[논문리뷰] Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
ECCV 2024. [Paper] [Github]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang
BNRist Center | IDEA | HKUST | The Chinese University of Hong Kong | Microsoft Research
9 Mar 2023
Introduction
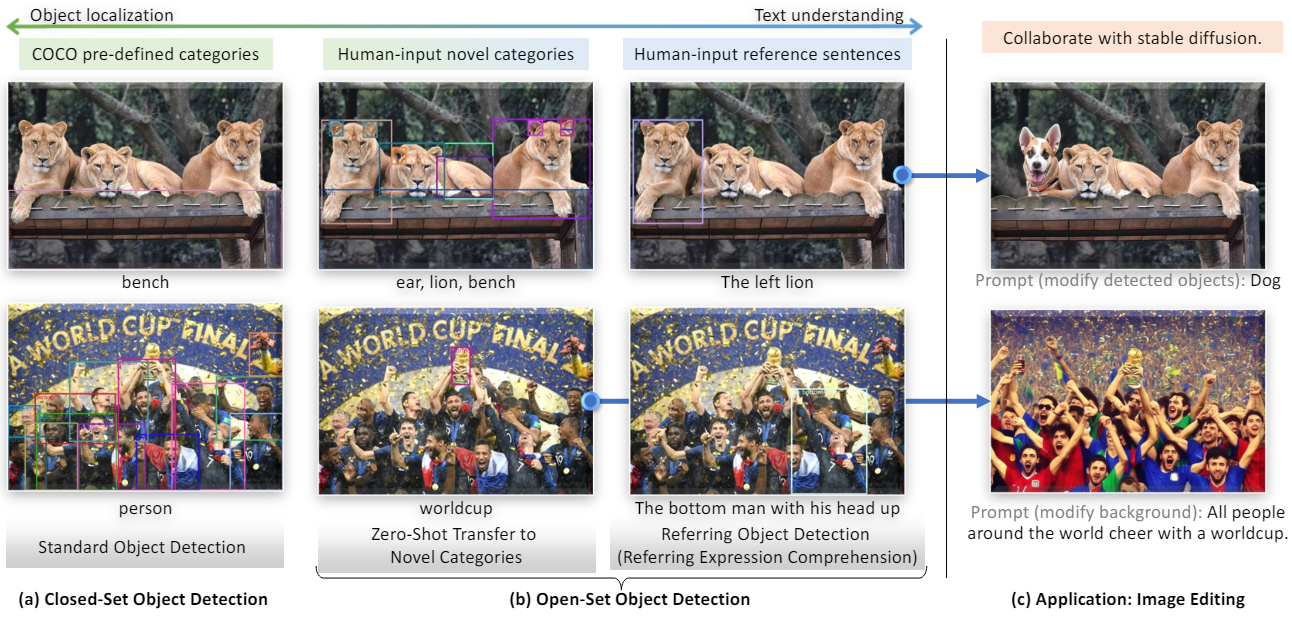
본 논문에서는 언어 입력에 의해 지정된 임의의 물체를 감지하는 강력한 시스템을 개발하는 것을 목표로 하며 이를 open-set object detection이라고 한다. 이 task는 큰 잠재력으로 인해 폭넓게 적용된다. 예를 들어, 이미지 편집을 위한 생성 모델과 협력할 수 있다.
Open-set detection의 핵심은 처음 보는 물체 일반화를 위한 언어를 도입하는 것이다. 예를 들어, GLIP은 object detection을 구문 grounding task로 재구성하고 물체 영역과 언어 구문 간의 contrastive training을 도입하였다. 인상적인 결과에도 불구하고 GLIP의 성능은 기존의 1단계 detector인 Dynamic Head를 기반으로 설계되었기 때문에 제한될 수 있다. Open-set detection과 closed-set detection은 밀접하게 관련되어 있으므로 더 강력한 closed-set detector가 더 나은 open-set detector를 생성할 수 있다.
본 논문에서는 Transformer 기반 detector의 발전에 동기를 부여하여 DINO 기반의 강력한 open-set detector인 Grounding DINO를 제안하였다. DINO는 SOTA object detection 성능을 가졌을 뿐만 아니라 여러 수준의 텍스트 정보를 grounded pre-training을 통해 알고리즘에 통합이 가능하다.
