[논문리뷰] Guided-TTS: A Diffusion Model for Text-to-Speech via Classifier Guidance
ICML 2021. [Paper] [Page]
Heeseung Kim, Sungwon Kim, Sungroh Yoon
Seoul National University
23 Nov 2021
Introduction
신경망 TTS 모델은 주어진 텍스트에서 고품질의 사람과 유사한 음성을 생성하기 위한 모델이다. 일반적으로 TTS 모델은 텍스트를 hidden representation으로 인코딩하고 인코딩된 representation에서 음성을 생성하는 조건부 생성 모델이다. 초기 TTS 모델은 고품질 음성을 생성하지만 순차적 샘플링 절차로 인해 합성 속도가 느린 autoregressive 생성 모델이다. Non-autoregressive 생성 모델의 개발로 인해 최근의 TTS 모델은 더 빠른 inference 속도로 고품질 음성을 생성할 수 있다. 최근에는 텍스트에서 raw waveform을 한 번에 생성하는 고품질 end-to-end TTS 모델이 제안되었다.
음성 합성의 높은 품질과 빠른 inference 속도에도 불구하고 대부분의 TTS 모델은 target speaker의 전사 데이터 (음성 → 문자)가 제공되어야만 학습이 가능하다. 오디오북이나 팟캐스트와 같이 전사되지 않은 긴 형태의 데이터는 다양한 웹사이트에서 사용할 수 있지만 이러한 음성 데이터를 기존 TTS 모델의 학습 데이터셋으로 사용하는 것은 어렵다. 이러한 데이터를 활용하기 위해서는 긴 형태의 전사되지 않은 음성 데이터를 문장으로 분할하고 각 음성을 정확하게 전사해야 한다. 기존 TTS 모델은 텍스트가 주어진 음성의 조건부 분포를 직접 모델링하기 때문에 전사되지 않은 데이터를 직접 사용하는 것은 여전히 어려운 과제이다.
또한 few-shot TTS 합성을 위해 사전 학습된 multi-speaker TTS 모델을 적응시키는 전사되지 않은 음성을 사용하는 접근 방식이 있다. 이러한 적응형 TTS 모델은 학습시키기 어렵고 고품질의 multi-speaker TTS 데이터셋이 필요한 사전 학습된 multi-speaker TTS 모델에 크게 의존한다. 또한 일반화의 어려움으로 인해 대량의 전사 데이터로 학습된 Glow-TTS나 Grad-TTS와 같은 고품질 단일 speaker TTS 모델에 비해 성능이 떨어진다.
본 논문에서는 unconditional DDPM으로 음성 생성을 학습하고 classifier guidance를 사용하여 텍스트 음성 합성을 수행하는 고품질 TTS 모델인 Guided-TTS를 제안한다. 대규모 음성 인식 데이터셋에서 학습된 음소 classifier를 도입함으로써 Guided-TTS는 TTS를 위한 target speaker의 어떤 전사 데이터도 사용하지 않는다. 전사되지 않은 데이터에 대해 학습된 생성 모델은 컨텍스트 없이 mel-spectogram을 생성하는 방법을 배운다. 전사되지 않은 데이터가 텍스트 시퀀스와 정렬될 필요가 없기 때문에 생성 모델을 학습시키기 위해 전사되지 않은 음성의 랜덤 묶음을 사용하기만 하면 된다. 이를 통해 긴 형태의 전사되지 않은 데이터만 사용할 수 있는 speaker의 음성을 모델링하는 데 추가 노력 없이 학습 데이터셋을 구축할 수 있다.
TTS를 위한 unconditional DDPM을 guide하기 위해 대규모 음성 인식 데이터셋인 LibriSpeech에서 프레임별 음소 classifier를 학습시키고 샘플링 중에 classifier의 기울기를 사용한다. Guided-TTS는 전사 없이 학습되지만 음소 classifier를 사용하여 unconditional DDPM의 생성 프로세스를 guide하여 전사가 주어진 mel-spectogram을 효과적으로 생성한다. Guiding error를 통한 잘못된 발음은 TTS 모델에 치명적이므로 샘플링 중 classifier 기울기와 unconditional score의 균형을 맞추는 norm 기반 guidance를 제시한다.
