[논문리뷰] GSLoc: Efficient Camera Pose Refinement via 3D Gaussian Splatting
ICLR 2025. [Paper] [Page]
Changkun Liu, Shuai Chen, Yash Bhalgat, Siyan Hu, Zirui Wang, Ming Cheng, Victor Adrian Prisacariu, Tristan Braud
HKUST | University of Oxford | Tristan Braud
20 Aug 2024
Introduction
Pose estimation 방법의 초기 포즈 추정의 정확도를 높이기 위한 pose refinement 방법에 대한 관심이 커지고 있다. 최근 방법들은 NeRF를 활용했지만 정확도 개선의 한계가 있고 NeRF 렌더링의 계산 요구량과 pose estimation 모델을 통한 역전파로 인해 수렴이 느리다.
본 논문은 이러한 한계점을 해결하기 위해 GSLoc라고 하는 새로운 test-time pose refinement 프레임워크를 제안하였다. GSLoc은 장면 표현으로 3D Gaussian Splatting (3DGS)을 활용하고, 3DGS의 고품질 및 빠른 렌더링 능력을 활용하여 합성 이미지와 depth map을 생성하여 쿼리 이미지와 기본 pose estimator의 초기 포즈 추정치와의 2D-3D correspondence를 효율적으로 구축한다. 쿼리 이미지와 렌더링된 이미지 간의 domain shift에 대한 robustness를 개선하기 위해 3DGS 모델에 노출 적응 모듈을 통합한다. 또한, GSLoc은 정확한 2D 매칭을 위해 3D vision foundation model MASt3R을 활용하기 때문에 장면별로 feature extractor나 descriptor를 학습시킬 필요가 없다.
GSLoc은 여러 벤치마크에서 APR (absolute pose regression)이나 SCR (scene coordinate regression) 방법으로 추정한 포즈의 정확도를 모두 크게 향상시켜 두 실내 데이터셋에서 SOTA 정확도를 달성하였다. ACE와 같은 SCR 방법을 개선하지 못하는 이전의 NeRF 기반 방법과 달리, GSLoc은 상당한 개선을 제공하고 주요 NeRF 기반 방법보다 성능이 뛰어나다.
Method
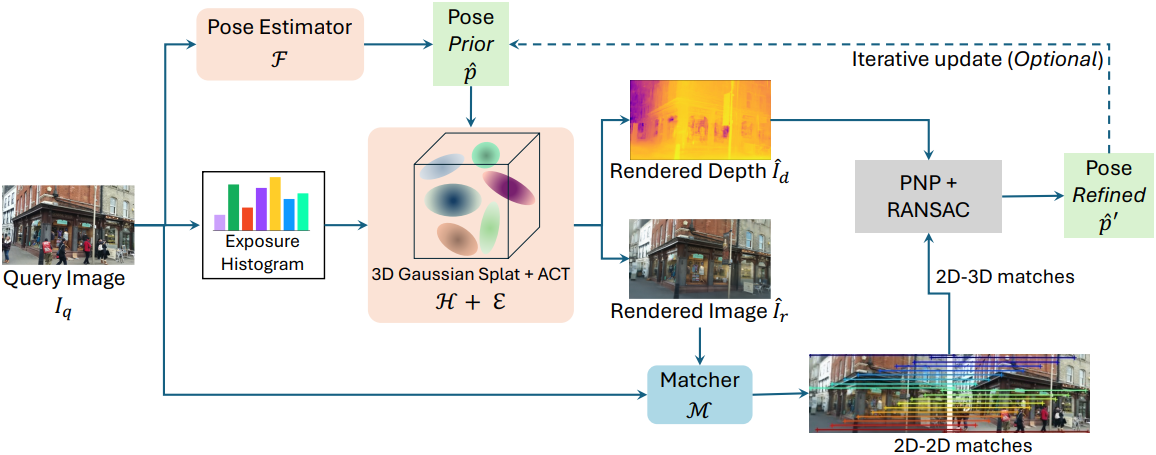
GSLoc은 test-time pose refinement 프레임워크이다. 사전 학습된 pose estimator와 장면의 3DGS 모델을 사용할 수 있다고 가정한다. 쿼리 이미지의 경우, 먼저 pose estimator에서 초기 추정 포즈를 얻는다. 본 논문의 목표는 정제된 포즈를 출력하는 것이다.
