[논문리뷰] GLIGEN: Open-Set Grounded Text-to-Image Generation
CVPR 2023. [Paper] [Page] [Github]
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, Yong Jae Lee
University of Wisconsin-Madison | Columbia University | Microsoft
17 Jan 2023
Introduction
이미지 생성 연구는 최근 몇 년 동안 엄청난 발전을 목격했다. 지난 몇 년 동안 GAN은 latent space와 제어 가능한 조작 및 생성을 위해 잘 연구된 조건부 입력으로 state-of-the-art이었다. 텍스트 조건부 autoregressive 및 diffusion model은 보다 안정적인 목적 함수와 웹 이미지-텍스트 쌍 데이터에 대한 대규모 학습으로 인해 놀라운 이미지 품질과 concept coverage를 보여주었다.
흥미로운 발전에도 불구하고 기존의 대규모 텍스트-이미지 생성 모델은 텍스트 이외의 다른 입력 양식에 따라 조건을 지정할 수 없으므로 개념을 정확하게 localize하거나 레퍼런스 이미지를 사용하여 생성 프로세스를 제어하는 기능이 부족하다. 자연어만으로는 정보를 표현할 수 있는 방식이 제한돤다. 예를 들어, 텍스트를 사용하여 객체의 정확한 위치를 설명하는 것은 어려운 반면 bounding box / keypoint는 쉽게 이를 달성할 수 있다. Inpainting, layout-to-image 생성 등을 위해 텍스트 이외의 입력 형식을 취하는 조건부 diffusion model과 GAN이 존재하지만 제어 가능한 text-to-image 생성을 위해 이러한 입력을 결합하는 경우는 거의 없다.
또한 생성 모델 계열에 관계없이 이전 생성 모델은 일반적으로 각 task별 데이터셋에서 독립적으로 학습된다. 이에 반해 인식 분야에서는 대규모 이미지 데이터나 이미지-텍스트 쌍으로 사전 학습된 기초 모델에서 시작하여 task별 인식 모델을 구축하는 것이 오랜 패러다임이었다. Diffusion model은 수십억 개의 이미지-텍스트 쌍에 대해 학습되었으므로 자연스러운 질문은 다음과 같다.
기존의 사전 학습된 diffusion model을 기반으로 새로운 조건부 입력 양식을 부여할 수 있는가?
이러한 방식으로 인식 분야의 논문과 유사하게 기존의 텍스트-이미지 생성 모델에 대해 더 많은 제어 가능성을 획득하면서 사전 학습된 모델이 가지고 있는 방대한 개념 지식으로 인해 다른 생성 task에서 더 나은 성능을 달성할 수 있다.

본 논문은 위의 목적을 가지고 사전 학습된 text-to-image diffusion model에 새로운 grounding 조건부 입력을 제공하는 방법을 제안한다. 위 그림에 표시된 것처럼 텍스트 캡션을 입력으로 유지하지만 grounding 개념, grounding 레퍼런스 이미지, grounding keypoint에 대한 bounding box와 같은 다른 입력 형식도 활성화한다. 핵심 과제는 새로운 grounding 정보를 주입하는 방법을 배우면서 사전 학습된 모델에서 원래의 방대한 개념 지식을 보존하는 것이다. 지식 망각을 방지하기 위해 원래 모델 가중치를 동결하고 새로운 grounding 입력(ex. bounding box)을 받아들이는 새로운 학습 가능한 gated Transformer layer를 추가할 것을 제안한다. 학습하는 동안 gated mechanism을 사용하여 사전 학습된 모델에 새로운 grounding 정보를 점진적으로 융합한다. 이 디자인은 품질 및 제어 가능성을 향상시키기 위해 샘플링 프로세스에서 유연성을 제공한다. 예를 들어 샘플링 단계의 전반부에서 전체 모델(모든 layer)을 사용하고 후반부에서 원래 계층(gated Transformer layer 제외)만 사용하면 grounding 조건을 정확하게 반영하는 생성 결과를 얻을 수 있음을 보여주며, 동시에 높은 이미지 품질을 제공한다.
실험에서 저자들은 주로 bounding box가 있는 grounded text-to-image 생성을 연구한다. 이는 최근 GLIP의 box를 사용한 grounded language-image 이해 모델 학습의 확장 성공에 영감을 받았다. 본 논문의 모델이 현실 어휘 개념을 ground할 수 있도록 하기 위해, 동일한 사전 학습된 텍스트 인코더(캡션 인코딩용)를 사용하여 각 grounded entity(즉, bounding box당 하나의 구문)와 관련된 각 구문을 인코딩하고 인코딩된 토큰을 공급한다. 인코딩된 위치 정보와 함께 새로 삽입된 레이어에 공유 텍스트 space로 인해 모델은 COCO 데이터셋에서만 학습된 경우에도 보지 못한 객체를 일반화할 수 있다. LVIS에 대한 일반화는 강력한 fully-supervised baseline보다 훨씬 뛰어나다. 모델의 grounding 능력을 더욱 향상시키기 위해 GLIP에 따라 학습을 위한 물체 감지 데이터와 grounding 데이터 형식을 통합하며, 이는 보완적인 이점을 제공하기 때문이다. 감지 데이터는 더 양이 많으며 grounding 데이터는 더 풍부한 어휘를 가지고 있다. 더 큰 학습 데이터를 사용하면 모델의 일반화가 지속적으로 개선된다.
