[논문리뷰] Any-speaker Adaptive Text-To-Speech Synthesis with Diffusion Models (Grad-StyleSpeech)
arXiv 2022. [Paper] [Page]
Minki Kang, Dongchan Min, Sung Ju Hwang
AITRICS | KAIST
17 Nov 2022
Introduction
최근 diffusion model이 TTS 합성 task에 사용되기 시작하였다. Single speaker에 대한 TTS 합성을 넘어 최근 논문들은 multiple speaker의 음성을 합성하는데 있어 괜찮은 품질을 보여주고 있다. 또한 임의의 speaker의 주어진 reference 음성에 대하여 음성을 합성하는 any-speaker adaptive TTS가 다양한 논문에서 주목을 받았다. Any-speaker adaptive TTS는 현실에 광범위하게 적용할 수 있기 때문에 많은 주목을 받고 있으며 Voice Cloning이라고도 불린다.
대부분의 any-speaker adaptive TTS는 target speaker의 샘플 몇 개가 주어졌을 때 굉장히 자연스럽고 target speaker의 목소리와 비슷한 음성을 합성한다. 기존의 몇몇 논문들은 TTS 모델을 fine-tuning하기 위하여 supervised sample이 몇 개 필요하다. Target speaker에 대한 supervised sample이 필요하다는 점은 분명한 약점이며, 많은 계산 비용이 모델의 파라미터를 업데이트하는 데 필요하다.
반면 몇몇 논문들에서는 zero-shot 방법을 사용한다. Zero-shot 방법은 unseen speaker에 대한 supervised sample이나 추가 fine-tuning이 필요하지 않으며, 신경망으로 된 인코더가 임의의 음성을 latent vector로 인코딩한다.
생성 모델링에 대한 capacity 때문에 zero-shot 방법은 unseen speaker에 대하여 낮은 유사성을 보여주며 감정적인 음성과 같은 독특한 스타일을 생성하는 데에 취약하다.
본 논문은 zero-shot any-speaker adaptive TTS 모델인 Grad-StyleSpeech을 제안하며, score-based diffusion model을 사용하여 임의의 target speaker에 대한 몇 초의 reference 음성만으로도 굉장히 자연스럽고 유사한 음성을 생성한다.
저자들은 기존의 diffusion 기반의 접근법과 달리 스타일 기반의 생성 모델을 사용하여 target speaker의 스타일을 고려한다. 특히 입력 phoneme(음소)를 임베딩할 때 target speaker의 스타일을 반영하는 hierarchical transformer encoder를 사용하며, 이를 통해 reverse process가 target speaker와 더 유사한 음성을 생성할 수 있는 사전 noise 분포를 생성한다.
Method
본 논문에서는 기존 논문들처럼 raw waveform이 아닌 mel-spectrogram을 합성한다. Phoneme으로 구성된 텍스트 $x = [x_1, \cdots, x_n]$와 reference 음성 $Y = [y_1, \cdots, y_m] \in \mathcal{R}^{m\times 80}$이 주어질 때, 목적 함수는 ground-truth 음성 $\tilde{Y}$를 생성하도록 한다. 학습 단계에서 $\tilde{Y}$는 $Y$와 동일하지만, inference 단계에서는 동일하지 않다.
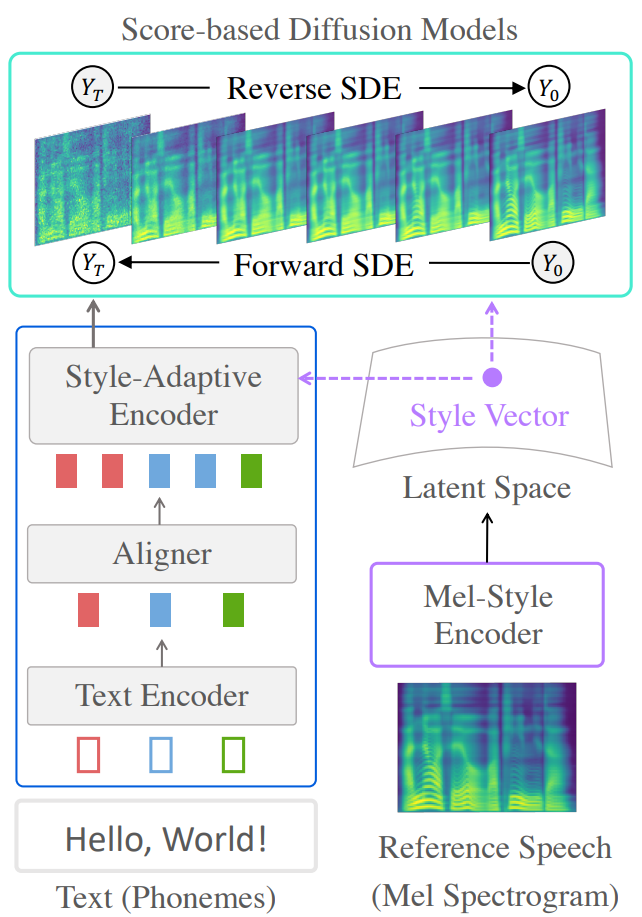
Grad-StyleSpeech는 위 그림과 같이 3가지로 구성된다.
