[논문리뷰] GETMusic: Generating Any Music Tracks with a Unified Representation and Diffusion Framework
arXiv 2023. [Paper] [Page] [Github]
Ang Lv, Xu Tan, Peiling Lu, Wei Ye, Shikun Zhang, Jiang Bian, Rui Yan
Microsoft Research Asia | Renmin University of China | Peking University
18 May 2023
Introduction
심볼릭 음악 생성은 처음부터 타겟 악기 트랙을 생성하거나 사용자가 제공한 소스 트랙을 기반으로 생성하는 등 음악 구성에서 사용자를 도울 수 있는 음표 생성을 목표로 한다. 소스 트랙과 타겟 트랙 간의 다양하고 유연한 조합을 고려할 때 포괄적인 트랙 생성 작업을 처리할 수 있는 통합 모델이 필요하다. 심볼릭 음악 생성에 대한 현재 연구는 주로 특정 소스-타겟 조합에 대해 제안되며 채택된 음악 표현을 기반으로 하는 두 가지 주요 접근 방식인 시퀀스 기반 및 이미지 기반으로 분류할 수 있다. 그러나 두 접근 방식 모두 표현과 모델 아키텍처에 내재된 제약으로 인해 단일 모델 내에서 원하는 타겟 트랙을 생성하는 데 제한이 있다.
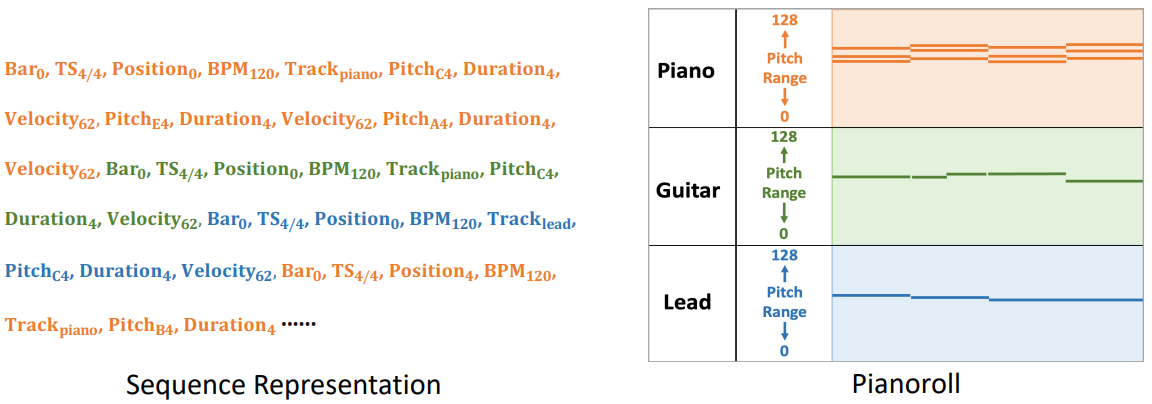
시퀀스 기반 연구들은 음악을 REMI, OctupleMIDI, ABC 표기법 등과 같은 discrete한 토큰 시퀀스로 나타낸다. 일반적으로 각 음표는 시작, pitch, duration, 악기와 같은 속성을 설명하기 위해 여러 토큰이 필요하다. 이러한 토큰은 시간순으로 정렬되어 서로 다른 트랙의 음이 인터리빙되며 일반적으로 autoregressive model에 의해 순차적으로 예측된다. 트랙의 인터리빙으로 인해 autoregressive model은 타겟 트랙에 속하는 토큰을 출력할 시기를 암시적으로 결정하고 다른 트랙에서 토큰 생성을 방지하므로 타겟 트랙 생성에 대한 제어가 제대로 이루어지지 않는다.
반면에 이미지 기반 연구들은 음악을 2D 이미지로 나타내며 피아노롤이 인기 있는 선택이다. 피아노롤은 음표를 가로선으로 묘사하는데 세로 위치는 pitch에 해당하고 길이는 길이를 나타낸다. 피아노롤은 악기의 전체 pitch 범위를 통합해야 하므로 크고 sparse한 이미지가 생성된다. Sparse한 고해상도 이미지를 생성하는 문제로 인해 대부분의 연구는 단일 트랙의 unconditional한 생성 또는 조건부 생성에 중점을 두었다.