Grounding DINO는 GLIP과 비교했을 때 몇 가지 장점이 있다.
- Transformer 기반 아키텍처는 언어 모델과 유사하므로 이미지와 언어 데이터를 모두 더 쉽게 처리할 수 있다.
- Transformer 기반 detector는 대규모 데이터셋를 활용하는 탁월한 능력이 입증되었다.
- DETR-like model인 DINO는 Non-Maximum Suppression (NMS)와 같은 모듈을 사용하지 않고도 end-to-end로 최적화할 수 있어 전체 모델 설계를 크게 단순화한다. ` 대부분의 기존 open-set detector는 closed-set detector를 언어 정보가 포함된 open-set 시나리오로 확장하여 개발되었다.
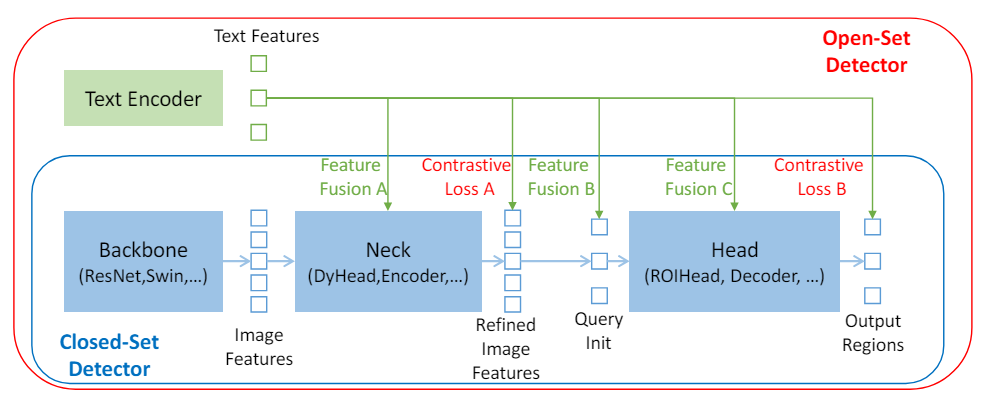
위 그림에서 볼 수 있듯이 closed-set detector에는 일반적으로
- Feature 추출을 위한 backbone
- Feature 향상을 위한 neck
- 영역 세분화 또는 bounding box 예측을 위한 head
라는 세 가지 모듈이 있다. Closed-set detector는 language-aware region embedding을 학습하여 새로운 물체를 감지하도록 일반화할 수 있으므로 각 영역은 language-aware semantic space에서 새로운 카테고리로 분류될 수 있다. 핵심은 영역 출력과 neck 및/또는 head 출력의 언어 feature 간의 contrastive loss를 사용하는 것이다. 모델이 modality 간 정보를 정렬할 수 있도록 일부 연구들에서는 최종 loss 단계 전에 feature를 융합하려고 했다. 위 그림은 feature 융합이 neck, 쿼리 초기화, head의 세 단계로 수행될 수 있음을 보여준다.
저자들은 더 많은 feature 융합이 모델의 성능을 향상시킬 수 있다고 주장하였다. Open-set detection의 경우 모델에는 일반적으로 대상 물체 카테고리 또는 특정 물체를 지정하는 이미지와 텍스트 입력이 모두 제공된다. 이러한 경우 처음에는 이미지와 텍스트를 모두 사용할 수 있으므로 더 나은 성능을 위해 긴밀한 융합 모델이 선호된다.
개념적으로는 간단하지만 세 단계 모두에서 feature 융합을 수행하기가 어렵다. 기존 detector와 달리 Transformer 기반 detector인 DINO는 언어 블록과 일관된 구조를 가지고 있다. 또한 layer-by-layer 디자인을 통해 언어 정보와 쉽게 상호 작용할 수 있다. 이 원칙에 따라 저자들은 neck, 쿼리 초기화, head 단계에서 세 가지 feature 융합 방식을 설계하였다.
