[논문리뷰] Vision Language Models are In-Context Value Learners
ICLR 2025 (Spotlight). [Paper] [Page]
Yecheng Jason Ma, Joey Hejna, Ayzaan Wahid, Chuyuan Fu, Dhruv Shah, Jacky Liang, Zhuo Xu, Sean Kirmani, Peng Xu, Danny Driess, Ted Xiao, Jonathan Tompson, Osbert Bastani, Dinesh Jayaraman, Wenhao Yu, Tingnan Zhang, Dorsa Sadigh, Fei Xia
Google DeepMind | University of Pennsylvania | Stanford University
7 Nov 2024
Introduction
최신 vision language model (VLM)은 상당한 일반화 및 추론 능력을 보여주었으며, 다음과 같은 이유들로 인해 잠재적으로 value 추정에 유용할 수 있다.
- VLM은 다양한 비전 task에서 강력한 공간적 추론 및 시간 이해 능력을 보여주어 새로운 task 및 장면에 대한 광범위한 일반화가 가능하다.
- 대규모 transformer 기반 VLM은 task 진행 상황을 예측할 때 observation 시퀀스에서 state를 정확하게 추정하기 위해 방대한 양의 과거 정보를 추론할 수 있는 context window를 갖추고 있다. 이를 통해 부분적으로 관찰된 환경에서 state를 정확하게 추정할 수 있다.
- VLM은 autoregressive하게 예측을 수행하므로 후속 예측을 위한 입력으로 자체 출력을 사용하여 긴 생성에 일관성 제약을 부과한다.
그러나 VLM을 사용하여 value를 예측하는 정확한 방법은 불분명하다. 저자들은 단순히 VLM에 동영상을 입력하고 모델에 각 프레임의 진행률 예측을 반환하도록 하는 것만으로는 실패한다는 것을 발견했다. 연속된 프레임 간의 강력한 시간적 상관관계로 인해 VLM이 궤적의 실제 품질과 프레임 간의 차이를 무시하고 유익하지 않은 단조로운 값을 생성하는 경우가 많다.
본 논문은 VLM의 광범위한 지식을 효과적으로 활용한 보편적인 value 추정 방법인 Generative Value Learning (GVL)을 소개한다. GVL의 핵심은 Gemini-1.5-Pro와 같은 최신 VLM에 셔플된 입력 동영상 프레임 시퀀스를 입력하고 task의 완료 비율을 autoregressive하게 예측하도록 요청한다는 것이다. 입력 동영상의 프레임을 셔플링하는 것만으로 동영상에서 발견되는 강력한 시간적 편향을 효과적으로 극복하여 VLM이 의미 있는 값을 생성할 수 있다. GVL은 zero-shot 방식으로 값을 생성할 수 있지만, GVL의 성능은 멀티모달 in-context learning을 통해 예제에 따라 확장되며, 컨텍스트에서 셔플링되지 않은 시각적 예제를 더 많이 제공하면 성능이 향상된다.
대규모의 value 예측 평가를 용이하게 하기 위해, 저자들은 새로운 평가 지표인 Value-Order Correlation (VOC)를 도입하여 예측된 value가 전문가 동영상의 GT 타임스텝 순서와 얼마나 잘 상관관계를 갖는지 측정하였다. 전체적으로 GVL은 대부분의 데이터셋에서 매우 긍정적인 VOC 점수와 함께 강력한 zero-shot value 예측 능력을 보여주었으며, 그 성능은 다양한 유형의 멀티모달 컨텍스트 예제를 통해 더욱 향상된다.