Guided-TTS
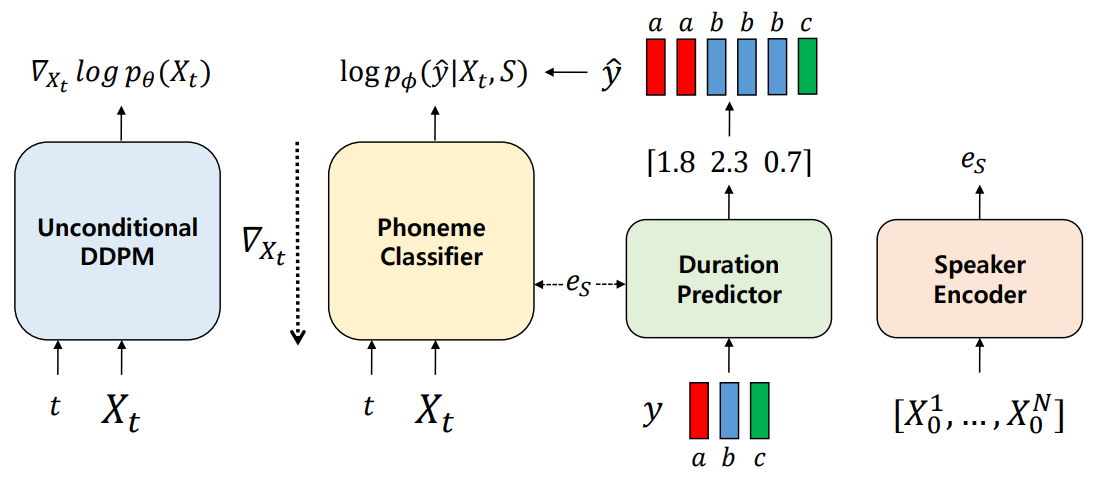
Guided-TTS는 4개의 모듈로 구성된다.
- Unconditional DDPM
- Phoneme(음소) classifier
- Duration predictor
- Speaker encoder
1. Unconditional DDPM
Unconditional DDPM은 전사 없이 음성 $P_X$의 unconditional한 분포를 모델링한다. 단일 target speaker $S$의 전사되지 않은 음성 데이터를 diffusion model의 학습 데이터로 사용하여 speaker $S$에 대한 TTS를 구축한다. Diffusion model은 전사 없이 학습하므로 학습 샘플을 전사와 정렬할 필요가 없다. 따라서 Guided-TTS가 $S$에 대해 긴 형태의 전사되지 않은 데이터만 사용할 수 있는 경우 전사되지 않은 음성 데이터의 랜덤 묶음 학습 데이터를 사용한다.
Mel-spectogram $X = X_0$가 주어지면 다음과 같은 forward process는 점진적으로 데이터를 noise로 손상시킨다.
\[\begin{equation} dX_t = - \frac{1}{2} X_t \beta_t dt + \sqrt{\beta_t} dW_t \end{equation}\]그리고 unconditional score $\nabla_{X_t} \log p(X_t)$를 각 timestep $t$에 대하여 추정하는 reverse process를 근사한다.
\[\begin{equation} dX_t = (-\frac{1}{2} X_t - \nabla_{X_t} \log p_t (X_t)) \beta_t dt + \sqrt{\beta_t} d \tilde{W}_t \end{equation}\]각 iteration에서 $X_t, t \in [0, 1]$가 mel-spectogram $X_0$로부터 샘플링된다.
\[\begin{equation} X_t \vert X_0 \sim \mathcal{N} (\rho (X_0, t), \lambda (t)) \end{equation}\]Score는 신경망 $s_\theta (X_t, t)$로 parameterize된다. 목적 함수는 다음과 같다.
\[\begin{equation} L(\theta) = \mathbb{E}_{t, X_0, \epsilon_t} [\| s_\theta (X_t, t) + \lambda (t)^{-1} \epsilon_t \|_2^2 ] \end{equation}\]Grad-TTS와 비슷하게 저자들은 mel-spectogram을 채널이 1개인 2D 이미지로 생각하며 U-Net 아키텍처를 사용한다. DDPM에서 32$\times$32 이미지에 적용된 아키텍처와 같은 크기의 아키텍처를 사용하며, 이를 통해 어떠한 텍스트 정보 없이 long-term dependency를 캡처한다. 반면 Grad-TTS는 조건부 분포 모델링을 위해 더 작은 아키텍처를 사용한다.
