[논문리뷰] Guided-TTS 2: A Diffusion Model for High-quality Adaptive Text-to-Speech with Untranscribed Data
arXiv 2022. [Paper] [Page]
Sungwon Kim, Heeseung Kim, Sungroh Yoon
Seoul National University
30 May 2022
Guided-TTS의 후속 논문이다.
Introduction
최근 diffusion 기반 생성 모델은 diffusion guidance 방법들을 통해 클래스 조건부 및 텍스트 조건부 생성에서 인상적인 결과를 얻었다. 음성 합성에서는 diffusion 기반 생성 모델이 샘플 품질과 inference 속도 사이의 trade-off를 유지하며 고품질 오디오 샘플을 생성한다. Guided-TTS는 target speaker의 전사되지 않은 데이터를 사용한 고품질 TTS를 가능하게 하였다. Diffusion model들이 고품질 TTS 합성에 성공하였음에도 불구하고 적응형 TTS를 위한 diffusion model의 잠재력은 아직 연구되지 않았다.
본 논문에서는 적은 양의 전사되지 않은 데이터를 사용하는 적응형 TTS를 위한 diffusion 기반 생성 모델인 Guided-TTS 2를 제안한다. 다양한 speaker의 음성 분포를 모델링하도록 대규모의 전사되지 않은 데이터셋에서 speaker-conditional DDPM을 학습시킨다. Classifier-free guidance 방법을 사용하여 사전 학습된 diffusion model을 target speaker에 적응시키고 레퍼런스 음성 데이터로 직접 fine-tuning한다. Fine-tuning이 적응을 위한 추가 학습 시간을 필요로 함에도 불구하고 Guided-TTS 2는 diffusion model의 적응력을 기반으로 fine-tuning에 걸리는 시간을 1분 미만으로 상당히 줄였다. 10초 정도의 fine-tuning으로 single-speaker TTS와 비슷한 샘플 품질과 speaker 유사성을 달성했다고 한다.
Guided-TTS 2
Guided-TTS 2의 목표는 적은 양의 전사되지 않은 데이터로 새로운 speaker를 적응시키는 것이다. Guided-TTS를 적응형 TTS로 확장하기 위해 multi-speaker의 전사되지 않은 데이터셋에서 speaker-conditional DDPM을 학습시키고 classifier guidance를 사용하여 phoneme classifier로 diffusion model을 guide한다. Guided-TTS에서 사용된 norm-based guidance의 발음 정확성에 기반하여 speaker-conditional DDPM이 새로운 speaker에 대한 조건부 score를 추정하도록 한다.
새로운 speaker에 더 잘 적응하도록 target speaker의 전사되지 않은 레퍼런스 음성으로 diffusion model을 fine-tuning한다. Guided-TTS 2가 전사되지 않은 음성에만 적응하기 때문에 외국어와 같은 까다로운 레퍼런스 음성을 사용하는 적응형 TTS를 가능하게 한다.
1. Speaker-conditional Diffusion Model
Speaker-conditional DDPM은 전사 없이 다양한 speaker의 음성에 대한 speaker-conditional score를 추정한다. Target speaker에 대한 zero-shot 적응 능력을 위해 사전 학습된 speaker verification model을 speaker encoder $E_S$로 사용하여 speaker 정보를 인코딩한다.
Mel-spectogram $X = X_0$가 주어지면 다음과 같은 forward process는 점진적으로 데이터를 noise로 손상시킨다.
\[\begin{equation} dX_t = - \frac{1}{2} X_t \beta_t dt + \sqrt{\beta_t} dW_t \end{equation}\]그리고 reverse denoising process에 필요한 speaker $S$에 대한 unconditional score
\[\begin{equation} \nabla_{X_t} \log p(X_t \vert S) \end{equation}\]를 추정하도록 학습된다. Guided-TTS와 같은 U-Net 아키텍처를 speaker-conditional DDPM $s_\theta$로 사용한다. Speaker 정보를 컨디셔닝하기 위해 speaker embedding $e_S = E_S (X) \in \mathbb{R}^d$를 mel-spectogram $X$에서 추출하고, timestep $t$와 concat한다. $s_\theta$의 목적 함수는 다음과 같다.