- Reference 음성을 스타일 벡터로 임베딩하는 mel-style encoder
- 텍스트와 스타일 벡터로 컨디셔닝된 중간 표현을 생성하는 hierarchical transformer encoder
- 이 중간 표현들을 denoising step으로 mel-spectrogram에 매핑하는 diffusion model
1. Mel-Style Encoder
Mel-style encoder는 zero-shot any-speaker adaptive TTS의 핵심 구성 요소이다.
스타일 벡터 $s \in \mathcal{R}^{d’}$는 $s = h_\psi (Y)$로 계산하며 $h_\psi$는 파라미터가 $\psi$인 mel-style encoder이다. Mel-style encoder는 공간적 processor와 시간적 processor, multi-head attention으로 구성된 transformer layer로 이루어져 있으며 마지막에 시간에 대한 average pooling이 적용된다.
2. Score-based Diffusion Model
Diffusion model은 가우시안 분포 $\mathcal{N}(0,I)$에서 시작하여 사전 noise 분포로부터 샘플링된 noise를 점진적으로 denoising하여 샘플을 생성한다. 저자들은 Markov chain이 아닌 SDE로 denoising process를 구성한 Grad-TTS의 공식을 대부분 사용하였다.
Forward Diffusion Process
Forward diffusion process는 다음과 같이 forward SDE로 모델링된다.
\[\begin{equation} dY_t = -\frac{1}{2} \beta (t) Y_t dt + \sqrt{\beta (t)} dW_t \end{equation}\]여기서 $t \in [0, T]$는 연속적인 timestep이며 $\beta (t)$는 noise scheduling 함수이고 $W_t$는 standard Wiener process이다.
대신에 Grad-TTS는 데이터 기반의 사전 noise 분포 $\mathcal{N} (\mu, I)$를 사용하며, $\mu$는 신경망으로 계산한 텍스트와 스타일로 컨디셔닝된 표현이다.
\[\begin{equation} dY_t = -\frac{1}{2} \beta (t) (Y_t - \mu) dt + \sqrt{\beta (t)} dW_t \end{equation}\]가우시안 분포인 transition kernel $p_{0t} (Y_t \vert Y_0)$은 다음과 같이 tractable하게 계산할 수 있다.
\[\begin{equation} p_{0t} (Y_t \vert Y_0) = \mathcal{N} (Y_t; \gamma_t, \sigma_t^2), \quad \sigma_t^2 = I - e^{-\int_0^t \beta (s) ds} \\ \gamma_t = (I - e^{-\frac{1}{2} \int_0^t \beta (s) ds}) \mu + e^{-\frac{1}{2} \int_0^t \beta (s) ds} Y_0 \end{equation}\]Reverse Diffusion Process
위 SDE 식에 대한 reverse-time SDE는 다음과 같다.
\[\begin{equation} dY_t = \bigg[ -\frac{1}{2} \beta (t) (Y_t - \mu) - \beta (t) \nabla_{Y_t} \log p_t (Y_t) \bigg] dt + \sqrt{\beta (t)} d \tilde{W}_t \end{equation}\]여기서 $\tilde{W}_t$는 reverse Wiener process이고 \(\nabla_{Y_t} \log p_t (Y_t)\)는 데이터 분포 $p_t (Y_t)$에 대한 score 함수이다.
Numerical SDE solver로 reverse SDE를 풀면 noise $Y_T$에서 $Y_0$를 샘플링할 수 있다. Reverse process 중에 정확한 score를 얻을 수 없기 때문에 신경망 $\epsilon_\theta (Y_t, t, \mu, s)$로 score를 추정한다.
3. Hierarchical Transformer Encoder
경험적으로 $\mu$를 결합하는 것이 diffusion model을 사용하는 multi-speaker TTS에서 중요하다. 따라서 저자들은 인코더를 3개의 계층으로 나눈다.