2. Text-to-Speech via Classifier Guidance
TTS 합성을 위해 frame-wise phoneme classifier를 도입하고 classifier guidance를 사용하여 unconditional DDPM을 guide한다. Classifier guidance를 통한 TTS는 텍스트 정보를 컨디셔닝하여 음성의 생성적 모델링을 분리한다. 이는 phoneme classifier를 위해 noisy한 음성 인식 데이터셋을 학습 데이터로 활용할 수 있게 하며, 기존 TTS 모델에서는 어려운 일이다.
주어진 텍스트로 mel-spectogram을 생성하기 위해서 duration predictor가 각 텍스트 토큰의 duration을 출력하고, 전사 $y$를 프레임 레벨의 음소 레이블 $\tilde{y}$로 확장한다. 그런 다음 $\tilde{y}$와 같은 길이로 랜덤 noise $X_T$를 표준 정규 분포에서 샘플링한 후, 조건부 score로 조건부 샘플을 생성할 수 있다.
아래와 같은 식으로 조건부 score를 예측할 수 있다.
\[\begin{aligned} \nabla_{X_t} \log p(X_t \vert \hat{y}, spk = S) &= \nabla_{X_t} \log p_\theta (X_t \vert spk = S) \\ &+ \nabla_{X_t} \log p_\phi (\hat{y} \vert X_t, spk = S) \end{aligned}\]우변의 첫번쨰 항은 unconditional DDPM에서 얻어 지고, 두번쨰 항은 phoneme classifier로 계산할 수 있다. 즉, unconditional한 생성 모델에 phoneme classifier의 기울기를 더해 TTS 모델을 구축할 수 있다.
임의의 target speaker $S$로 unconditional DDPM을 guide하려면, phoneme classifier와 duration predictor는 대규모 음성 인식 데이터셋에서 학습되어야 하고 모르는 speaker $S$에 대한 더 나은 일반화를 위해 speaker-dependent한 모듈로 디자인되어야 한다. 본 논문에서는 사전 학습된 speaker verification network에서 추출한 speaker embedding을 두 모듈에 조건으로 제공한다.
Phoneme Classifier
Phoneme classifier는 입력 mel-spectogram의 각 프레임에 대응되는 음소를 인식하도록 대규모 음성 인식 데이터셋에서 학습된다. Frame-wise phoneme classifier를 학습하기 위해 전사와 음성을 forced alignment tool인 Montreal Forced Aligner (MFA)로 align하고 프레임 레벨의 음소 레이블 $\tilde{y}$를 추출한다. Phoneme classifier는 손상된 mel-spectogram $X_t$를 $\hat{y}$로 분류하도록 학습된다. 학습 목적 함수는 출력 확률과 $\hat{y}$ 사이의 cross-entropy의 기대값을 최소화하도록 한다.
본 논문은 WaveNet과 비슷한 아키텍처를 phoneme classifier로 사용하며, time embedding $e_t$는 글로벌한 조건으로 사용되어 $X_t$의 noise 레벨에 대한 정보를 제공한다. Speaker-dependent한 분류를 위해 speaker encoder에서 얻은 speaker embedding $e_S$를 글로벌한 조건으로 사용한다.
Duration Predictor
Duration predictor는 주어진 텍스트 시퀀스 $y$의 각 텍스트 토큰의 duration을 예측하는 모듈이다. 각 텍스트 토큰의 duration label은 phoneme classifier와 같은 데이터로 학습된 MFA로 추출한다. Duration predictor는 duration label과 추정된 duration 사이의 L2 loss를 로그 도메인에서 최소화하여 학습되며, inference 시에는 추정된 duration을 반올림하여 사용한다. Duration predictor의 아키텍처는 Glow-TTS의 아키텍처를 사용한다. Text embedding과 speaker embedding $e_S$를 concat하여 speaker-dependent duration을 예측한다.