구체적으로, 저자들은 self-attention, text-to-image cross-attention, image-to-text cross-attention을 neck 모듈로 쌓아서 feature enhancer를 설계하였다. 그런 다음 head에 대한 쿼리를 초기화하는 언어 기반 쿼리 선택 방법을 개발하였다. 또한 쿼리 표현을 강화하기 위해 이미지 및 텍스트 cross-attention layer를 사용하여 head 단계에 대한 cross-modality 디코더를 설계하였다. 세 가지 융합 단계는 더 나은 성능을 달성하는 데 효과적으로 도움이 된다.
대부분의 기존 open-set detection은 새로운 카테고리의 물체에 대한 모델을 평가한다. 저자들은 물체가 속성으로 설명되는 또 다른 중요한 시나리오도 고려해야 한다고 주장하며, 이 task를 Reference Expression Comprehension (REC)라 부른다. REC는 이전 open-set detection task에서는 간과되는 경향이 있었다. 본 논문에서는 open-set detection을 확장하여 REC를 지원하고 REC 데이터셋에 대한 성능도 평가히였다.
Method
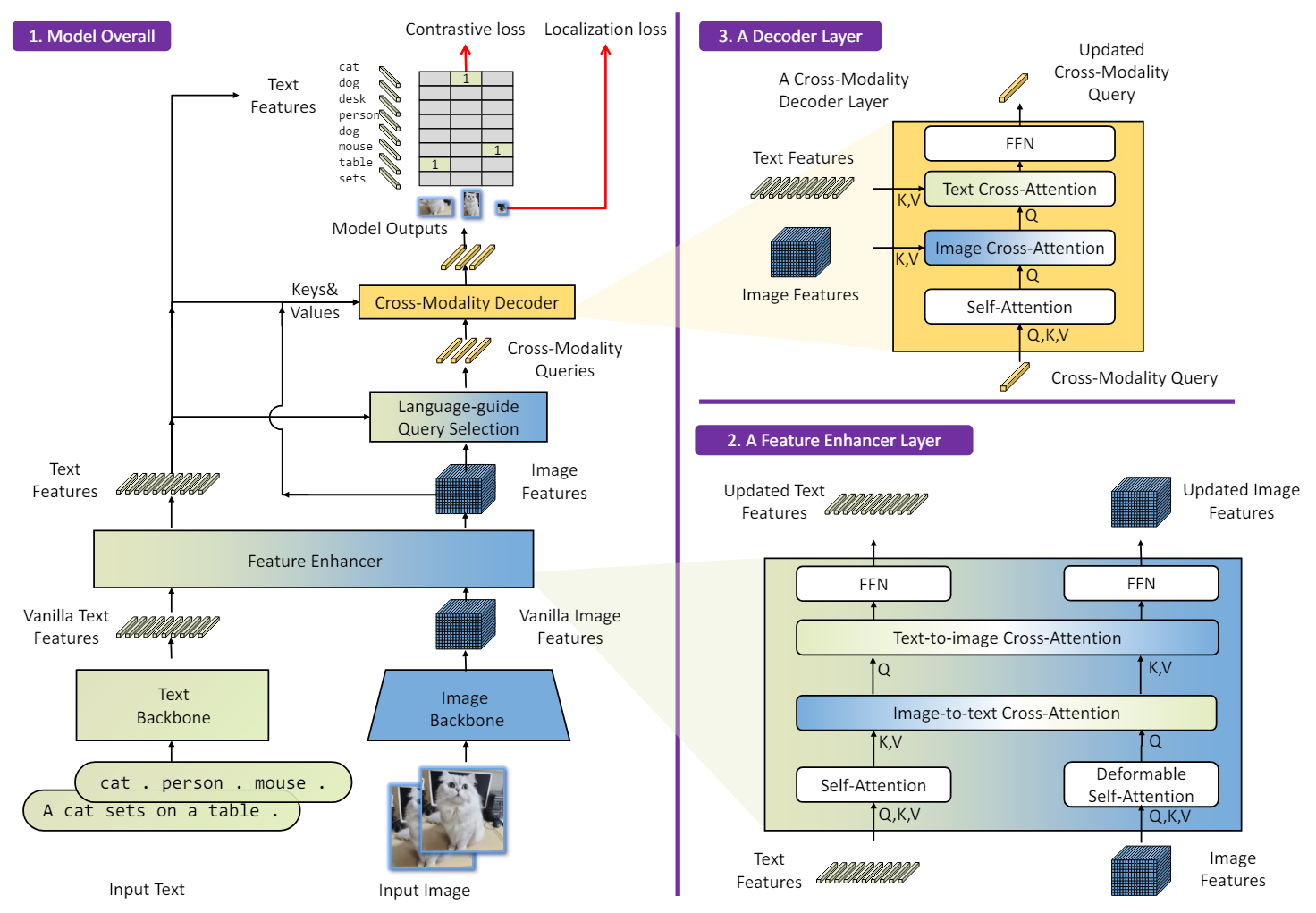
Grounding DINO는 주어진 이미지-텍스트 쌍에 대해 여러 쌍의 bounding box와 명사구를 출력한다. GLIP을 따라 object detection를 위한 입력 텍스트로 모든 카테고리 이름을 concatenate한다. REC에는 각 텍스트 입력에 bounding box가 필요하다. 가장 큰 점수를 가진 출력 물체를 REC task의 출력으로 사용한다.