임의의 트랙에 대한 유연하고 다양한 생성 요구를 해결하기 위해 본 논문은 GETScore라는 표현과 GETDiff라는 discrete diffusion model로 구성된 GETMusic이라는 통합 표현 및 diffusion 프레임워크를 제안한다. ‘GET’은 GEnerate music Tracks를 나타낸다. GETScore는 트랙이 세로로 쌓이고 시간이 지남에 따라 가로로 진행되는 2D 구조로 음악을 나타낸다. pitch와 duration 토큰으로 음표를 간결하게 나타낸다. 트랙의 동시 음표의 경우 pitch 토큰은 복합 pitch 토큰으로 결합된다. 토큰은 GETScore의 해당 트랙 및 시작점에 있다. 학습 중에 GETDiff는 트랙을 타겟 또는 소스로 무작위로 선택한다. GETDiff는 두 가지 프로세스로 구성된다. 전달 프로세스에서 타겟 트랙은 마스킹 토큰에 의해 손상되고 소스 트랙은 ground truth로 보존된다. Denoising process에서 GETDiff는 제공된 소스를 기반으로 마스킹된 타겟 토큰을 예측하는 방법을 학습한다. GETMusic의 공동 설계 표현 및 diffusion model은 이전 연구들에 비해 몇 가지 이점을 제공한다.
- GETScore의 개별 트랙과 non-autoregressive 예측 방식을 사용하여 GETMusic은 원하는 타겟 트랙의 생성을 처음부터 명시적으로 제어하거나 사용자가 제공한 소스 트랙을 컨디셔닝할 수 있다.
- GETScore는 컴팩트한 멀티트랙 음악 표현으로 모델 학습과 조화로운 생성을 촉진한다. 또한 pitch 토큰은 다성적 의존성 (즉, 동시 음표 간의 상호 의존성)을 보존하여 조화로운 생성을 촉진한다.
- 트랙별 생성 외에도 GETDiff의 마스크 및 denoising 메커니즘은 zero-shot 채우기 (즉, GETScore의 임의 위치에서 마스킹된 토큰 denoising)를 가능하게 하여 다양성과 창의성을 더욱 향상시킨다.
실험에서 GETMusic은 베이스, 드럼, 기타, 피아노, 현악기, 리드 멜로디의 6가지 악기를 지원하여 665개의 소스-타겟 조합을 생성한다. GETMusic은 리드 멜로디를 기반으로 5트랙 반주를 생성하거나 처음부터 6개 트랙을 모두 생성하는 등 특정 소스-타겟 조합에 대해 이전 연구들을 능가하며 다양한 소스-타겟 조합에 걸쳐 지속적으로 고품질 생성을 보여준다.
GETMusic
GETMusic의 두 가지 주요 구성 요소는 GETScore 표현과 diffusion model인 GETDiff이다.
1. GETScore
멀티 트랙 음악 모델링을 위한 효율적이고 효과적인 표현을 설계하여 소스 트랙과 타겟 트랙을 유연하게 지정하여 다양한 트랙 생성 작업의 토대를 마련하는 것이 목표이다. 이를 위해 저자들은 다음과 같은 몇 가지 노력을 기울였다.
첫째, 트랙의 인터리빙이 타겟 트랙 생성의 제어 가능성을 제한하기 때문에 트랙을 분리한다. 악보에서 영감을 받아 여러 악기 트랙을 수직으로 쌓고 각 트랙은 시간이 지남에 따라 수평으로 진행된다. 가로축은 세분화된 시간 단위로 나뉘며 각 단위는 1/4 박자를 나타낸다.
둘째, 이 2차원 구조 내에서 음악을 효율적으로 표현하고 피아노롤의 sparsity를 극복하는 것을 목표로 한다. 줄 길이를 사용하여 duration과 pitch의 세로 좌표를 나타내는 대신 토큰을 사용하여 두 속성을 모두 나타낸다. 동일한 트랙 내의 동시 음표 그룹의 경우 개별 pitch 토큰을 복합 pitch 토큰으로 결합한다. 동일한 트랙 내의 동시 음표가 동일한 duration을 갖도록 단순화했다.
