[논문리뷰] Zero-shot Referring Image Segmentation with Global-Local Context Features (Global-Local CLIP)
CVPR 2023. [Paper] [Github]
Seonghoon Yu, Paul Hongsuck Seo, Jeany Son
AI graduate school, GIST | Google Research
31 Mar 2023
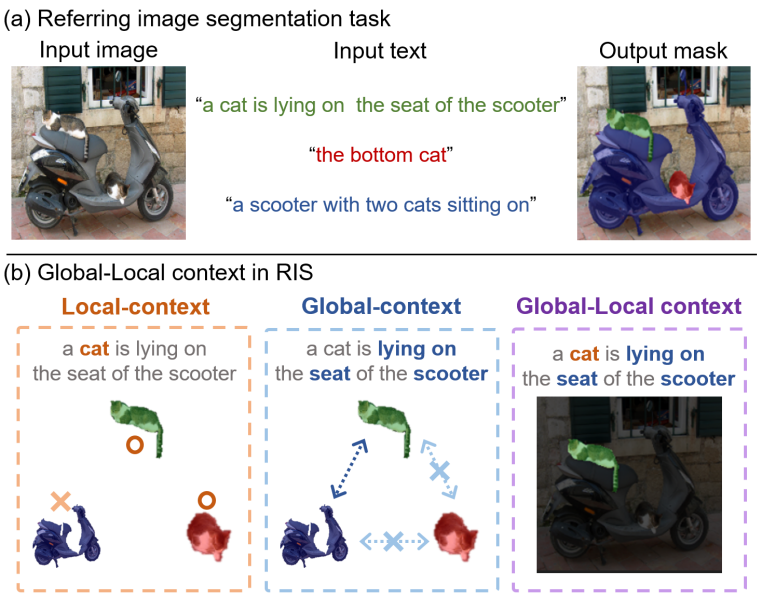
Introduction
CLIP과 같은 멀티모달 모델의 최근 성공의 핵심 요소는 대규모 이미지-텍스트 쌍 집합에 대한 대조 이미지-텍스트 사전 학습이다. object detection, semantic segmentation, image captioning, visual question answering (VQA) 등과 같은 광범위한 task에서 놀라운 zero-shot 전송 가능성을 보여주었다.
사전 학습된 멀티모달 모델의 우수한 전송 가능성에도 불구하고 object detection 및 image segmentation과 같은 dense prediction task를 처리하는 것은 간단하지 않다. 픽셀 수준의 dense prediction task는 이미지 수준의 대조 사전 학습 task와 semantic segmentation과 같은 픽셀 수준의 다운스트림 task 사이에 상당한 차이가 있기 때문에 어렵다. 두 task 사이의 간격을 줄이기 위한 여러 시도가 있었지만 이러한 연구들은 결과적으로 노동 집약적이고 비용이 많이 드는 task별 조밀한 주석이 필요한 모델을 fine-tuning하는 것을 목표로 한다.
Referring image segmentation (RIS)은 특정 영역을 설명하는 자연어 텍스트가 주어졌을 때 이미지에서 특정 영역을 찾는 task로, 비전-언어 관련 과제 중 하나로 잘 알려져 있다. 이 task에 대한 주석을 수집하는 것은 타겟 영역의 정확한 참조 표현과 조밀한 마스크 주석을 수집해야 하기 때문에 훨씬 더 어렵다. 최근에는 이러한 문제를 극복하기 위해 weakly-supervised RIS 방법이 제안되었다. 그러나 여전히 타겟 데이터셋에 대한 이미지와 쌍을 이루는 높은 수준의 텍스트 표현 주석이 필요하며 성능은 supervised 방법과는 차이가 크다. 이 문제를 해결하기 위해 본 논문에서는 사전 학습된 CLIP 지식에서 RIS로의 zero-shot 전송에 중점을 둔다.
게다가 이 task는 높은 수준의 언어 이해와 이미지에 대한 포괄적인 이해, 그리고 조밀한 인스턴스 수준 예측이 필요하기 때문에 어렵다. Zero-shot semantic segmentation을 위한 여러 연구가 있었지만, 서로 다른 특성을 가지고 있기 때문에 zero-shot RIS로 직접 확장할 수는 없다. 구체적으로 semantic segmentation는 인스턴스를 구별할 필요가 없지만 RIS는 인스턴스 수준 분할 마스크를 예측할 수 있어야 한다. 또한, 동일한 클래스의 여러 인스턴스 중 표현식에서 설명하는 인스턴스 하나만 선택해야 한다.