Grounded DINO는 이중 인코더-단일 디코더 아키텍처이다. 여기에는 이미지 feature 추출을 위한 이미지 backbone, 텍스트 특징 추출을 위한 텍스트 backbone, 이미지와 텍스트 feature 융합을 위한 feature enhancer, 쿼리 초기화를 위한 언어 기반 쿼리 선택 모듈, 박스 세분화를 위한 cross-modality 디코더가 포함되어 있다.
각 이미지-텍스트 쌍에 대해 먼저 각각 이미지 backbone과 텍스트 backbone을 사용하여 이미지 feature와 텍스트 feature를 추출한다. 두 가지 feature는 cross-modality feature 융합을 위해 feature enhancer에 공급된다. 텍스트 feature와 이미지 feature를 얻은 후 언어 기반 쿼리 선택 모듈을 사용하여 이미지 feature에서 쿼리를 선택한다. 이 쿼리는 cross-modality 디코더에 공급되어 두 feature에서 원하는 feature를 조사하고 자체적으로 업데이트된다. 마지막 디코더 레이어의 출력 쿼리는 bounding box를 예측하고 해당 문구를 추출하는 데 사용된다.
1. Feature Extraction and Enhancer
이미지-텍스트 쌍이 주어지면 Swin Transformer와 같은 이미지 backbone으로 멀티스케일 이미지 feature를 추출하고 BERT와 같은 텍스트 backbone으로 텍스트 feature를 추출한다. 이전 DETR-like detector를 따라 다양한 블록의 출력에서 멀티스케일 feature가 추출된다. 이미지 feature와 텍스트 feature를 추출한 후 이를 cross-modality feature 융합을 위한 feature enhancer에 공급한다. Feature enhancer에는 여러 feature 강화 레이어가 포함되어 있다. Deformable self-attention을 활용하여 이미지 feature를 향상시키고 일반 self-attention을 활용하여 텍스트 feature를 향상시킨다. GLIP에서 영감을 받아 feature 융합을 위해 image-to-text cross-attention과 text-to-image cross-attention을 추가한다.
2. Language-Guided Query Selection

Grounding DINO는 입력된 텍스트로 지정된 이미지에서 물체를 감지하는 것을 목표로 한다. 입력 텍스트를 효과적으로 활용하여 object detection을 가이드하기 위해 입력 텍스트와 더 관련성이 높은 feature를 디코더 쿼리로 선택하는 언어 기반 쿼리 선택 모듈을 사용한다. Algorithm 1은 쿼리 선택 프로세스이다.
언어 기반 쿼리 선택 모듈은 디코더의 쿼리 수만큼의 인덱스를 출력하며, 구현 시 쿼리 수는 900으로 설정된다. 선택된 인덱스를 기반으로 feature를 추출하여 쿼리를 초기화할 수 있다. DINO를 따라 혼합 쿼리 선택을 사용하여 디코더 쿼리를 초기화한다. 각 디코더 쿼리에는 각각 콘텐츠 파트과 위치 파트가 포함된다. 위치 파트는 인코더 출력으로 초기화되는 동적 앵커 박스이다. 콘텐츠 파트는 학습 가능하도록 설정된다.