셋째, 각 트랙 내에서 두 개의 행을 할당한다. 하나는 pitch 토큰용이고 다른 하나는 duration 토큰용이다. 쌍을 이룬 pitch-duration 토큰은 GETScore의 시작 시간을 기준으로 배치되며 토큰이 없는 위치는 패딩 토큰으로 채워진다.
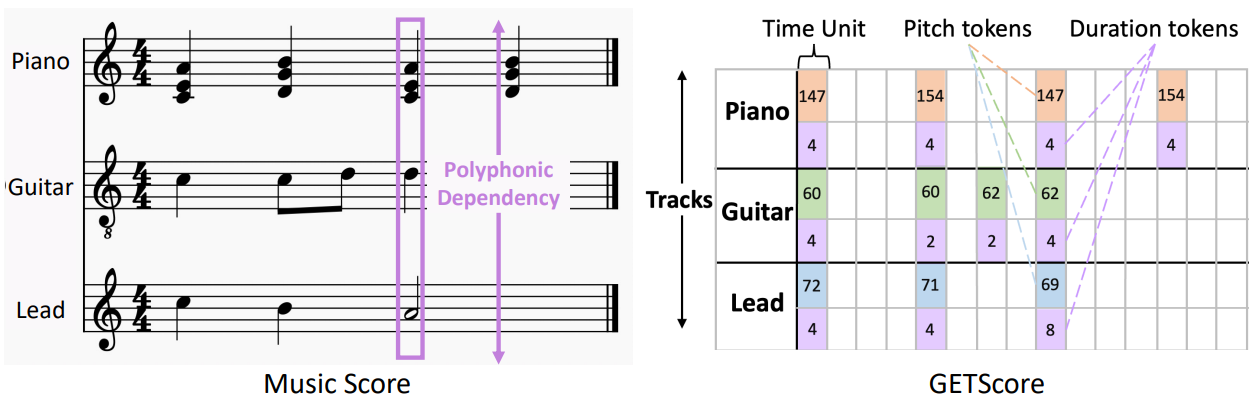
위 그림은 총 6개의 행으로 구성된 GETScore에 표시된 3트랙 음악의 예시이다. 특히 GETScore는 피아노 트랙의 동시 음표를 복합 pitch 토큰으로 결합한다. 그림의 숫자는 토큰 인덱스를 나타낸다.
GETScore는 기존 시퀀스 표현 이미지 표현에 비해 몇 가지 장점이 있다.
- GETScore는 다성 및 다중 트랙 음악에 적합한 심볼릭 표현으로, 소스 트랙과 타겟 트랙의 유연한 사양을 용이하게 하고 트랙 생성에 대한 명시적인 제어를 용이하게 한다.
- Pitch와 duration의 간결한 토큰 표현을 통해 GETScore는 멀티트랙 음악을 효율적으로 표현할 수 있다.
- GETScore는 효과적이다. 추가적인 이점으로 pitch 토큰과 시간이 지남에 따른 트랙의 정렬이 트랙 내 및 트랙 간에 다성 의존성을 명시적으로 보존하여 조화로운 생성을 보장한다.
2. GETDiff
1. The Forward Process
GETMusic은 discrete한 토큰으로 구성된 GETScore에서 작동하므로 discrete diffusion model을 사용한다. Forward process의 흡수 상태로서 특수 토큰 [MASK]를 vocabulary에 도입한다. 시간 $t-1$에서 일반 토큰은 $\alpha_t$의 확률로 현재 상태를 유지하고 $1-\alpha_t$ (= $\gamma_t$)의 확률로 [MASK]로 전환된다. GETScore는 GETMusic이 지원하는 고정된 수의 트랙을 포함하고 구성 요구 사항이 항상 모든 트랙을 포함하는 것은 아니므로 관련되지 않은 트랙을 다른 특수 토큰 [EMPTY]로 채운다. 중요한 것은 [EMPTY]는 다른 토큰으로 절대 전환하지 않아 관련되지 않은 트랙의 간섭을 효과적으로 방지한다는 것이다. 공식적으로 전환 행렬
\[\begin{equation} [Q_t]_{mn} = q (x_t = m \vert x_{t−1} = n) \in \mathbb{R}^{K \times K} \end{equation}\]는 시간 $t − 1$의 $n$번째 토큰에서 시간 $t$의 $m$번째 토큰으로의 전환 확률을 정의한다.