카메라 intrinsic이 $K \in \mathbb{R}^{3 \times 3}$인 쿼리 이미지 $I_q \in \mathbb{R}^{H \times W \times 3}$이 주어졌을 때, 전체 프로세스는 다음과 같다.
- Pose estimator $\mathcal{F}$ (일반적으로 APR 또는 SCR 모델)로 $I_q$에 대한 초기 6-DOF 포즈 \(\hat{p} = [\hat{\mathbf{R}} \vert \hat{\mathbf{t}}]\)를 예측한다.
- \(\hat{p}\)에 대해 사전 학습된 3DGS 모델 $\mathcal{H}$가 이미지 \(\hat{I}_r \in \mathbb{R}^{H \times W \times 3}\)과 depth map \(\hat{I}_d \in \mathbb{R}^{H \times W \times 1}\)을 렌더링한다. 이 렌더링 프로세스 중에 노출 적응형 affine color transformation (ACT) 모듈 $\mathcal{E}$를 사용하여 까다로운 야외 환경에 대한 모델의 robustness를 향상시킨다.
- Matcher $\mathcal{M}$이 $I_q$와 \(\hat{I}_r\) 사이의 dense한 2D-2D correspondence를 구축한다.
- $I_q$와 \(\hat{I}_d\)를 기반으로 2D-3D correspondence를 구축한다.
- 2D-3D correspondence에서 정제된 포즈 \(\hat{p}^\prime\)를 얻는다.
1. 3DGS Test-time Exposure Adaptation
3DGS는 고품질의 새로운 뷰 렌더링이 가능하지만 상당한 왜곡이 없는 학습 및 테스트를 가정한다. 매핑 및 쿼리 시퀀스는 시간, 날씨, 노출의 변화에 영향을 받는다. 이로 인해 3DGS 렌더링과 쿼리 이미지 사이에 상당한 외형 차이가 발생하여 2D-2D 매칭 성능에 부정적인 영향을 미친다.
이 문제를 해결하기 위해, 저자들은 3DGS에 노출 적응형 affine color transformation (ACT) 모듈 $\mathcal{E}$를 적용하여 3DGS가 테스트 중에 외형을 적응적으로 렌더링하고 $I_q$의 노출을 정확하게 반영할 수 있도록 한다. 구체적으로, 쿼리 이미지의 휘도(luminance) 히스토그램을 입력으로 받고 3차원 bias 벡터 $\mathbf{b}$와 함께 3$\times$3 행렬 $\mathbf{Q}$를 생성하는 4-layer MLP를 사용한다. 그런 다음 MLP의 출력은 3DGS의 렌더링된 픽셀에 직접 적용되어 쿼리 이미지의 노출과 더 가깝게 일치한다.
\[\begin{equation} \hat{\mathbf{C}} (\mathbf{r}) = \mathbf{Q} \hat{\mathbf{C}}_\textrm{rend} (\mathbf{r}) + \mathbf{b} \end{equation}\](\(\hat{\mathbf{C}} (\mathbf{r})\)은 최종 색상, \(\hat{\mathbf{C}}_\textrm{rend} (\mathbf{r})\)는 3DGS 모델 $\mathcal{H}$에서 얻은 렌더링된 색상)
2. Pose Refinement with 2D-3D Correspondences
GSLoc는 쿼리 이미지 $I_q$와 장면 표현 사이의 2D-3D correspondence를 설정하여 카메라 포즈를 추정한다.
1. 2D-2D 매칭
먼저, 초기 추정 시점 \(\hat{p}\)에서 이미지 \(\hat{I}_r\)이 렌더링된다. 그런 다음 matcher $\mathcal{M}$을 사용하여 쿼리 이미지 $I_q$와 렌더링된 이미지 \(\hat{I}_r\) 사이의 2D-2D 픽셀 correspondence $C_{q,r}$을 구축한다. $\mathcal{M}$은 3D vision foundation model인 MASt3R이다. MASt3R은 합성 데이터와 실제 데이터 모두에서 학습되었으므로 시뮬레이션-실제 도메인 차이가 있는 이미지 쌍에서 2D-2D 매칭에 대한 강력한 robustness를 보여준다.
