[논문리뷰] Scaling up GANs for Text-to-Image Synthesis (GigaGAN)
CVPR 2023. [Paper] [Page] [Github]
Minguk Kang, Jun-Yan Zhu, Richard Zhang, Jaesik Park, Eli Shechtman, Sylvain Paris, Taesung Park
POSTECH | Carnegie Mellon University | Adobe Research
9 Mar 2023

Introduction
최근 발표된 DALL·E 2, Imagen, Parti, Stable Diffusion과 같은 모델들은 이미지 생성의 새 시대를 열었으며, 전례없는 수준의 이미지 품질과 모델 유연성을 달성하였다. 현재 지배적인 패러다임이 된 diffusion model과 autoregressive model은 둘 다 반복적인 inference를 기반으로 한다. 반복적인 방법은 간단한 목적함수를 사용한 안정적인 학습을 가능하게 하지만 inference 중에 높은 계산 비용이 필요하므로, 이는 양날의 검이다.
반면에 GAN은 단일 forward pass로 이미지를 생성하므로 효율적이다. GAN이 생성 모델링의 이전 시대를 지배했지만, GAN을 확장하는 것은 불안정한 학습 과정에 따른 네트워크 아키텍처와 학습에 대한 고려가 필요하다. 이와 같이 GAN은 단일 또는 다중 개체 클래스를 모델링하는 데 탁월했지만 복잡한 데이터 셋으로 확장하는 것은 여전히 어려운 일이었다. 결과적으로 초대형 모델, 데이터, 컴퓨팅 리소스는 이제 diffusion model과 autoregressive model 전용이다. 본 논문에서 저자들은 GAN이 계속 확장되어 그러한 리소스로부터 잠재적으로 이익을 얻을 수 있는지, 아니면 정체되어 있는지, 추가 확장을 방해하는 요소는 무엇이며 이러한 장벽을 극복할 수 있는지 묻는다.
저자들은 먼저 StyleGAN2로 실험하고 단순히 backbone을 확장하는 것이 불안정한 학습을 유발한다는 것을 관찰하였다. 저자들은 몇 가지 핵심 문제를 식별하고 모델 용량을 늘리면서 학습을 안정화할 수 있는 기술을 제안한다. 첫째, filter bank를 유지하고 샘플별 선형 결합을 취함으로써 generator의 용량을 효과적으로 확장한다. 또한 diffusion에서 일반적으로 사용되는 몇 가지 테크닉을 채택하고 GAN에 유사한 이점을 제공하는지 확인한다. 예를 들어 self-attention (이미지 전용)과 cross-attention (이미지-텍스트)을 convolutional layer 사이에 끼워넣으면 성능이 향상된다.
또한 text-to-image alignment와 생성된 출력의 저주파 디테일를 개선하는 새로운 방식을 찾아 multi-scale 학습을 다시 도입한다. Multi-scale 학습을 통해 GAN 기반 generator는 저해상도 블록의 파라미터를 보다 효과적으로 사용할 수 있으므로 text-to-image alignment와 이미지 품질이 향상된다. 신중한 조정 후 LAION2B-en과 같은 대규모 데이터셋에서 10억 파라미터 GAN (GigaGAN)의 안정적이고 확장 가능한 학습을 달성한다.
또한, 본 논문의 방법은 multi-stage 접근 방식을 사용한다. 먼저 64$\times$64에서 생성한 다음 512$\times$512로 upsampling한다. 이 두 네트워크는 모듈식이며 plug-and-play 방식으로 사용할 수 있을 만큼 견고하다. 학습 시 diffusion 이미지를 본 적이 없음에도 불구하고 텍스트로 컨디셔닝된 GAN 기반 upsampling 네트워크가 DALL·E 2와 같은 기본 diffusion model을 위한 효율적이고 고품질의 upsampler로 사용될 수 있음을 보여준다.
이러한 발전을 통해 GigaGAN은 StyleGAN2보다 36배 더 크고 StyleGAN-XL과 XMC-GAN보다 6배 더 크며, 이전 GAN을 훨씬 능가할 수 있다. 본 논문의 10억 파라미터 수는 Imagen (30억), DALL·E 2 (55억), Parti (200억)와 같은 가장 큰 최신 합성 모델보다 여전히 낮지만 모델 크기에 관한 품질 포화는 아직 관찰되지 않았다.
또한 GigaGAN은 diffusion model과 autoregressive model에 비해 세 가지 주요한 실용적인 이점이 있다.
- 0.13초 만에 512px 이미지를 생성하여 훨씬 더 빠르다.
- 3.66초 만에 4k 해상도의 초고해상도 이미지를 합성할 수 있다.
- 스타일 믹싱, 프롬프트 보간, 프롬프트 믹싱과 같이 잘 연구된 제어 가능한 이미지 합성 어플리케이션에 적합한 제어 가능한 latent vector space가 부여된다.
