[논문리뷰] GeoDream: Disentangling 2D and Geometric Priors for High-Fidelity and Consistent 3D Generation
arXiv 2023. [Paper] [Page] [Github]
Baorui Ma, Haoge Deng, Junsheng Zhou, Yu-Shen Liu, Tiejun Huang, Xinlong Wang
Beijing Academy of Artificial Intelligence | BUPT | Tsinghua University | Peking University
29 Nov 2023
Introduction
Diffusion model은 text-to-image 합성을 상당히 발전시켰다. 이 놀라운 성과는 쌍을 이루는 방대한 텍스트-이미지 데이터에서 확장 가능한 생성 모델을 학습함으로써 달성되었다. Diffusion model의 성공에 영감을 받아 이러한 성공을 2D에서 3D로 끌어올리는 것은 매력적이다. 템플릿 기반 generator와 3D 생성 모델은 자연스럽고 직접적인 접근 방식을 제공한다. 그러나 이러한 일반화된 모델을 학습시키는 데에는 방대하고 다양한 3D 데이터가 필요하기 때문에 이러한 방법들은 일반적으로 상대적으로 간단한 토폴로지와 텍스처를 가진 특정 카테고리로 제한된다.
최근 Score Distillation Sampling (SDS)과 Variational Score Distillation (VSD)가 도입되어 주어진 텍스트에 따라 diffusion model을 평가할 때 모든 관점에서 렌더링된 이미지가 높은 likelihood를 유지하도록 3D 표현을 최적화했다. 주어진 텍스트 프롬프트에서 3D 에셋을 생성할 수 있어 3D 데이터가 필요하지 않기 때문에 흥미로운 방향이다. SDS와 VSD는 기하학적으로 대칭인 광범위한 3D geometry에 대해 만족스러운 결과를 산출하지만, SDS loss와 VSD loss는 여전히 일관되지 않은 3D 기하학적 구조(Janus problems)와 비대칭적인 기하학적 구조로 인한 심각한 아티팩트로 인해 어려움을 겪는다. 이는 주로 2D diffusion model의 3D 인식이 부족하여 본질적으로 2D 관찰에서 3D로의 전환이 모호하기 때문이다.
해결책으로 3D 데이터셋에서 3D prior 학습은 이론적으로 합리적이고 올바른 것으로 보인다. 그러나 3D 데이터는 이미지에 비해 가격이 비싸고 희박하다. 따라서 현재 가장 유망한 방법은 상대적으로 제한된 3D 데이터에서 학습한 3D prior를 2D diffusion prior에 장착하여 두 세계의 장점을 모두 달성하는 것이다. 최근 대규모 3D 데이터셋인 Objaverse와 Objaverse-XL이 출시되면서 3D 데이터셋에서 렌더링된 멀티뷰 이미지를 사용하여 사전 학습된 2D diffusion model을 fine-tuning하려는 시도가 몇몇 연구에서 이루어졌다. 여기에는 카메라 파라미터에 따라 튜닝된 diffusion model로부터 멀티뷰 이미지를 얻고 예측된 멀티뷰 일관성의 단서를 활용하여 3D 정보를 추론하는 작업이 포함된다. 그럼에도 불구하고 이러한 방법은 다양한 소스 뷰에서 예측된 콘텐츠의 일관성에 크게 의존한다. 서로 다른 뷰 간에 feature를 교환하기 위해 3D self-attention을 사용하거나, 3D-aware attention을 사용하여 멀티뷰 feature를 연관시키거나, RGB 예측을 더 coarse한 Canonical Coordinates Map 예측으로 변환하여 불일치의 부정적인 영향을 완화하려는 노력에도 불구하고 예측된 멀티뷰 간의 이러한 불일치는 특히 학습 데이터 분포를 넘어서는 상상력이 풍부하고 흔하지 않은 경우에 눈에 띄게 나타나 생성된 3D 에셋의 의미론적 기하학이 oversmoothing되고 손실된다.
이 문제를 해결하기 위해 본 논문은 명시적인 일반화된 3D prior과 2D diffusion prior를 통합하여 다양성과 높은 충실도를 유지하면서 명확하고 일관된 3D 기하학적 구조를 얻는 능력을 향상시키는 새로운 방법인 GeoDream을 소개한다. 저자들의 기여는 다음과 같다.
- 위에서 언급한 멀티뷰 prior 사이의 일관성에 크게 의존하는 방법과는 완전히 대조적으로, 저자들은 3D 공간 내에서 3D prior를 얻을 것을 제안하였다. 이는 멀티뷰에서 예측된 prior 내에서 본질적인 완벽한 일관성 부족을 처리하는 데 적합하고 자연스럽게 카메라 시점 전환으로 인한 불일치가 발생하지 않는다.
