[논문리뷰] GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation
CVPR 2024. [Paper] [Page]
Shoufa Chen, Mengmeng Xu, Jiawei Ren, Yuren Cong, Sen He, Yanping Xie, Animesh Sinha, Ping Luo, Tao Xiang, Juan-Manuel Perez-Rua
The University of Hong Kong | Meta
7 Dec 2023

Introduction
본 논문에서는 transformer를 사용한 diffusion model에 중점을 두었다. 특히, U-Net 대신 transformer를 사용하는 DiT에서 출발하였다. 먼저 사전 정의된 one-hot 클래스 임베딩 대신 언어 임베딩을 활용하여 제한된 수의 사전 정의된 클래스만 처리하도록 제한되는 DiT의 한계를 극복했다. 그 과정에서 컨디셔닝 아키텍처와 텍스트 인코딩 방법 등 다양한 컨디셔닝 전략을 조사하였다.
저자들은 GenTron의 scaling-up 속성도 연구하였다. Transformer 아키텍처는 시각적 인식 및 언어 task 모두에서 상당한 확장성(scalability)을 보유하는 것으로 입증되었다. 예를 들어, 가장 큰 언어 모델에는 5,400억 개의 파라미터가 있고 가장 큰 비전 모델에는 220억 개의 파라미터가 있다. 반면, 가장 큰 diffusion transformer인 DiT-XL은 약 6.75억 개의 파라미터만 갖고 있어 다른 도메인에서 사용되는 transformer나 U-Net 아키텍처를 사용하는 최근 diffusion model에 비해 훨씬 뒤떨어져 있다. 저자들은 Scaling vision transformers 논문의 스케일링 전략에 따라 GenTron의 transformer 블록 수와 hidden dimension 크기를 스케일링하였다. 그 결과, 가장 큰 모델인 GenTron-G/2는 30억 개 이상의 파라미터를 가지며 소형 모델에 비해 시각적 품질이 크게 향상되었다.
또한 저자들은 각 transformer 블록에 temporal self-attention layer를 삽입하여 GenTron을 text-to-image (T2I)에서 text-to-video (T2V) 모델로 발전시켰으며, transformer를 video diffusion model의 전용 블록으로 사용하려는 최초의 시도를 했다. 또한 동영상 생성이 가진 기존 문제점들에 대해 논의하고 해결 방법인 motion-free guidance (MFG)를 도입하였다. MFG에는 temporal self-attention mask를 항등 행렬로 설정하여 학습 중에 모션 모델링을 간헐적으로 비활성화하는 연산이 포함된다. MFG는 모션이 비활성화될 때마다 이미지가 학습 샘플로 사용되는 공동 이미지-동영상 전략과 원활하게 통합된다.
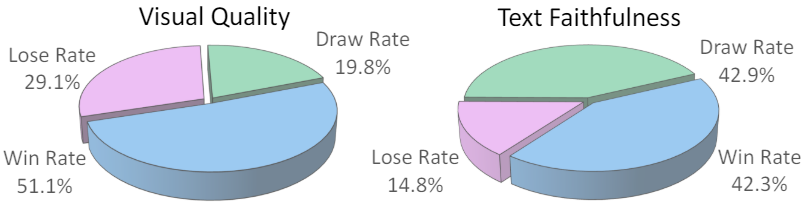
인간 평가에서 GenTron은 시각적 품질에서 51.1%의 승률, 텍스트 정렬에서 42.3%의 승률을 달성하며 SDXL을 능가하였다. 특히 T2ICompBench에 대해 벤치마킹한 경우 GenTron은 attribute binding, 물체 관계, 복잡한 합성 처리 등 다양한 기준에서 탁월한 성능을 보여주었다.