Method
저자들은 로봇 task를 goal로 컨디셔닝된 부분적으로 관찰된 Markov decision processes로 모델링하였다.
\[\begin{equation} \mathcal{M}(\phi) = (\mathcal{O}, \mathcal{A}, R, P, T, \mu, \mathcal{G}) \end{equation}\]- $\mathcal{O}$: observation space
- $\mathcal{A}$: action space
- $R$: reward function
- $P$: transition function
- $T$: horizon
- $\mu$: 초기 state 분포
- $\mathcal{G}$: goal space
Task $g$에 따라 에이전트 $\mathcal{O} \rightarrow \mathcal{A}$는 value function 또는 horizon에 걸친 누적 reward인 $V^\pi (o_1; g) = \mathbb{E}_{\mu, \pi, P} [r(o_1; g) + \cdots + r(o_T; g)]$를 최대화하는 것을 목표로 한다. 그러나 reward function과 value function은 정의하기 어려울 수 있다.
이를 감안할 때, 보편적인 value의 선택은 task의 진행률, 즉 observation과 goal을 0과 1 사이의 실수에 매핑하는 것이다.
\[\begin{equation} V : \mathcal{O} \times \mathcal{G} \rightarrow [0, 1] \end{equation}\]초기 observation은 value가 0이고 goal을 충족하는 observation은 value가 1이다. 이 정의에 따라 전문가 궤적 \(\tau = (o_1, \ldots, o_T) \sim \pi_E\)는 가치 함수 value function \(V^{\pi_E} (o_t; g) = \frac{t}{T}\)가 된다. 본 논문의 목표는 동영상의 각 프레임 $o_1, \ldots, o_T$에 대한 task 진행률 $v_1, \ldots, v_T$를 예측할 수 있는 시간적 value function $V$를 얻는 것이다.
대규모 foundation model에 주입된 prior를 활용하기 위해 단순히 동영상 프레임으로 VLM을 유도하는 것만으로는 의미 있는 추정치를 생성하지 못한다. 본 논문은 VLM을 value 예측에 적합하게 만들기 위해 세 가지 핵심 구성 요소를 제안하였다.
- Autoregressive value prediction
- Input observation shuffling
- In-context value learning
1. Autoregressive value prediction
전통적으로 value function $V(\cdot) : \mathcal{O} \rightarrow \mathbb{R}$는 bellman equation을 적용하여 자체 일관성을 갖도록 학습된다.
\[\begin{equation} V^\pi (o_t) = R(o_t) + \mathbb{E}_{\pi, P} [V (o_{t+1})] \end{equation}\]Value function를 feed-forward 신경망으로 parameterize할 때는 일반적으로 위의 등식의 평균 제곱 오차(MSE)를 최소화한다. 동일한 궤적 내의 다른 observation에 대한 값은 bellman equation을 통해 관련되므로 하나의 observation으로만 쿼리하더라도 value function은 일관성을 유지한다.
반면 VLM은 본질적으로 어떠한 일관성에 대한 loss로도 학습되지 않는다. 따라서 동일한 궤적의 다른 observation으로 VLM을 독립적으로 쿼리하면 일관되지 않은 값이 생성될 가능성이 높다.
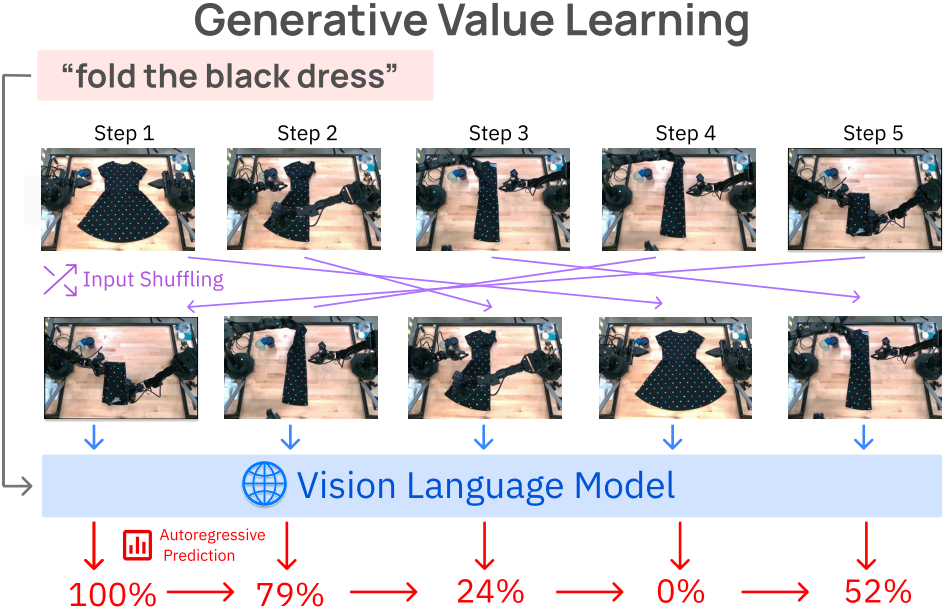
저자들의 통찰력은 하나의 observation 대신 전체 궤적을 입력으로 제공하면 VLM이 자체적으로 일관된 값 추정치를 생성할 수 있는 더 큰 기회를 제공한다는 것이다. 구체적으로, task에 대한 언어 설명 $l_\textrm{task}$가 주어지면 VLM에 전체 동영상을 컨텍스트로 주어진 값을 autoregressive하게 생성하도록 요청한다.