본 논문에서는 이미지와 표현의 글로벌 및 로컬 컨텍스트가 일관된 방식으로 처리되는 CLIP의 사전 학습된 모델을 사용하여 zero-shot RIS의 새로운 기준선을 제안하였다. 텍스트 참조 표현이 주어진 이미지에서 객체 마스크 영역을 localize하기 위해 마스크가 주어진 이미지의 글로벌 및 로컬 컨텍스트 정보를 캡처하는 글로벌-로컬 시각적 인코더를 제안하였다. 또한 로컬 컨텍스트가 타겟 명사구에 의해 캡처되고 글로벌 컨텍스트가 표현의 전체 문장에 의해 캡처되는 글로벌-로컬 텍스트 인코더를 제안하였다. 두 가지 서로 다른 컨텍스트 수준의 feature를 결합함으로써 타겟 개체의 특정 특성뿐만 아니라 포괄적인 지식을 이해할 수 있다. 본 논문의 방법은 CLIP 모델에 대한 추가 학습이 필요하지 않지만 모든 baseline과 weakly-supervised RIS 방법보다 큰 차이로 성능이 뛰어나다.
Method
1. Overall Framework
텍스트 설명을 기반으로 타겟 영역을 예측하는 것을 목표로 하는 RIS를 해결하려면 공유 임베딩 공간에서 이미지와 텍스트 표현을 학습하는 것이 필수적이다. 이를 위해 CLIP을 채택하여 이미지와 자연어에 대해 사전 학습된 cross-modal feature를 활용한다.
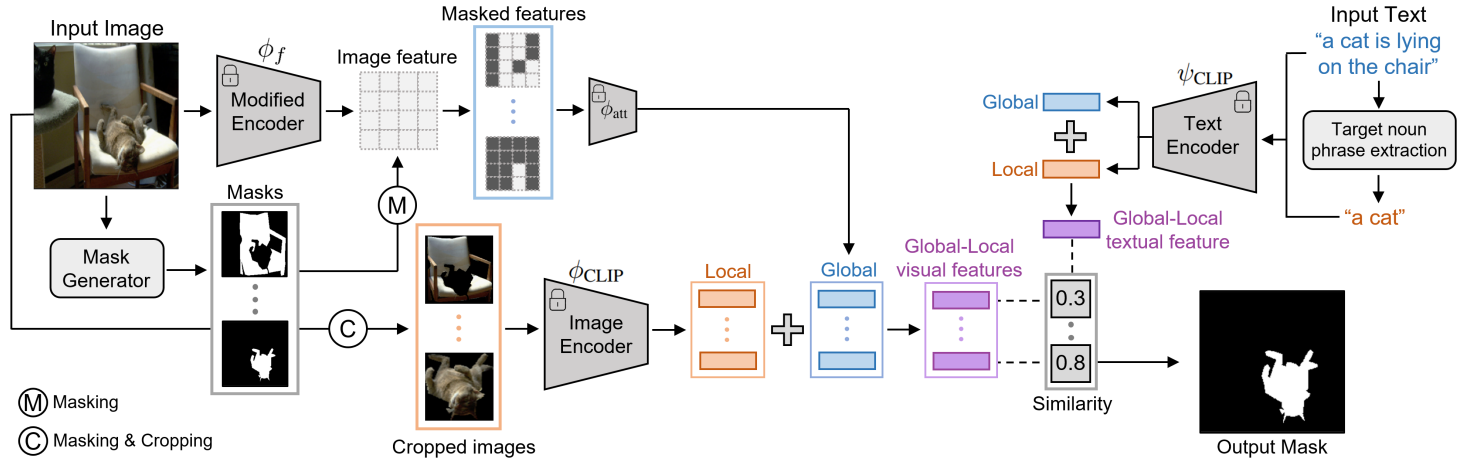
본 논문의 프레임워크는 위 그림과 같이 두 부분으로 구성된다.