먼저, 텍스트 인코더 $f_\lambda$는 여러 transformer block으로 입력 텍스트를 phoneme 시퀀스의 컨텍스트 표현으로 매핑한다.
\[\begin{equation} H = f_\lambda (x) \in \mathcal{R}^{n \times d} \end{equation}\]그런 다음 unsupervised alignment learning framework로 입력 텍스트 $x$와 target 음성 $Y$ 사이의 alignment를 계산하고 표현의 길이를 정규화한다.
\[\begin{equation} \textrm{Align} (H, x, Y) = \tilde{H} \in \mathcal{R}^{m \times d} \end{equation}\]마지막으로 style-adaptive transformer block의 stack으로 임베딩 시퀀스 $\mu$를 인코딩한다.
\[\begin{equation} \mu = g_\phi (\tilde{H}, s) \end{equation}\]여기서 $s$는 mel-style encoder로 매핑한 스타일 벡터이며, Style-Adaptive Layer Normalization (SALN)을 사용하여 스타일 정보를 transformer block에 컨디셔닝한다.
결과적으로 hierarchical transformer encoder는 입력 텍스트 $x$와 스타일 벡터 $s$로부터 언어적 내용을 반영하는 $\mu$를 출력한다. 이 $\mu$는 denoising diffusion model에 사용된다. 또한 Grad-TTS와 같이 prior loss $\mathcal{L}_{prior} = \vert\vert\mu - Y\vert\vert_2^2$를 사용한다.
4. Training
Score 추정 신경망 $\epsilon_\theta$를 학습시키기 위하여 tractable한 transition kernel에 대한 marginalization로 기대치를 다음과 같이 계산한다.
\[\begin{equation} \mathcal{L}_{diff} = \mathbb{E}_{t \sim \mathcal{U} (0,T)} \mathbb{E}_{Y_0 \sim p_0 (X_0)} \mathbb{E}_{Y_t \sim p_{0t} (Y_t \vert Y_0)} \| \epsilon_\theta (Y_t, t, \mu, s) - \nabla_{Y_t} \log p_{0t} (Y_t \vert Y_0) \|_2^2 \end{equation}\]$p_{0t} (Y_t \vert Y_0)$가 가우시안 분포이므로 정확한 score 계산이 다음과 같이 tractable하다.