- 3D prior과 2D prior를 분리하는 것이 2D diffusion prior의 일반화와 3D prior의 일관성을 모두 유지하는 데 잠재적으로 흥미로운 방향임을 보였다. 즉, 3D prior를 통해 힌트를 제공하여 2D diffusion model을 fine-tuning할 필요 없이 2D diffusion prior에서 3D 인식의 큰 잠재력을 잠금 해제한다.
구체적으로, 예측된 멀티뷰 2D 이미지를 3D 공간으로 집계하여 cost volume을 3D prior로 재구성하는 것부터 시작한다. 이러한 집계 연산들은 기하학적 추론을 위한 귀중한 단서를 제공하기 위해 강력하고 일반화된 것으로 알려진 MVS 기반 기술에서 널리 사용되었다. 이러한 연산들은 불완전하고 일관되지 않은 멀티뷰 예측을 처리하는 데 적합하다. 이는 각 뷰를 개별적으로 처리하는 대신 일관성 없는 콘텐츠를 어느 정도 필터링하는 데 도움이 되는 멀티뷰 정보 집계가 포함되기 때문이다.
또한 저자들은 disentangle된 솔루션에서 3D prior과 2D diffusion prior를 통합하는 것을 제안하였다. 기존 멀티뷰 diffusion prior에는 supervision으로 멀티뷰를 생성하거나 3D 표현을 최적화하기 위한 기울기를 계산하기 위한 loss로 확률 밀도를 증류(distill)하며 결합된 방식으로 2D diffusion prior가 장착되어 있다. 대신, 3D prior에 제공된 기하학적 단서를 활용하면 “disentangled design”이라고 하는 2D diffusion prior에 내재된 큰 잠재적인 3D 인식 능력을 효과적으로 발휘할 수 있다.
최근 연구들에서는 score function이나 부정적인 텍스트 프롬프트를 변경하여 2D diffusion에서 3D 인식 능력을 불러일으키는 방법을 탐구하기 시작했다. 이러한 노력은 놀라운 진전을 이루었지만 3D 일관성과 관련하여 성능은 여전히 불안정하다. 저자들의 통찰력은 2D diffusion에서 3D 인식의 큰 잠재력을 잠금 해제하기 위해 기하학적 prior를 통과하는 것이 일반적이고 안정적인 유망한 방향이라는 것이다. 또한 3D prior supervision 없이 Neural Implicit Surfaces (NeuS)의 최적화를 가이드하기 위해 2D prior의 3D 인식 능력에만 의존하여 일반화 및 창의성 측면에서 2D prior의 고유한 이점이 손상되는 것을 방지한다.
저자들은 렌더링 품질과 기하학적 정확도를 높이기 위해 3D prior를 더욱 개선할 수 있음을 보여주었다. 2D diffusion prior는 점진적으로 진화하는 3D prior의 이점을 가지며, 이는 결국 2D prior를 해제하기 위한 우수한 guidance를 제공한다. 마지막으로 DMTet을 사용하여 메쉬 fine-tuning을 위해 최적화된 NeuS에서 텍스처 메쉬를 추출한다. 일반적으로 렌더링 해상도를 높일 때 over-saturation 문제로 인해 어려움을 겪는 이전 연구들과 달리 GeoDream은 렌더링 해상도를 512에서 1024로 성공적으로 높였다. 저자들은 향상된 결과가 보다 그럴듯한 geometry와 현실감을 제공하는 3D prior에 의해 지원되고 조장된다고 가정하였다. 렌더링된 이미지가 diffuse된 분포에 더 가깝기 때문에 최적화가 더 쉬워진다. 저자들은 의미론적 일관성을 종합적으로 평가하기 위해 측정을 2D에서 3D로 끌어올리는 Uni3Dscore metric을 최초로 제안했다.