- 시각적 표현을 위한 글로벌-로컬 시각적 인코더
- 참조 표현을 위한 글로벌-로컬 자연어 인코더
Unsupervised mask generator에 의해 생성된 mask proposal 집합이 주어지면 먼저 각 mask proposal에 대해 글로벌 컨텍스트와 로컬 컨텍스트 수준에서 두 개의 visual feature를 추출한 다음 이를 하나의 visual feature로 결합한다. 글로벌 컨텍스트 visual feature는 마스킹된 영역과 주변 영역을 포괄적으로 표현할 수 있는 반면, 로컬 컨텍스트 visual feature는 마스킹된 특정 영역의 표현을 캡처할 수 있다. 이는 타겟의 포괄적인 표현을 사용하여 작은 특정 타겟 영역에 초점을 맞춰야 하기 때문에 RIS에서 핵심 역할을 한다.
동시에 타겟을 표현하는 문장이 주어지면 CLIP 텍스트 인코더를 통해 텍스트 표현이 추출된다. 타겟의 전체적인 표현을 이해하고 타겟 객체 자체에 집중하기 위해 먼저 spaCy에서 제공하는 종속성 파싱을 사용하여 문장에서 핵심 명사구를 추출한 후 글로벌 문장 feature와 로컬 타겟 명사구 feature를 결합한다. 시각적 인코더와 텍스트 인코더는 글로벌 컨텍스트와 로컬 컨텍스트 정보를 일관된 방식으로 처리하도록 설계되었다.
본 논문의 방법은 visual feature와 textual feature가 공통 임베딩 공간에 임베딩된 CLIP을 기반으로 구축되었기 때문에 zero-shot RIS의 목적 함수를 다음과 같이 공식화할 수 있다. 이미지 $I$와 참조 표현 $T$의 입력이 주어지면 본 논문의 방법은 모든 mask proposal 중에서 visual feature와 주어진 textual feature 사이의 최대 유사도를 갖는 마스크를 찾는다.
\[\begin{equation} \hat{m} = \underset{m \in M (I)}{\arg \max} \; \textrm{sim} (t, f_m) \end{equation}\]여기서 $\textrm{sim}(\cdot, \cdot)$은 코사인 유사도, $t$는 $T$에 대한 글로벌-로컬 textual feature, $f$는 글로벌-로컬 visual feature, $M(I)$는 주어진 이미지 $I$에 대한 mask proposal 집합이다.
2. Mask-guided Global-local Visual Features
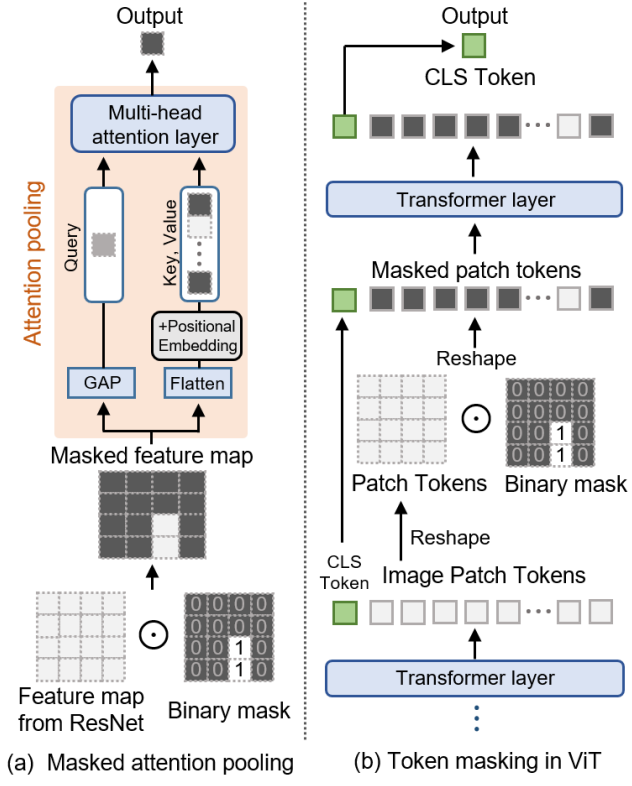
참조 표현과 관련된 타겟 영역을 분할하기 위해서는 타겟의 로컬 semantic 정보뿐만 아니라 이미지 내 여러 객체 간의 글로벌 관계를 이해하는 것이 필수적이다. CLIP을 사용하여 글로벌 및 로컬 컨텍스트 feature를 추출하고 이를 융합한다.