Preliminaries on Latent Diffusion Models
Diffusion 기반 방법은 text-to-image task를 위한 가장 효과적인 모델 계열 중 하나이며, 그 중 latent diffusion model (LDM)과 그 후속 모델인 Stable Diffusion은 연구 커뮤니티에서 공개적으로 사용할 수 있는 가장 강력한 모델이다. 일반 diffusion model 학습의 계산 비용을 줄이기 위해 LDM은 두 단계로 진행된다. 첫 번째 단계는 이미지 $x$의 latent 표현 $z$를 얻기 위해 양방향 매핑 네트워크를 학습한다. 두 번째 단계는 latent $z$에서 diffusion model을 학습한다. 첫 번째 단계 모델은 $x$와 $z$ 사이에 고정된 양방향 매핑을 생성하므로 여기서부터는 단순화를 위해 LDM의 latent generation space에 중점을 둔다.
Training Objective
Noise $z_T$에서 시작하여 모델은 캡션 $c$를 조건으로 받아 각 timestep $t$에서 점진적으로 덜 noisy한 샘플 $z_{T-1}, z_{T-2}, \cdots, z_0$를 생성한다. 모델 $f_\theta$를 학습시키기 위해, 각 step에서 LDM 목적 함수는 latent 표현 $z$에서 denoising problem을 푼다.
\[\begin{equation} \min_{\theta} \mathcal{L}_\textrm{LDM} = \mathbb{E}_{z, \epsilon \sim \mathcal{N}(0,I), t} [ \| \epsilon - f_\theta (z_t, t, c) \|_2^2 ] \end{equation}\]Network Architecture
네트워크 아키텍처의 핵심은 보다 깨끗한 버전의 $z$가 생성되는 조건을 인코딩하는 방법이다.
- 노이즈 제거 자동 인코더. $f_\theta (\ast, t, c)$는 UNet을 통해 구현된다. Timestep $t$와 조건 $c$의 정보뿐만 아니라 noisy한 latent $z$를 가져온다. 일련의 ResNet 및 Transformer block으로 구성된다.
- 조건 인코딩. 원래 LDM에서 BERT와 유사한 네트워크는 각 캡션을 일련의 텍스트 임베딩 $f_\textrm{text} (c)$로 인코딩하도록 처음부터 학습되며, 이는 $c$를 대체하기 위해 목적 함수에 공급된다. 캡션 feature는 Stable Diffusion에서 고정 CLIP 텍스트 인코더를 통해 인코딩된다. 시간 $t$는 먼저 시간 임베딩 $\phi(t)$에 매핑된 다음 UNet에 주입된다. 캡션 feature는 각 Transformer block 내의 cross-attention layer에서 사용된다. 모델은 목적 함수로 noise를 예측하는 방법을 학습한다.
대규모 학습을 통해 모델 $f_\theta (\ast, t, c)$는 캡션 정보에만 기반하여 $z$를 denoise하도록 잘 학습된다. 인터넷 규모의 데이터에 대한 사전 학습을 통해 LDM을 사용하여 인상적인 language-to-image 생성 결과가 표시되었지만 추가 grounding 입력을 지시할 수 있는 이미지를 합성하는 것은 여전히 어려운 일이므로 본 논문의 목표이다.
Open-set Grounded Image Generation
1. Grounding Instruction Input
Grounded text-to-image 생성의 경우 공간적 컨디셔닝을 통해 개체를 grounding하는 다양한 방법이 있다. 텍스트나 예시 이미지를 통해 설명된 grounding entity를 $e$로 표시하고 bounding box 또는 일련의 keypoint 등으로 설명된 grounding 공간 구성을 $l$로 표시한다. 캡션과 grounding entity의 구성으로 grounded text-to-image model에 대한 instruction을 정의한다.
\[\begin{aligned} \textrm{Instruction: } & y = (c, e), \quad \textrm{with} \\ \textrm{Caption: } & c = [c_1, \cdots, c_L] \\ \textrm{Grounding: } & e = [(e_1, l_1), \cdots. (e_N, l_N)] \end{aligned}\]$L$은 캡션의 길이이고, $N$은 ground할 entity을 개수이다. 본 논문에서는 가용성이 높고 사용자가 쉽게 주석을 달 수 있는 grounding 공간 구성 $l$로 bounding box를 사용하여 주로 연구한다. Grounded entity $e$의 경우 단순성으로 인해 주로 텍스트를 표현으로 사용하는 데 중점을 둔다. 캡션 및 grounded entity를 diffusion model에 대한 입력 토큰으로 처리한다.