Method
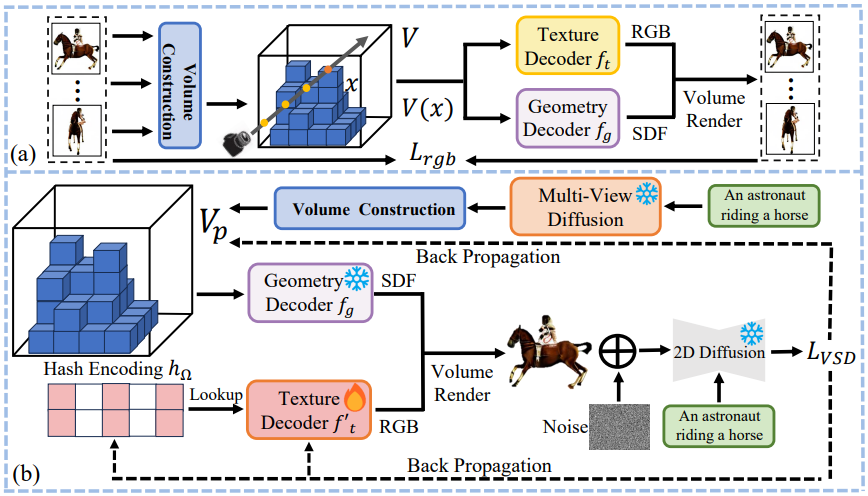
저자들은 일반화 가능성을 유지하면서 3D로 일관된 geometry를 생성할 수 있는 능력을 2D diffusion prior에 장착하여 일관되게 정확한 geometry와 섬세한 시각적 디테일을 갖춘 3D 콘텐츠를 생성하는 데 중점을 두었다. GeoDream의 개요는 위 그림에 나와 있다. GeoDream은 다음 두 단계로 구성된다.
- 위 그림의 (a)와 같이 3D prior 학습 중에 geometry는 cost volume $V$와 geometry decoder $f_g$로 인코딩하는 One-2-3-45를 기반으로 구축된다. 또한 객체의 모양은 cost volume $V$와 texture decoder $f_t$로 모델링된다.
- Prior 개선 과정에서 위 그림의 (b)와 같이 2D 확산 모델을 결합하여 기하학적 prior 개선을 통해 렌더링 품질과 기하학적 정확도를 향상시킬 수 있다.
1. Generalizable 3D Priors Training
2D 이미지 feature를 3D 공간으로 집계하여 cost volume $V$를 기본 3D prior로 재구성하는 것부터 시작한다. 이는 prior 개선 단계에서 기하학적 추론을 위한 귀중한 단서를 제공한다.
Cost Volume Construction
MVS 기반 방법들을 따라 멀티뷰 이미지 \(I = \{(I_i)_{i=0}^{N−1}\}\)이 주어지면 2D feature 네트워크 $f_\textrm{2D}$를 사용하여 2D feature map \(F = \{(F_i)_{i=0}^{N−1}\}\)을 추출한다. 볼륨 재구성 모델은 2D feature map $F$를 입력으로 사용하고 복셀의 복셀별 feature를 사용하여 cost volume $V$를 출력한다. 구체적으로, 3D 위치 $h$를 중심으로 하는 각 복셀에 대해 복셀별 feature는 각 위치 $h$를 $N$개의 이미지 feature 평면에 project한 다음 projection 위치에서 feature의 분산을 가져와 계산된다. 분산 연산을 나타내기 위해 $\textrm{Var}$를 사용하고 projection 절차를 나타내기 위해 $P$를 사용한다. 그러면 sparse 3D CNN $f_\textrm{3D}$를 사용하여 복셀당 분산 feature를 처리하여 다음과 같이 cost volume을 회귀한다.
\[\begin{equation} V = f_\textrm{3D} (\textrm{Var} \{P(F_i, h)\}_{i=0}^{N-1}) \end{equation}\]여기서 분산 연산은 입력 이미지의 수 $N$에 따라 변하지 않는다. 이러한 연산은 각 뷰를 개별적으로 처리하는 대신 정보 집계를 포함하기 때문에 불완전하고 일관성이 없는 멀티뷰 예측을 처리하는 데 적합하다.
Geometry and Texture Decoder
Cost volume $V$는 해당 geometry decoder $f_g$와 texture decoder $f_t$를 사용하여 signed distance function (SDF) 값과 색상 정보로 직접 디코딩된다. 임의의 쿼리 포인트 $x \in \mathbb{R}^3$에 대해 SDF $s$와 색상 $c$를 다음과 같이 얻는다.
\[\begin{equation} s(x) = f_g (E(x), V(x)) \\ c(x) = f_t (\{P(F_i, x)\}_{i=0}^{N-1}, V(x), \{\Delta d_i\}_{i=0}^{N-1}) \end{equation}\]여기서 $E$는 위치 인코딩을 나타내고, $V(p)$는 쿼리 지점 $x$에서 cost volume으로부터 trilinearly interpolate된 feature를 나타내며, $\Delta d_i = d − d_i$는 $i$번째 멀티뷰 이미지의 시야 방향에 대한 쿼리 광선의 시야 방향이다.