2. 3D 좌표 맵 생성
동시에, 학습된 3DGS 모델 $\mathcal{H}$를 사용하여 $\hat{p}$에서 depth map \(\hat{I}_d\)를 렌더링한다. 3DGS의 rasterization 엔진을 수정하여 다음과 같이 depth map을 렌더링한다.
\[\begin{equation} \hat{I}_d = \sum_{i \in N} d_i \alpha_i \prod_{j=1}^{i-1} (1 - \alpha_j) \end{equation}\]($d_i$는 viewspace에서 z-depth, $\alpha_i$는 projection된 2D 공분산에 곱해진 학습된 불투명도)
렌더링된 depth map \(\hat{I}_d\), 카메라 intrinsic $K$, 포즈 $\hat{p}$를 사용하여 렌더링된 이미지 \(\hat{I}_r\)에 대한 3D 좌표 맵 $X_r^d \in \mathbb{R}^{H \times W \times 3}$를 얻는다.
3. 2D-3D correspondences 구축
2D-2D correspondence $C_{q,r}$을 3D 좌표 맵 $X_r^d$과 결합함으로써 $I_q$와 장면 간의 2D-3D correspondence를 구축한다. $I_q$의 각 매칭된 픽셀에 대해 $X_r^d$에서 3D 좌표를 얻는다.
4. Pose Refinement
이러한 2D-3D correspondence를 RANSAC 루프가 있는 PnP solver에 공급하여 정제된 포즈 \(\hat{p}^\prime\)을 얻는다. 이 프로세스는 pose estimator $\mathcal{F}$ 또는 3DGS 모델 $\mathcal{H}$를 통한 역전파를 필요로 하지 않으므로 효율적인 계산을 보장하고 모든 pose estimator에서 사용할 수 있다.
PnP + RANSAC과 결합된 2D-3D correspondence의 사용은 2D-2D 매칭에만 의존하는 방법보다 더 신뢰할 수 있는 포즈를 제공한다. 또한, 이전 방법들과 달리 robustness를 위한 특수 feature descriptor를 학습시킬 필요가 없다.
초기 포즈 $\hat{p}$가 덜 정확한 경우, 선택적으로 최적화된 포즈 $\hat{p}^\prime$을 초기 포즈로 사용하고 위의 프로세스를 반복하여 정확도를 더욱 향상시킬 수 있다.
3. Faster Alternative with Relative Post Estimation
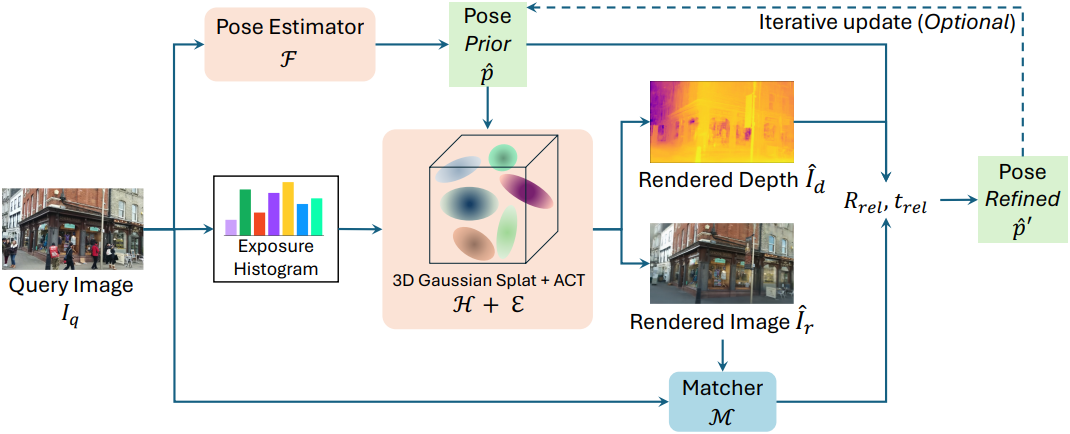
저자들은 계산 효율성을 우선시 하는 GSLocrel을 추가로 제안하였다. GSLocrel은 MASt3R의 point map registration 기능을 활용하여 relative pose를 추정한다.