\[\begin{equation} Q_t = \begin{bmatrix} \alpha_t & 0 & 0 & \cdots & 0 & 0 \\ 0 & \alpha_t & 0 & \cdots & 0 & 0 \\ 0 & 0 & \alpha_t & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & \cdots & 0 & 0 \\ \gamma_t & \gamma_t & \gamma_t & \cdots & 0 & 1 \end{bmatrix} \end{equation}\]여기서 $K$는 두 개의 특수 토큰을 포함한 총 vocabulary 크기이다. 행렬의 마지막 두 열은 각각 $q(x_t \vert x_{t-1} = [\textrm{EMPTY}])$와 $q(x_t \vert x_{t-1} = [\textrm{MASK}])$에 해당한다. $v(x)$를 $x$의 카테고리를 나타내는 one-hot 열 벡터라 하고 forward process의 Markovian 특성을 고려하면 다음과 같다.
\[\begin{aligned} q(x_t \vert x_0) &= v^\top (x_t) \bar{Q}_t v (x_0), \quad \textrm{with} \quad \bar{Q}_t = Q_t \ldots Q_1 \\ q(x_{t-1} \vert x_t, x_0) &= \frac{q(x_t \vert x_{t-1}, x_0)q(x_{t-1} \vert x_0)}{q(x_t \vert x_0)} \\ &= \frac{(v^\top (x_t) Q_t v(x_{t-1})) (v^\top (x_{t-1}) \bar{Q}_{t-1} v(x_0))}{v^\top (x_t) \bar{Q}_t v(x_0)} \end{aligned}\]다루기 쉬운 posterior를 사용하여 다음 식으로 GETDiff를 최적화할 수 있다.
\[\begin{equation} L_\lambda = L_\textrm{vlb} + \lambda \mathbb{E}_q \bigg[ \sum_{t=2}^T - \log p_\theta (x_0 \vert x_t) \bigg] \end{equation}\]The Denoising Process