Method
Latent code $z \sim \mathcal{N}(0,1) \in \mathbb{R}^{128}$와 텍스트 컨디셔닝 신호 $c$가 주어지면 이미지 $x \in \mathbb{R}^{H \times W \times 3}$을 예측하는 generator $G(z, c)$를 학습한다. Discriminator $D(x, c)$를 사용하여 학습 데이터베이스 $\mathcal{D}$의 샘플과의 비교를 통해 생성된 이미지의 현실성을 판단한다.
GAN들이 단일 및 다중 카테고리 데이터셋들에서 현실적인 이미지를 성공적으로 생성하지만, 인터넷 이미지에서의 개방형 텍스트로 컨디셔닝된 합성은 어렵다. 저자들은 이 제한이 convolutional layer에 대한 의존에서 비롯된다고 가정한다. 즉, 동일한 convolution filter는 이미지의 모든 위치에 걸쳐 모든 텍스트 컨디셔닝에 대한 일반 이미지 합성 함수를 모델링하는 데 어려움을 겪는다. 이러한 관점에서 저자들은 입력 컨디셔닝을 기반으로 convolution filter를 동적으로 선택하고 attention mechanism을 통해 long-range dependence를 캡처하여 paramterization에 더 많은 표현력을 주입하려고 한다.
1. Modeling complex contextual interaction
다음은 GigaGAN의 고용량 text-to-image generator를 묘사한 그림이다.
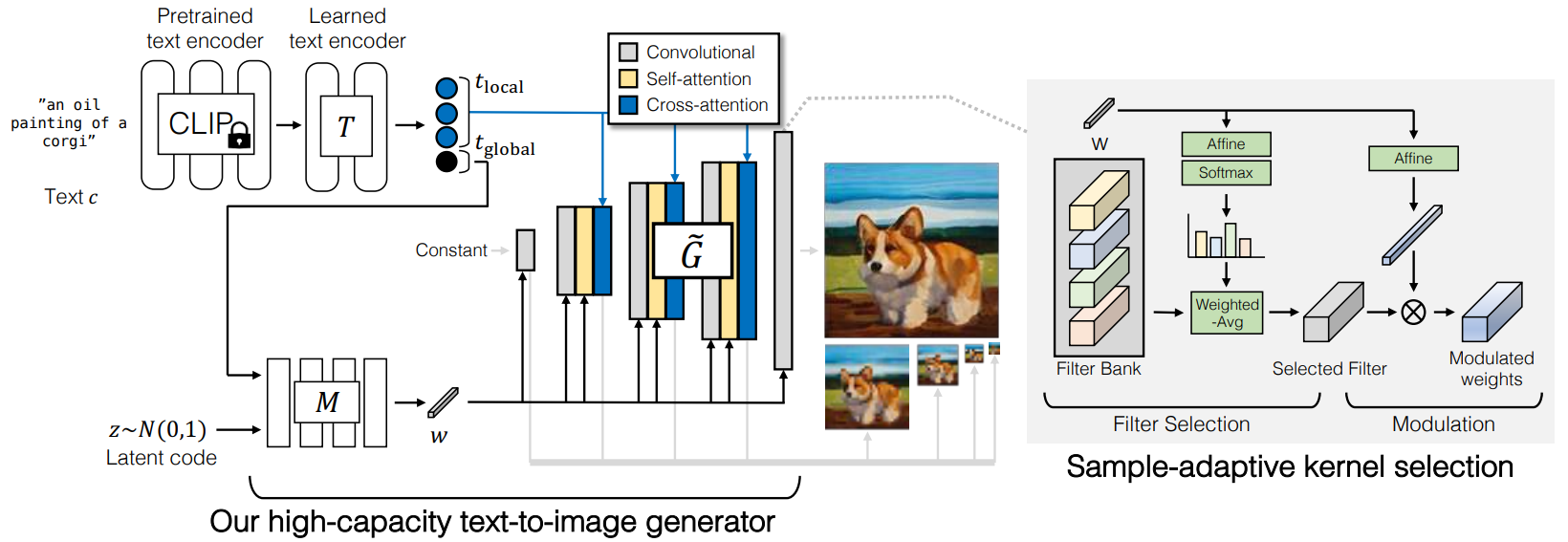
Baseline StyleGAN generator
본 논문의 아키텍처는 두 개의 네트워크 $G = \tilde{G} \circ M$으로 구성된 StyleGAN2의 조건부 버전을 기반으로 한다. 매핑 네트워크 $w = M(z, c)$는 입력을 스타일 벡터 $w$로 매핑하고 합성 네트워크 $\tilde{G}(w)$ 내부의 일련의 upsampling convolutional layer를 modulate하여 학습된 상수 텐서를 출력 이미지 $x$에 매핑한다. Convolution 모든 출력 픽셀을 생성하는 주요 엔진이며 $w$ 벡터는 모델 컨디셔닝에 대한 유일한 정보 소스이다.