최종 렌더링된 이미지 $I^\prime$은 SDF 기반 differentiable volume rendering $R$을 통해 얻을 수 있다. 본 논문에서 학습된 One-2-3-45로부터 $f_g$, $f_t$, $f_\textrm{3D}$ 네트워크의 사전 학습된 파라미터를 얻는다. 이는 다음과 같은 loss로 Objaverse 데이터셋에서 렌더링한 실제 이미지에 대해 학습되었다.
\[\begin{equation} \mathcal{L}_\textrm{rgb} = \| I - I^\prime \|_2 \\ \textrm{where} \; I^\prime = R(\{s(x_j), c(x_j)\}_{j=0}^{M-1}) \end{equation}\]$M$은 시야 방향의 광선을 따라 샘플링한 쿼리 점의 개수이다.
2. Priors Refinement
2D diffusion prior를 사용하여 3D prior 학습 단계에서 얻은 기하학적 prior, 즉 최적화 가능한 cost volume $V$와 고정된 geometry decoder $f_g$를 추가로 fine-tuning한다. 이전 개선 단계에서 $N$개의 ground-truth 렌더링 이미지를 멀티뷰 diffusion model 예측으로 대체한다. One-2-3-45와 달리 GeoDream은 Zero123 예측에만 국한되지 않는다. 저자들은 MVDream, Zero123++ 등 다양한 멀티뷰 diffusion model을 사용해 광범위한 실험을 진행하였다. 또한 저자들은 GeoDream이 단 하나의 모델에만 국한되지 않고 다양한 멀티뷰 diffusion model에 강력하게 적응할 수 있도록 뷰 샘플링 전략을 도입하였다. 전반적으로 3D prior과 2D diffusion prior를 분리함으로써 GeoDream이 2D diffusion model에서 3D 인식의 엄청난 잠재력을 잠금 해제하고 표준 뷰를 생성하는 경향을 피하여 여러 면과 축소된 geometry를 feature로 하는 3D 에셋을 생성한다. 디커플링 덕분에 GeoDream은 2D diffusion prior의 일반화와 상상력을 유지하는 동시에 모양 모델링을 개선하는 데 기하학적 prior가 수행하는 중요한 역할을 탐구한다.
Multi-View Images Generation
3D 생성의 급속한 발전으로 Zero123, MVDream, Zero123++ 등 멀티뷰 이미지 생성에 사용할 수 있는 다양한 방법이 제공되었다. 미리 정의된 카메라 포즈 집합 \(\{(R_i, T_i)_{i=0}^{N−1}\}\)과 사용자 제공 조건 $c$가 주어지면 고정된 멀티뷰 diffusion model $f_\textrm{mv}$를 활용하여 해당 포즈의 이미지 $I_p = {(I_i^p)_{i=0}^{N−1}}$를 예측하고 2D feature map \(F_p = \{(F_i^p)_{i=0}^{N-1}\}\)를 추출한다.
\[\begin{equation} F_i^p = f_\textrm{2D} (f_\textrm{mv} (c, R_i, T_i)) \end{equation}\]여기서 $R \in \mathbb{R}^{3 \times 3}$, $T \in \mathbb{R}^{3 \times 3}$은 각각 상대적인 카메라 회전과 기본 시점의 이동을 나타낸다.
3D Geometric Priors
$F_i$를 $F_i^p$로 대체함으로써 임의의 쿼리 지점 $x$에서 SDF 값을 다음과 같이 얻는다.
\[\begin{equation} V_p = f_\textrm{3D} (\textrm{Var} \{P(F_i^p, h)\}_{i=0}^{N-1}) \\ s_p (x) = f_g (E(x), V_p (x)) \end{equation}\]여기서 $s_p (x)$는 예측된 멀티뷰에 숨겨진 기하학적 단서를 인코딩하므로 기하학적 prior로 처리된다.
Texture Decoder
저자들은 텍스처 prior가 렌더링된 데이터셋과 유사한 조명 및 텍스처 스타일로 3D 에셋을 생성하는 경향이 있다는 것을 경험적으로 발견했기 때문에 사전 학습된 텍스처 prior $f_t$를 삭제하는 것을 제안하였다. 효율적인 고해상도 텍스처 인코딩을 위해 Instant NGP를 사용한다. 구체적으로, 임의의 쿼리 포인트 $x \in \mathbb{R}^3$에 대해 $h_\Omega$을 인코딩하는 학습 가능한 해시(hash)는 초기화된 texture decoder $f_t^\prime$을 사용하여 다음과 같이 색상 $c$로 디코딩된다.
\[\begin{equation} c_p (x) = f_t^\prime (h_\Omega (x), x) \end{equation}\]여기서 $h_\Omega (x)$는 쿼리 지점 $x$에서 $h_\Omega$에서 조회된 feature 벡터이다.