3. Cross-Modality Decoder
저자들은 이미지 feature와 텍스트 feature를 결합하는 cross-modality 디코더를 개발하였다. 각 cross-modality 쿼리는 self-attention layer, 이미지 feature를 결합하는 이미지 cross-attention layer, 텍스트 feature를 결합하는 텍스트 cross-attention layer, 각 cross-modality 디코더 레이어의 FFN layer에 입력된다. 더 나은 modality 정렬을 위해 쿼리에 텍스트 정보를 삽입해야 하기 때문에 INO 디코더 레이어와 다르게 각 디코더 레이어에는 텍스트 cross-attention layer가 추가로 있다.
4. Sub-Sentence Level Text Feature
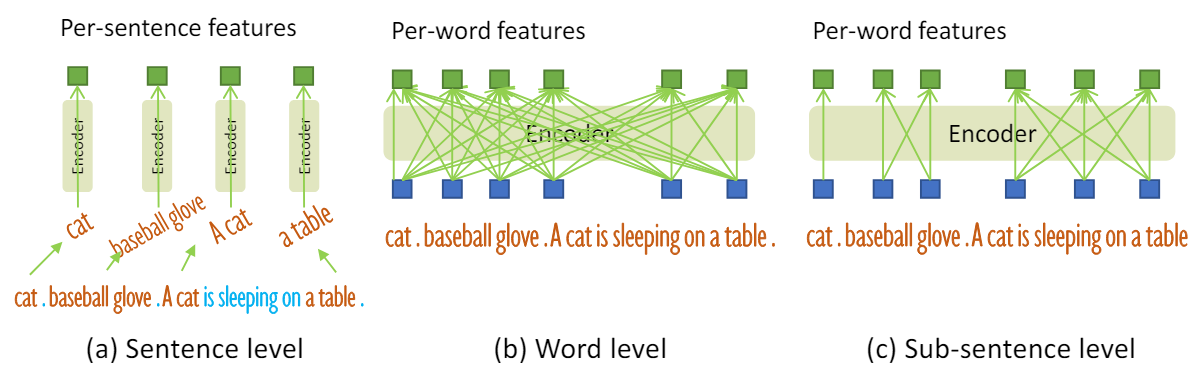
위 그림과 같이 문장 수준 표현과 단어 수준 표현이라는 두 가지 종류의 텍스트 프롬프트가 이전 연구들에서 탐색되었다. 문장 수준 표현은 전체 문장을 하나의 feature로 인코딩한다. 일부 문장에 여러 구문이 있는 경우 해당 구문을 추출하고 다른 단어를 삭제한다. 이런 식으로 문장의 세밀한 정보를 잃어버리면서 단어 사이의 영향이 제거된다. 단어 수준 표현을 사용하면 여러 카테고리 이름을 하나의 forward pass로 인코딩할 수 있지만 attention 중에 관련되지 않은 일부 단어가 상호 작용한다.
원치 않는 단어 상호 작용을 피하기 위해 “subsentence” 수준 표현이라는 관련 없는 카테고리 이름 간의 attention을 차단하는 attention mask를 도입한다. 세밀한 이해를 위해 단어별 feature를 유지하면서 서로 다른 카테고리 이름 간의 영향을 제거한다.
5. Loss Function
Bounding box regression에 L1 loss와 GIOU loss를 사용한다. GLIP을 따라 classification을 위해 예측 물체와 언어 토큰 간의 contrastive loss를 사용한다. 구체적으로, 각 쿼리에 텍스트 feature를 내적하여 각 텍스트 토큰에 대한 로짓을 예측한 다음 각 로짓에 대한 focal loss를 계산한다. Box regression 및 classification 비용은 먼저 예측과 GT 간의 이분 매칭에 사용된다. 그런 다음 동일한 loss를 사용하여 GT와 일치하는 예측 간의 최종 loss를 계산한다. DETR-like model을 따라 각 디코더 레이어와 인코더 출력 뒤에 보조 loss를 추가한다.