Sample-adaptive kernel selection
인터넷 이미지의 매우 다양한 분포를 처리하기 위해 convolution kernel의 용량을 늘리는 것을 목표로 한다. 그러나 convolutional layer의 너비를 늘리는 것은 모든 위치에서 동일한 연산이 반복되기 때문에 너무 까다로워진다.
저자들은 convolution kernel의 표현력을 향상시키기 위한 효율적인 방법으로 텍스트 컨디셔닝을 기반으로 즉석에서 convolution kernel을 생성하는 것을 제안한다. 각 layer에서 feature \(f \in \mathbb{R}^{C_\textrm{in}}\)를 취하는 대신 $N$개의 filter들의 bank \(\{K_i \in \mathbb{R}^{C_\textrm{in} \times C_\textrm{out} \times K \times K}\}_{i=1}^N\)를 인스턴스화한다. 그런 다음 스타일 벡터 $w \in \mathbb{R}^d$는 affine layer \([W_\textrm{filter}, b_\textrm{filter}] \in \mathbb{R}\)를 통과하여 filter 전체에 평균화할 가중치의 집합을 예측하여 집계된 필터 $K \in \mathbb{R}^{C_\textrm{in} \times C_\textrm{out} \times K \times K}$를 생성한다.
\[\begin{equation} K = \sum_{i=1}^N K_i \cdot \textrm{softmax} (W_\textrm{filter}^\top w + b_\textrm{filter}) \end{equation}\]그런 다음 가중치 modulation을 위한 두번째 affine layer $[W_\textrm{mod}, b_\textrm{mod}] \in \mathbb{R}^{(d+1) \times C_m}$와 함께 필터는 StyleGAN2의 일반적인 convolution 파이프라인에 사용된다.
\[\begin{equation} g_\textrm{adaconv} (f, w) = ((W_\textrm{mod}^\top w + b_\textrm{mod}) \otimes K) \ast f \end{equation}\]$\otimes$와 $\ast$는 각각 modulation과 convolution을 의미한다.
높은 레벨에서 softmax 기반 가중치는 입력 컨디셔닝을 기반으로 하는 미분 가능한 filter 선택 프로세스로 볼 수 있다. 또한 filter 선택 프로세스는 각 레이어에서 한 번만 수행되므로 선택 프로세스가 실제 컨볼루션보다 훨씬 빠르고, 계산 복잡도와 해상도가 분리된다. 본 논문의 방법은 convolution filter가 샘플마다 동적으로 변경된다는 점에서 dynamic convolution과 정신을 공유하지만 더 큰 filter bank를 명시적으로 인스턴스화하고 StyleGAN의 $w$-공간에 따라 별도의 경로를 기반으로 가중치를 선택한다는 점에서 다르다.
Interleaving attention with convolution
Convolutional filter는 receptive field 내에서 작동하기 때문에 이미지의 먼 부분과 관련하여 자체적으로 컨텍스트화할 수 없다. 이러한 장거리 관계를 통합하는 한 가지 방법은 attention layer $g_\textrm{attention}$을 사용하는 것이다. 최근의 diffusion 기반 모델은 attention mechanism을 일반적으로 채택했지만 StyleGAN 아키텍처는 BigGAN, GANformer, ViTGAN과 같은 주목할만한 예외를 제외하고는 주로 convolutional하다.
저자들은 attention layer와 convolutional backbone을 통합하여 StyleGAN의 성능을 향상시키는 것을 목표로 한다. 그러나 단순히 StyleGAN에 attention layer를 추가하는 것은 종종 학습 붕괴를 초래하는데, 아마도 dotproduct self-attention이 Lipschitz가 아니기 때문일 것이다. Discriminator의 Lipschitz 연속성이 안정적인 학습에 중요한 역할을 했기 때문에 ViTGAN과 유사하게 Lipschitz 연속성을 촉진하기 위해 attention logit으로 내적 대신 L2 distance를 사용한다.
성능을 더 향상시키려면 균일화된 learning rate나 단위 정규 분포의 가중치 초기화와 같은 StyleGAN의 아키텍처 세부 사항을 일치시키는 것이 중요하다. 초기화 시 단위 정규 분포와 대략 일치하도록 L2 distance logit의 스케일을 줄이고 attention layer의 residual gain을 줄인다. Key와 query 행렬을 연결하고 weight decay를 적용하여 안정성을 더욱 향상시킨다.
합성 네트워크 $\tilde{G}$에서 attention layer는 스타일 벡터 $w$를 추가 토큰으로 활용하여 각 convolutional block 사이에 끼워진다. 각 attention block에서 개별 단어 임베딩에 attention을 적용하기 위해 별도의 cross-attention mechanism $g_\textrm{cross-attention}$을 추가한다. 각 입력 feature 텐서를 query로 사용하고 텍스트 임베딩을 attention mechanism의 key와 value로 사용한다.
