[논문리뷰] GS2Mesh: Surface Reconstruction from Gaussian Splatting via Novel Stereo Views
ECCV 2024. [Paper] [Page]
Yaniv Wolf, Amit Bracha, Ron Kimmel
Technion
18 Jul 2024

Introduction
3D Gaussian Splatting (3DGS)은 최근 novel view synthesis 분야에서 상당한 도약을 이루었으며, 속도와 정확도 면에서 이전의 뉴럴 렌더링 방법을 능가했다. 그러나 3DGS에서 표면을 직접 재구성하는 데는 상당한 어려움이 따른다. 가장 큰 문제는 3D 공간에서 Gaussian들의 위치가 기하학적으로 일관된 표면을 형성하지 않는다는 것이다. 이는 Gaussian들이 이미지 평면으로 다시 projection될 때 입력 이미지와 가장 잘 일치하도록 최적화되어 있기 때문이다. 결과적으로 Gaussian 중심을 기준으로 표면을 재구성하면 잡음이 많고 부정확한 결과가 생성된다. 현재의 SOTA 방법에서는 추가적인 기하학적 제약 조건을 추가하고, Gaussian을 flattening하거나, opacity field를 사용하여 형상을 추출하는 등의 방법으로 3DGS 최적화 프로세스를 정규화하려고 시도하지만, 여전히 Gaussian 위치에 의존하고 잡음이 많고 비현실적인 표면을 형성한다.
본 논문은 잡음이 있는 Gaussian의 위치에 의존하지 않는 최적화된 Gaussian 포인트 클라우드에서 깊이를 추출하기 위한 새로운 접근 방식인 GS2Mesh를 제안하였다. GS2Mesh는 실제 데이터로 학습된 강력한 geometric regularizer, 즉 사전 학습된 스테레오 매칭 모델을 활용한다. 스테레오 매칭 모델은 정확한 깊이를 추출할 수 있는 스테레오 이미지 쌍에 대한 correspondence 문제를 해결한다. 3DGS 렌더링을 통해 원래 뷰에 해당하는 스테레오 이미지 쌍을 인위적으로 생성하고, 이러한 쌍을 사전 학습된 스테레오 모델에 공급하고, TSDF 알고리즘을 사용하여 결과 깊이를 융합한다. 그 결과, 기하학적으로 일관된 표면이 생성된다.
제안된 방법은 표면 재구성 시간을 극적으로 줄여 3DGS가 장면을 캡처하는 것 위에 작은 오버헤드만 차지하는데, 이는 다른 표면 재구성 방법에 비해 상당히 빠르다. 예를 들어, 스마트폰 카메라로 촬영한 장면을 재구성하는 데는 5분 미만의 추가 계산 시간이 필요하다. 또한 3DGS 캡처를 기반으로 표면을 재구성하기 때문에 Gaussian의 메쉬 기반 조작을 위해 메쉬를 원본 모델에 바인딩하는 것이 간단하다. 게다가 GS2Mesh의 메시는 더 정확하기 때문에 추가적인 정제가 필요하지 않다.