Speaker Encoder
Speaker encoder는 입력 mel-spectogram에서 speaker 정보를 인코딩하고 speaker embedding $e_S$를 출력한다. Speaker encoder는 speaker verification 데이터셋으로 GE2E loss로 학습되며, speaker encoder를 사용하여 speaker-dependent한 모듈을 컨디셔닝한다. 각 학습 데이터의 깨끗한 mel-spectogram $X_0$에서 $e_S$를 추출한다. Guidance를 위해 target speaker $S$ 전사되지 않은 음성의 speaker embedding을 평균화하고 정규화하여 $e_S$를 추출한다.
3. Norm-Based Guidance

앞에서는 classifier의 기울기 $\nabla_{X_t} \log p_\phi (\hat{y} \vert X_t, spk = S)$를 gradient scale $s$로 스케일링하였다. 하지만, unconditional DDPM을 frame-wise phoneme classifier로 guide하면 $t = 0$ 근처에서 unconditional score의 norm이 갑자기 증가한다. 즉, 데이터 $X_0$에 가까울수록 phoneme classifier가 DDPM의 생성 프로세스에 적은 영향을 준다. 다양한 수의 gradient scale을 사용하여 샘플을 생성하는 실험은 모든 경우에 대해 텍스트가 주어진 샘플을 잘못 발음하는 결과를 낳았다고 한다.
여기서 저자들은 unconditional DDPM을 $\tilde{y}$를 조건으로 둔 음성 생성 측면에서 더 잘 guide하기 위한 norm-based guidance를 제안한다. Norm-based guidance는 score가 급격하게 증가함에 따라 기울기의 영향이 미미해지는 것을 방지하기 위해 score의 norm에 비례하여 classifier 기울기의 norm을 스케일링하는 방법이다. 스케일링된 기울기의 norm과 score의 norm 사이의 비율은 gradient scale $s$로 정의된다. $s$를 조정하여 classifier 기울기가 unconditional DDPM의 guidance에 얼마나 기여하는지 확인할 수 있다. 또한 DDPM을 guide할 때 temperature parameter $\tau$를 사용한다. $\tau$를 1보다 큰 값으로 조정하면 고품질 mel-spectogram을 생성하는 데 도움이 된다.
Experiments
- 데이터셋
- Speaker-dependent phoneme classifier & Duration predictor: LibriSpeech (982시간, 2484 speakers)
- Speaker encoder: VoxCeleb2 (1M utterances, 6112 speakers)
- Model comparison: LJSpeech
- Training Details
- 오픈소스 소프트웨어로 텍스트를 International Phonetic Alphabet (IPA) phoneme 시퀀스로 변환
- mel-spectrogram 추출에는 Glow-TTS와 같은 hyperparameter 사용
- 모든 모듈은 Adam optimizer (learning rate 0.0001)로 학습
- beta schedule: $\beta_0 = 0.05, \beta_1 = 20$
1. Model Comparison
저자들은 Amazon Mechanical Turk를 사용하여 LJSpeech에서 5-scale mean opinion score (MOS)를 측정하였다. 생성된 샘플이 텍스트를 잘 반영하는 지 확인하기 위해 Character Error Rate (CER)을 사용한다. MOS와 CER 모두 50개의 샘플을 랜덤하게 선택하여 평가하였다.
다음은 다양한 TTS 모델과 MOS, CES를 비교한 것이다. “GT MEL”은 ground-truth mel-spectogram을 HiFi-GAN으로 복원한 것을 의미한다.
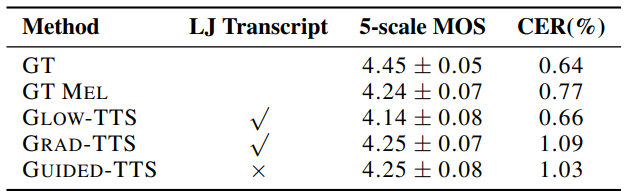
Guided-TTS가 LJSpeech의 전사 없이 고품질의 음성을 합성할 수 있음을 확인할 수 있다.