\[\begin{equation} v_t = \textrm{VLM}(o_1, \ldots, o_T; v_1, \ldots, v_{t-1}; l_\textrm{task}), \quad \forall t \in [2, T] \end{equation}\]이 간단한 메커니즘을 통해 VLM은 다음 value 예측을 할 때 모든 이전 예측과 프레임을 처리할 수 있으므로 기존 feed-forward value function처럼 학습할 필요 없이 긴 시퀀스에 대해 글로벌하게 일관된 추정치를 생성할 수 있다. 이를 통해 VLM은 일관된 값을 생성할 수 있지만 value가 의미 있어야 하지는 않다. 이런 방식으로 단순하게 VLM을 프롬프팅하면 최적성과 관계없이 모든 동영상에 대해 선형적이고 monotonic한 value function이 생성되는 경향이 있다.
2. Input observation shuffling
저자들은 프레임의 시간적 시퀀스가 제시될 때 VLM이 단조롭게 증가하는 value를 출력하는 것을 발견하였으며, 종종 task 설명이나 궤적의 실제 품질을 무시한다는 것을 발견했다. 한 가지 가설은 VLM이 캡션 생성 및 질의응답을 위해 정렬된 동영상 프레임에서 학습되기 때문에 시간 자체가 value 예측과 관련 없는 다운스트림 task에 대한 단서가 된다는 것이다. 결과적으로 모델에 대한 단순한 프롬프트는 신뢰할 수 없는 value 예측을 초래한다.
저자들은 이러한 시간적 편향을 깨기 위해 입력 프레임을 무작위로 섞는 것을 제안하였다. 이런 방식으로 GVL은 VLM이 각 개별 프레임에 주의를 기울이고 컨텍스트에서 제공된 모든 정보를 사용하여 신뢰할 수 있는 value 예측을 출력하도록 한다.
\[\begin{equation} v_{\tilde{1}}, \ldots, v_{\tilde{T}} = \textrm{VLM} (o_{\tilde{1}}, \ldots, o_{\tilde{T}}; l_\textrm{task}, o_1), \quad \mathrm{where} \; (\tilde{1}, \ldots, \tilde{T}) = \textrm{permute} (1, \ldots, T) \end{equation}\]여기서 permute 연산자는 시간 인덱스를 무작위로 섞는다. 그러나 모든 프레임을 섞으면 원본 동영상의 시간 방향이 모호해질 수 있다. 즉, 많은 경우 역재생한 동영상도 물리적으로 그럴듯하여 실제 순서를 예측하는 것이 불가능하다. 따라서 위의 식에서와 같이 VLM을 첫 번째 입력 프레임으로 컨디셔닝하여 첫 번째 observation을 다른 모든 섞인 프레임의 앵커 포인트로 사용할 수 있도록 한다.