Method
1. Text-to-Image GenTron
GenTron은 DiT-XL/2를 기반으로 구축되었으며, 32$\times$32$\times$4 모양의 latent를 2$\times$2 패치 레이어가 있는 중첩되지 않는 토큰 시퀀스로 변환한다. 그런 다음 이러한 토큰은 일련의 transformer 블록으로 전송된다. 이러한 이미지 토큰을 latent space로 변환하기 위해 선형 디코더가 적용된다.
DiT는 transformer 기반 모델이 클래스 조건부 시나리오에서 유망한 결과를 산출한다는 것을 보여주었지만 T2I 생성 영역을 탐색하지는 않았다. 이 분야는 덜 제한적인 컨디셔닝 형식을 고려할 때 상당한 어려움을 야기한다. 특히 6.75억 개의 파라미터를 가진 가장 큰 DiT 모델인 DiT-XL/2조차도 30억 개가 넘는 파라미터를 갖는 현재 U-Net에 비해 크게 압도된다. 저자들은 이러한 한계를 해결하기 위해 특히 텍스트 컨디셔닝 접근 방식에 중점을 두고 GenTron을 30억 개 이상의 파라미터로 확장하여 transformer 기반 T2I diffusion model 모델에 대한 철저한 연구를 수행하였다.
From Class to Text Condition
T2I diffusion model은 텍스트 입력을 사용하여 이미지 생성 프로세스를 조정한다. 텍스트 컨디셔닝 메커니즘에는 두 가지 중요한 구성 요소가 포함된다. 첫 번째는 텍스트를 텍스트 임베딩으로 변환하는 텍스트 인코더를 선택하는 것이고, 두 번째는 이러한 임베딩을 diffusion process에 통합하는 방법이다.
텍스트 인코더 모델. 기존 T2I diffusion model들은 다양한 언어 모델을 사용하며 각각 고유한 장점과 한계가 있다. 저자들은 CLIP과 T5-XXL을 고려하였으며, 개별로 사용하는 경우와 함께 사용하는 경우를 모두 고려하였다.
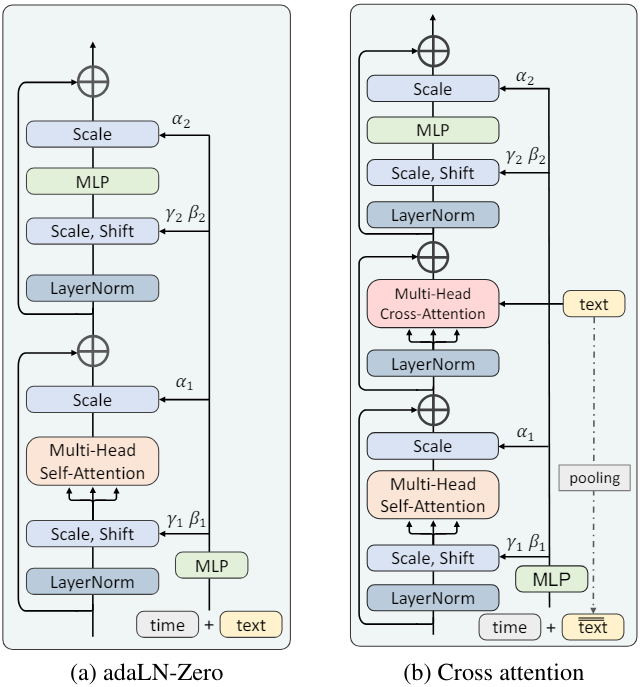
임베딩 통합. 저자들은 두 가지 방법에 중점을 두었다.
- Adaptive layernorm (adaLN): 조건부 임베딩을 feature 채널의 정규화 파라미터로 통합한다. StyleGAN과 같은 조건부 생성 모델링에 널리 사용되며 DiT에서도 클래스 조건을 관리하기 위해 사용되었다.
- Cross-attention: 이미지 feature는 query 역할을 하며 텍스트 임베딩은 key와 value 역할을 한다. Attention 메커니즘을 통해 이미지 feature와 텍스트 임베딩 간의 직접적인 상호 작용이 가능하다.