Caption Tokens
캡션 $c$는 LDM에서와 같은 방식으로 처리된다. 특히 $h^c = [h_1^c, \cdots, h_L^c] = f_\textrm{text} (c)$를 사용하여 caption feature sequence를 얻는다. 여기서 $h_l^c$는 캡션의 $l$번째 단어에 대한 컨텍스트화된 텍스트 feature이다.
Grounding Tokens
Bounding box로 표시된 각 grounded text entity에 대해 위치 정보를 왼쪽 상단과 오른쪽 하단 좌표와 함께 $l = [\alpha_\textrm{min}, \beta_\textrm{min}, \alpha_\textrm{max}, \beta_\textrm{max}]$로 나타낸다. Text entity $e$의 경우 동일한 사전 학습된 텍스트 인코더를 사용하여 text feature $f_\textrm{text} (e)$를 얻은 다음 bounding box 정보와 융합하여 grounding token을 생성한다.
\[\begin{equation} h^c = \textrm{MLP} (f_\textrm{text} (e), \textrm{Fourier} (b)) \end{equation}\]$\textrm{Fourier}$는 Fourier embedding이며, $\textrm{MLP} (\cdot , \cdot)$는 먼저 두 입력을 feature 차원에서 concat한 다음 MLP를 통과시키는 연산이다. Grounding token sequence $h^e = [h_1^e, \cdots, h_N^e]$로 표현된다.
From Closed-set to Open-set
기존 layout-to-image 연구는 위 식의 $f_\textrm{text} (e)$를 대체하기 위해 일반적으로 entity당 $u$를 포함하는 벡터를 학습하므로 closed-set setting (ex. COCO 카테고리)만 처리한다. $K$개의 개념이 있는 closed-set setting의 경우 $K$개의 임베딩이 있는 dictionary $U = [u_1, \cdots, u_K]$가 학습된다. 이 non-parametric 표현은 closed-set setting에서 잘 작동하지만 두 가지 단점이 있다.
- 컨디셔닝은 평가 단계에서 $U$에 대한 dictionary look-up으로 구현되므로 모델은 생성된 이미지에서 관찰된 entity만 ground할 수 있으며 새 entity를 ground하도록 일반화하는 능력이 부족하다.
- 모델 컨디셔닝에서 사용된 단어/문구가 없으며 기본 언어 instruction의 의미 구조가 누락되었다.
대조적으로, open-set design에서는 명사 entity들이 캡션을 인코딩하는 데 사용되는 동일한 텍스트 인코더로 처리되기 때문에 localization 정보가 grounding 학습 데이터셋의 개념으로 제한되는 경우에도 모델이 여전히 다른 개념으로 일반화할 수 있다.
Training Data
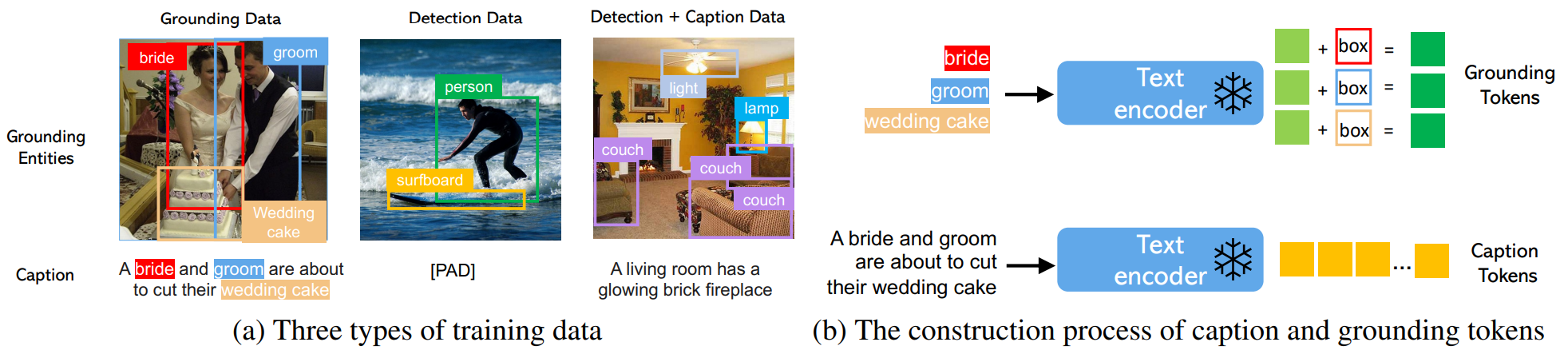
Ground된 이미지 생성을 위한 학습 데이터는 전체 조건으로 텍스트 $c$와 grounding entity $e$가 모두 필요하다. 실제로는 보다 유연한 입력, 즉 세 가지 유형의 데이터를 고려하여 데이터 요구 사항을 완화할 수 있다.