CLIP은 이미지 수준 표현을 학습하도록 설계되었으므로 image segmentation과 같은 픽셀 수준의 dense prediction에는 적합하지 않다. CLIP 사용의 한계를 극복하기 위해 task를 mask proposal 생성과 마스킹된 이미지-텍스트 매칭이라는 두 가지 하위 task로 분해한다. Mask proposal을 생성하기 위해 unsupervised 인스턴스 수준 마스크 생성 모델인 기성 마스크 추출기를 사용한다. Mask proposal을 명시적으로 사용함으로써 본 논문의 방법은 CLIP을 사용하여 매우 상세한 인스턴스 수준 segmentation mask를 처리할 수 있다.
Global-context Visual Features
각 mask proposal에 대해 먼저 CLIP으로 사전 학습된 모델을 사용하여 글로벌 컨텍스트 visual feature를 추출한다. 그러나 CLIP의 원래 visual feature는 전체 이미지를 설명하기 위해 하나의 feature 벡터를 생성하도록 설계되었다. 이 문제를 해결하기 위해 CLIP의 시각적 인코더를 수정하여 마스킹된 영역뿐만 아니라 주변 영역의 정보가 포함된 feature를 추출하여 여러 객체 간의 관계를 이해하도록 한다.
본 논문에서는 CLIP에서와 같이 시각적 인코더에 ResNet과 ViT의 두 가지 다른 아키텍처를 사용한다. ResNet 아키텍처를 사용하는 시각적 인코더의 경우 pooling layer가 없는 visual feature 추출기를 $\phi_f$로 나타내고 해당 attention pooling layer를 \(\phi_\textrm{att}\)로 나타내자. 그러면 CLIP의 시각적 인코더인 \(\phi_\textrm{CLIP}\)을 사용한 visual feature $f$는 다음과 같이 표현될 수 있다.
\[\begin{equation} f = \phi_\textrm{CLIP} (I) = \phi_\textrm{att} (\phi_f (I)) \end{equation}\]여기서 $I$는 주어진 이미지이다. 마찬가지로 ViT에는 여러 개의 multi-head attention layer가 있으므로 이 시각적 인코더를 마지막 $k$개의 레이어와 나머지의 두 부분으로 나눈다. CLIP을 기반으로 하는 ViT 아키텍처의 경우 전자를 \(\phi_\textrm{att}\)로 표시하고 후자를 $\phi_f$로 표시한다. 그러면 주어진 이미지 $I$와 마스크 $m$에 대하여 글로벌 컨텍스트 visual feature는 다음과 같이 정의된다.
\[\begin{equation} f_m^G = \phi_\textrm{att} (\phi_f (I) \odot \bar{m}) \end{equation}\]여기서 $\bar{m}$은 feature map의 크기에 맞게 크기가 조정된 마스크이고, $\odot$은 element-wise 곱셈 연산이다.
전체 이미지가 인코더를 통과하고 마지막 레이어의 feature map에 이미지에 대한 전체적인 정보가 포함되어 있기 때문에 이를 글로벌 컨텍스트 visual feature라고 한다. Feature map의 마스킹된 영역에서만 feature를 얻기 위해 mask proposal을 사용하지만 이러한 feature는 이미 장면에 대한 포괄적인 정보를 가지고 있다.
Local-context Visual Features
주어진 mask proposal에 대한 로컬 컨텍스트에 맞는 visual feature를 얻으려면 먼저 이미지를 마스킹한 다음 이미지를 잘라 mask proposal 영역만 둘러싸는 새 이미지를 얻는다. 이미지를 자르고 마스킹한 후 CLIP의 시각적 인코더로 전달되어 로컬 컨텍스트 visual feature $f_m^L$를 추출한다.
\[\begin{equation} f_m^L = \phi_\textrm{CLIP} (\mathcal{T}_\textrm{crop} (I \odot m)) \end{equation}\]여기서 \(\mathcal{T}_\textrm{crop}(\cdot)\)은 자르기 연산을 나타낸다. 이 접근 방식은 일반적으로 zero-shot semantic segmentation 방법에 사용된다. 이 feature는 이미지에서 마스킹된 영역에 초점을 맞추고 관련 없는 영역을 제거하므로 타겟 객체 자체에만 집중한다.