클래스 임베딩과 시간 임베딩을 먼저 concatenate하여 함께 처리하는 DiT와 달리 시간 임베딩을 별도로 모델링하기 위해 cross-attention과 함께 adaLN의 사용을 유지한다. 이 디자인의 기본 근거는 모든 공간적 위치에서 일관된 시간 임베딩이 adaLN의 글로벌 변조 능력의 이점을 누릴 수 있다는 점이다. 또한 시간 임베딩에 풀링된 텍스트 임베딩도 더한다.
Scaling Up GenTron

저자들은 모델 크기를 실질적으로 확장하는 것의 영향을 탐색하기 위해 GenTron-G/2라고 하는 GenTron의 고급 버전을 개발했다. 이 고급 버전은 Scaling vision transformers 논문에 설명된 스케일링 원칙에 따라 다음 세 가지 중요한 측면을 스케일링하는 데 중점을 두었다.
- Depth: Transformer 블록 수
- Width: 패치 임베딩의 차원
- MLP Width: MLP의 hidden dimension
GenTron 모델의 사양과 구성은 위 표에 자세히 나와 있다. 특히 GenTron-G/2 모델은 30억 개가 넘는 파라미터를 갖고 있다. 이는 현재까지 개발된 가장 큰 transformer 기반 diffusion model이다.
2. Text-to-Video GenTron
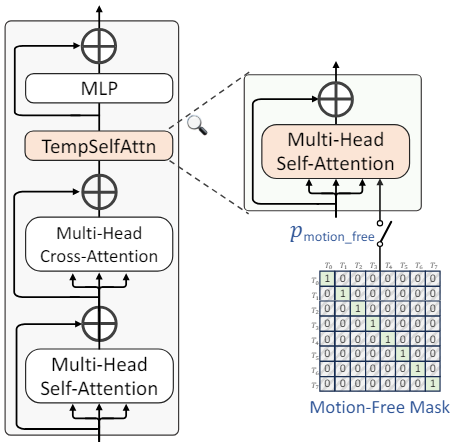
GenTron-T2V Architecture
Temporal self-attention. T2I U-Net에 temporal convolution layer와 temporal transformer block을 모두 추가하는 기존 접근 방식과 달리, GenTron은 가벼운 temporal self-attention (TempSelfAttn) 레이어만 각 transformer block에 통합하였다. TempSelfAttn 레이어는 cross-attention 레이어 바로 뒤와 MLP 레이어 앞에 배치된다. 또한 TempSelfAttn 레이어에 들어가기 전에 cross-attention 레이어의 출력을 reshape한 다음 통과시킨 후 원래 형식으로 다시 reshape한다.
\[\begin{aligned} x &= \textrm{rearrange} (x, \textrm{(b t) n d} \rightarrow \textrm{(b n) t d}) \\ x &= x + \textrm{TempSelfAttn} (\textrm{LN} (x)) \\ x &= \textrm{rearrange} (x, \textrm{(b n) t d} \rightarrow \textrm{(b t) n d}) \end{aligned}\]여기서 b, t, n, d는 각각 batch size, 프레임 수, 프레임당 패치 수, 채널 차원을 나타낸다. 이 간단한 TempSelfAttn 레이어는 모션을 캡처하는 데 충분하며 시간 모델링을 켜고 끄는 것이 편리해진다.
초기화. 사전 학습된 T2I 모델을 T2I와 T2V 모델 간의 공유 레이어를 초기화하기 위한 기반으로 사용한다. 새로 추가된 TempSelfAttn 레이어의 경우 출력 projection layer의 가중치와 편향을 0으로 초기화한다. 이를 통해 T2V fine-tuning이 시작될 때 TempSelfAttn 레이어가 0을 출력하여 skip-connection과 함께 항등 매핑으로 기능하도록 보장한다.