2. Generator design
Text and latent-code conditioning
먼저 프롬프트에서 임베딩된 텍스트를 추출한다. 이전 연구에서는 강력한 언어 모델을 활용하는 것이 강력한 결과를 생성하는 데 필수적이라는 것을 보여주었다. 이를 위해 입력 프롬프트를 $C = 77$로 토큰화하여 컨디셔닝 벡터 $c \in \mathbb{R}^{C \times 1024}$를 생성하고 고정된 CLIP feature extractor의 두 번째 layer에서 feature를 가져온다. 추가적인 유연성을 허용하기 위해, 단어 임베딩을 MLP 기반 매핑 네트워크로 전달하기 전에 추가 attention layer $T$를 적용한다. 이로 인해 텍스트 임베딩 \(t = T (\mathcal{E}_\textrm{txt} (c)) \in \mathbb{R}^{C \times 1024}\)가 생긴다. $t$의 각 원소 $t_i$는 문장에서 $i$번째 단어의 임베딩을 캡처한다. 이를 \(t_\textrm{local} = t_{\{1:C\} \backslash \textrm{EOT}} \in \mathbb{R}^{(C-1) \times 1024}\)이라 부른다. $t$의 EOT (end of text) 원소는 글로벌한 정보를 집계하므로 $t_\textrm{global} \in \mathbb{R}^{1024}$이라 부른다. 이 global text descriptor를 latent code $z$와 함께 MLP 매핑 네트워크에 넣어 스타일 $w$를 추출한다.
\[\begin{equation} (t_\textrm{local}, t_\textrm{global}) = T (\mathcal{E}_\textrm{txt} (c)) \\ w = M (z, t_\textrm{global}) \end{equation}\]원래 StyleGAN과 다르게 텍스트 기반 스타일 코드 $w$로 합성 네트워크 $\tilde{G}$를 modulate하면서 단어 임베딩 $t_\textrm{local}$를 cross-attention을 위한 feature로 사용한다.
\[\begin{equation} x = \tilde{G} (w, t_\textrm{local}) \end{equation}\]이전 연구들과 비슷하게 cross-attention으로 text-to-image alignment가 시각적으로 개선된다.
Synthesis network
본 논문의 합성 네트워크는 일련의 upsampling convolutional layer로 구성되며, 각 layer는 adaptive kernel selection으로 향상되고 attention layer가 이어진다.
\[\begin{equation} f_{l+1} = g_\textrm{xa}^l (g_\textrm{attn}^l (g_\textrm{adaconv}^l (f_l, w), w), t_\textrm{local}) \end{equation}\]여기서 $g_\textrm{xa}^l$, $g_\textrm{attn}^l$, $g_\textrm{adaconv}^l$은 각각 cross-attention, self-attention, weight modulation layer의 $l$번째 layer이다.
저자들은 각 layer에 더 많은 block을 추가하여 네트워크의 깊이를 높이는 것이 유익하다는 것을 알아냈다. 또한 generator는 MSG-GAN이나 AnycostGAN과 유사하게 최고 해상도의 단일 이미지 대신 $L = 5$ 레벨의 multi-scale 이미지 피라미드를 출력한다. 이 피라미드를 \(\{x_i\}_{i=0}^{L-1} = \{x_0, \cdots, x_4\}\), 공간적 해상도를 \(\{S_i\}_{i=0}^{L-1} = \{64, 32, 16, 8, 4\}\)라 부른다. Base level $x_0$는 출력 이미지 $x$dl다. 피라미드의 각 이미지는 GAN loss를 계산하는 데 독립적으로 사용된다. StyleGAN-XL의 결과를 따르며, 스타일 혼합과 경로 길이 정규화를 사용하지 않는다.