Method
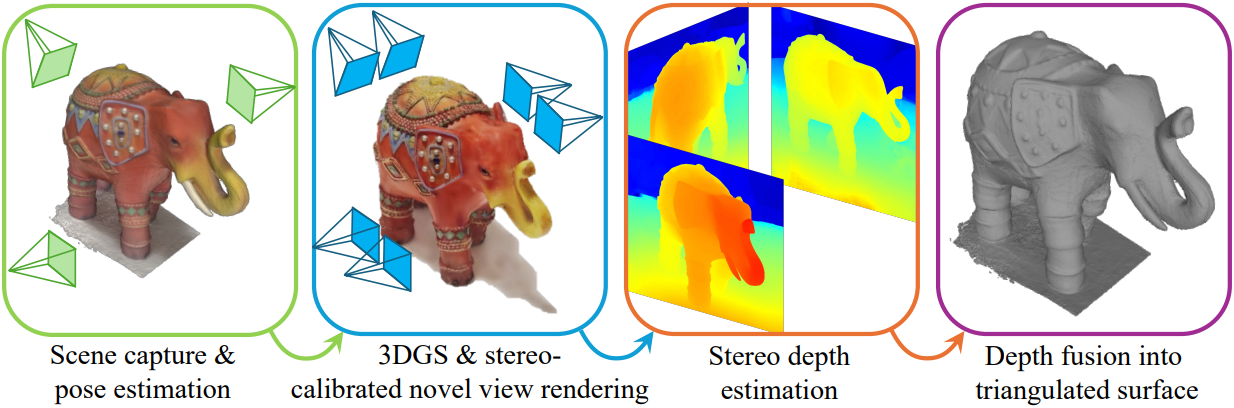
1. Stereo-Aligned Novel View Rendering
3DGS 프로세스 동안 Gaussian은 주어진 소스 이미지와 렌더링된 이미지 간의 photometric loss에 따라 최적화된다. 이를 통해 원래의 학습 데이터에 없었던 새로운 뷰를 렌더링할 수 있는 장면 표현이 생성된다. 3DGS는 충분한 학습 이미지가 없는 영역에서는 아티팩트가 나타날 수 있다. 또한 3DGS는 학습 이미지를 기반으로 최적화되므로 학습 이미지에 가까울수록 렌더링이 더 깔끔해진다.
따라서 장면의 새로운 스테레오 뷰를 생성할 때 관심 영역을 포함하는 충분한 양의 이미지를 입력한다. 또한 스테레오 쌍의 왼쪽 이미지를 학습 이미지와 동일한 포즈 $R_L$, $T_L$에 두어 원래 학습 포즈에 최대한 가깝게 유지한다. 이 선택에 따라 수평 baseline $b$만큼 떨어진 오른쪽 포즈는 다음과 같다.
\[\begin{equation} R_R = R_L, \quad T_R = T_L + (R_L \times [b, 0, 0]) \end{equation}\]2. Stereo Depth Estimation
렌더링된 스테레오 이미지 쌍을 사용하면 3DGS의 novel view synthesis 능력을 사용하여 하나의 카메라에서 촬영한 장면을 스테레오 카메라 쌍에서 촬영한 장면으로 바꿀 수 있다. 그런 다음 스테레오 매칭 알고리즘을 적용하여 모든 스테레오 쌍에서 깊이를 계산한다. 사전 학습된 Middlebury 가중치를 사용한 DLNR을 스테레오 매칭 모델로 사용한다. 재구성을 더욱 향상시키기 위해 스테레오 모델의 출력에 여러 마스크를 적용한다.
첫 번째 마스크는 occlusion mask로, 같은 이미지 쌍의 left-to-right disparity와 right-to-left disparity의 차이에 threshold를 적용하여 계산한다. 이를 통해 스테레오 모델의 출력을 신뢰할 수 없는 하나의 카메라에서만 볼 수 있는 영역을 마스킹한다. 마스킹된 영역은 인접한 다른 스테레오 뷰에서 채워진다.
두 번째 마스크는 스테레오 출력의 깊이에 따라 적용된다. 스테레오 매칭 오차 사이의 관계는
\[\begin{equation} \epsilon (Z) \approx \frac{\epsilon (d)}{f_x \cdot B} Z^2 \end{equation}\]로 설명할 수 있다. 여기서 $\epsilon (d)$는 disparity 출력 오차, $Z$는 GT 깊이, $\epsilon (Z)$는 깊이 추정 오차, $f_x$는 카메라의 수평 초점 거리, $B$는 baseline이다.
