[논문리뷰] Taming Video Diffusion Prior with Scene-Grounding Guidance for 3D Gaussian Splatting from Sparse Inputs
CVPR 2025 (Highlight). [Paper] [Page] [Github]
Yingji Zhong, Zhihao Li, Dave Zhenyu Chen, Lanqing Hong, Dan Xu
The Hong Kong University of Science and Technology | Huawei Noah’s Ark Lab
7 Mar 2025

Introduction
3DGS에서 sparse한 입력을 사용한 장면 모델링은 여전히 상당한 과제이며, 두 가지 중요한 문제가 존재한다.
- Extrapolation: 시야 밖에 있는 영역이 여전히 존재할 수 있다.
- Occlusion: 학습 입력 뷰에서 약간이라도 벗어난 새로운 뷰에서 occlusion이 자주 발생한다. 최적화된 3DGS로 렌더링할 때 심각한 아티팩트가 발생하여 이미지 품질이 크게 저하될 수 있다.
이 문제들을 해결하기 위해, 본 논문에서는 생성 모델을 사용한 3DGS 기반의 새로운 재구성 파이프라인을 제안하였다. 직관적으로, video diffusion model을 사용하여 멀티뷰 시퀀스를 생성하는데, 대규모 데이터셋에서 학습된 prior를 기반으로 장면에 대한 타당한 해석을 제공하여 이 문제들을 해결할 수 있는 높은 잠재력을 제공한다.
그러나 sparse한 입력과 생성된 시퀀스를 이용하여 3DGS를 최적화하는 단순한 파이프라인은 성능 향상을 거의 가져오지 못하거나 오히려 성능을 저하시킬 수 있다. 주된 이유는 생성된 시퀀스 내의 멀티뷰 불일치 때문이다. 이러한 불일치는 두 가지 측면에서 나타난다.
- 시퀀스 내 프레임 간의 외형 불일치
- 생성된 시퀀스에 장면에는 존재하지 않는 요소가 포함될 수 있음
저자들은 video diffusion model에서 학습된 prior를 최대한 활용하기 위해, 생성된 시퀀스 내 불일치 문제를 해결하는 방법을 추가로 탐구하였다. 프레임별로 학습 가능한 외형 임베딩을 할당하여 외형 불일치를 해결하는 기존 방법과 달리, video diffusion model을 길들여 일관성 있는 시퀀스를 직접 생성하는 데 중점을 두었다.
저자들은 diffusion model을 추가로 fine-tuning하지 않고도 일관된 생성을 보장하기 위해 scene-grounding guidance라는 새로운 전략을 도입하였다. 구체적으로, scene-grounding guidance는 최적화된 3DGS에서 렌더링된 시퀀스를 기반으로 한다. Denoising process의 각 step에서 noise가 있는 시퀀스는 렌더링된 시퀀스의 supervision으로부터 gradient를 받는다. 렌더링된 시퀀스가 완벽한 guidance를 제공하지는 않지만, 불일치 문제를 해결하기 위해 이를 사용하는 데 있어 핵심적인 통찰력은 두 가지이다.
- 렌더링된 시퀀스 내 인접 프레임은 카메라 이동이 제한되어 있어 매우 일관성이 있다.
- 렌더링된 시퀀스는 장면에 존재하지 않는 요소가 생성되는 것을 방지하기 위해 diffusion model을 가이드할 수 있다.
저자들은 시야 밖에 있거나 가려진 영역을 효과적으로 식별하기 위해, 시퀀스 생성 중 카메라 궤적을 결정하는 궤적 초기화 전략을 제안하였는데, 이 전략 역시 최적화된 3DGS를 기반으로 한다. 제안된 방법을 사용하면 장면의 전체적인 모델링을 수행할 수 있다. 또한, 저자들은 loss와 샘플링 설계에 중점을 두고 생성된 시퀀스를 사용하여 3DGS를 최적화하는 방안을 제시하여 전반적인 성능을 더욱 향상시켰다.
Method