3. Discriminator design
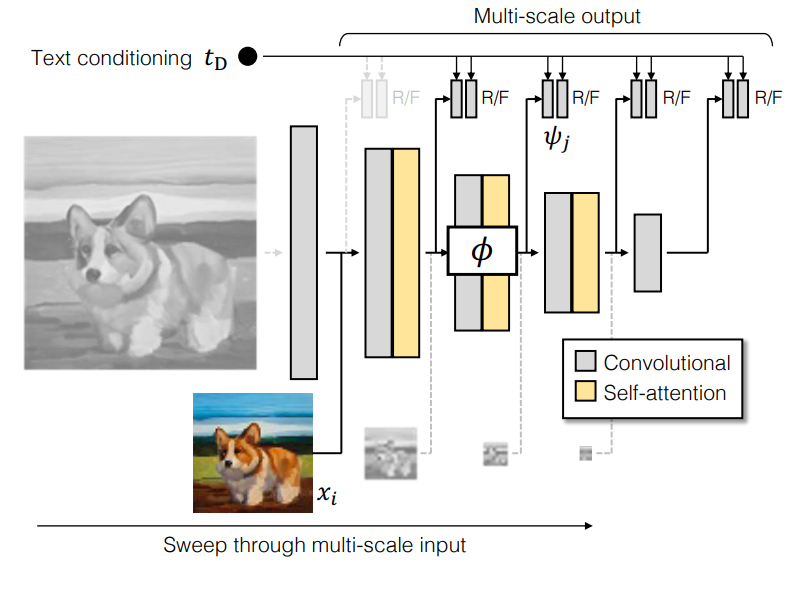
위 그림에서 볼 수 있듯이 discriminator는 함수 $t_D$로 텍스트를 처리하고 함수 $\phi$로 이미지를 처리하기 위한 별도의 분기로 구성된다. 진짜/가짜에 대한 예측은 함수 $\psi$를 사용하여 두 분기의 feature을 비교하여 이루어진다. 본 논문은 여러 scale에서 예측을 수행하는 새로운 방법을 소개한다. 마지막으로 추가 CLIP loss와 Vision-Aided GAN loss를 사용하여 안정성을 개선한다.
Text conditioning
먼저 컨디셔닝을 discriminator에 통합하기 위해 텍스트 $c$에서 text descriptor $t_D$를 추출한다. Generator와 유사하게 CLIP과 같은 사전 학습된 텍스트 인코더를 적용한 다음 몇 가지 학습 가능한 attention layer를 적용한다. 이 경우 global descriptor만 사용한다.
Multiscale image processing
저자들은 제공된 프롬프트와 관계없이 작은 동적 범위를 사용하여 generator의 초기 저해상도 layer가 비활성화되는 것을 관찰했다. StyleGAN2도 이 현상을 관찰하여 모델 크기가 증가함에 따라 네트워크가 고해상도 레이어에 의존한다는 결론을 내린다. 복잡한 구조 정보가 포함된 저주파에서의 성능 회복이 중요하므로 여러 scale에 걸쳐 학습 신호를 제공하도록 모델 구조를 재설계한다.
Generator가 피라미드 base에 전체 이미지 $x_0$가 있는 피라미드 \(\{x_i\}_{i=0}^{L-1}\)를 생성한다는 것을 기억하자. MSG-GAN은 전체 피라미드에 대한 예측을 한 번에 수행하여 scale에 걸쳐 일관성을 유지함으로써 성능을 향상시킨다. 그러나 본 논문의 large-scale 세팅에서는 generator가 초기 저해상도 출력을 조정하는 것을 제한하므로 안정성이 손상된다.
대신 피라미드의 각 레벨을 독립적으로 처리한다. 각 레벨 $x_i$는 여러 scale $i < j \le L$에서 진짜/가짜 예측을 만든다. 예를 들어 전체 $x_0$은 5개의 scale에서 예측하고 다음 레벨 $x_1$은 4개의 scale에서 예측한다. 전체적으로, discriminator는 $L(L−1)/2$개의 예측을 생성하여 여러 scale에서 여러 생성을 supervise한다.
서로 다른 스케일에서 feature를 추출하기 위해 feature extractor $\phi_{i \rightarrow j} : \mathbb{R}^{X_i \times X_i \times 3} \rightarrow \mathbb{R}^{X_j^D \times X_j^D \times C_j}$를 정의한다. 실질적으로 각 sub-network $\phi_{i \rightarrow j}$는 전체 $\phi \triangleq \phi_{0 \rightarrow L}$의 부분 집합이며, $i > 0$은 late entry를 나타내고 $j < L$은 early exti을 나타낸다. $\phi$의 각 레이어는 self-attention으로 구성되고 뒤이어 stride가 2인 convolution이 뒤따른다. 마지막 layer는 공간 범위를 1$\times$1 텐서로 평탄화한다. 이것은 \(\{X_j^D\} = \{32, 16, 8, 4, 1\}\)에서 출력 해상도를 생성한다. 이를 통해 피라미드의 저해상도 이미지를 중간 layer에 주입할 수 있다. 여러 레벨에서 공유 feature extractor를 사용하고 추가된 예측의 대부분이 낮은 해상도에서 이루어지기 때문에 증가된 계산 오버헤드를 관리할 수 있다.