\[\begin{equation} L(\theta) = \mathbb{E}_{t, X_0, \epsilon_t} [\| s_\theta (X_t \vert S) + \lambda (t)^{-1} \epsilon_t \|_2^2 ] \end{equation}\]Speaker classifier-free guidance를 위해 GLIDE에서와 같이 null embedding $e_\phi \in \mathbb{R}^d$를 도입하고 $s_\theta$가 conditional score와 unconditional score를 모두 추정하도록 학습시킨다. 각 iteration에서 $e_S$를 50% 확률로 $e_\phi$로 교체하여 unconditional score를 추정하도록 한다. Speaker embedding이 unit norm을 가지도록 설정하기 위해 $e_\phi$를 추가 파라미터 $w \in \mathbb{R}^d$로 정의한다.
\[\begin{equation} e_\phi = \frac{w}{\| w \|} \end{equation}\]Zero-shot 적응을 위해 speaker embedding $e_{\hat{S}}$를 target speaker $\hat{S}$의 레퍼런스 데이터에서 추출하고 diffusion model에 제공한다. Classifier-free scale $\gamma_S$를 0보다 크게 설정하여 speaker 조건을 augment한다. 수정된 conditional score는 다음과 같다.
\[\begin{equation} \hat{s}_\theta (X_t \vert \hat{S}) = s_\theta (X_t \vert \hat{S}) + \gamma_S \cdot (s_\theta (X_t \vert \hat{S}) - s_\theta (X_t \vert \phi)) \end{equation}\]2. Fine-tuning
앞서 설명한 zero-shot 적응은 레퍼런스 데이터에서 추출한 speaker embedding에 의존한다. Target speaker에 더 잘 적응하도록 하기 위해 사전 학습된 $s_\theta$를 레퍼런스 데이터로 fine-tuning하여 target speaker의 speaker-conditional score를 추정하도록 한다. 대부분의 기존 적응형 TTS가 fine-tuning에 1분 이상 필요한 것에 비해 대규모 multi-speaker 데이터셋에서 학습된 $s_\theta$은 10초만 fine-tuning해도 target speaker에 잘 적응하였다. 하지만, 레퍼런스 데이터에 $s_\theta$가 overfitting되면 diffusion model이 multi-speaker 데이터셋에서 학습한 발음 능력을 잃게 되고 TTS 합성에 사용하기 어려워진다. 따라서, 본 논문에서는 작은 learning rate와 작은 수의 iteration으로 fine-tuning하여 레퍼런스 데이터에 overfitting되지 않도록 한다.
$\hat{S}$의 레퍼런스 데이터가 주어지면 먼저 $e_{\hat{S}}$를 추출한다. 레퍼런스 데이터를 사용하여 사전 학습에 사용한 learning rate인 $1 \times 10^{-4}$보다 작은 $2 \times 10^{-5}$로 diffusion model을 최적화한다. 저자들은 사전 학습된 optimizer의 통계값들이 적응 성능을 악화시키는 것을 발견했다. 따라서 사전 학습된 diffusion model의 가중치만 재사용하며 optimizer는 초기화한다. Fine-tuning은 사전 학습과 같은 목적 함수로 진행된다.
Diffusion model은 500 iteration으로 업데이트되며 모델이 발음 능력을 유지하면서 다양한 target speaker에 잘 적응하도록 한다. Fine-tuning은 NVIDIA RTX 8000 GPU로 40초가 걸린다고 한다.
