[논문리뷰] Geometry Transfer for Stylizing Radiance Fields
CVPR 2024. [Paper] [Page] [Github]
Hyunyoung Jung, Seonghyeon Nam, Nikolaos Sarafianos, Sungjoo Yoo, Alexander Sorkine-Hornung, Rakesh Ranjan
Seoul National University | Meta Reality Labs
1 Feb 2024

Introduction
최근 연구에서는 포인트 클라우드나 메쉬와 같은 3D 모델에 스타일을 적용하여 3D style transfer 문제를 해결했지만, 오차가 발생하기 쉬운 형상으로 인해 radiance field의 stylization이 적극적으로 탐구되었다.
이 연구들은 스타일 이미지에서 색상, 질감, 붓터치 등의 미적 특성을 전달하여 스타일리시함을 강화하고 이러한 특성을 3D 장면에 효과적으로 적용하는 데 중점을 두었다. 그러나 기하학적 구조의 잠재적인 이점은 아직까지 탐구되지 않고 무시되고 있다. 3D 장면이 모양과 색상 속성을 모두 갖고 있음에도 불구하고 대부분의 연구에서는 색상에만 초점을 맞추고 style transfer 중에 기하학적 파라미터는 변경되지 않는다. 따라서 출력 모양이 원본 콘텐츠에서 벗어나지 않고 스타일 이미지의 기하학적 단서를 반영하지 못한다.
본 논문에서는 주로 기하학적 변형을 3D style transfer에 통합하였을 때 얻는 이점에 중점을 두었다. 저자들은 “기하학적 스타일”을 스타일 이미지의 기하학적 본질을 정확하게 포착하는 뚜렷하고 명확한 특성으로 정의하였다. 본 논문은 depth map을 사용하여 스타일 템플릿에서 기하학적 스타일을 추출한 다음 NeRF의 모양을 직접 stylize하는 Geometry Transfer를 제안한 최초의 style transfer 논문이다.
그러나 단순히 RGB 스타일 이미지를 depth map으로 바꾸는 것만으로는 원하는 결과를 얻을 수 없다. 이 문제는 NeRF 표현에서 모양과 외형이 본질적으로 분리되어 있기 때문에 발생한다. 모양이 직접 최적화되면 결과 색상이 업데이트된 형태와 잘 정렬되지 않는다. 이 문제를 극복하기 위해 각 3D 포인트에 대한 오프셋 벡터를 예측하는 deformation field를 도입한다. 이를 통해 최적화 중에 모양과 외형의 조화로운 stylization이 보장된다. 결과적으로 depth map을 스타일 이미지로 사용하여 3D 장면의 기하학적 구조를 stylize한다.
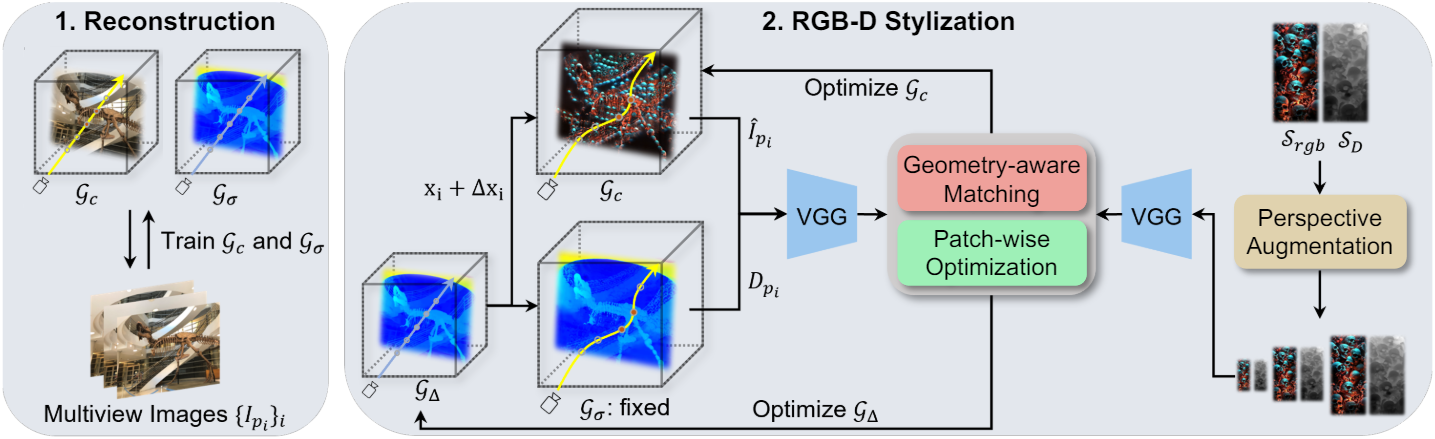
본 논문은 geometry transfer를 바탕으로 RGB-D 쌍을 스타일 이미지로 사용하는 새로운 3D style transfer 방법을 제안하며, 모양과 외형 측면에서 주어진 스타일을 더 잘 반영하는 보다 표현적인 stylization을 목표로 한다. 이를 위해 patch-wise 방식을 통해 로컬한 기하학적 구조를 유지하면서 stylization의 다양성을 향상시키는 geometry-aware matching을 제안하였다. 또한 더욱 풍부한 장면 깊이감을 제공하기 위해 새로운 style augmentation 전략을 도입하였다.