Experiments
- 구현 디테일
- 이미지 backbone: Swin-T, Swin-L
- 텍스트 backbone: BERT-base
1. Zero-Shot Transfer of Grounding DINO
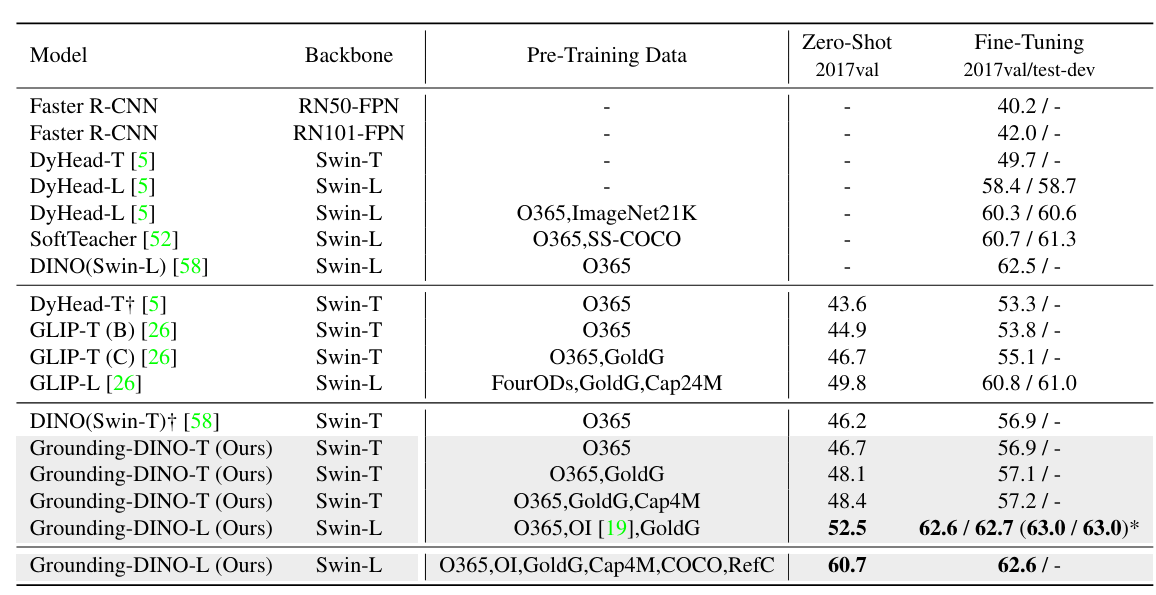
다음은 COCO로의 zero-shot transfer를 비교한 표이다.
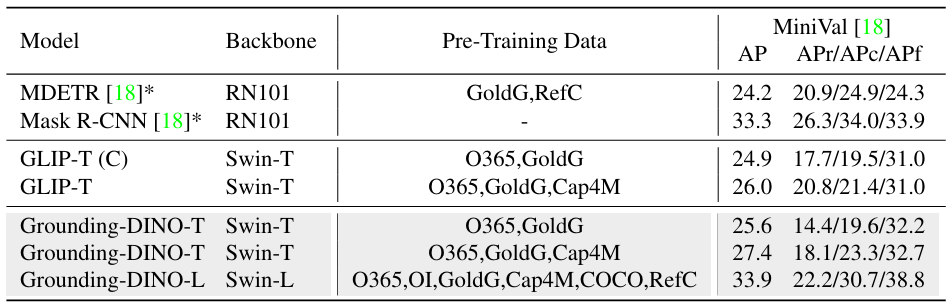
다음은 LVIS로의 zero-shot transfer를 비교한 표이다.