3. Adaptive Text-to-Speech
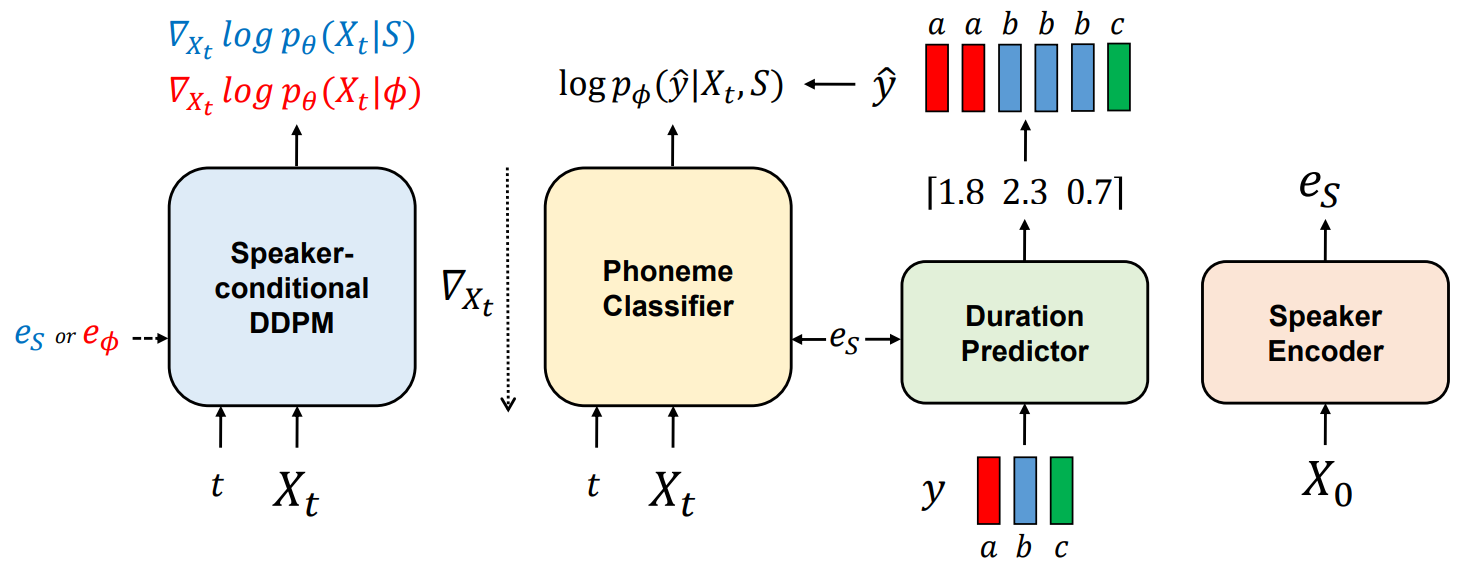
Guided-TTS 2는 위 그림과 같이 speaker-conditional DDPM, phoneme classifier, duration predictor, speaker encoder로 구성된다. Phoneme classifier는 mel-spectogram $X_t$에서 frame-wise하게 음소 시퀀스를 예측하며, duration predictor는 각 음소의 duration을 출력한다. 새로운 speaker에 대해 일반화하기 위해 모든 모듈은 speaker embedding을 조건으로 사용한다.
생성할 음소 시퀀스를 $y$라고 하자. 먼저 duration predictor가 각 음소의 duration을 예측하고 나면, 예측된 duration으로 $y$를 프레임 레벨의 음소 시퀀스 $\hat{y}$로 확장한다. 그런 다음 noise $X_1$을 $\hat{y}$와 같은 길이로 표준 가우시안 분포에서 샘플링한다. 적응형 TTS를 수행하기 위해 다음과 같은 식을 사용한다.
\[\begin{equation} X_{t - \frac{1}{N}} = X_t + \frac{\beta_t}{N} ( \frac{1}{2} X_t + \hat{s}_\theta (X_t \vert \hat{y}, \hat{S})) + \sqrt{\frac{\beta_t}{N}} z_t \end{equation}\]\(\hat{s}_\theta (X_t \vert \hat{y}, \hat{S})\)를 계산하기 위해 classifier-free guidance와 norm-based guidance를 결합한다. Reverse sampling process의 각 timestep에서 classifier-free guidance로 \(\hat{s}_\theta (X_t \vert \hat{S})\)를 얻고 사전 학습된 phoneme classifier로 classifier 기울기
\[\begin{equation} \nabla_{X_t} \log p(\hat{y} \vert X_t, \hat{S}) \end{equation}\]를 계산한다. 수정된 조건부 score는 다음과 같다.
\[\begin{equation} \hat{s}_\theta (X_t \vert \hat{y}, \hat{S}) = \hat{s}_\theta (X_t \vert \hat{S}) + \gamma_T \cdot \frac{\| \hat{s}_\theta (X_t \vert \hat{S}) \|}{\| \nabla_{X_t} \log p(\hat{y} \vert X_t, \hat{S}) \|} \cdot \nabla_{X_t} \log p(\hat{y} \vert X_t, \hat{S}) \end{equation}\]$\gamma_T$는 norm-based guidance를 위한 text gradient scale이다.