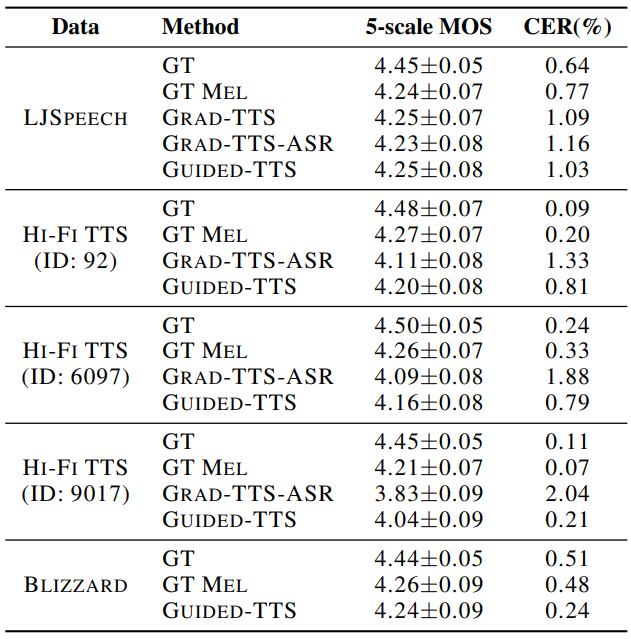
2. Generalization to Diverse Datasets
저자들은 전사가 되지 않은 음성만 있는 상황에서의 음성 생성과 일반화 능력을 평가하고자 하였다. 기존의 TTS 모델이 학습을 위해 전사 데이터가 불가피하게 필요하므로 사전 학습된 ASR 모델로 전사를 추출하여 입력으로 주었다.
다음은 다양한 데이터셋에 대한 5-scale MOS이다.
3. Analysis
Norm-based Guidance
저자들은 기존의 classifier guidance와 본 논문에서 제안한 norm-based classifier guidance를 비교하여 실험하였으며, 그 결과는 다음 그래프와 같다.
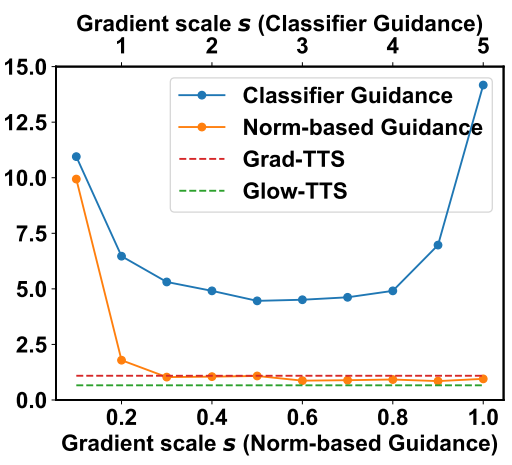
기존 guidance를 사용하여 생성한 샘플은 기존 TTS 모델보다 CER이 나빴으며, 이는 TTS에 적합하지 않음을 의미한다. 반면 본 논문의 guidance는 기존 TTS 모델과 비슷하게 주어진 텍스트 문장에 대하여 샘플을 정확하게 생성한다. Gradient scale이 너무 작으면 classifier guidance의 효과가 거의 없으며 주어진 텍스트를 반영하지 못한다. 반면 gradient scale이 너무 크면 샘플의 품질이 악화된다.
Amount of Data for Phoneme Classifier
다음은 phoneme classifier를 학습하는 데 사용되는 LibriSpeech 데이터의 양에 따른 CER을 나타낸 표와 classification 정확도를 나타낸 그래프이다.

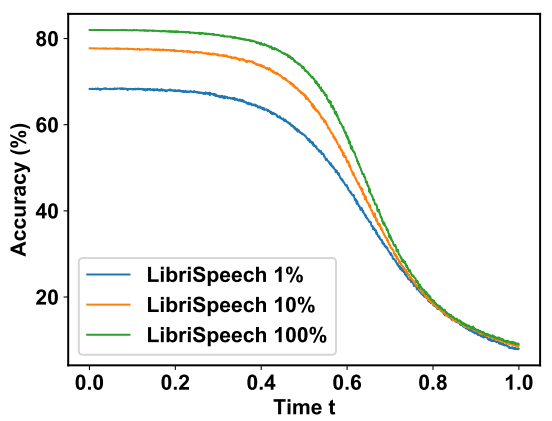
Phoneme classification을 위한 데이터의 양이 증가할수록 Guided-TTS의 발음이 개선되는 것을 확인할 수 있다. 따라서 더 큰 규모의 ASR 데이터셋을 사용하여 학습하면 Guided-TTS의 성능을 더 개선할 수 있다.