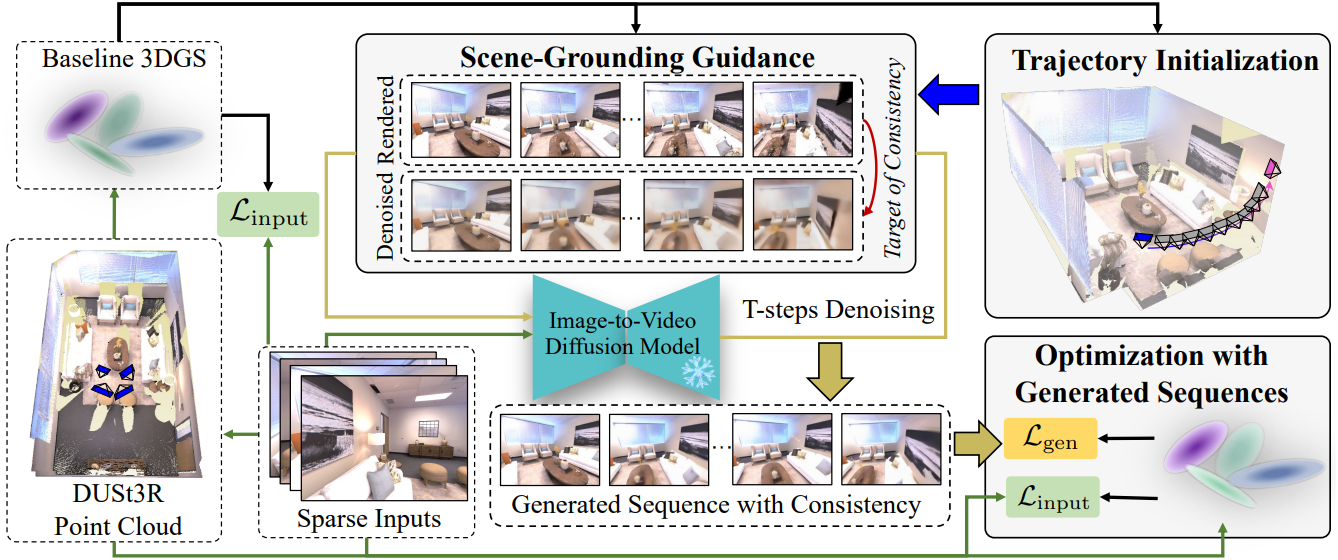
1. Generation via Scene-Grounding Guidance
Video diffusion model에서 생성된 시퀀스를 적용하면 sparse한 입력으로 포함되지 않은 영역에 대한 타당한 해석을 제공할 수 있다. 그러나 생성된 시퀀스 내의 불일치는 프레임 간 외형 불일치와 존재하지 않는 요소의 발생으로 나타나며, 이는 3DGS 모델링에 부정적인 영향을 미칠 수 있다.
저자들은 기존의 학습이 필요 없는 guidance 방법에서 영감을 받아, 일관성을 달성하기 위해 유사한 접근법을 채택하였다. 구체적으로, 아래와 같은 denoising process 식에서 score function \(\nabla_{\textbf{x}_t} \log p (\textbf{x}_t)\)를 조건부 score function \(\nabla_{\textbf{x}_t} \log p (\textbf{x}_t \vert \mathcal{Q})\)로 대체한다.
\[\begin{equation} \textbf{x}_{t-1} = (1 + \beta_t / 2) \textbf{x}_t + \beta_t \nabla_{\textbf{x}_t} \log p (\textbf{x}_t) + \sqrt{\beta_t} \textbf{z} \end{equation}\]여기서 $\mathcal{Q}$는 일관성 타겟을 나타낸다. 조건부 score function은 Bayesian rule을 통해 다음과 같이 확장될 수 있다.
\[\begin{equation} \nabla_{\textbf{x}_t} \log p (\textbf{x}_t \vert \mathcal{Q}) = \nabla_{\textbf{x}_t} \log p (\textbf{x}_t) + \nabla_{\textbf{x}_t} \log p (\mathcal{Q} \vert \textbf{x}_t) \end{equation}\]여기서 \(\nabla_{\textbf{x}_t} \log p (\mathcal{Q} \vert \textbf{x}_t)\)는 일관성 제약 조건을 denoising process에 주입하는 guidance 항으로 볼 수 있다. 구체적으로 \(p(\mathcal{Q} \vert \textbf{x}_t)\)는 다음과 같다.
\[\begin{equation} p(\mathcal{Q} \vert \textbf{x}_t) = \frac{\exp (-\lambda \mathcal{L}(\mathcal{Q}, \textbf{x}_t))}{Z} \end{equation}\](\(\mathcal{L}(\mathcal{Q}, \textbf{x}_t)\)는 현재 샘플 \(\textbf{x}_t\)가 target과 얼마나 잘 정렬되어 있는지를 나타냄, $Z$는 정규화 항)
따라서 guidance 항은 다음 loss function의 기울기를 사용하여 구현할 수 있다.
\[\begin{equation} \nabla_{\textbf{x}_t} \log p (\mathcal{Q} \vert \textbf{x}_t) \propto - \nabla_{\textbf{x}_t} \mathcal{L}(\mathcal{Q}, \textbf{x}_t) \end{equation}\]이 guidance 항은 denoising 샘플링 동안 일관성 타겟을 달성하기 위해 denoising process에 추가된다.
남은 문제는 일관성 타겟 $\mathcal{Q}$를 어떻게 정의할 것인가에 있다. 본 논문에서는 최적화된 3DGS 모델 $\mathcal{R}$의 렌더링된 시퀀스를 사용하여 타겟을 설정하였다. 렌더링된 시퀀스가 완벽하지는 않지만, 본 연구의 주요 통찰력은 다음과 같다.
