[논문리뷰] GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
ECCV 2024. [Paper] [Page]
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, Zexiang Xu
Adobe Research | Cornell University
30 Apr 2024

Introduction
전통적인 3D 재구성에는 dense한 멀티뷰 이미지 세트가 필요하였다. 최근에는 transformer 기반 3D large reconstruction models (LRM)이 제안되어 방대한 3D object 컬렉션에서 일반적인 3D 재구성을 학습하고 전례 없는 품질의 sparse-view 3D 재구성을 달성했다. 그러나 이러한 모델들은 장면 표현으로 triplane NeRF를 채택하는데, 이는 제한된 triplane 해상도와 계산량이 많은 볼륨 렌더링으로 인해 어려움을 겪는다. 이로 인해 학습 및 렌더링 속도 느리며, 세밀한 디테일이 유지되지 않고, 대규모 장면으로 확장하는 데 어려움을 겪게 된다.
본 논문의 목표는 일반적이고 확장 가능하며 효율적인 3D 재구성 모델을 구축하는 것이다. 이를 위해 sparse한 입력 이미지에서 3D Gaussian들을 예측하여 빠르고 고품질의 렌더링 및 재구성을 가능하게 하는 새로운 transformer 기반 LRM인 GS-LRM을 제안하였다.
GS-LRM의 핵심은 픽셀별로 Gaussian을 예측하는 간단하고 확장 가능한 transformer 기반 네트워크 아키텍처이다. 포즈를 아는 입력 이미지를 패치 토큰으로 patchify하고 이를 self-attention layer와 MLP layer로 구성된 일련의 transformer block을 통해 처리하고 상황에 맞는 멀티뷰 토큰에서 뷰별 픽셀별 3D Gaussian들을 직접 회귀한다. 이전 LRM들과 달리 입력 2D 이미지와 출력 3D Gaussian을 동일한 픽셀 공간에 정렬하여 광선을 따라 픽셀당 하나의 Gaussian을 예측한다. 이러한 정렬은 transformer 아키텍처를 단순화할 뿐만 아니라 3D Gaussian이 입력 이미지의 고주파 디테일을 보존하는 것을 용이하게 한다. 또한 픽셀별 Gaussian을 예측하면 모델이 입력 이미지 해상도에 자유롭게 적응하여 고해상도 입력에서 정확한 장면 디테일을 표시할 수 있다.
Transformer 기반 GS-LRM은 모델 크기, 학습 데이터, 장면 규모 등 여러 측면에서 확장성이 뛰어나다. 저자들은 도메인별 파라미터 변경을 최소화하면서 동일한 transformer 아키텍처를 사용하여 개체 및 장면 재구성 작업을 위해 두 개의 대규모 데이터셋 Objaverse와 RealEstate10K에서 두 가지 버전의 GS-LRM을 학습시켰다. GS-LRM은 object-level 재구성과 scene-level 재구성 모두에 대해 고품질의 sparse-view 재구성을 달성하였다. 또한 SOTA 재구성 품질을 달성하였으며 object-level의 경우 4dB PSNR, scene-level의 경우 2.2dB PSNR의 큰 차이로 이전 방법보다 성능이 뛰어나다.
Method
1. Transformer-based Model Architecture
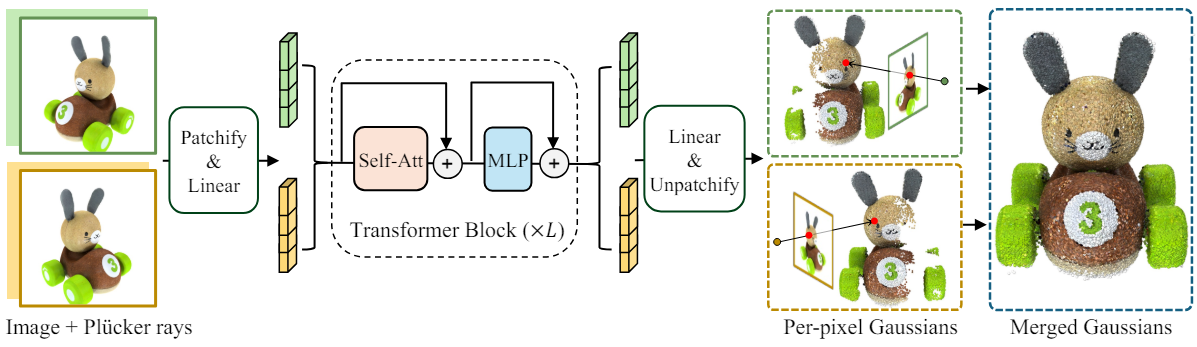
위 그림에서 볼 수 있듯이, 카메라 포즈를 알고 있는 이미지 세트에서 픽셀별 3D Gaussian 파라미터를 회귀하도록 transformer 모델을 학습시킨다. Patchify 연산자를 통해 입력 이미지를 토큰화한다. 그런 다음 멀티뷰 이미지 토큰이 concatenate되어 self-attention layer와 MLP layer로 구성된 일련의 transformer block을 통과한다. 각 출력 토큰에서 linear 레이어를 사용하여 해당 패치의 픽셀 정렬된 Gaussian 속성을 디코딩한다.
이미지 토큰화
모델의 입력은 $N$개의 멀티뷰 이미지 \(\{\mathbf{I}_i \in \mathbb{R}^{H \times W \times 3} \vert 1, \ldots, N\}\)와 카메라의 intrinsic 및 extrinsic 파라미터이다. 포즈 컨디셔닝을 위해 카메라 파라미터로부터 계산된 각 이미지의 Plücker 광선 좌표 \(\{\mathbf{P}_i \in \mathbb{R}^{H \times W \times 6}\}\)를 사용한다. 특히 이미지 RGB와 해당 Plücker 좌표를 channel-wise로 concatenate하여 픽셀별 포즈를 컨디셔닝하고 9개 채널로 뷰별 feature map을 형성한다. ViT와 마찬가지로 뷰별 feature map을 패치 크기가 $p$인 겹치지 않는 패치로 나누어 입력을 patchify한다. 각 2D 패치에 대해 길이가 $9p^2$인 1D 벡터로 flatten한다. 그런 다음 linear layer로 1D 벡터를 $d$ 차원의 이미지 패치 토큰에 매핑한다. 여기서 $d$는 transformer 너비이다.