Method
1. Geometry Transfer
Depth Map as a Style Guide

스타일 가이드로 RGB 이미지를 사용하는 대신, 이를 depth map \(\mathcal{S}_D\)로 대체하여 모양의 독특한 스타일을 캡처한다. Style transfer 프로세스 중에 depth map $D_{p_i}$를 렌더링하고 $D_{p_i}$와 \(\mathcal{S}_D\) 간의 style loss를 최적화한다. VGG 네트워크는 3채널 이미지를 입력으로 예상하므로 depth map을 세 번 복제하여 채널 차원을 따라 concatenate한다. $D_{p_i}$가 volume density에만 관련되어 있다는 점을 고려하면 loss function은 density grid \(\mathcal{G}_\sigma\)를 최적화한다. 이 접근 방식은 위 figure의 (a)에서 볼 수 있듯이 색상에 style transfer을 적용하는 것과 동일한 방식으로 모양을 조작할 수 있다. 그러나 모양이 스타일 이미지에 적응하는 동안 색상은 그대로 유지되어 원하지 않는 결과를 초래하는 문제가 발생한다.
Modeling Deformation Fields
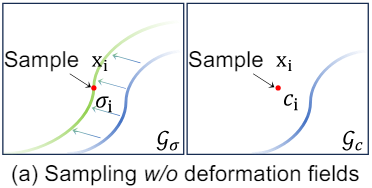
실제 장면에 대한 사전 학습 후 \(\mathcal{G}_\sigma\)는 3D 장면을 반영하는 표면 분포를 형성한다. 동시에, appearance grid \(\mathcal{G}_c\)의 색상 값은 \(\mathcal{G}_\sigma\)의 표면 분포의 해당 위치와 일관되게 업데이트된다. 이러한 동기화를 통해 정확한 표면을 정확한 모양으로 렌더링할 수 있다. 그러나 기하학적 구조가 stylize되면 \(\mathcal{G}_\sigma\) 내의 표면 분포는 변경되지만 \(\mathcal{G}_c\)는 일관되게 유지된다. 수정된 영역의 색상은 위 그림과 같이 \(\mathcal{G}_c\)의 새로운 표면 위치에서 주로 공급된다.
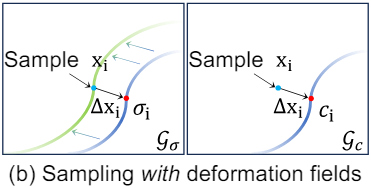
이 문제를 해결하기 위해 모양과 외형 모두를 동시에 수정할 수 있는 deformation network를 도입한다. 이 네트워크는 3D 포인트 $x_i$를 $x_i + \Delta x_i$에 매핑하는 $\Delta x_i \in \mathbb{R}^3$을 예측하는 함수로 설계되었다. 또 다른 voxel grid인 \(\mathcal{G}_\Delta\)를 사용하여 deformation network를 표현하고 \(\mathcal{G}_\sigma\)를 변경하지 않고 기하학적 스타일을 지정하기 위한 목적으로만 이를 업데이트한다. 위 그림에 설명된 대로 stylize된 장면을 렌더링할 때 volume density와 색상 모두 원래 표면에서 샘플링된다. 이를 통해 일관된 색상이 수정된 영역과 연관된다.
