[논문리뷰] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
EMNLP 2023. [Paper]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, Sumit Sanghai
Google Research
22 May 2023
Introduction
Autoregressive 디코더 inference는 모든 디코딩 step에서 디코더 가중치와 모든 attention key와 value를 로드하는 데 따른 메모리 대역폭 오버헤드로 인해 Transformer 모델에 심각한 병목 현상이 발생한다. Key와 value를 로드하는 데 따른 메모리 대역폭은 여러 개의 query head를 사용하지만 하나의 key 및 value head를 사용하는 multi-query attention (MQA)를 통해 크게 줄어들 수 있다.
그러나 MQA는 품질 저하와 불안정한 학습으로 이어질 수 있으며, 품질과 inference에 최적화된 별도의 모델을 학습하는 것이 불가능할 수 있다. 또한 PaLM과 같은 일부 언어 모델은 이미 MQA를 사용하고 있지만 T5나 LLaMA와 같은 공개적으로 사용 가능한 언어 모델을 포함하여 많은 언어 모델은 사용하지 않는다.
본 논문에는 대규모 언어 모델의 더 빠른 inference를 위한 두 가지 기여가 포함되어 있다. 먼저, multi-head attention (MHA)이 있는 언어 모델 체크포인트가 원래 학습 컴퓨팅의 작은 부분으로 MQA를 사용하도록 업트레이닝될 수 있음을 보여준다. 이는 빠른 multi-query와 고품질 MHA 체크포인트를 얻는 비용 효율적인 방법을 제시한다.
둘째, query head의 하위 그룹당 하나의 key 및 value head를 사용하여 multi-head와 MQA를 보간하는 grouped-query attention (GQA)를 제안한다. 업트레이닝된 GQA는 MQA만큼 빠른 동시에 multi-head attention에 가까운 품질을 달성한다.
Method
1. Uptraining
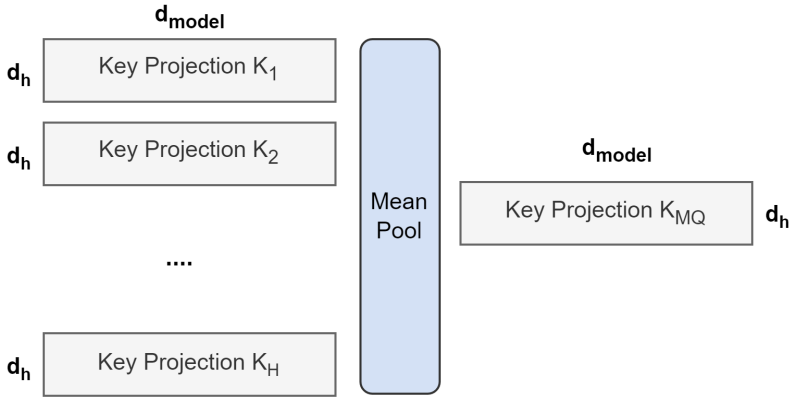
Multi-head 모델에서 multi-query 모델을 생성하는 작업은 두 단계로 이루어진다. 첫 번째는 체크포인트 변환이고, 두 번째는 모델이 새로운 구조에 적응할 수 있도록 하는 추가 사전 학습이다. 위 그림은 multi-head 체크포인트를 multi-query 체크포인트로 변환하는 프로세스를 보여준다. Key head와 value head에 대한 projection 행렬은 하나의 projection 행렬로 average pooling된다. 이는 하나의 key 및 value head를 선택하거나 처음부터 새 key 및 value head를 무작위로 초기화하는 것보다 더 잘 작동한다.
그런 다음 변환된 체크포인트는 동일한 사전 학습 방법으로 원래 학습 단계의 작은 비율 $\alpha$에 대해 사전 학습된다.
2. Grouped-query attention
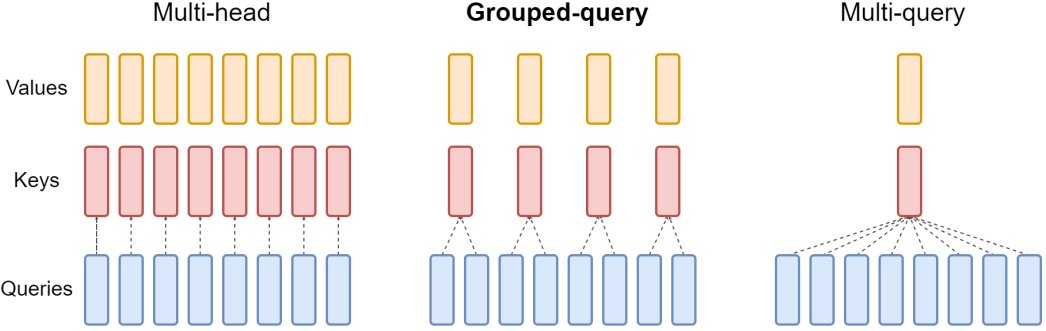
Grouped-query attention (GQA)은 query head를 $G$개의 그룹으로 나누고, 각 그룹은 하나의 key 및 value head를 공유한다. GQA-G는 $G$개의 그룹이 포함된 grouped-query를 나타낸다. 하나의 그룹, 즉 하나의 key 및 value head를 갖는 GQA-1은 MQA와 동일하고, head 수와 동일한 그룹을 갖는 GQA-H는 MHA와 동일하다. 위 그림은 GQA와 MHA/MQA를 비교한 것이다. Multi-head 체크포인트를 GQA 체크포인트로 변환할 때 해당 그룹 내의 모든 원래 head를 average pooling하여 각 그룹 key 및 value head를 구성한다.