\[\begin{equation} \{\mathbf{T}_{ij}\}_{j = 1, \ldots, HW/p^2} = \textrm{Linear} (\textrm{Patchify}_p (\textrm{Concat} (\mathbf{I}_i, \mathbf{P_i}))) \end{equation}\]여기서 \(\{\mathbf{T}_{ij} \in \mathbb{R}^d\}\)는 이미지 $i$에 대한 패치 토큰 세트이고, 각 이미지에 대해 이러한 토큰들이 총 $HW / p^2$개가 있다. Plücker 좌표는 픽셀과 뷰에 따라 다양하므로 자연스럽게 서로 다른 패치를 구별하는 공간 임베딩 역할을 한다. 따라서 추가적인 위치 임베딩을 사용하지 않는다.
Transformer로 이미지 토큰 처리
\(\{\mathbf{T}_{ij}\}\)가 주어지면 이를 concatenate하고 transformer block에 공급한다.
\[\begin{aligned} \{\mathbf{T}_{ij}\}^0 &= \{\mathbf{T}_{ij}\} \\ \{\mathbf{T}_{ij}\}^l &= \textrm{TransformerBlock}^l (\{\mathbf{T}_{ij}\}^{l-1}), \quad l = 1, \ldots L \end{aligned}\]$L$은 transformer block의 개수이다. 각 transformer block에는 residual connection이 있으며 Pre-LayerNorm, multi-head Self-Attention, MLP로 구성된다.
출력 토큰을 픽셀별 Gaussian으로 디코딩
출력 토큰 \(\{\mathbf{T}_{ij}\}^L\)을 사용하여 linear layer에 넣어 Gaussian 파라미터로 디코딩한다.
\[\begin{equation} \{\mathbf{G}_{ij} \in \mathbb{R}^{p^2 q}\} = \textrm{Linear} (\{\mathbf{T}_{ij}\}^L) \end{equation}\]$q$ Gaussian당 파라미터 수이다. 그런 다음 \(\mathbf{G}_{ij}\)를 $p^2$개의 Gaussian들로 unpatchify한다. Patchify와 unpatchify 연산에 동일한 패치 크기 $p$를 사용하기 때문에 각 2D 픽셀이 하나의 3D Gaussian에 해당하며, 각 뷰에 대해 $H \times W$개의 Gaussian이 생성된다.
3D Gaussian들은 3채널 RGB, 3채널 scale, 4채널 rotation quaternion, 1채널 불투명도, 1채널 광선 거리로 parameterize된다. 따라서 $q = 12$이다. 렌더링의 경우 Gaussian 중심의 위치는 광선 거리와 카메라 파라미터를 통해 얻는다. 광선 거리, 광선 원점, 광선 방향을 각각 $t$, \(\textrm{ray}_o\), \(\textrm{ray}_d\)라 하면 Gaussian 중심은 \(\textrm{ray}_o + t \cdot \textrm{ray}_d\)이다.
모델의 최종 출력은 단순히 $N$개의 모든 입력 뷰의 3D Gaussian들을 병합한 것이다. 따라서 모델은 총 $NHW$개의 Gaussian을 출력하게 된다. 입력 해상도가 증가하면 Gaussian 수가 증가하기 때문에 대규모 장면에서 고주파 디테일을 더 잘 처리할 수 있다.
2. Loss Functions
예측된 Gaussian splat들을 사용하여 $M$개의 supervision view에서 이미지를 렌더링하고 이미지 재구성 loss를 최소화한다. GT 이미지와 렌더링된 이미지를 각각 \(\{\mathbf{I}_{i^\prime}^\ast\}\)와 \(\{\hat{\mathbf{I}}_{i^\prime}^\ast\}\)라 하면 loss function은 다음과 같이 MSE loss와 Perceptual loss의 조합이다.
\[\begin{equation} \mathcal{L} = \frac{1}{M} \sum_{i^\prime = 1}^M (\textrm{MSE} (\hat{\mathbf{I}}_{i^\prime}^\ast, \mathbf{I}_{i^\prime}^\ast) + \lambda \cdot \textrm{Perceptual} (\hat{\mathbf{I}}_{i^\prime}^\ast, \mathbf{I}_{i^\prime}^\ast)) \end{equation}\]Perceptual loss는 VGG-19를 기반으로 한다.
Experiments
- 데이터셋: Objaverse, RealEstate10K
- 구현 디테일
- patch size: 8$\times$8
- transformer
- layer: 24개
- hidden dimension: 1024
- head: 16개
- 2-layered MLP: GeLU activation, hidden dimension 4096
- 256$\times$256에서 사전 학습 후 512$\times$512에서 fine-tuning
- 뷰 개수
- Objaverse: 4 input views & 4 supervision views
- RealEstate10K: 2 input views & 6 supervision views
- GPU: A100 40G VRAM 64개 (사전 학습 2일, fine-tuning 1일)
1. Evaluation against Baselines
다음은 (왼쪽) object-level 재구성과 (오른쪽) scene-level 재구성에 대하여 baseline들과 비교한 표이다.