2. RGB-D Stylization
색상과 기하학적 구조를 모두 수정하는 보다 표현적인 stylization을 위해 RGB 이미지와 depth map의 한 쌍의 스타일 가이드를 사용한다. RGB 스타일 \(\mathcal{S}_\textrm{rgb}\)가 주어지면 zero-shot 깊이 추정 네트워크를 사용하여 depth map을 얻고 style depth \(\mathcal{S}_D\)로 사용한다.
Geometry-aware Nearest Matching
두 가지 스타일 이미지 \(\mathcal{S}_\textrm{rgb}\)와 \(\mathcal{S}_D\)를 사용하여 stylize하려면 여러 스타일 소스들을 고려하여 style loss를 조정해야 한다. 본 논문의 목표는 색상과 기하학적 구조를 모두 정렬하는 것이므로 nearest matching loss를 독립적으로 계산하는 것은 모양과 외형 패턴 간의 잠재적인 불일치로 인해 부적절하다. 보다 효과적인 방법은 처음에 한 도메인에서 content feature와 style feature 사이의 nearest matching을 식별한 다음 미리 결정된 이러한 쌍을 사용하여 다른 도메인에 대한 style loss를 계산하는 것이다. 또는 color feature와 geometry feature를 모두 사용하여 nearest neighbor를 동시에 검색할 수 있다. RGB와 depth map에서 VGG feature map을 추출한 후 채널 차원을 따라 concatenate한 다음 검색을 수행하여 가장 가까운 쌍을 찾는다.
\[\begin{equation} j = \underset{i^\prime}{\arg \min} \, D ([F_\mathcal{I}^\textrm{rgb} (i), F_\mathcal{I}^\textrm{D} (i)], [F_\mathcal{S}^\textrm{rgb} (i^\prime), F_\mathcal{S}^\textrm{D} (i^\prime)]) \end{equation}\]그런 다음 RGB와 depth map에서 얻은 feature 각각에 cosine distance $D$를 적용하여 최적화한다.
\[\begin{equation} L(i) = D(F_\mathcal{I}^\textrm{rgb} (i), F_\mathcal{S}^\textrm{rgb} (j)) + D (F_\mathcal{I}^D (i), F_\mathcal{S}^D (j)) \end{equation}\]Style loss는 모든 feature 벡터의 평균으로 계산된다.
\[\begin{equation} L_\textrm{style} = \frac{1}{N} \sum_i L(i) \end{equation}\]Geometry feature를 매칭 프로세스에 통합하는 이 전략은 다양성을 향상시킬 뿐만 아니라 장면 구조를 더 잘 보존한다.
Patch-wise Optimization
RGB 스타일 이미지를 사용하면 출력이 색상, 질감, 기타 시각적 특성 측면에서 스타일과 일치하는지 쉽게 확인할 수 있다. 그러나 depth map은 스타일을 식별하는 데 제한된 단서를 제공한다. 이는 모양이 고립된 픽셀이 아니라 주변 환경과의 관계에 의해 정의되기 때문이다. 픽셀별로 매칭을 수행하는 기존의 nearest matching loss는 기하학적 스타일을 효과적으로 전달하기에 충분하지 않다. 이 문제를 해결하기 위해 receptive field를 넓혀 공간적 상호작용을 포착하는 데 더욱 효과적인 patch-wise 매칭 방식을 도입한다.