- Grounding data. 각 이미지는 전체 이미지를 설명하는 캡션과 연결된다. 명사 entity는 캡션에서 추출되고 bounding box로 레이블이 지정된다. 명사 entity는 자연어 캡션에서 직접 가져오기 때문에 현실 어휘 기반 생성에 도움이 될 훨씬 더 풍부한 어휘를 다룰 수 있다.
- Detection data. 명사 entity는 미리 정의된 closed-set 카테고리이다 (ex. COCO의 80개 객체 클래스). 이 경우 캡션에 대한 classifier-free guidance에 소개된 대로 null 캡션 토큰을 사용하도록 선택한다. Detection data는 grounding data(수천 개)보다 더 많은 양(수백만 개)이므로 전체 학습 데이터를 크게 증가시킬 수 있다.
- Detection and caption data. 명사 entity는 detection data와 동일하며 이미지는 텍스트 캡션과 함께 별도로 설명된다. 이 경우 명사 entity가 캡션의 entity와 정확히 일치하지 않을 수 있다.
Extensions to Other Grounding Conditions
Grounding instruction은 일반적인 형식이지만 지금까지 텍스트를 entity $e$로 사용하고 bounding box를 $l$로 사용하는 경우에 중점을 두었다. 저자들은 GLIGEN 프레임워크의 유연성을 입증하기 위해 instruction의 사용 시나리오를 확장하는 두 가지 추가 대표적인 사례도 연구하였다.
- Image Prompt. 언어를 사용하면 사용자가 개방형 어휘 방식으로 풍부한 entity 집합을 설명할 수 있지만 때로는 더 추상적이고 세분화된 개념이 예제 이미지로 더 잘 특성화될 수 있다. 이를 위해 언어 대신 이미지를 사용하여 개체 $e$를 설명할 수 있다. 이미지 인코더를 사용하여 $e$가 이미지일 때 $f_\textrm{text} (e)$ 대신 사용되는 feature $f_\textrm{image} (e)$를 얻는다.
- Keypoints. Entity의 공간 구성을 지정하는 간단한 parameterization 방법으로 bounding box는 개체 레이아웃의 높이와 너비만 제공하여 사용자와의 상호 작용 인터페이스를 용이하게 한다. Keypoint 좌표의 집합으로 $l$을 parameterize하여 GLIGEN의 keypoint와 같은 더 풍부한 공간 구성을 고려할 수 있다. 인코딩 상자와 유사하게 Fourier embedding은 각 키포인트 위치 $l = [x, y]$에 적용될 수 있다.
2. Continual Learning for Grounded Generation
본 논문의 목표는 기존의 대규모 language-to-image 생성 모델에 새로운 공간 grounding 능력을 부여하는 것이다. 다양하고 복잡한 언어 instruction을 기반으로 사실적인 이미지를 합성하는 데 필요한 지식을 얻기 위해 웹 스케일 이미지 텍스트에 대해 대규모 diffusion model을 사전 학습시켰다. 높은 사전 학습 비용과 우수한 성능으로 인해 새로운 능력을 확장하면서 모델 가중치에 대한 지식을 유지하는 것이 중요하다. 따라서 원래 모델 가중치를 고정하고 새 모듈을 조정하여 점차 모델을 적응시킨다.
Gated Self-Attention
$v$를 이미지의 visual feature token이라 하자. LDM의 원래 Transformer block은 두 개의 attention layer로 구성된다.
- Visual token에 대한 self-attention
- 캡션 토큰의 cross-attention
Residual connection을 고려하여 두 layer를 다음과 같이 쓸수 있다.
\[\begin{aligned} v &= v + \textrm{SelfAttn} (v) \\ v &= v + \textrm{CrossAttn} (v, h^c) \end{aligned}\]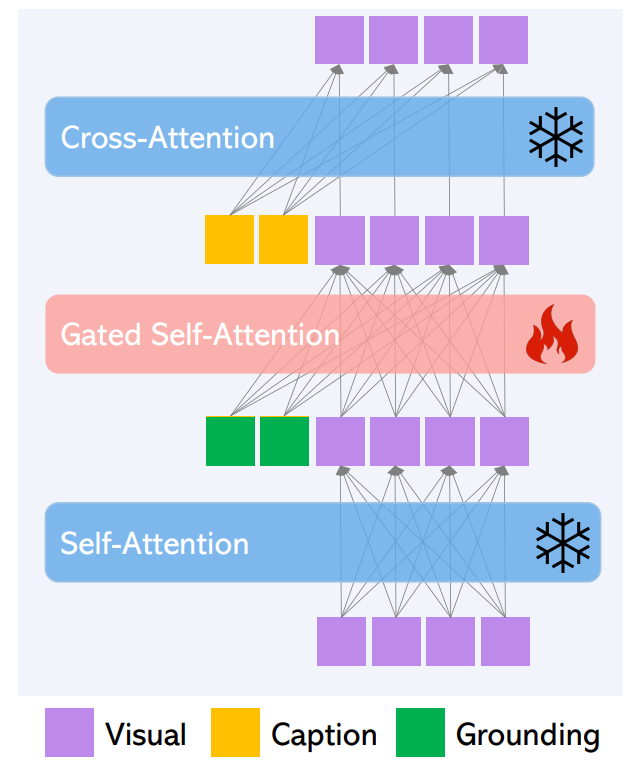
위 그림과 같이 두 개의 attention layer를 freeze하고 새로운 gated self-attention layer를 추가해 공간적 grounding 능력을 활성화한다. 특히 visual token과 grounding token을 concat한 후 attention을 수행한다.