다음은 Instant3D의 Triplane-LRM과 시각적으로 비교한 결과들이다.

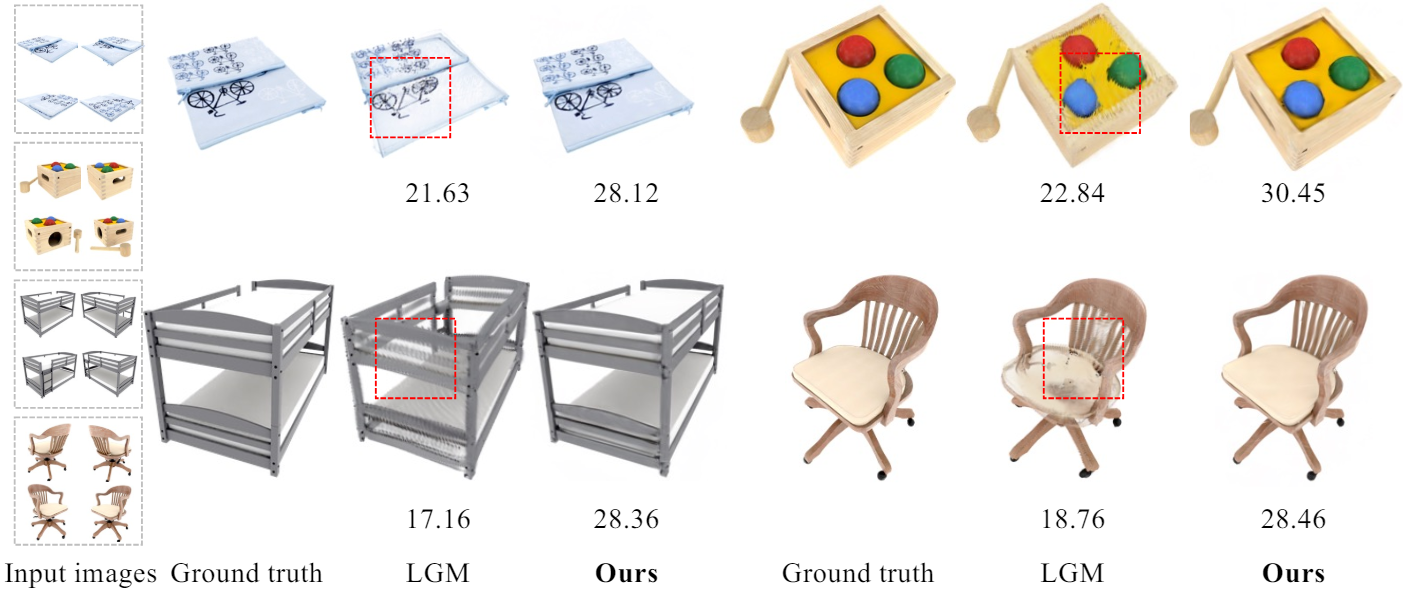
다음은 LGM들과 시각적으로 비교한 결과들이다.
다음은 pixelSplat과 렌더링 결과들을 비교한 것이다.

2. High-resolution Qualitative Results
다음은 고해상도의 novel-view 렌더링 결과들이다.

3. Applications in 3D Generation
다음은 (위) Instant3D의 텍스트 조건부 멀티뷰 생성기와 (아래) Zero123++의 이미지 조건부 멀티뷰 생성기를 GS-LRM reconstructor에 연결한 결과들이다.

다음은 text-to-scene 예시이다.

Limitations
- 모델이 현재 작동할 수 있는 최고 해상도는 512$\times$904이다.
- 카메라 파라미터를 알고 있어야 한다. 이 가정은 특정 시나리오에서는 실용적이지 않을 수 있다.
- 픽셀 정렬 표현은 view frustum 내부의 표면만 명시적으로 모델링한다. 즉, 보이지 않는 영역을 재구성할 수 없다.