즉, 멀리 있는 물체의 깊이를 추정하면 깊이의 제곱에 비례하는 오차가 발생한다. 또한, 카메라에서 가까운 거리에 위치한 물체의 두 이미지에서 일치하는 픽셀 간의 disparity는 스테레오 매칭 알고리즘에서 생성된 최대 disparity 한계를 초과할 수 있다. 따라서 카메라에 너무 가까운 물체의 깊이를 추정하면 매칭 알고리즘의 한계로 인해 오차가 발생할 수 있다.
따라서 $4B \le Z \le 20B$ 범위의 깊이를 고려한다. 이는 깊이 추정 프로세스의 전반적인 정확도와 신뢰성을 향상시켜 더 일관된 기하학적 재구성을 보장한다.
위의 고려 사항에 고려하여 스테레오 쌍의 baseline $B$을 설정하면 두 가지 상충되는 요소가 있다.
- $B$가 클수록 신뢰할 수 있는 스테레오 모델의 출력 범위가 더 넓어진다.
- $B$가 작을수록 렌더링의 잡음이 적어지고 원래의 학습 이미지에서 덜 벗어난다.
저자들이 다양한 baseline을 테스트한 결과, 장면 반경의 7%의 baseline이 최상의 결과를 제공한다는 것을 발견했다.
3. Depth Fusion into Triangulated Surface
기하학적 일관성을 더욱 향상시키고 개별 깊이에서 발생할 수 있는 잡음과 오차를 부드럽게 하기 위해 TSDF 알고리즘을 사용하여 추출된 모든 깊이를 집계한 다음 Marching-Cubes 알고리즘으로 메쉬를 생성한다.
Experiments
- 데이터셋: DTU, Tanks and Temples, Mip-NeRF360, MobileBrick
1. Results
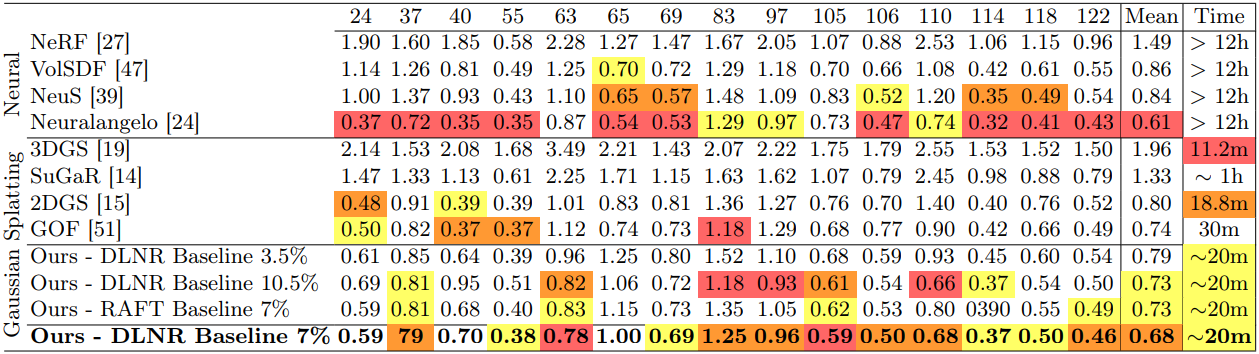
다음은 DTU 데이터셋에서 SOTA 방법들과 Chamfer distance를 비교한 표이다.
다음은 Tanks and Temples 데이터셋에서 (위) SuGaR와 비교한 결과와 (아래) SOTA 방법들과 F1 score를 비교한 표이다.


다음은 Mip-NeRF360 데이터셋에서 BakedSDF, SuGaR와 비교한 결과이다.

다음은 일반 동영상들에서 SuGaR와 비교한 결과이다.

2. Ablation Study
다음은 MobileBrick 데이터셋에서 두 가지 유형의 입력, 즉 원본 이미지와 렌더링된 이미지를 사용한 MVSFormer와 GS2Mesh를 비교한 결과이다. 왼쪽부터 GT, 원본 이미지를 사용한 MVSFormer, 렌더링된 이미지를 사용한 MVSFormer, GS2Mesh이다.


Limitations

- (왼쪽) 스테레오 매칭 모델은 투명한 표면에서 어려움을 겪는다.
- (오른쪽) 원래 학습 이미지에서 충분히 다루어지지 않은 영역에서 floater를 생성한다.
- TSDF 퓨전은 큰 장면에 맞게 확장되지 않는다.