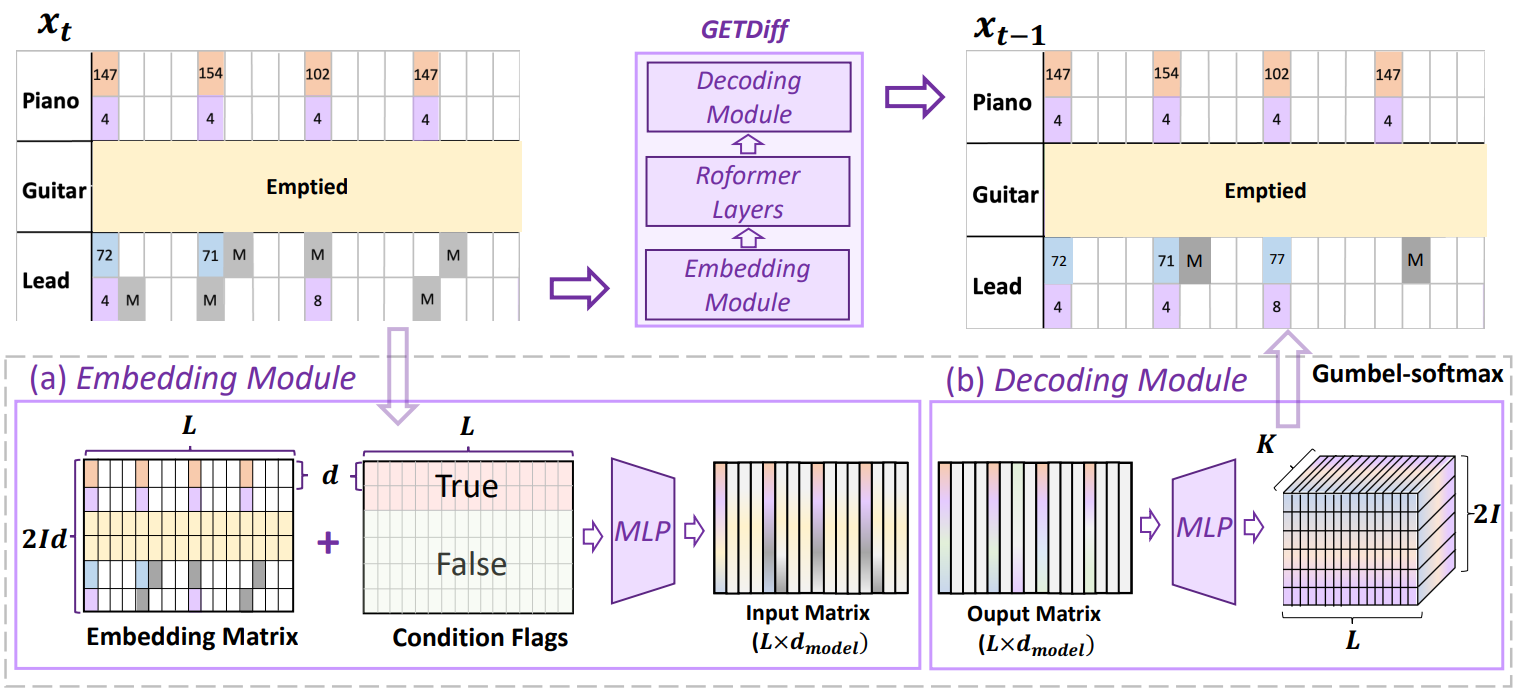
위 그림은는 시간 단위의 길이가 $L$인 3트랙 학습 샘플을 denoise하는 GETMusic의 개요이다. GETDiff에는 임베딩 모듈, Roformer 레이어, 디코딩 모듈의 세 가지 주요 구성 요소가 있다. Roformer는 상대적 위치 정보를 attention 행렬에 통합하는 transformer 변형으로, inference 중 길이 h extrapolati(외삽)에 대한 모델의 능력을 향상시킨다.
학습 중에 GETMusic은 각각 $I$개의 트랙이 있는 음악 작품에 대한 소스 트랙과 타겟 트랙의 다양한 조합을 처리해야 하며, 이는 $2I$개의 행이 있는 GETScore로 표시된다. 이를 위해 $m$개의 트랙 (GETScore에서 $2m$개의 행)이 랜덤하게 소스로 선택되고 $n$개의 트랙 (GETScore에서 $2n$)이 타겟으로 선택되며 $m \ge 0$, $n > 0$, $m + n ≤ I$이다.
임의로 샘플링된 시간 $t$에서 원래 GETScore $x_0$에서 $x_t$를 얻기 위해 타겟 트랙의 토큰은 $Q_t$에 따라 전환되고 소스 트랙의 토큰은 ground-truth로 유지되며 관련되지 않은 트랙은 비워진다. GETDiff는 4단계로 $x_t$의 noise를 제거한다.
- GETScore의 모든 토큰은 $d$차원 임베딩에 임베딩되어 크기 $2Id \times L$의 임베딩 행렬을 형성한다.
- 학습 가능한 조건 플래그가 행렬에 더해져 컨디셔닝할 수 있는 토큰을 GETDiff에 가이드하므로 inference 성능이 향상된다.
- 임베딩 행렬은 MLP를 사용하여 GETDiff의 입력 차원 $d_\textrm{model}$로 resize된 다음 Roformer 모델에 입력된다.
- 출력 행렬은 classification head를 통과하여 크기 $K$의 vocabulary에 대한 토큰 분포를 얻고 gumbel-softmax 테크닉을 사용하여 최종 토큰을 얻는다.