추출된 VGG feature map \(F_\mathcal{I}\)와 \(F_\mathcal{S}\)가 주어지면 먼저 각 feature map을 $k \times k$개의 패치 세트 \(\{\mathcal{P}_\mathcal{I}^i\}_i\)와 \(\{\mathcal{P}_\mathcal{S}^i\}_i\)로 분할한다. Patch-wise style loss \(L_\mathcal{SP}\)는 다음과 같이 계산된다.
\[\begin{equation} L_\mathcal{SP} = \frac{1}{\vert \mathcal{P}_\mathcal{I} \vert} \sum_i \min_j D^\mathcal{P} (\mathcal{P}_\mathcal{I}^i, \mathcal{P}_\mathcal{S}^j) \end{equation}\]여기서 \(D^\mathcal{P} (\mathcal{P}_1, \mathcal{P}_2)\)는 각 패치 내의 해당 위치에 있는 feature 벡터 간의 cosine distance의 합을 계산한다.
\[\begin{equation} D^\mathcal{P} (\mathcal{P}_1, \mathcal{P}_2) = \sum_i^{k^2} D(F_1^i, F_2^i) \end{equation}\]계산을 늘리지 않고 더 큰 receptive field를 달성하기 위해 각 패치는 dilation rate $r$을 hyperparameter로 정의할 수 있다.
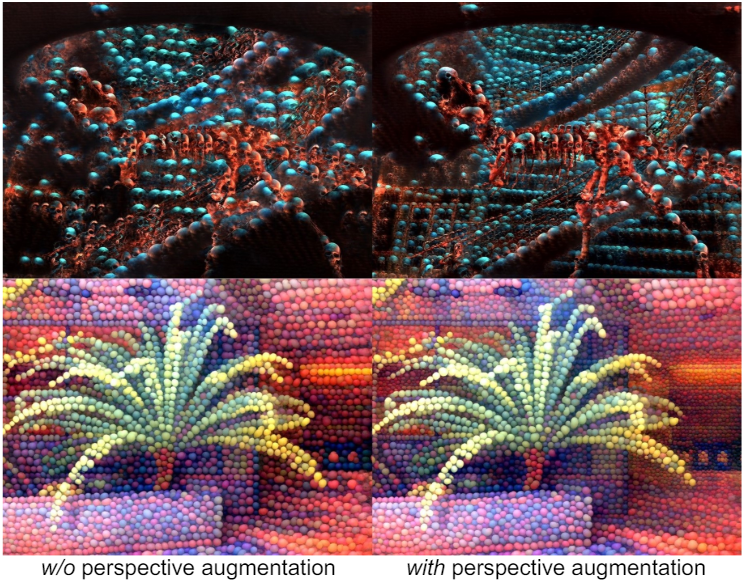
Perspective Style Augmentation
일반적으로 뚜렷한 패턴을 가진 스타일 이미지가 선택된다. 이는 기하학적 스타일을 보다 명확하게 식별하는 데 도움이 되기 때문이다. 다양성과 깊이에 대한 인식을 향상시키기 위해 이러한 패턴의 크기를 다양하게 변경하여 거리에 따라 표면에 다르게 적용할 수 있다.
Stylization 과정에 앞서, 모든 학습 시점에서 월드 좌표계의 3D 포인트를 수집하고 $z$-좌표를 기준으로 $N$개의 bin \(\{B_i\}_{i=1}^N\)로 분류한다. 각 bin $B_i$는 해당 bin 내 포인트의 $z$ 값을 평균하여 결정되는 중앙 값 $C_i$에 연결된다. 패턴 크기가 콘텐츠 및 스타일 이미지의 상대적 해상도에 따라 달라질 수 있다는 점을 고려하여 스타일 이미지를 여러 스케일 \(\{s_i\}_{i=1}^N\)로 다운샘플링하여 수정한다. 이 프로세스를 통해 일련의 스타일 쌍 \(\{\mathcal{S}_i\}_{i=1}^N\)이 생성된다 (\(\mathcal{S} = (\mathcal{S}_\textrm{rgb}, \mathcal{S}_D)\)). 첫 번째 bin의 스케일 $s_1$을 1로 설정하고 나머지 bin의 스케일은 첫 번째 bin으로부터의 상대 거리를 기준으로 $s_i = C_1 / C_i$로 계산된다.