- 인접 프레임의 렌더링된 이미지는 카메라 움직임이 일반적으로 미미하기 때문에 매우 일관성이 높다.
- 렌더링된 프레임은 장면에 어떤 요소가 존재하는지 명확하게 나타낸다.
따라서 렌더링된 시퀀스는 생성된 시퀀스가 일관성 타겟을 달성하는 데 효과적인 guidance 역할을 할 수 있다.
시퀀스 생성을 위한 카메라 궤적 \(\{\phi_j\}_{j=1}^L\)이 주어지면, 먼저 최적화된 3DGS를 사용하여 시퀀스 \(\textbf{S} = \{S_j\}_{j=1}^L \in \mathbb{R}^{L \times H \times W \times 3}\)과, sparse한 입력에 의해 가려지지 않는 영역을 나타내는 마스크 시퀀스 \(\textbf{M} = \{M_j\}_{j=1}^L \in \mathbb{R}^{L \times H \times W \times 1}\)을 렌더링한다. 마스크를 얻기 위해 먼저 opacity에 알파 블렌딩을 적용하여 얻은 transmittance map을 렌더링한다. 각 픽셀 $x_p$에 대해 알파 블렌딩은 다음과 같다.
\[\begin{equation} O(x_p) = \sum_{i \in K} \sigma_i \prod_{j=1}^{i-1} (1 - \sigma_j) \end{equation}\]($\sigma$는 Gaussian의 opacity, $O$는 transmittance map)
마스크는 transmittance map을 \(\eta_\textrm{mask}\)로 thresholding하여 얻는다.
\[\begin{equation} M = O < \eta_\textrm{mask} \end{equation}\]일관성 타겟은 깨끗한 데이터 공간에서 렌더링된 시퀀스를 기반으로 하므로, guidance를 받기 위해 모델 \(\epsilon_\theta\)의 예측을 기반으로 noise가 있는 latent \(\textbf{x}_t\)를 깨끗한 데이터 공간의 latent \(\textbf{x}_{0 \vert t}\)로 변환한다.
\[\begin{equation} \textbf{x}_{0 \vert t} = \frac{\textbf{x}_t − \sqrt{1 - \bar{\alpha}_t} \epsilon_\theta (\textbf{x}_t, t)}{\sqrt{\vphantom{1} \bar{\alpha}_t}} \end{equation}\]렌더링된 시퀀스 $\textbf{S}$를 기반으로 하는 일관성 타겟 $\mathcal{Q}$를 사용하여 guidance 항의 함수 $\mathcal{L}$을 다음과 같이 정의한다.
\[\begin{equation} \mathcal{L}(\textbf{S}, \textbf{M}, \textbf{X}_{0 \vert t}) = \| \textbf{M} \odot (\textbf{S} - \textbf{X}_{0 \vert t}) \|_1 + \lambda_\textrm{spec} \mathcal{L}_\textrm{spec} (\textbf{M} \odot \textbf{S}, \textbf{M} \odot \textbf{X}_{0 \vert t}) \end{equation}\](\(\textbf{X}_{0 \vert t}\)는 latent \(\textbf{x}_{0 \vert t}\)를 VAE로 디코딩한 시퀀스, \(\mathcal{L}_\textrm{spec}\)은 perceptual loss)
위 식의 guidance에 따라, denoising process는 일관성 제약 조건과 diffusion model의 prior를 균형 있게 조정하여 이를 타당한 생성 결과로 통합한다. 이 guidance는 diffusion model의 fine-tuning을 포함하지 않으므로, 생성 성능을 그대로 유지한다.