중간 개수의 그룹은 MQA보다 품질이 높지만 MHA보다 빠른 보간된 모델로 이어지며, 유리한 trade-off를 나타낸다. MHA에서 MQA로 전환하면 $H$개의 key 및 value head가 하나의 key 및 value head로 줄어들어 key-value 캐시의 크기가 줄어들고 그에 따라 로드해야 하는 데이터의 양이 $H$만큼 줄어든다. 그러나 더 큰 모델은 일반적으로 head 수를 확장하므로 MQA는 메모리 대역폭과 용량 모두에서 더 공격적인 감소를 나타낸다. GQA를 사용하면 모델 크기가 증가함에 따라 대역폭과 용량이 동일하게 비례적으로 감소한다.
또한 key-value 캐시는 모델 차원에 따라 확장되고 모델 FLOP와 파라미터는 모델 차원의 제곱에 따라 확장되므로 더 큰 모델은 attention으로 인한 메모리 대역폭 오버헤드로 인해 상대적으로 덜 고통받는다. 마지막으로 대규모 모델의 표준 샤딩(sharding)은 모델 파티션 수만큼 하나의 key와 value head를 복제한다. GQA는 이러한 파티셔닝에서 낭비를 제거한다. 따라서 GQA는 대형 모델에 대해 특히 좋은 trade-off를 제공할 것으로 기대된다.
Experiments
- 데이터
- 요약: CNN/Daily Mail, arXiv/PubMed, MediaSum, Multi-News
- 번역: WMT 2014 English-to-German
- 질의응답: TriviaQA
- Configurations: 모든 모델은 T5.1.1 아키텍처를 기반으로 하며 JAX, Flax 및 Flaxformer로 구현된다. MHA가 있는 T5 Large와 XXL과 MQA와 GQA가 있는 T5 XXL의 업트레이닝된 버전을 고려한다. MQA와 GQA를 디코더 self-attention과 cross-attention에 적용하지만 인코더 self-attention은 적용하지 않는다.
- Uptraining: 업트레이닝된 모델은 T5.1.1 체크포인트에서 초기화된다. Key 및 value head는 적절한 MQA 또는 GQA 구조로 average pooling된 다음 원래 사전 학습 설정을 사용하여 원래 사전 학습 단계의 추가 $\alpha$ 비율에 대해 사전 학습된다.
- Fine-tuning
- learning rate: 0.001
- batch size: 128
- dropout: 0.1
- 입출력 길이
- CNN/Daily Mail, WMT: 입력 512, 출력 256
- 다른 요약 데이터셋: 입력 2048, 출력 512
- TriviaQA: 입력 2048, 출력 32
1. Main results
다음은 샘플당 시간과 성능을 비교한 그래프이다.
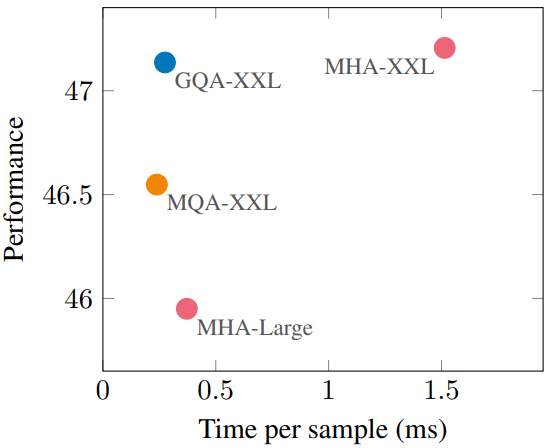
다음은 inference 시간과 평균 성능을 비교한 표이다. ($\alpha = 0.05$)

2. Ablations
Checkpoint conversion
다음은 MQA로 업트레이닝된 T5-Large에 대한 다양한 체크포인트 변환 방법의 성능을 비교한 그래프이다. ($\alpha = 0.05$)
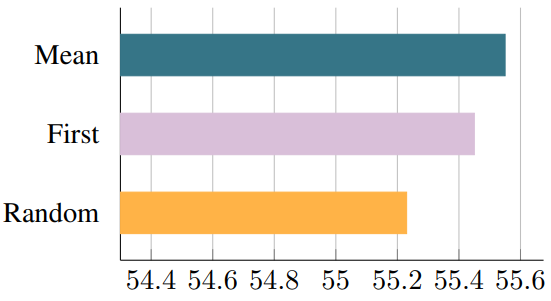
Uptraining steps
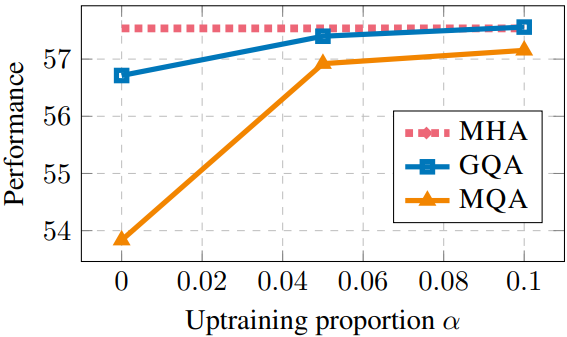
다음은 MQA와 GQA-8이 포함된 T5 XXL 모델의 업트레이닝 비율에 따른 성능을 비교한 그래프이다.
Number of groups
다음은 GQA 그룹 수에 따른 GQA-XXL의 샘플당 시간이다. (입력 길이가 2048, 출력 길이가 512)