3. In-context value learning
Autoregressive 예측과 셔플링만으로도 좋은 성능을 얻을 수 있지만, GVL은 VLM의 매력적인 특성을 활용하면 더 나은 성능을 낼 수 있다. 특히, 대규모 모델은 종종 in-context learning을 보이는데, 여기서 task는 단순히 예제를 제공함으로써 학습할 수 있다. 이를 통해 유연하고 다재다능한 in-context value learning이 가능해지며, GVL의 예측은 모델 fine-tuning 없이 test-time에 예제를 제공함으로써 꾸준히 개선될 수 있다. 특히, 셔플된 동영상과 GT task 진행률을 in-context 예제로 간단히 추가하여 few-shot 학습을 통해 value 예측 품질을 높일 수 있다.
\[\begin{equation} v_{\tilde{1}}, \ldots, v_{\tilde{T}} = \textrm{VLM} (o_{\tilde{1}}, \ldots, o_{\tilde{T}}; l_\textrm{task} \,\vert\, \textrm{permute}((o_1, v_1), \ldots, (o_M, v_M))) \end{equation}\]GVL은 관련 없는 task와 심지어 인간을 포함한 유연한 형태의 in-context 예시에서 이점을 얻는다. GVL zero-shot은 이미 광범위한 task와 로봇에서 효과적이지만, in-context learning을 통해 가장 어려운 양손 task에서 상당한 개선을 보였다.
Experiments
- backbone: Gemini-1.5-Pro
- 구현 디테일
- VLM에 0과 100 사이의 정수 값 백분율 숫자를 출력하도록 요청
- 실제 로봇 동영상 데이터셋은 길이가 다르고 다른 프레임레이트로 수집되므로 모든 동영상을 서브샘플링하여 입력 시퀀스에 30개의 프레임이 있도록 하였음
Value-Order Correlation (VOC)
가능한 한 많은 로봇 데이터셋에서 GVL의 value 추정을 대규모로 평가하고, 일반화 능력을 전체적으로 테스트하기 위해, 저자들은 value model을 평가하기 위한 Value-Order Correlation (VOC)을 도입하였다. 이 평가 지표는 예측된 value와 입력 전문가 동영상의 시간 순서 사이의 상관 관계를 계산한다.
\[\begin{equation} \textrm{VOC} = \textrm{rank-correlation} (\textrm{argsort}(v_{\tilde{1}}, \ldots, v_{\tilde{T}}); \textrm{arange}(T)) \end{equation}\]VOC의 범위는 -1에서 1까지이며, 1은 두 순서가 완벽하게 정렬되었음을 나타낸다. 전문가 데모는 시간이 지남에 따라 단조 증가하는 value를 가지므로 좋은 value model은 전문가 동영상에서 평가할 때 높은 VOC 점수를 가져야 한다. 반면에 품질이 낮은 궤적은 VOC 점수가 낮아야 한다.
1. Large-scale real-world evaluation
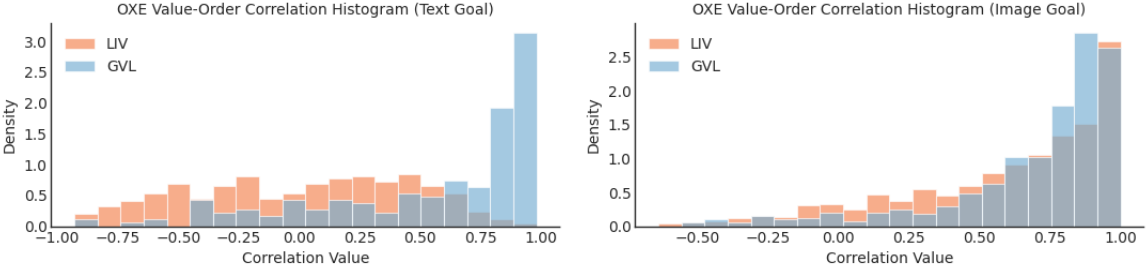
다음은 Open X-Embodiment (OXE) 데이터셋에서의 zero-shot value 예측 결과이다.