Global-local Context Visual features
이미지의 마스킹된 영역 표현을 설명하는 하나의 visual feature를 얻기 위해 마스킹된 영역에 대한 글로벌 및 로컬 컨텍스트 feature를 집계한다. 글로벌-로컬 컨텍스트 visual feature는 다음과 같이 계산된다.
\[\begin{equation} f_m = \alpha f_m^G + (1 - \alpha) f_m^L, \quad \alpha \in [0, 1] \end{equation}\]여기서 $m$은 mask proposal, $f^G$와 $f^L$은 글로벌 및 로컬 컨텍스트 visual feature이다. 그런 다음 각 mask proposal의 점수는 글로벌-로컬 컨텍스트 visual feature와 참조 표현의 textual feature 간의 유사도를 계산하여 얻는다.
3. Global-local Textual Features
Visual feature와 마찬가지로, 주어진 참조 표현에서 타겟 객체 명사뿐만 아니라 전체적인 의미를 이해하는 것이 중요하다. 참조 표현 $T$가 주어지면 사전 학습된 CLIP 텍스트 인코더 \(\psi_\textrm{CLIP}\)을 사용하여 다음과 같이 글로벌 문장 feature $t^G$를 추출한다.
\[\begin{equation} t^G = \psi_\textrm{CLIP} (T) \end{equation}\]CLIP 텍스트 인코더는 이미지 수준 표현에 맞춰 텍스트 표현을 추출할 수 있지만, 이 task의 표현은 여러 절을 포함하는 복잡한 문장으로 구성되므로 표현에서 타겟 명사에 집중하기 어렵다.
이 문제를 해결하기 위해 spaCy를 사용한 dependency parsing으로 텍스트 표현식 $T$가 주어지면 타겟 명사구 $\textrm{NP}(T)$를 찾는다. 타겟 명사구를 찾으려면 먼저 표현식에서 모든 명사구를 찾은 다음 문장의 어근명사 (root noun)를 포함하는 타겟 명사구를 선택한다. 입력 문장에서 타겟 명사구를 식별한 후 CLIP 텍스트 인코더에서 로컬 컨텍스트 textual feature를 추출한다.
\[\begin{equation} t^L = \psi_\textrm{CLIP} (\textrm{NP} (T)) \end{equation}\]마지막으로, 글로벌-로컬 컨텍스트 textual feature는 다음과 같이 글로벌 및 로컬 textrm feature의 가중 합계로 계산된다.