Motion-Free Guidance
직면한 문제. 현재 T2V diffusion model은 프레임당 시각적 품질이 T2I 모델보다 크게 뒤떨어진다. 특히 원래의 T2I 모델과 비교할 때 fine-tuning 후 T2V 모델의 시각적 품질이 현저하게 저하된다. 이러한 문제는 일반적으로 transformer 기반 T2V에 국한되지 않고 현재 T2V diffusion model에 존재한다.
문제 분석. 저자들은 이 문제가 주로 두 가지 요인에서 비롯된 것으로 추정하였다.
- 동영상 데이터의 특성: 동영상 데이터셋은 이미지 데이터셋에 비해 품질과 양 모두 부족한 경우가 많다. 또한 많은 동영상 프레임이 모션 블러와 워터마크로 인해 손상되어 시각적 품질이 더욱 저하된다.
- Fine-tuning 방식: 동영상 fine-tuning 중 시간적 측면 최적화에 초점을 맞추면 공간적 시각적 품질이 의도치 않게 손상되어 생성된 동영상의 전반적인 품질이 저하될 수 있다.
해결 방법 1: 이미지-동영상 공동 학습. 데이터 측면에서는 동영상 데이터 부족을 완화하기 위해 이미지-동영상 공동 학습 전략을 채택한다. 또한, 공동 학습은 학습을 위해 두 데이터 유형을 모두 통합함으로써 두 데이터셋 간의 도메인 불일치 문제를 완화하는 데 도움이 된다.
해결 방법 2: motion-free guidance. 동영상 클립 내의 시간적 움직임을 T2I/T2V diffusion model의 텍스트 컨디셔닝과 유사할 수 있는 특수 컨디셔닝 신호로 처리한다. 이를 바탕으로 생성된 동영상에서 모션 정보의 가중치를 변조하기 위해 classifier-free guidance에서 영감을 받은 motion-free guidanc (MFG)를 제안하였다.
Classifier-free guidance는 특정 학률로 조건부 텍스트가 빈 문자열로 대체된다. 이와 비슷하게 \(p_\textrm{motion_free}\)의 확률로 temporal attention을 무효화하기 위해 단위 행렬을 사용한다. 이 구성은 temporal self-attention이 하나의 프레임 내에서 작동하도록 제한하며, temporal self-attention은 시간적 모델링을 위한 유일한 연산자이다. 따라서 motion-free attention mask를 사용하면 동영상 diffusion process에서 시간적 모델링을 비활성화할 수 있다.
Inference 중에는 텍스트와 모션 컨디셔닝이 적용된다. Score 추정치를 다음과 같이 수정할 수 있다.
\[\begin{aligned} \tilde{\epsilon}_\theta &= \epsilon_\theta (x_t, \varnothing, \varnothing) \\ &+ \lambda_T \cdot (\epsilon_\theta (x_t, c_T, c_M) - \epsilon_\theta (x_t, \varnothing, c_M)) \\ &+ \lambda_M \cdot (\epsilon_\theta (x_t, \varnothing, c_M) - \epsilon_\theta (x_t, \varnothing, \varnothing)) \end{aligned}\]여기서 $c_T$와 $c_M$은 텍스트 조건과 모션 조건이다. $\lambda_T$와 $\lambda_M$은 각각 텍스트와 모션의 guidance scale로, 생성된 샘플이 각각 텍스트 조건, 모션 조건과 얼마나 강하게 일치하는지 제어한다. 저자들은 $\lambda_T = 7.5$로 고정하고 $\lambda_M \in [1.0, 1.3]$을 조정하는 것이 최상의 결과를 얻는 경향이 있다는 것을 경험적으로 발견했다.
해결 방법 통합. 다음과 같은 방법으로 두 해결 방법을 통합할 수 있다. 학습 단계에서 모션이 생략되면 이미지-텍스트 쌍을 로드하고 이미지를 $T -1$번 반복하여 $T$개의 프레임을 생성한다. 반대로 모션이 포함된 경우 동영상 클립을 로드하고 $T$개의 프레임을 추출한다.