Multi-scale input, multi-scale output adversarial loss
전체적으로, 학습 목적 함수는 discriminator가 컨디셔닝을 고려하도록 장려하기 위해 제안된 matching loss와 함께 discriminator loss로 구성된다.
\[\begin{equation} \mathcal{V}_\textrm{MS-I/O} (G, D) = \sum_{i=0}^{L-1} \sum_{j=1}^L \mathcal{V}_\textrm{GAN} (G_i, D_{ij}) + \mathcal{V}_\textrm{match} (G_i, D_{ij}) \end{equation}\]\(\mathcal{V}_\textrm{GAN}\)은 표준 GAN loss이다. Discriminator 출력을 계산하기 위해 text feature $t_D$를 사용하여 이미지 feature $\phi (x)$를 modulate하는 predictor $\psi$를 학습시킨다.
\[\begin{equation} D_{ij} (x, c) = \psi_j (\phi_{i \rightarrow j} (x_i), t_D) + \textrm{Conv}_{1 \times 1} (\phi_{i \rightarrow j} (x_i)) \end{equation}\]$\psi_j$는 4-layer 1$\times$1 modulated convolution으로 구현되며, \(\textrm{Conv}_{1 \times 1}\)을 skip connection으로 더해 unconditional한 예측 분기를 명시적으로 유지한다.
Matching-aware loss
\(\mathcal{V}_\textrm{GAN}\)은 이미지 $x$가 컨디셔닝 $c$와 얼마나 근접하게 일치하는지 뿐만 아니라 컨디셔닝에 관계없이 $x$가 얼마나 사실적으로 보이는지 측정한다. 그러나 초기 학습 중에 아티팩트가 명백할 때 discriminator는 컨디셔닝과 독립적인 결정을 내리는 데 크게 의존하고 나중에 컨디셔닝을 설명하는 것을 주저한다.
Discriminator가 컨디셔닝을 통합하도록 강제하기 위해 $x$를 임의의 독립적으로 샘플링된 조건 $\hat{c}$와 일치시키고 가짜 쌍으로 표시한다.
\[\begin{aligned} \mathcal{V}_\textrm{match} = \mathbb{E}_{x, c, \hat{c}} [ & \log (1 + \exp (D (x, \hat{c}))) \\ &+ \log (1 + \exp (D(G(c)), \hat{c}))] \end{aligned}\]$(x, c)$와 $\hat{c}$는 $p_\textrm{data}$에서 독립적으로 샘플링된다. 이 loss는 이전에 text-to-image GAN 연구에서 연구되었지만 저자들은 $G$에서 생성된 이미지와 실제 이미지 $x$에 Matching-aware loss를 적용하면 성능이 확실히 향상된다는 것을 발견했다.
CLIP contrastive loss
추가로 사전 학습된 기존 모델을 loss function으로 활용한다. 특히, 사전 학습된 CLIP 이미지 및 텍스트 인코더인 \(\mathcal{E}_\textrm{img}\) 및 \(\mathcal{E}_\textrm{txt}\)에 의해 원래 학습에 사용된 contrastive cross-entropy loss에서 식별 가능한 출력을 생성하도록 generator를 강제한다.
\[\begin{equation} \mathcal{L}_\textrm{CLIP} = \mathbb{E}_{\{c_n\}} \bigg[ - \log \frac{\exp (\mathcal{E}_\textrm{img} (G (c_0))^\top \mathcal{E}_\textrm{txt} (c_0))}{\sum_n \exp (\mathcal{E}_\textrm{img} (G (c_0))^\top \mathcal{E}_\textrm{txt} (c_n))} \bigg] \end{equation}\]\(\{c_n\} = \{c_0, \cdots\}\)는 학습 데이터에서 샘플링된 캡션이다.
Vision-aided adversarial loss
마지막으로, CLIP model을 backbone으로 사용한 Vision-Aided GAN으로 알려진 추가 discriminator를 사용한다. CLIP 이미지 인코더를 freeze하고, 중간 layer에서 feature를 추출하고, 실제/가짜 예측을 하기 위한 3$\times$3 conv layer가 있는 간단한 네트워크를 통해 feature를 처리한다. 또한 modulation을 통해 컨디셔닝을 통합한다. 학습을 안정화하기 위해 Projected GAN에서 제안한 대로 고정된 random projection layer도 추가한다. 이를 $L_\textrm{Vision} (G)$라고 한다.
최종 목적 함수는 다음과 같다.
\[\begin{equation} \mathcal{V} (G, D) = \mathcal{V}_\textrm{MS-I/O} (G, D) + \mathcal{L}_\textrm{CLIP} (G) + \mathcal{L}_\textrm{Vision} (G) \end{equation}\]4. GAN-based upsampler
또한 GigaGAN 프레임워크는 기본 GigaGAN generator의 출력을 upsampling하여 512px 또는 2k 해상도에서 고해상도 이미지를 얻을 수 있는 text-conditioned super-resolution model을 학습하도록 쉽게 확장할 수 있다. 별도의 두 단계에서 파이프라인을 학습시킴으로써 동일한 계산 리소스 내에서 더 높은 용량의 64px base model을 감당할 수 있다.