Experiments
- 데이터셋
- Speaker-dependent phoneme classifier & Duration predictor: LibriSpeech (982시간, 2484 speakers)
- Speaker encoder: VoxCeleb2 (1M utterances, 6112 speakers)
- Speaker-conditional diffusion model: LibriTTS (585시간, 2456 speakers), Libri-Light (6만 시간)
- Model comparison: LJSpeech
- Training Details
- Speaker-conditional diffusion model을 제외하고 Guided-TTS와 같은 아키텍처와 파라미터 사용
- 오픈소스 소프트웨어로 텍스트를 International Phonetic Alphabet (IPA) phoneme 시퀀스로 변환
- mel-spectrogram 추출에는 Glow-TTS와 같은 hyperparameter 사용
- Montreal Forced Aligner (MFA)로 음성과 전사의 alignment를 추출
- Phoneme classifier, duration predictor, speaker encoder는 Guided-TTS와 같은 방법으로 학습
1. Comparison to Single Speaker TTS Models
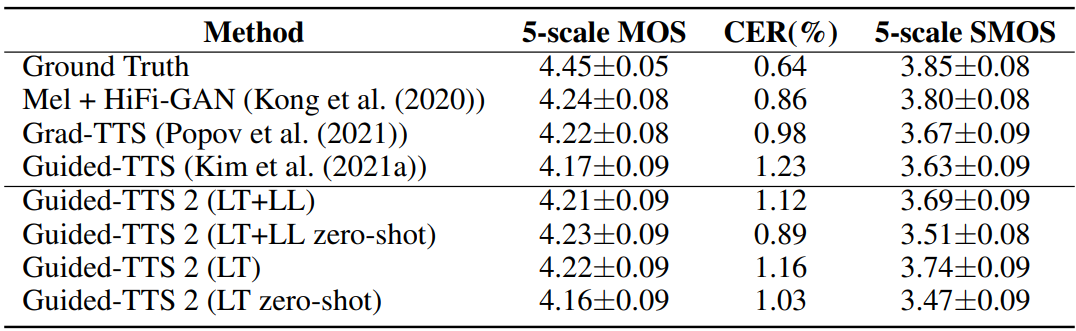
저자들은 Amazon Mechanical Turk를 사용하여 LJSpeech에서 5-scale mean opinion score (MOS)와 5-scale speaker similarity mean opinion score (SMOS)를 측정하였다. 생성된 샘플이 텍스트를 잘 반영하는 지 확인하기 위해 Character Error Rate (CER)을 사용한다. MOS와 CER 모두 50개의 샘플을 랜덤하게 선택하여 평가하였다. SMOS 평가에는 사전에 선택된 10개의 레퍼런스 샘플이 사용된다. 각 레퍼런스 오디오마다 5문장을 생성하였다고 한다.
다음은 고품질 single speaker TTS 모델과 비교한 표이다. “LT”는 LibriTTS, “LL”은 Libri-Light를 의미한다.
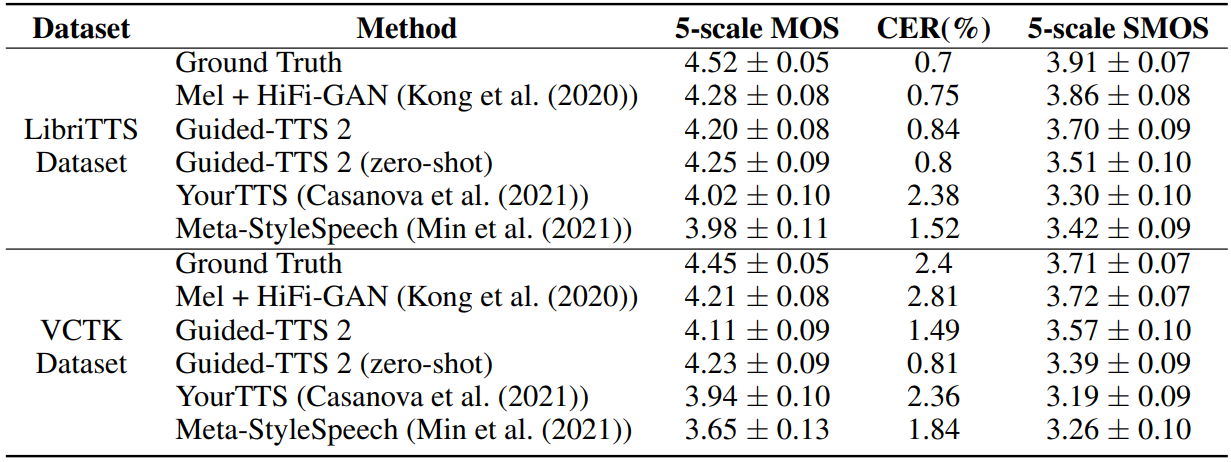
2. Comparison to Adaptive TTS Models
다음은 다양한 적응현 TTS 모델과 비교한 표이다.