$\textrm{TS}(\cdot)$는 visual token만 고려하는 토큰 선택 연산이고 $\gamma$는 0으로 초기화되는 학습 가능한 스칼라이다. $\beta$는 전체 학습에서 1로 설정되며, inference 중에 scheduled sampling을 위해 변경하여 품질과 조절 능력을 개선한다. 위 식은 self-attention과 cross-attention 사이에 들어간다. 직관적으로, 위 식의 gated self-attention은 visual feature가 bounding box 정보를 활용하도록 만들며, grounded feature 결과를 residual로 취급한다. 이 residual의 gate는 초기에 0으로 설정되며, 학습을 더 안정하게 만든다.
Learning Procedure
원래의 모든 구성 요소는 그대로 유지하면서 grounding 정보를 주입할 수 있도록 사전 학습된 모델을 조정한다. 모든 gated self-attention 레이어의 새 파라미터를 $\theta’$로 표시함으로써 grounding instruction 입력 $y$를 기반으로 연속적인 모델 학습을 위해 다음과 같이 원래 denoising 목적 함수를 사용한다.
\[\begin{equation} \min_{\theta'} \mathcal{L}_\textrm{Grounding} = \mathbb{E}_{z, \epsilon \sim \mathcal{N}(0, I), t} [\| \epsilon - f_{\{\theta, \theta'\}} (z_t, t, y) \|_2^2] \end{equation}\]모델이 각 개체의 위치에 대한 외부 지식을 활용할 수 있다면 reverse diffusion process에서 학습 이미지에 추가된 noise를 직관적으로 예측하는 것이 더 쉬울 것이다. 따라서 이러한 방식으로 모델은 사전 학습된 개념 지식을 유지하면서 추가 localization 정보를 사용하는 방법을 학습한다.
A Versatile User Interface
모델이 잘 학습되면 캡션을 disentangling하고 입력을 grounding하는 본 논문의 디자인은 다목적 인터페이스를 지원한다. 사용자가 캡션 입력에 존재하는 entity를 ground할 수 있을 뿐만 아니라 캡션 입력에 언급되지 않은 개체를 원하는 위치에 자유롭게 추가할 수도 있다. 순수한 텍스트 기반 diffusion model의 경우 사용자는 캡션의 모든 개체를 번거롭게 설명하는 동시에 정확한 위치를 지정해야 하므로 언어만으로는 어려울 수 있다.
Scheduled Sampling in Inference
GLIGEN의 표준 inference 방식은 $\beta = 1$로 설정하는 것이며 전체 diffusion process는 grounding token의 영향을 받는다. 이 일정한 $\beta$ 샘플링 방식은 생성 및 grounding 측면에서 전반적으로 우수한 성능을 제공하지만 때때로 원본 text-to-image model에 비해 낮은 품질의 이미지를 생성한다. GLIGEN의 생성과 grounding 사이의 더 나은 균형을 맞추기 위해 저자들은 scheduled sampling 방식을 제안한다. 원래 모델 가중치를 동결하고 새로운 layer를 추가하여 학습에 새로운 grounding 정보를 주입함에 따라, 다른 $\beta$ 값을 설정하여 inference 중에 언제든지 grounding token과 language token을 모두 사용하거나 원래 모델의 language token만 사용하도록 diffusion process를 schedule할 수 있는 유연성이 있다.