Experiments
- 학습 디테일
- optimizer: AdamW (learinng rate = $10^{-4}$)
- T2I 모델
- multi-stage procedure
- 256$\times$256에서 batch size 2048, 50만 step으로 학습
- 512$\times$512에서 batch size 784, 30만 step으로 학습
- GPU 메모리 사용량을 최적화하기 위해 Fully Sharded Data Parallel (FSDP)와 activation checkpointing (AC)을 도입
- multi-stage procedure
- T2V 모델
- 동영상의 짧은 쪽이 512, FPS가 24가 되도록 전처리
- 128개의 동영상 클립을 batch로 사용
- 각 클립은 4 FPS로 캡처된 8개의 프레임으로 구성됨
1. Main Results of GenTron-T2I
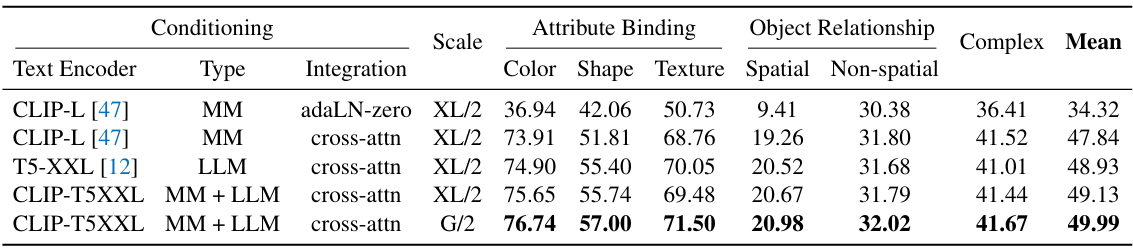
다음은 컨디셔닝과 모델 스케일에 따른 성능을 비교한 표이다.
다음은 adaLN-Zero와 cross-attention을 비교한 결과이다. (프롬프트: “A panda standing on a surfboard in the ocean in sunset.”)

다음은 모델 스케일에 따른 결과를 비교한 것이다. (프롬프트: “a cat reading a newspaper”)

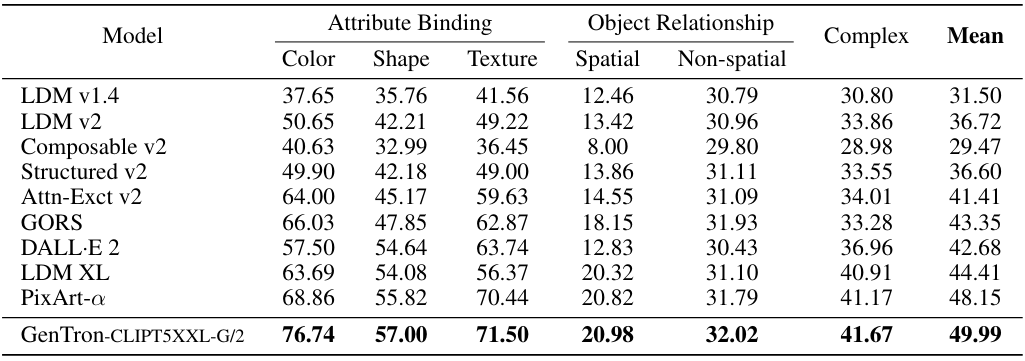
다음은 T2I-CompBench에서 기존 방법들과 성능을 비교한 표이다.
다음은 user study 결과이다.
2. GenTron-T2V Results
다음은 GenTron-T2V의 생성 결과이다. 프롬프트는 각각
- “Teddy bear walking down 5th Avenue front view beautiful sunset”
- “A dog swimming”
- “A giant tortoise is making its way across the beach”
- “A dolphin jumping out of the water”
이다.

다음은 motion-free guidance의 영향을 비교한 결과이다.