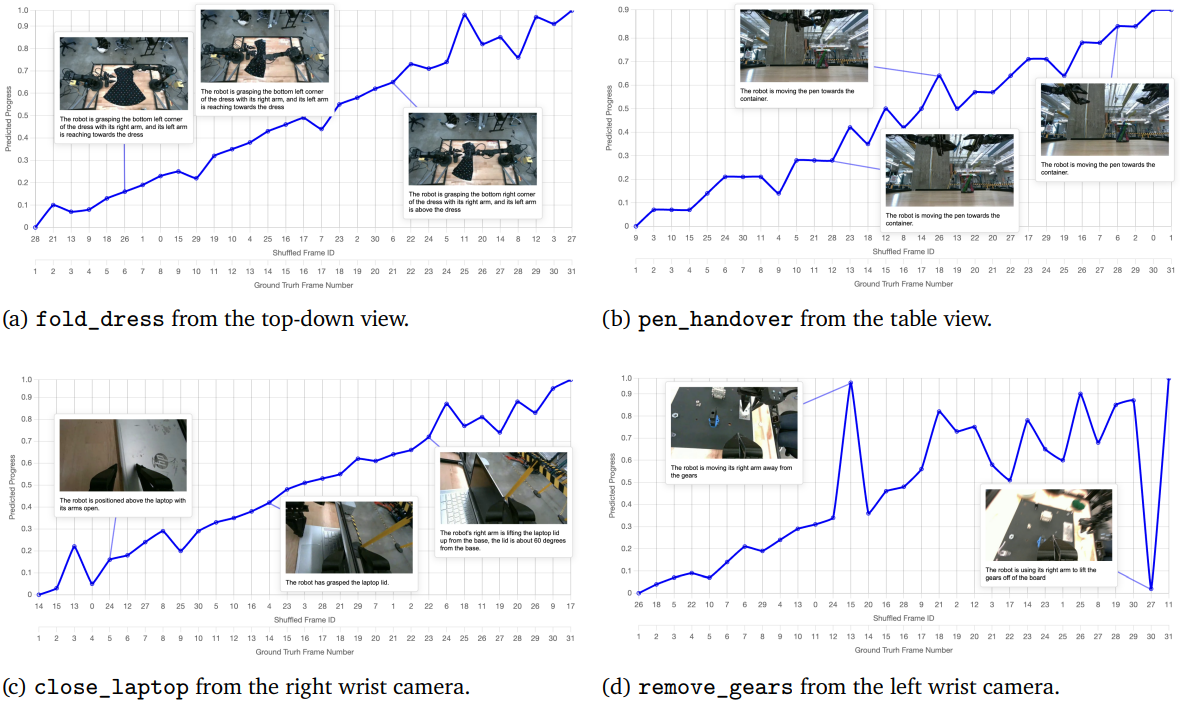
다음은 real-world ALOHA task에 대한 GVL의 예측들을 시각화한 것이다.
2. Multi-Modal In-Context Value Learning
다음은 ALOHA의 250개의 양손 task에 대한 결과이다.
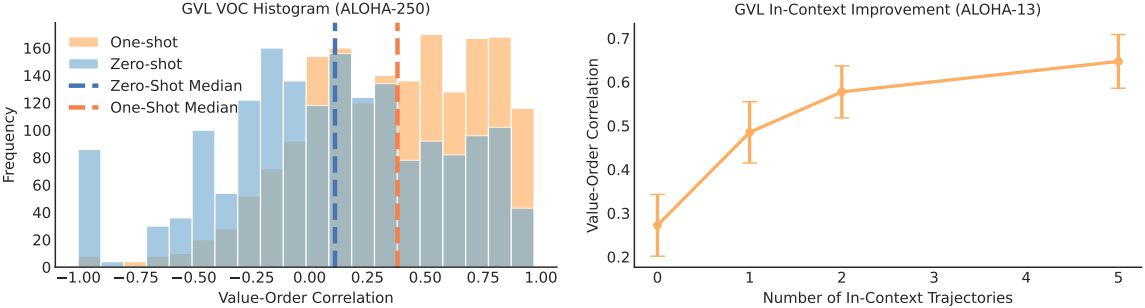
다음은 사람이나 다른 로봇의 데모로부터 in-context learning의 이점을 얻은 결과이다.