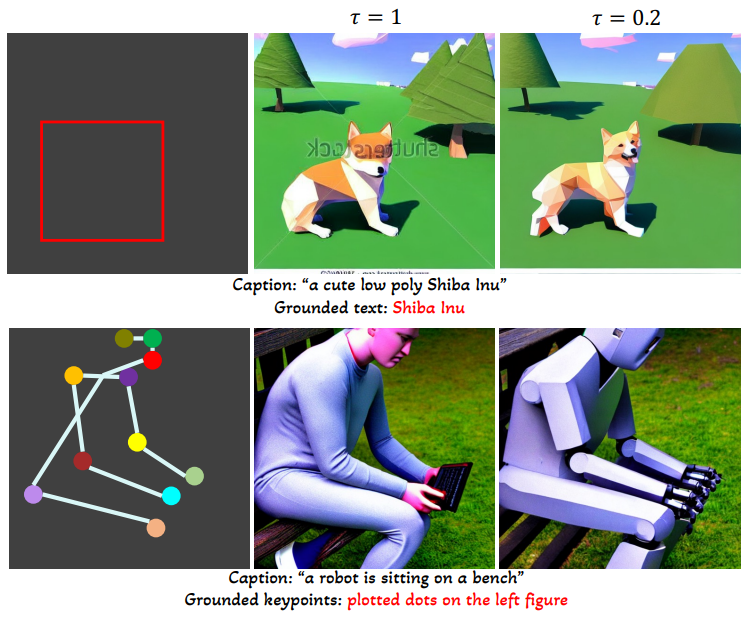
구체적으로, $\tau \in [0, 1]$로 나눈 2단계 inference 절차를 고려한다. 총 $T$ step이 있는 diffusion process의 경우 처음 $\tau \times T$ step에서 $\beta$를 1로 설정하고 나머지 $(1−\tau) \times T$ step에서 $\beta$를 0으로 설정할 수 있다.
\[\begin{equation} \beta = \begin{cases} 1, & t \le \tau \times T \quad \textrm{(Grounded inference stage)} \\ 0, & t > \tau \times T \quad \textrm{(Standard inference stage)} \end{cases} \end{equation}\]Scheduled sampling의 주요 이점은 대략적인 개념 위치와 윤곽이 초기 step에서 결정되고 이후 step에서 세밀한 디테일이 결정되기 때문에 시각적 품질이 향상된다는 것이다. 또한 한 도메인에서 학습된 모델을 다른 도메인으로 확장할 수 있다.
Experiments
1. Closed-set Grounded Text-to-Image Generation
- Grounding instruction:
- COCO2014D: Detection Data
- COCO2014CD: Detection + Caption Data
- COCO2014G: Grounding Data
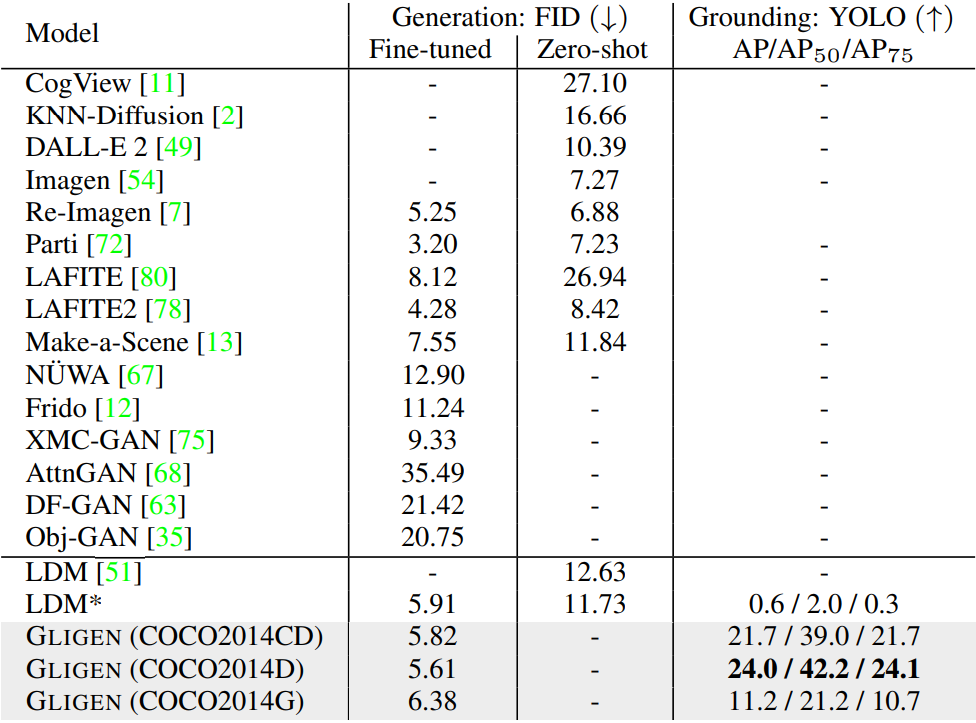
다음은 COCO2014 val-set에서의 이미지 품질과 layout 일치성을 평가한 표이다.
다음은 COCO2017 val-set에서의 이미지 품질과 layout 일치성을 평가한 표이다.