\[\begin{equation} \mathcal{L}_{diff} = \mathbb{E}_{t \sim \mathcal{U} (0,T)} \mathbb{E}_{Y_0 \sim p_0 (X_0)} \mathbb{E}_{\epsilon \sim \mathcal{N} (0, I)} \| \epsilon_\theta (Y_t, t, \mu, s) - \sigma_t^{-1} \epsilon \|_2^2 \\ (\sigma_t = \sqrt{1 - e^{-\int_0^t \beta (s) ds}}) \end{equation}\]위의 loss들을 aligner 학습을 위한 aligner loss $\mathcal{L}_{align}$와 결합하면 최종 목적 함수는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_{diff} + \mathcal{L}_{prior} + \mathcal{L}_{align} \end{equation}\]Experiment
- 데이터셋
- LibriTTS (multi-speaker English, 1142명, 110시간): clean-100과 clean-360을 학습에, test-clean을 평가에 사용
- VCTK (110명)으로 unseen speaker에 대한 평가 진행
- Implementation Details
- Text encoder와 style-adaptive encoder에 각각 4개의 transformer block 사용
- Style-adaptive encoder와 mel-style encoder는 Meta-StyleSpeech와 동일한 SALN을 사용하는 아키텍처 사용
- Aligner: 원본 논문과 동일한 아키텍처와 loss 함수 사용
- $\epsilon_\theta$: Grad-TTS와 동일한 아키텍처 사용
- Maximum Likelihood SDE solver로 빠른 샘플링, denoising step은 100
- TITAN RTX GPU, 배치 사이즈 8, 100만 step, Adam optimizer
- Learning rate는 Meta-StyleSpeech와 동일
- 평가 지표
- 객관적 평가 지표: YourTTS에서 사용한 Speaker Embedding Cosine Similarity (SECS)와 Character Error Rate (CER)
- 주관적 평가 지표: 16명의 사람이 평가한 Mean Opinion Score (MOS)와 Similarity MOS (SMOS)
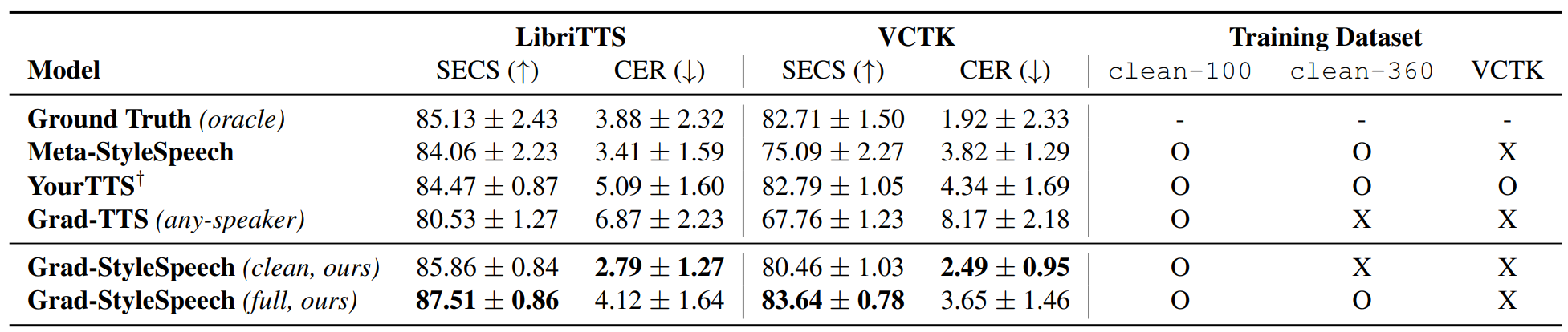
다음은 zero-shot 적용이 잘 되는지에 대한 객관적 평가 지표로, fine-tuning을 하지 않았을 때의 결과이다.
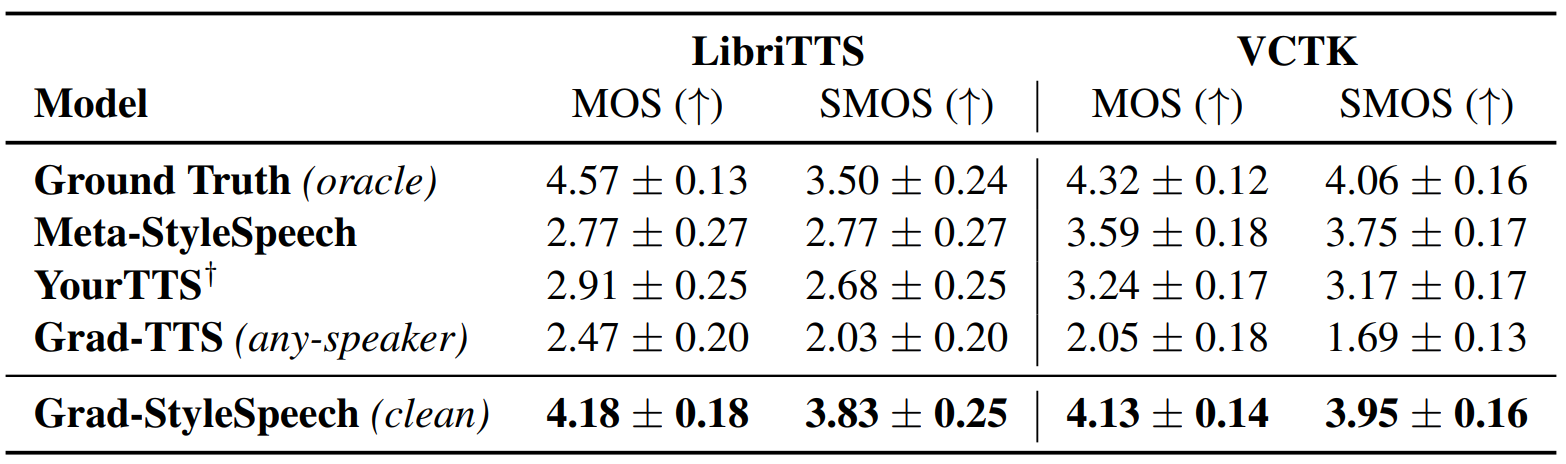
다음은 zero-shot 적용이 잘 되는지에 대한 주관적 평가 지표로, fine-tuning을 하지 않았을 때의 결과이다.
다음은 본 논문의 모델로 합성한 mel-spectrogram을 시각화한 것이다.