Texture and Geometry Refinement
기하학적 3D prior를 2D diffusion prior과 통합하기 위해 ProlificDreamer에 도입된 VSD loss를 최소화하여 cost volume $V$의 파라미터 $\theta_1$, 해시 인코딩 $h_\Omega$의 파라미터 $\theta_2$, texture decoder $f_t^\prime$의 파라미터 $\theta_3$를 최적화한다. 각 iteration마다 사전 정의된 분포에서 카메라 포즈를 샘플링한다. Differential rendering $R$을 통해 포즈 $o$에서 2D 이미지 $\hat{x}$를 렌더링한다. Prior 개선 중 목적 함수는 VSD loss \(\mathcal{L}_\textrm{VSD}\)를 최소화하는 것이다. 기울기 \(\nabla_{\theta_1, \theta_2, \theta_3} \mathcal{L}_\textrm{VSD}\)는 다음과 같다.
\[\begin{equation} \mathbb{E}_{t, \epsilon, o} [w(t) (\epsilon_\textrm{pretrain} (\hat{x}_t, t, c) - \epsilon_l (\hat{x}_t, t, c, o)) \frac{\partial \hat{x}}{\partial (\theta_1, \theta_2, \theta_3)}] \end{equation}\]여기서 \(\hat{x}_t\)는 timestep $t$에서 noisy한 렌더링된 이미지, $w(t)$는 가중치 함수, \(\epsilon_\textrm{pretrain}\)은 사전 학습된 2D diffusion model이고 ϵl은 파라미터 $l$을 갖는 LoRA diffusion model이다. 저자들은 기하학적 단서를 유지하고 최적화 초기 단계에서 더 나은 디테일을 달성하기 위해 튜닝하는 것을 목표로 cost volume에 대한 learning rate decay 전략과 함께 geometry decoder $f_g$를 수정하는 것을 제안하였다.
Mesh Fine-tuning
고해상도 렌더링을 위해 DMTet을 사용하여 최적화된 NeuS에서 텍스처가 있는 3D 메쉬 표현을 추출한다. 먼저 ProlificDreamer를 따라 normal map을 사용하여 geometry를 최적화한 다음 텍스처를 최적화한다. 일반적으로 렌더링 해상도를 높일 때 over-saturation 문제로 인해 어려움을 겪는 이전 연구들과 달리 GeoDream은 렌더링 해상도를 512에서 1024로 성공적으로 높였다. 렌더링된 이미지 $\hat{x}$가 각 iteration에서 diffusion 분포에 더 가깝기 때문에 잘 최적화된 결과가 더 그럴듯한 geometry와 사실적인 텍스처를 제공하는 3D prior에 의해 지원되어 최적화를 더 쉽게 만든다.
Experiment
렌더링 각도와 기하학적인 가려짐으로 인해 제한되는 2D metric은 360도 전체에서 3D 개체를 평가하는 데 어려움을 겪는 경우가 많다. 3D 에셋의 의미론적 일관성을 평가하기 위해 text-to-3D task에 아직 도입된 metric은 없다. 따라서 저자들은 의미론적 일관성 측정을 2D에서 3D로 향상시키기 위해 텍스트-이미지-포인트 클라우드 정렬 목적 함수에 따라 10억 개의 파라미터를 가진 가장 큰 3D 표현 모델인 Uni3D를 사용할 것을 제안하였다. CLIP의 이미지 인코더와 텍스트 인코더를 Uni3D의 포인트 클라우드와 텍스트 인코더로 대체한다는 점을 제외하면 CLIP R-score와 유사한 전략을 채택하였다. 이 metric을 Uni3Dscore라고 부른다.
1. Results of GeoDream
다음은 GeoDream이 생성한 렌더링된 이미지와 메쉬 결과이다.

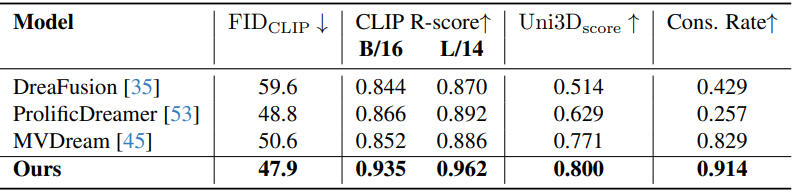
Quantitative Comparison
다음은 baseline들과 생성 결과를 비교한 것이다.
Qualitative Comparison
다음은 baseline들과 정량적으로 비교한 표이다.

2. Ablation Study
다음은 ablation study 결과이다.