Inference
Inference하는 동안 사용자는 타겟 트랙과 소스 트랙을 지정할 수 있으며 GETMusic은 소스 트랙, 마스킹된 타겟 트랙, 비어 있는 트랙 (있는 경우)의 ground-truth 정보를 포함하는 $x_T$로 표시되는 해당 GETScore 표현을 구성한다. 그런 다음 GETMusic은 $x_T$를 단계적으로 denoise하여 $x_0$를 얻는다. GETMusic은 출력에서 토큰을 수정할 수 있는 non-autoregressive 패턴으로 모든 토큰을 동시에 생성한다. 원하는 소스 트랙에서 일관된 guidance를 보장하기 위해 $x_{t-1}$이 획득되면 소스 트랙의 토큰은 ground-truth로 돌아가고 관련되지 않은 트랙은 다시 비워진다. 표현과 GETDiff 동작의 결합된 이점을 고려할 때 GETMusic은 트랙 생성에 대한 다양한 요구를 해결하는 데 두 가지 주요 이점을 제공한다.
- GETMusic은 유연한 타겟 및 소스 사양을 지원하는 동시에 타겟 트랙의 명시적인 생성 제어 능력을 제공한다.
- GETDiff의 마스크와 denoising 메커니즘은 zero-shot 채우기 (즉, GETScore의 임의 위치에서 마스킹된 토큰의 denoising)를 가능하게 하여 다양성과 창의성을 더욱 향상시킨다.
Experiments
- 데이터
- Musescore에서 1,569,469개의 MIDI 파일을 크롤링
- $I = 6$개의 음악 트랙 (베이스, 드럼, 기타, 피아노, 스트링, 리드 멜로디) + 추가 코드 진행 트랙
- 137,812개의 GETScore: $L = 512$ (= 4/4 박자 음악에서 32마디)
- vocabulary 크기 $K$ = 11,881
- 학습 디테일
- diffusion timestep: $T = 100$
- 보조 loss 스케일: $\lambda$ = 0.001
- \(\bar{\gamma}_t\)는 0에서 1로 선형적으로 증가, \(\bar{\alpha}_t\)는 1에서 0으로 감소
- GETDiff: 12개의 Roformer 레이어 ($d$ = 96, $d_\textrm{model}$ = 768)
- optimizer: AdamW (learning rate = $10^{-4}$, $\beta_1$ = 0.9, $\beta_2$ = 0.999)
- learning rate는 처음 1,000 step에서 linear warmup 후 선형적으로 감소
- 8개의 32G Nvidia V100 GPU에서 학습
- 각 GPU당 batch size는 3, epoch 수는 50
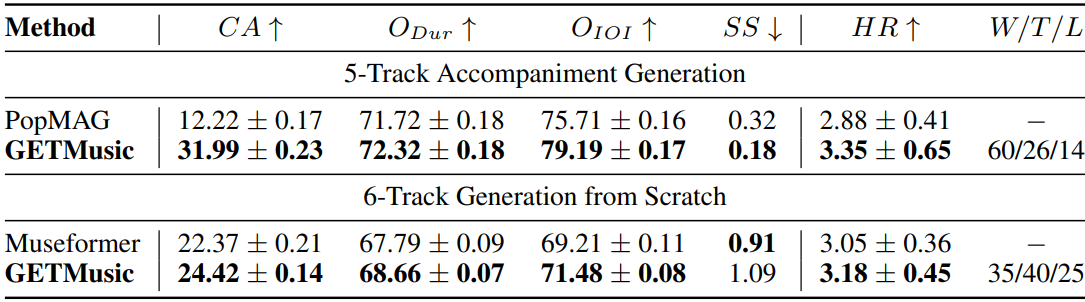
1. Comparison with Prior Works
다음은 이전 방법들과 GETMusic의 성능을 비교한 표이다.