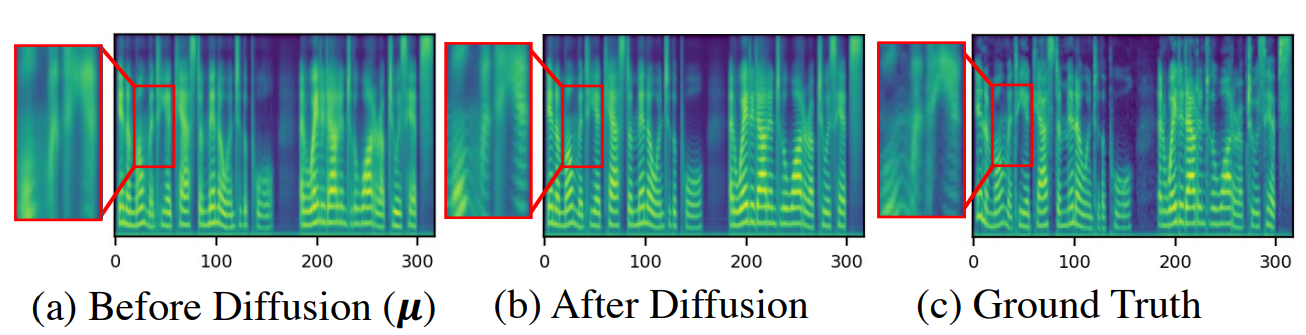
Diffusion model이 고주파수 요소를 자세하게 모델링하여 기존 연구에서 존재하는 over-smoothness 문제를 극복하도록 도와주는 것을 알 수 있다.
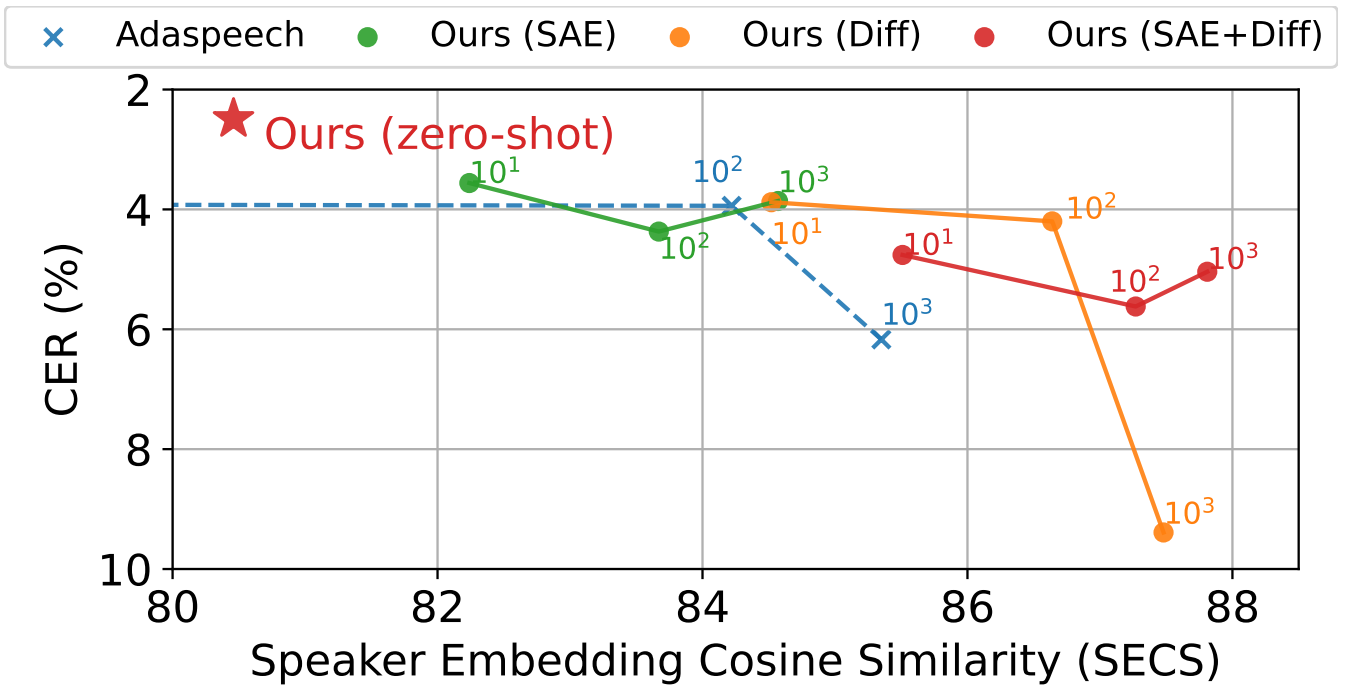
다음은 VCTK 데이터셋에서 fine-tuning을 진행한 step에 따라 나타낸 SECS와 CER이다. 각 unseen speaker마다 20개의 음성으로 fine-tuning하였다. SAE와 Diff는 각각 Style-Adaptive Encoder와 Diffusion model의 파라미터를 fine-tune한 것을 의미한다.