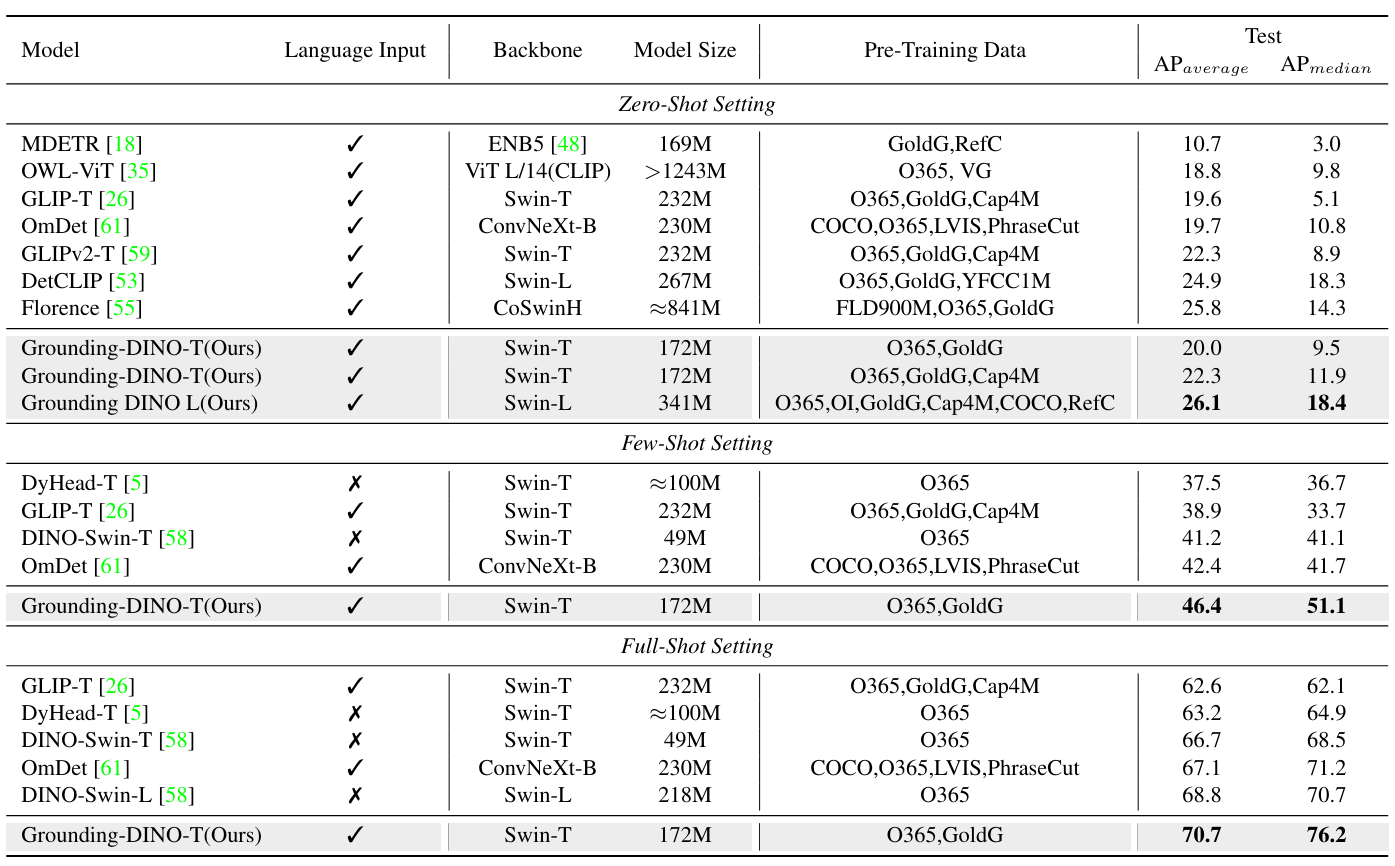
다음은 ODinW 벤치마크에서의 성능을 비교한 표이다.