2. High-Quality Results Across Diverse Tasks
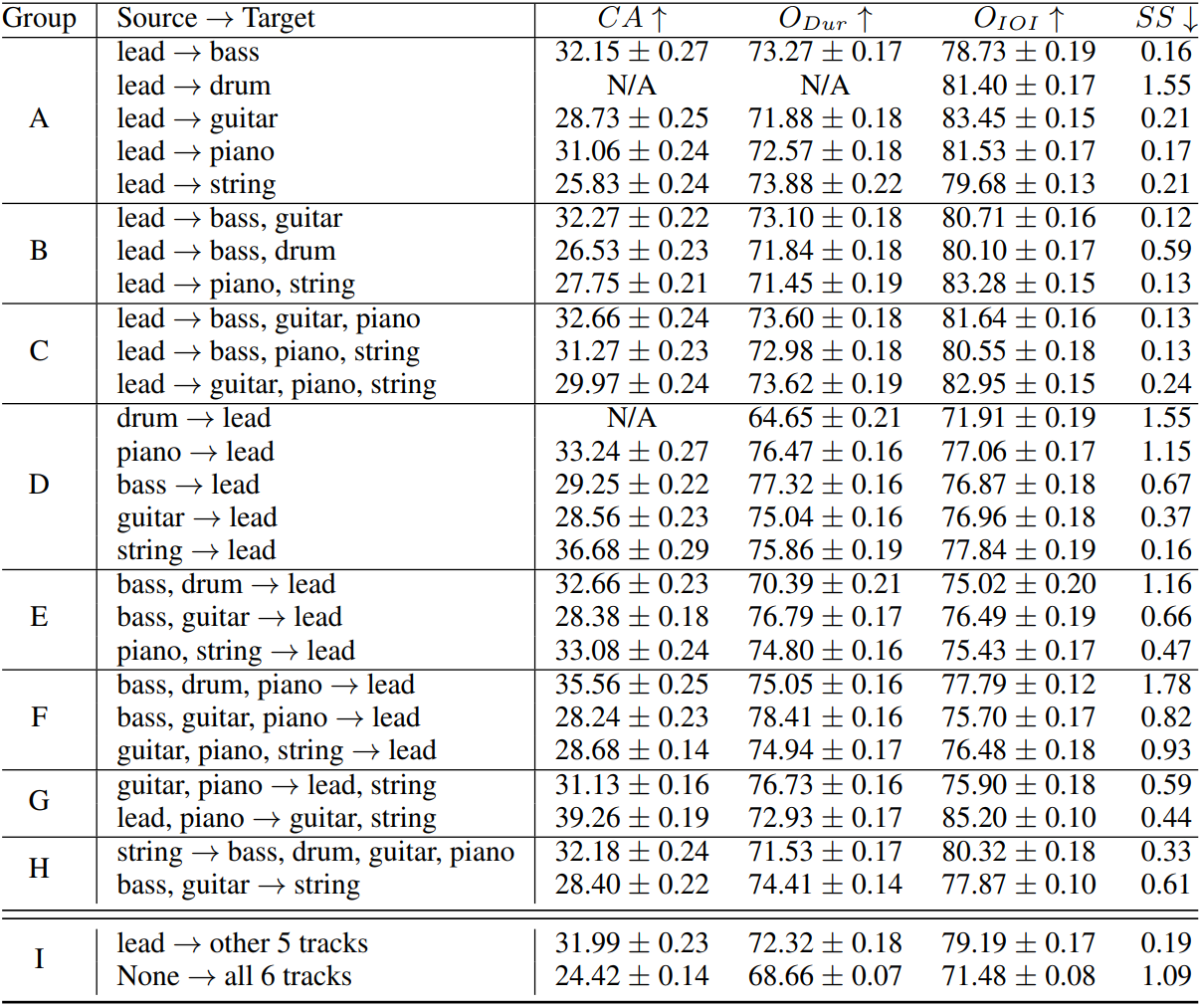
다음은 7개의 대표 소스-타겟 조합에 대한 결과이다.
3. Composition Identity
다음은 ‘lead $\rightarrow$ other 5 tracks’ task에 대하여 생성된 트랙 $\tilde{Y}$와 ‘lead $\rightarrow$ $Y$’ task에 대하여 생성된 트랙 $Y$ 사이의 identity score (‰)이다. B, D, G, P, S는 각각 베이스, 드럼, 기타, 피아노, 현을 나타낸다.
