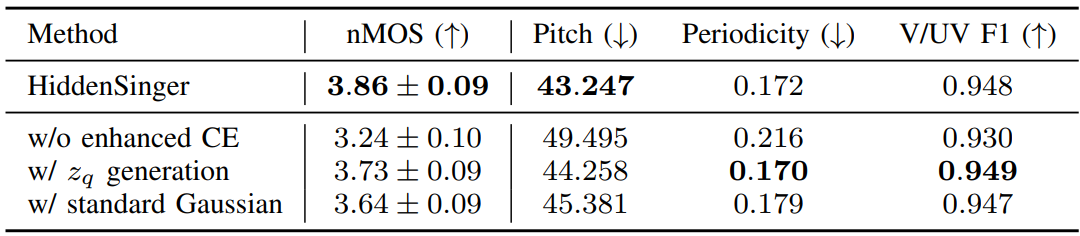
4. Ablation Study
다음은 ablation study 결과이다. Enhanced CE는 향상된 조건 인코더를 뜻한다.