Stylization 중에 렌더링된 이미지의 각 픽셀은 픽셀의 $z$ 좌표에서 bin의 중심 $C_{i^\prime}$까지의 거리를 기준으로 bin $B_{i^\prime}$에 할당된다. 이 방법은 렌더링된 이미지를 계층화된 깊이 이미지와 유사한 형식으로 변환한다. 그런 다음 각 레이어는 해당 스타일 쌍 \(\mathcal{S}_{i^\prime}\)을 사용하여 stylize되며, 이는 적절한 스케일로 다운샘플링된다. 결과적으로, 큰 패턴은 가까운 표면에 매핑되고, 작은 패턴은 먼 표면에 적용되어 전체적인 깊이감이 향상된다.
Experiments
- 데이터셋: LLFF, ScanNet
- 구현 디테일
- TensoRF 기반
- deformation field
- 사전 학습 시에는 랜덤하게 초기화되고 0을 출력하도록 최적화
- 사전 학습 후에는 density grid를 고정하고 appearance grid와 deformation grid를 학습
- VGG-16의 conv2와 conv3 layer에서 feature 추출
- stylization 전후로 view-consistent color transfer를 적용
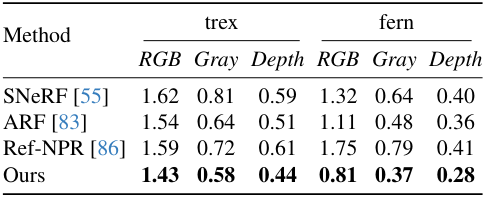
1. Qualitative and Quantitative Comparisons
다음은 기존 방법들과 정성적으로 비교한 결과이다.

다음은 기존 방법들과 Single Image Frechet Inception Distance (SIFID)를 비교한 표이다.
다음은 user study 결과이다. (평균 순위)

2. Ablation Experiments
다음은 geometric feature에 대한 영향을 비교한 결과이다.

다음은 patch-wise 최적화에 대한 영향을 비교한 결과이다.

다음은 perspective style augmentation의 영향을 비교한 결과이다.
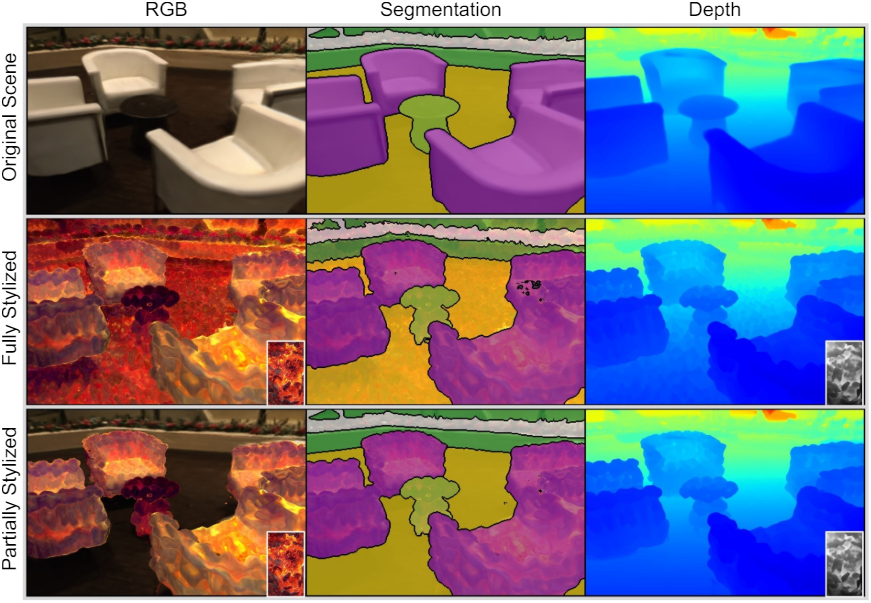
3. Application: Partial Stylization
다음은 3D 장면을 부분적으로 stylize한 예시이다.
Limitations
- TensoRF를 사용하기 때문에 본질적으로 360도의 unbounded scene을 처리하는 능력이 제한된다.
- 3D 장면의 패턴이 상당히 다른 시점에서 볼 때 동일하게 나타나지 않는다.