3. Analysis
Effect of Fine-tuning
위 표들에서 Guided-TTS 2 (zero-shot)와 Guided-TTS 2의 결과를 비교해 보면 fine-tuning을 하면 SMOS가 개선되지만 발음 정확도를 잃는다는 것을 볼 수 있다. 다시 말해, 모델이 fine-tuning되면 샘플이 운율과 음색에 관해서는 레퍼런스 음성에 가까워지지만 주어진 텍스트에서 멀어진다. 적응형 TTS의 주 목적이 주어진 reference speaker에 가까운 음성을 생성하는 것이므로 저자들은 발음 정확도의 희생을 최소화하면서 유사성을 개선하는 것을 목표로 하였다.
Effects of Speaker Classifier-free Gradient Scale
다음은 LibriTTS에서 $\gamma_S$에 따른 모델의 성능을 나타낸 그래프이다.
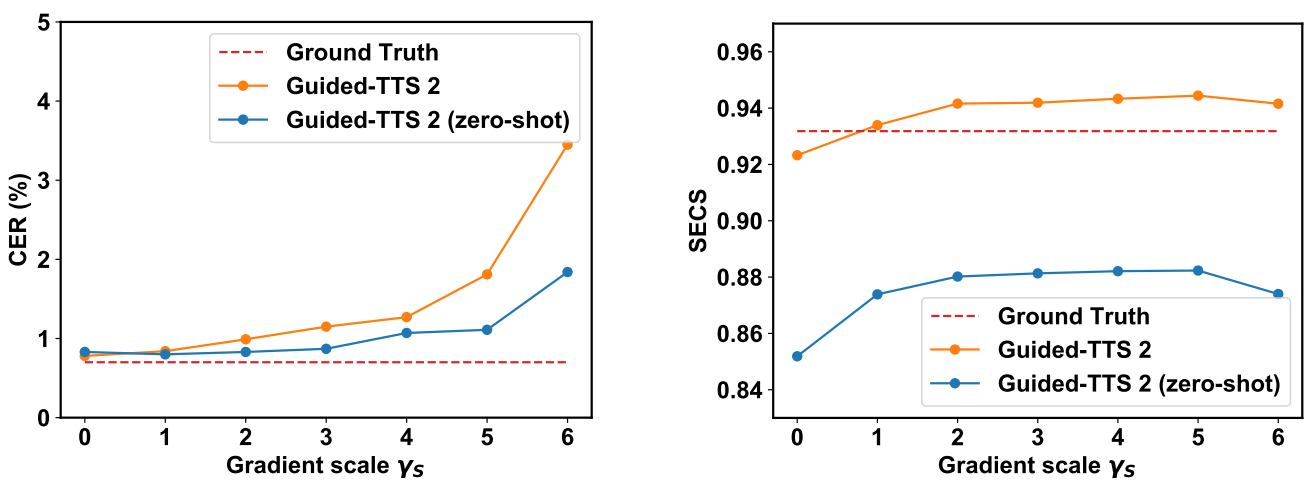
Gradient scale이 증가하면 발음 정확도가 감소하고 speaker 유사성이 조금 증가한다. 특히, fine-tuning된 모델의 발음 정확도는 gradient scale에 민감하다. $\gamma_S \in [1, 3]$으로 설정하면 Guided-TTS 2가 고품질 샘플을 생성하면서 정확하게 발음한다고 한다. 편의를 위해 $\gamma_S = 1$을 default로 한다.