Upsampler에서 합성 네트워크는 비대칭 U-Net 아키텍처로 재정렬되어 64px 입력을 3개의 downsampling residual block을 통해 처리한 다음 attention layer가 있는 6개의 upsampling residual block을 통해 512px 이미지를 생성한다. CoModGAN과 유사하게 동일한 해상도에 skip connection이 존재한다. 이 모델은 기본 모델과 동일한 loss와 ground-truth 고해상도 이미지에 대한 LPIPS Perceptual Loss로 학습된다. Vision-aided GAN은 upsampler에 사용되지 않는다. 학습 및 inference 시간 동안 실제 이미지와 GAN 생성 이미지 사이의 간격을 줄이기 위해 적당한 Gaussian noise augmentation을 적용한다.
GigaGAN 프레임워크는 고해상도에서 base model만큼 많은 샘플링 단계를 감당할 수 없는 diffusion 기반 모델에 비해 super-resolution task에 특히 효과적이다. LPIPS regression loss도 안정적인 학습 신호를 제공한다. 저자들은 GAN upsampler가 다른 생성 모델의 super-resolution 단계를 대체할 수 있다고 생각한다.
Experiments
- 데이터셋: LAION2B-en, COYO-700M
- 사전 학습된 텍스트 인코더: CLIP ViT-L/14
- CLIP score 계산: OpenCLIP ViT-G/14
1. Effectiveness of proposed components
다음은 GigaGAN의 각 요소의 효과를 확인하기 위해 64px text-to-image 합성에 대한 ablation study 결과를 나타낸 표이다.
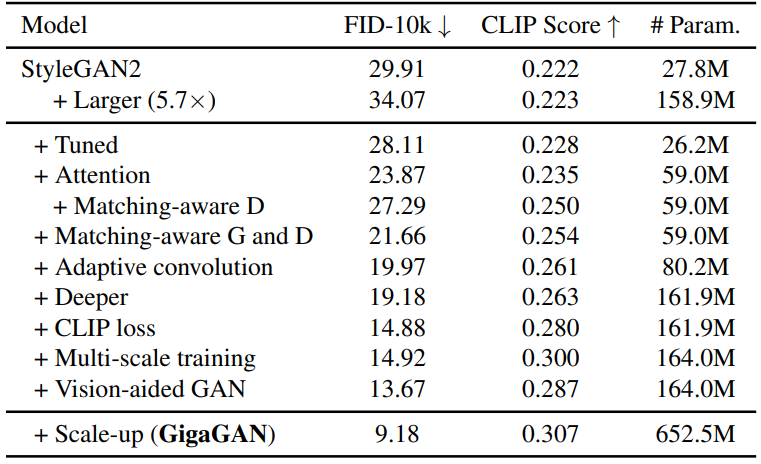
각 요소의 효과를 평가하기 위해 텍스트 컨디셔닝을 위해 수정된 버전의 StyleGAN으로 시작한다. 네트워크 폭을 늘려도 만족스러운 개선이 보이지는 않지만 요소를 추가할 때마다 지표가 계속 개선된다. 마지막으로 네트워크 폭을 늘리고 학습을 확장하여 최종 모델에 도달한다. 모든 ablation 모델은 Scale-up 행을 제외하고 배치 크기 256에서 100k iteration에 대해 학습되며, Scale-up 행은 배치 크기가 더 키우고 1350k iteration에 대해 학습된다. CLIP score는 CLIP ViT-B/32를 사용하여 계산되었다.
2. Text-to-Image synthesis
다음은 최근 text-to-image 모델과 비교한 표이다.
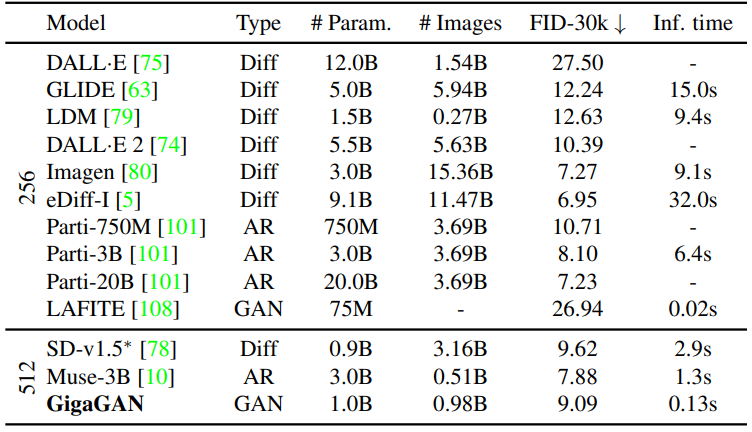
GigaGAN은 DALL·E 2, Stable Diffusion, and Parti-750M보다 낮은 FID를 기록하였다. 본 논문의 모델은 기존 모델보다 실제 이미지의 feature 분포와 더 잘 일치하도록 최적화할 수 있지만 생성된 이미지의 품질이 반드시 더 좋은 것은 아니다. 저자들은 이것이 COCO2014 데이터셋에서 zero-shot FID의 코너 케이스를 나타낼 수 있음을 인정하고 text-to-image model을 개선하기 위해 더 나은 평가 metric에 대한 추가 연구가 필요하다고 제안한다.