3. GVL Applications
다음은 여러 OXE 데이터셋에서 평균 VOC 점수를 비교한 표이다. 카메라가 가려지지 않은 데이터셋에서는 점수가 높고, 탐색(exploration)이 필요한 데이터셋의 경우 점수가 낮다.
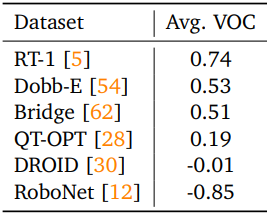
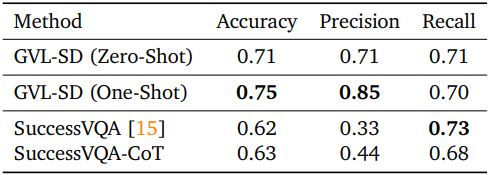
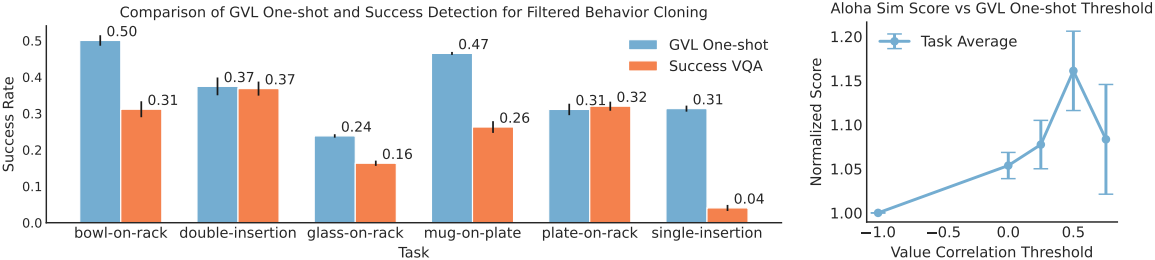
다음은 성공 여부를 판단하는 VLM과 성능을 비교한 결과이다.
다음은 성공 여부에 따른 GVL의 VOC 분포이다.
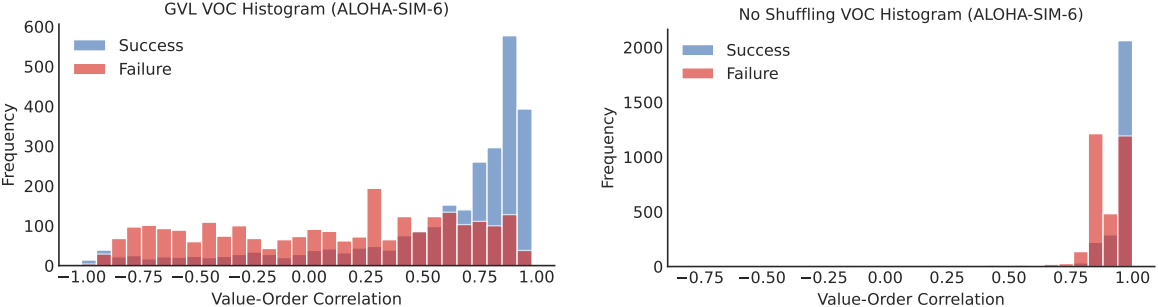
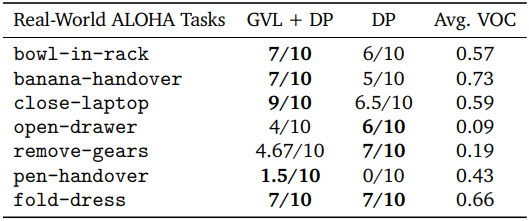
다음은 ALOHA 시뮬레이션 task에서 success-filtered behavior cloning을 위해 GVL을 사용한 결과이다.
다음은 real-world ALOHA에 대한 policy learning 결과이다.