2. Trajectory Initialization Strategy
장면의 전체적인 모델링을 가능하게 하기 위해 video diffusion model의 카메라 궤적은 시야 밖에 있거나 가능한 한 가려진 영역을 포함해야 한다. 따라서 생성된 시퀀스는 이러한 영역에 대한 그럴듯한 해석을 제공할 수 있으며, 이는 후속 3DGS 모델을 최적화하는 기초가 된다.

제안된 궤적 초기화 방법도 최적화된 3DGS 모델을 기반으로 한다. 카메라 포즈가 \(\varphi_i\)인 $i$번째 입력 뷰의 경우, 먼저 그 주변의 후보 포즈 세트를 샘플링한다. 총 $m$개의 후보 포즈가 있다고 가정하면, 최적화된 3DGS 모델 $\mathcal{R}$을 사용하여 이러한 포즈에 대한 이미지를 렌더링한다.
렌더링된 이미지가 상당한 구멍을 보이는 포즈의 경우, 입력 카메라 포즈와 이러한 포즈 사이에 길이 $L$의 궤적을 다음과 같이 interpolation한다.
\[\begin{equation} \{\phi_j^{(i,c)}\}_{j=1}^L = \textrm{interp}(\varphi_i, \hat{\phi}_c^{(i)}) \end{equation}\]실제로는 해당 마스크의 크기에 따라 상위 $k$개의 후보 포즈를 선택한다. 그런 다음, 모든 입력 뷰와 각각의 선택된 후보 포즈를 순회하여 궤적 풀을 다음과 같이 구축한다.
\[\begin{equation} \Phi = \{\{ \phi_j^{(i,c)} \}_{j=1}^L \vert i, c\} \end{equation}\]여기서 궤적 풀의 각 요소는 시퀀스 생성을 위해 샘플링된다.
3. 3DGS Optimization with Generation
$N$개의 이미지와 그 포즈 \(\{C_i^\textrm{gt}, \varphi_i\}_{i=1}^N\)가 입력으로 주어졌을 때, 보조적으로 생성된 시퀀스를 이용하여 3DGS 모델을 최적화한다. 각 iteration에서 입력 뷰와 생성된 뷰를 샘플링한다. 구체적으로, 입력 뷰의 경우, 다음과 같은 기본 reconstruction loss를 사용한다.
\[\begin{equation} \mathcal{L}^\textrm{input} = (1 - \lambda)\mathcal{L}_1 (C_i, C_i^\textrm{gt}) + \lambda \mathcal{L}_\textrm{D-SSIM} (C_i, C_i^\textrm{gt}) \end{equation}\]($C_i$는 렌더링된 이미지)
생성된 뷰의 경우, reconstruction loss를 사용하면 구멍 영역을 효과적으로 채우지 못하며, 가중치를 증가시키면 생성된 이미지의 결함으로 인해 성능 저하가 발생한다. 저자들은 이 문제를 해결하기 위해 perceptual loss를 사용하였다. Perceptual loss는 전체 이미지에 대해 계산되므로, 구멍 영역이 gradient에 상당한 영향을 미쳐 모델이 해당 영역을 효과적으로 채우도록 유도한다. 따라서 생성된 뷰에 대한 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}^\textrm{gen} = \lambda_\textrm{gen1} \mathcal{L}_1 (C_j, S_j) + \lambda_\textrm{gen2} \mathcal{L}_\textrm{spec} (C_j, S_j) \end{equation}\]($S_j$는 생성된 이미지)
저자들은 특정 최적화 구간 내에서 생성된 뷰의 상당 부분이 동일한 로컬 영역 시퀀스에서 샘플링되는 로컬 샘플링을 수행하면 시각적 품질이 향상됨을 경험적으로 확인했다. 그러나 단일 시퀀스에서만 샘플링하면 다른 영역의 구멍에 대한 최적화된 정보가 희석되는 forgetting 문제가 발생할 수 있다. 따라서 각 로컬 샘플링 구간 내에 비율 $\eta$를 갖는 다른 시퀀스에서 생성된 뷰도 포함한다.

Experiments
- 장면: Replica 6개, ScanNet++ 4개
- 구현 디테일
- 생성 모델: Viewcrafter ($L = 25$)
- 마스크 threshold: $\eta_\textrm{mask} = 0.9$
- $\lambda = 0.2$, \(\lambda_\textrm{perc} = 10^{-4}\), \(\lambda_\textrm{gen1} = 0.1\), \(\lambda_\textrm{gen2} = 0.01\)
- 생성 간격: 260
- 총 iteration: 10,000
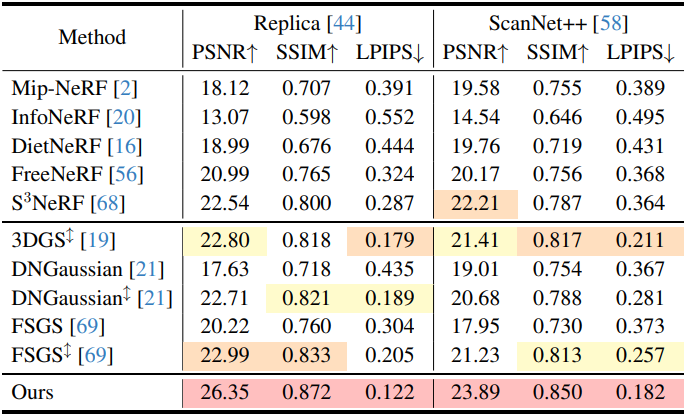
1. Comparisons
다음은 Replica와 ScanNet++에서의 비교 결과이다.

2. Ablation Studies
다음은 Replica에서의 ablation 결과이다.

다음은 guidance 유무에 따른 영향을 비교한 결과이다.

다음은 perceptual loss에 대한 ablation 결과이다.

3. Further Comparisons with Inpainting Methods
다음은 Replica에서 inpainting 방법들과 비교한 결과이다.