MASt3R은 쿼리 이미지 $I_q$와 렌더링된 이미지 \(\hat{I}_r\)에 대한 포인트 맵 \(\mathbf{P}_q\)와 \(\mathbf{P}_r\)을 생성하고 두 이미지 간의 relative rotation \(\mathbf{R}_\textrm{rel}\)과 relative translation \(\mathbf{t}_\textrm{rel}\)을 예측한다. 그러나 MASt3R에서 예측한 이 relative pose는 장면의 스케일에 맞춰야 한다. 포인트 맵 $P_r$을 depth map \(\hat{I}_d\)와 맞춰 스케일 $s$를 복구한다. 최종적으로 정제된 포즈 \(\hat{p}^\prime\)은 다음과 같이 계산된다.
\[\begin{equation} \hat{p}^\prime = [\hat{\mathbf{R}}^\prime \vert \hat{\mathbf{t}}^\prime] = [\mathbf{R}_\textrm{rel} \hat{\mathbf{R}} \vert \hat{\mathbf{t}} + s \mathbf{R}_\textrm{rel} \mathbf{t}_\textrm{rel}] \end{equation}\]GSLocrel은 속도와 정확도 간의 trade-off를 제공하므로 더 빠른 처리가 필요한 시나리오에 적합하다.
Experiments
- 데이터셋: 7Scenes, 12Scenes, Cambridge Landmarks
- 구현 디테일
- Scaffold-GS를 3DGS 표현으로 사용
- ACT 모듈은 NeFeS를 따름
- 동적 장면의 경우 Mask2Former로 움직이는 물체를 필터링
- GPU: NVIDIA A6000 1개
1. Localization Accuracy
다음은 세 벤치마크에서 pose estimator의 포즈와 GSLoc으로 개선된 포즈를 비교한 것이다. (왼쪽 아래가 추정된 포즈, 오른쪽 위가 GT)