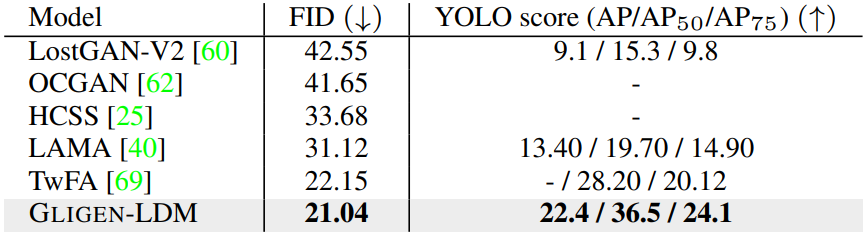
다음은 COCO2017 (왼쪽)과 LVIS (오른쪽) 데이터셋에서 이미지 품질과 grounding 품질을 비교한 그래프이다.
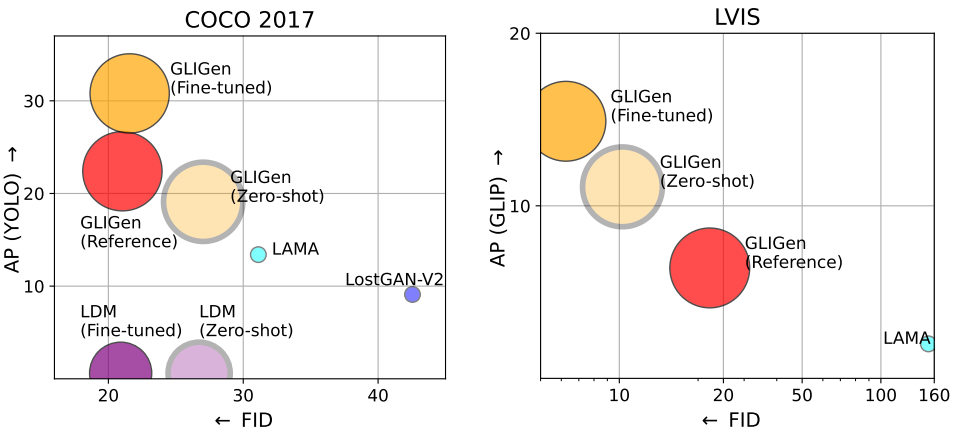
2. Open-set Grounded Text-to-Image Generation
다음은 먼저 COCO (COCO2014CD)의 grounding 주석으로만 학습된 GLIGEN을 가져와 COCO 카테고리를 넘어 grounded entity를 생성할 수 있는지 여부를 평가한 결과이다.

본 논문의 모델은 COCO의 localization 주석을 사용하여 학습된 경우에도 현실 개념으로 일반화할 수 있다.
다음은 LVIS validation set에서 GLIP-score를 측정한 표이다.
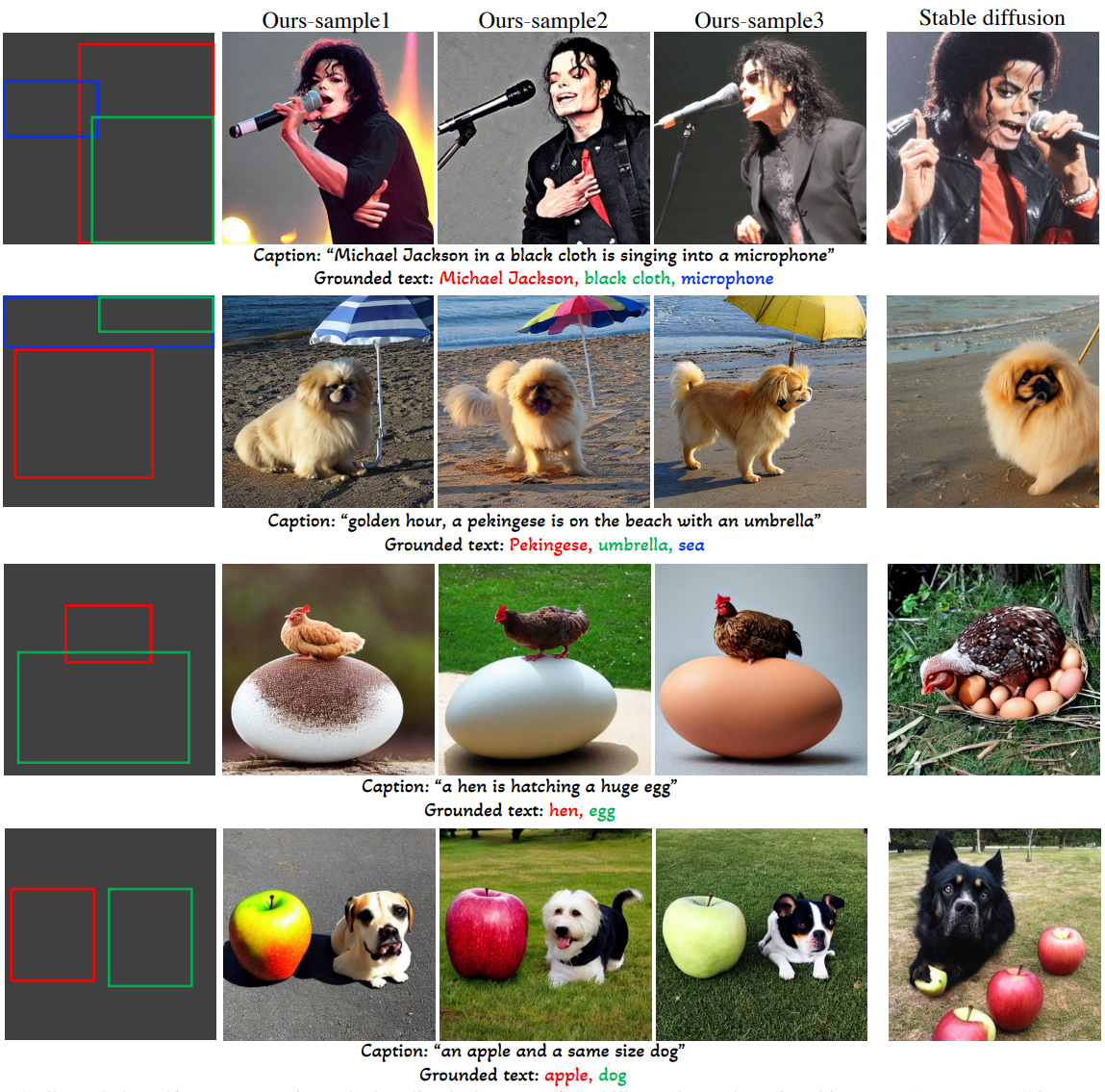
다음은 grounded text-to-image 생성의 예시들이다.
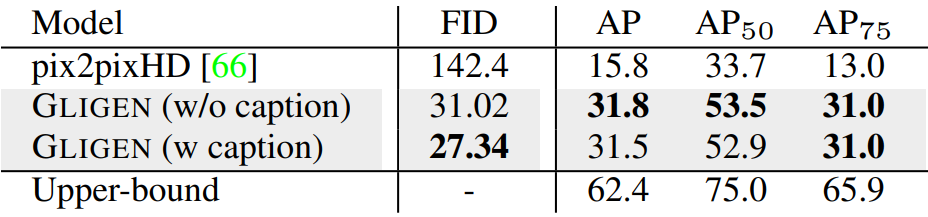
3. Inpainting Comparison
다음은 inpainting 예시이다.

다음은 다양한 크기의 개체에 대한 inpainting 결과 (YOLO AP)를 나타낸 표이다.