2. Referring Object Detection Settings
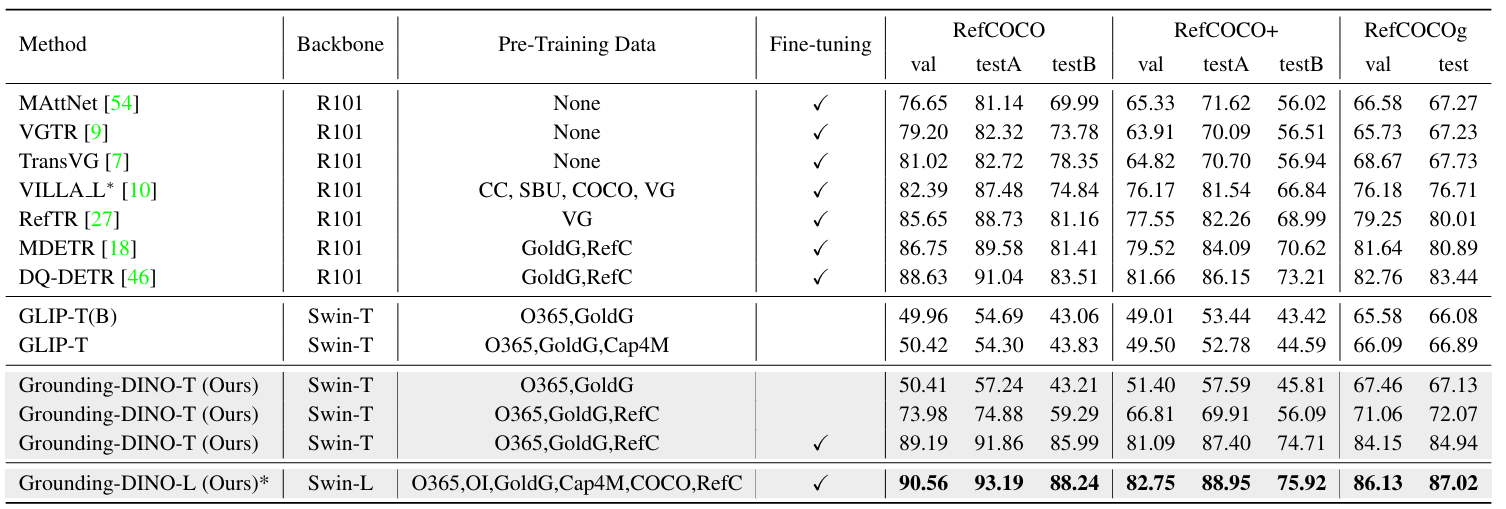
다음은 REC task에서의 top-1 정확도를 비교한 표이다.
3. Ablations
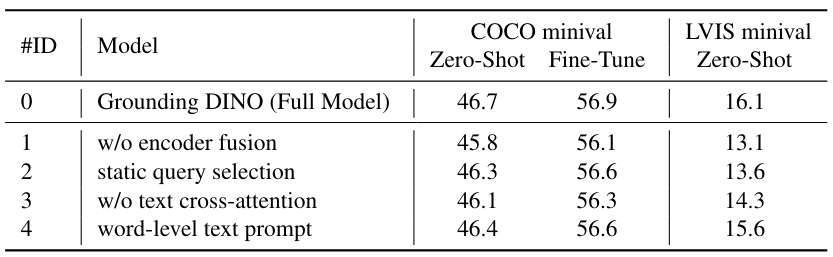
다음은 ablation 결과이다.
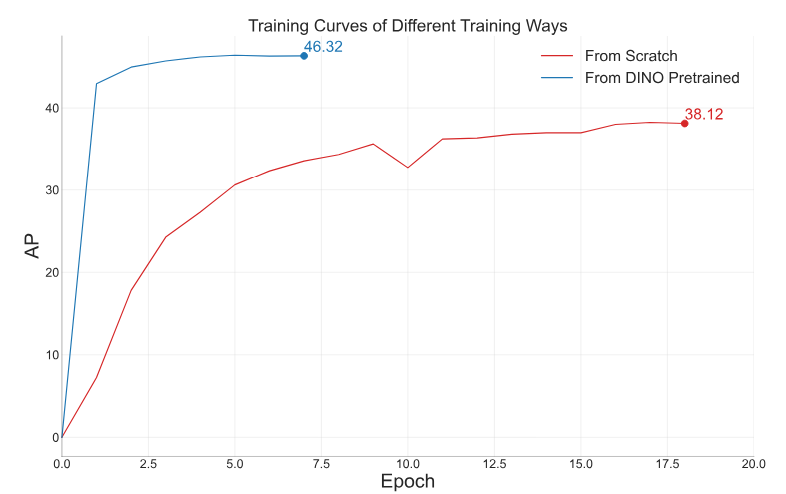
4. Transfer from DINO to Grounding DINO
다음은 사전 학습된 DINO에서 transfer한 Grounding DINO와 처음부터 학습한 Grounding DINO를 비교한 결과이다.