그럼에도 불구하고 저자들은 GigaGAN이 임의의 텍스트 프롬프트에서 유망한 이미지를 합성할 수 있는 최초의 GAN 모델이며 다른 text-to-image model과 경쟁할 수 있는 zero-shot FID를 보여준다는 점을 강조한다.
3. Comparison with distilled diffusion models
다음은 distilled diffusion model과 비교한 표이다.
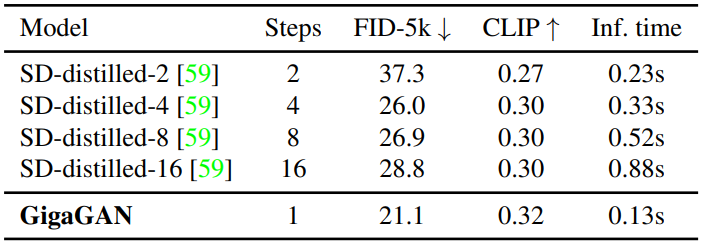
GigaGAN은 더 나은 FID와 CLIP score를 보여주면서 distilled Stable Diffusion보다 더 빠르다.
4. Super-resolution for large-scale image synthesis
다음은 1만 개의 랜덤한 LAION 샘플에 대한 text-conditioned 128$\rightarrow$1024 super-resolution을 비교한 표이다.

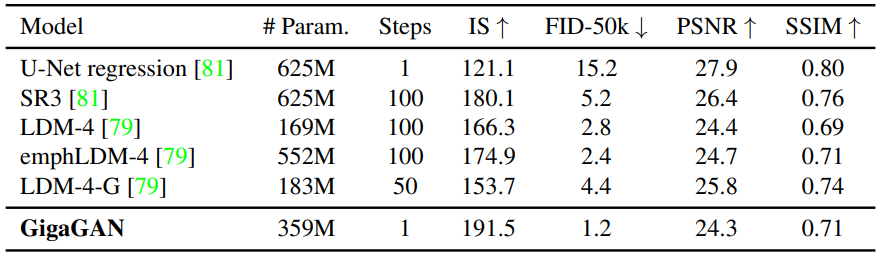
다음은 ImageNet에서 unconditional 64$\rightarrow$256 super-resolution을 비교한 표이다.
다음은 text-conditioned 128$\rightarrow$1024 super-resolution model로 upsampling을 한 후, 모델을 재적용하여 4K까지 upsampling한 예시이다. 텍스트 컨디셔닝은 각각 “Portrait of a colored iguana dressed in a hoodie”(위)와 “A dog sitting in front of a mini tipi tent”(아래)이다.


5. Controllable image synthesis
StyleGAN은 $\mathcal{W}$-space라고 하는 이미지 조작에 유용한 선형 latent space를 보유하는 것으로 알려져 있다. 마찬가지로 스타일 벡터 $w$를 사용하여 coarse하고 fine한 style swapping을 수행한다.

StyleGAN의 $\mathcal{W}$-space과 유사하게, 위 그림은 GigaGAN이 disentangled $\mathcal{W}$-space을 유지함을 보여주며 StyleGAN의 기존 latent 조작 테크닉이 GigaGAN으로 이전될 수 있음을 시사한다. 또한, GigaGAN은 $\mathcal{W}$ 이전에 텍스트 임베딩 $t = [t_\textrm{local}, t_\textrm{global}]$의 또 다른 latent space를 가지고 있으며, 저자들은 $t$의 이미지 합성 잠재력을 연구하였다.

위 그림에서는 텍스트 입력을 통해 disentangle한 스타일 조작을 제어할 수 있음을 보여준다. 서로 다른 프롬프트를 사용하여 텍스트 임베딩 $t$와 스타일 코드 $w$를 계산하고 generator의 다른 layer에 적용할 수 있다. 이러한 방식으로 coarse고 fine한 style disentanglement뿐만 아니라 style space에서 직관적인 프롬프트 기반 조작도 얻을 수 있다.
다음은 프롬프트 보간의 예시를 보여준다.

Limitations
본 논문의 실험은 GAN의 확장성에 대한 결정적인 답을 제공한다. 새로운 아키텍처는 text-to-image 합성을 가능하게 하는 모델 크기까지 확장할 수 있다. 그러나 결과의 시각적 품질은 아직 DALL·E 2와 같은 프로덕션 모델과 비교할 수 없다.

위 그림은 photorealism과 text-to-image alignment 측면에서 DALL·E 2와 비교할 때, DALL·E 2에서 사용된 것과 동일한 입력 프롬프트에 대하여 고품질 결과를 생성하지 못하는 몇 가지 사례를 보여준다.