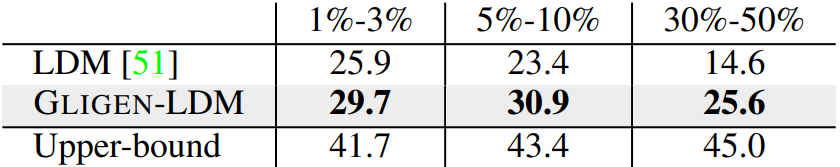
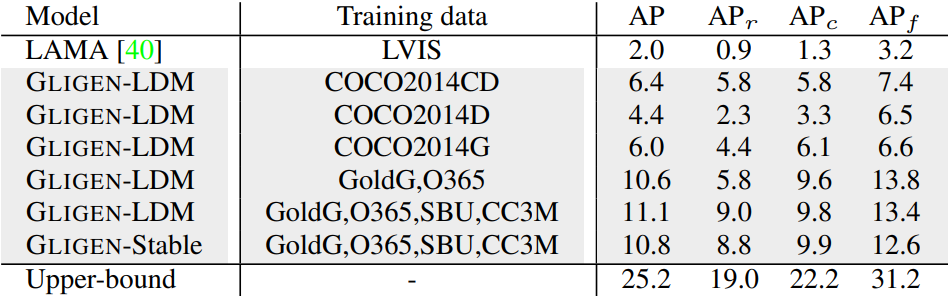
4. Keypoints Grounding
다음은 keypoints grounding의 예시이다.

다음은 COCO2017 validation set에서 Human Keypoints으로 컨디셔닝한 결과를 평가한 것이다. Upper-bound는 256$\times$256으로 스케일링된 실제 이미지로 계산한 것이다.
5. Image Grounding
다음은 image grounding의 예시로, 윗줄은 이미지로 grounding한 것이고 아랫줄은 텍스트와 이미지로 grounding한 것이다.

윗줄은 visual feature가 자동차의 스타일과 모양과 같이 언어로 설명하기 어려운 디테일을 보완할 수 있음을 보여준다. 아랫줄은 스타일/톤 전송을 사용한 텍스트 기반 생성을 보여준다.
다음은 image grounded inpainting의 예시이다.

6. Scheduled Sampling
다음은 Stable Diffusion을 기반으로 한 모델에서 scheduled sampling의 이점을 보여주는 예시이다.