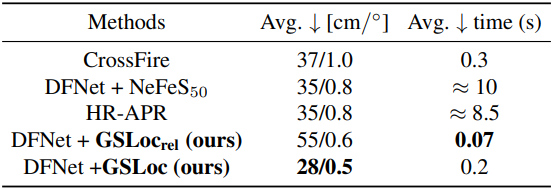
다음은 DFNet으로 추정한 포즈를 NeFeS로 50번 정제한 결과와 GSLoc으로 2번 정제한 결과를 비교한 것이다.

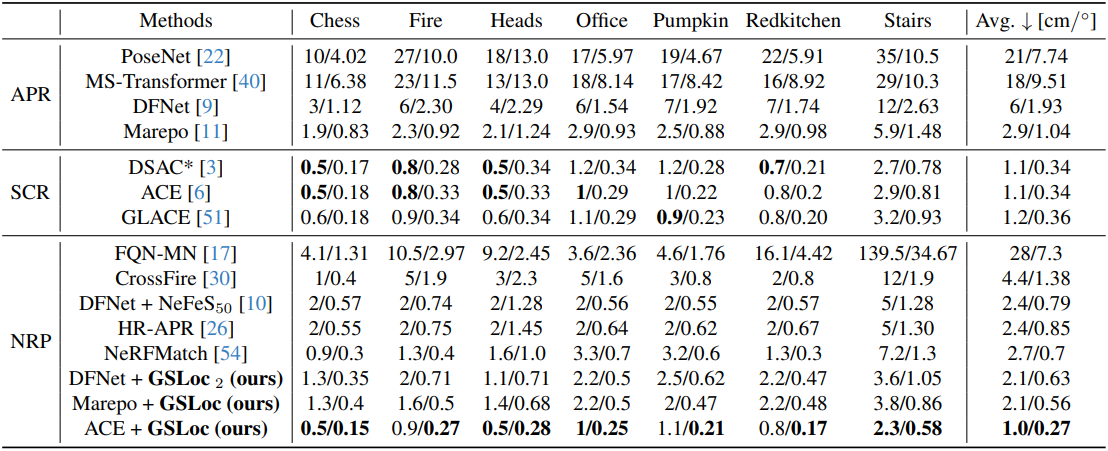
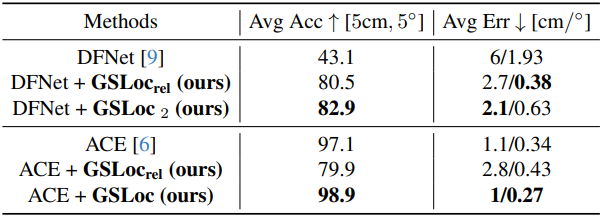
다음은 7Scenes 데이터셋에서 평균 translation 및 rotation 오차를 비교한 표이다. (GSLoc2는 GSLoc을 2번 사용)
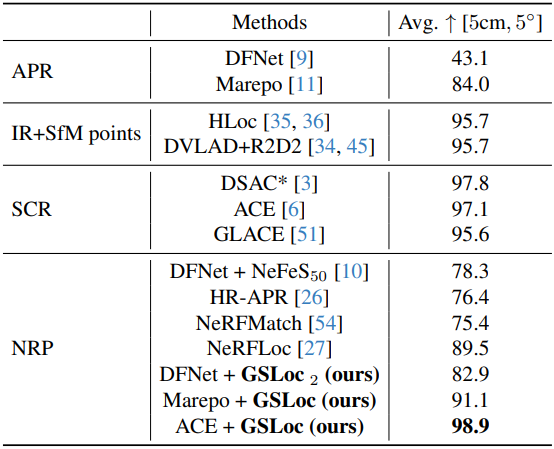
다음은 7Scenes 데이터셋에서 포즈 오차가 5cm, 5° 미만인 프레임 비율(%)을 비교한 표이다.
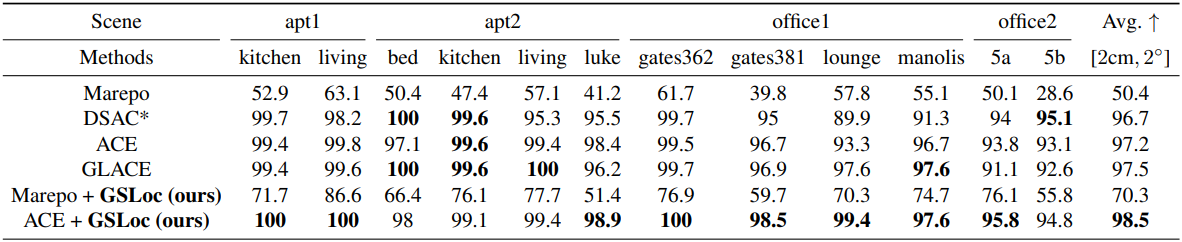
다음은 12Scenes 데이터셋에서 포즈 오차가 2cm, 2° 미만인 프레임 비율(%)을 비교한 표이다.
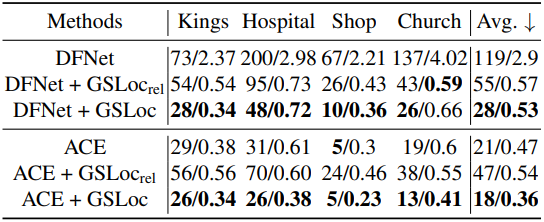
다음은 Cambridge Landmarks 데이터셋에서 평균 translation 및 rotation 오차를 비교한 표이다.

다음은 (왼쪽) Cambridge Landmarks와 (오른쪽) 7Scenes에서 GSLoc과 GSLocrel을 비교한 표이다.
2. Runtime Analysis
다음은 실행 시간을 비교한 표이다. (Cambridge Landmarks)
3. Ablation study
다음은 matcher에 대한 ablation 결과이다. (7Scenes)
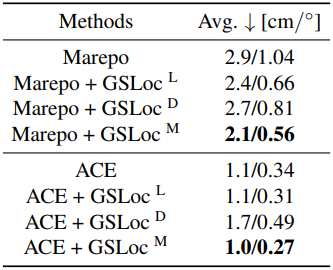
다음은 ACT 모듈에 대한 ablation 결과이다. (Cambridge Landmarks)

다음은 ACT 모듈의 유무에 따른 Scaffold-GS의 렌더링 결과를 비교한 것이다.