\[\begin{equation} t = \beta t^G + (1 - \beta) t^L, \quad \beta \in [0, 1] \end{equation}\]Experiments
- 데이터셋: RefCOCO, RefCOCO+, RefCOCOg
- 구현 디테일
- FreeSOLO를 사용하여 mask proposal을 얻음 (입력 이미지의 짧은쪽 크기 = 800)
- CLIP 시각적 인코더로 ResNet-50과 ViT-B/32를 모두 사용
- CLIP의 경우 이미지 크기는 224$\times$224
- ViT의 마스킹 레이어의 수: $k = 3$
- $\alpha$: RefCOCOg는 0.85, RefCOCO와 RefCOCO+는 0.95
- $\beta$: 모든 데이터셋에서 0.5
1. Results
Main Results
다음은 세 가지 표준 벤치마크 데이터셋에 대하여 zero-shot RIS baseline과 비교한 표이다. (U: The UMD partition. G: The Google partition)
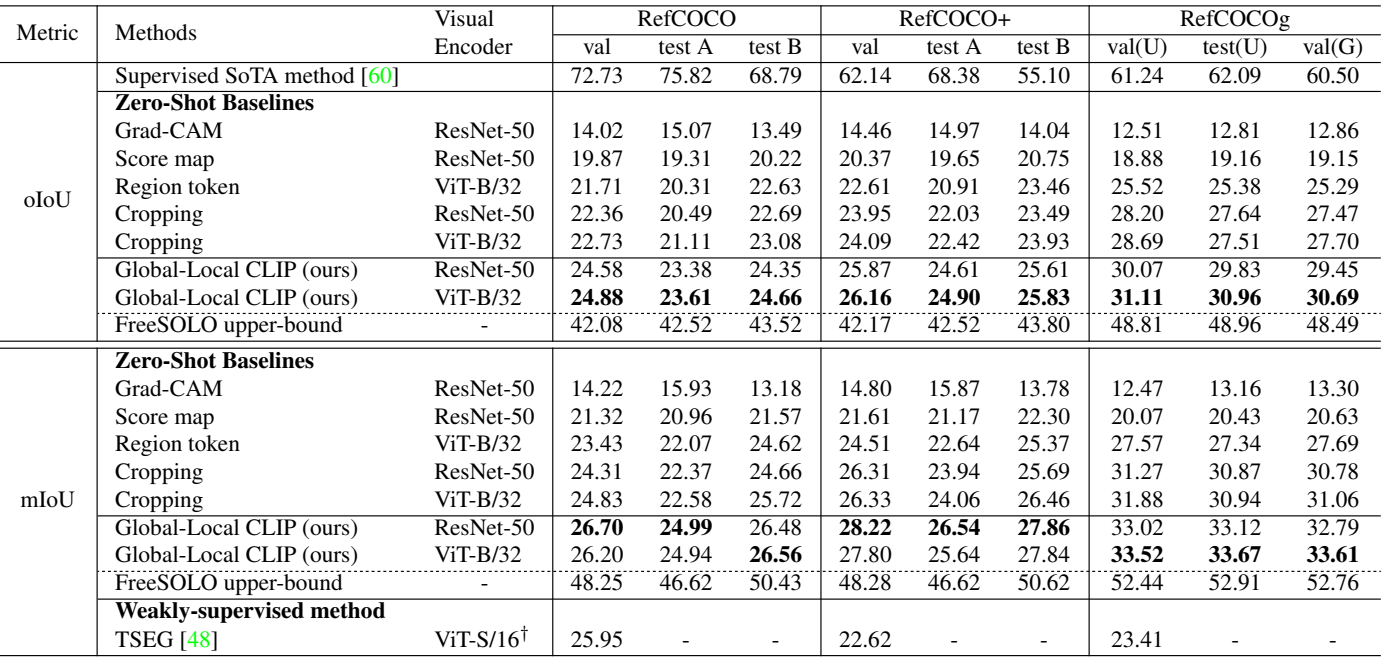
Zero-shot Evaluation on Unseen Domain
다음은 PhraseCut의 zero-shot 설정에서 supervised 방법을 비교한 결과이다.
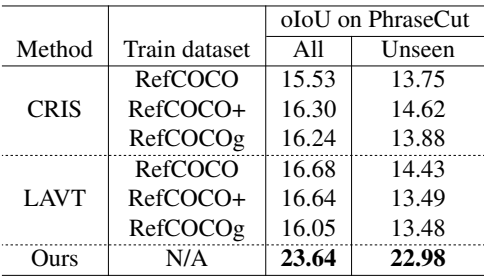
Comparison to supervised methods in few-shot Setting
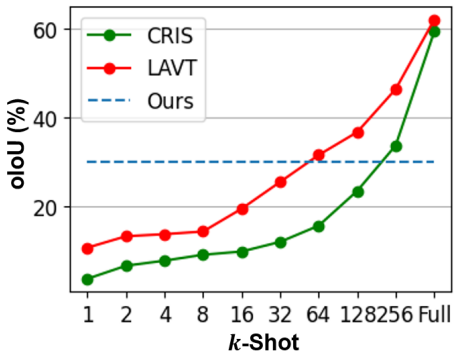
다음은 RefCOCOg의 few-shot 설정에서 supervised 방법을 비교한 그래프이다.
2. Ablation Study
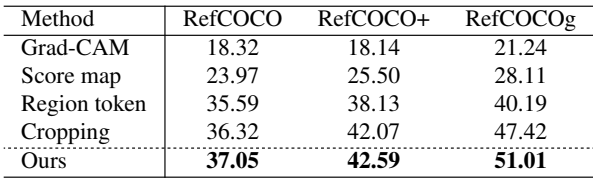
Effects of Mask Quality
다음은 본 논문의 방법과 baseline를 oIoU로 비교한 표이다.
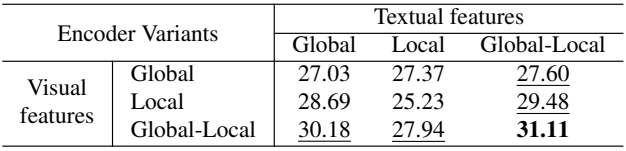
Effects of Global-Local Context Features
다음은 여러 컨텍스트 수준의 feature에 대한 oIoU 결과이다.
Qualitative Analysis
다음은 여러 수준의 visual feature에 대한 정성적 결과이다.

다음은 여러 수준의 textual feature에 대한 정성적 결과이다.

다음은 본 논문의 방법을 여러 baseline들과 정성적으로 비교한 결과이다.
