[논문리뷰] GEN3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control
CVPR 2025. [Paper] [Page] [Github]
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, Jun Gao
NVIDIA | University of Toronto | Vector Institute
5 Mar 2025
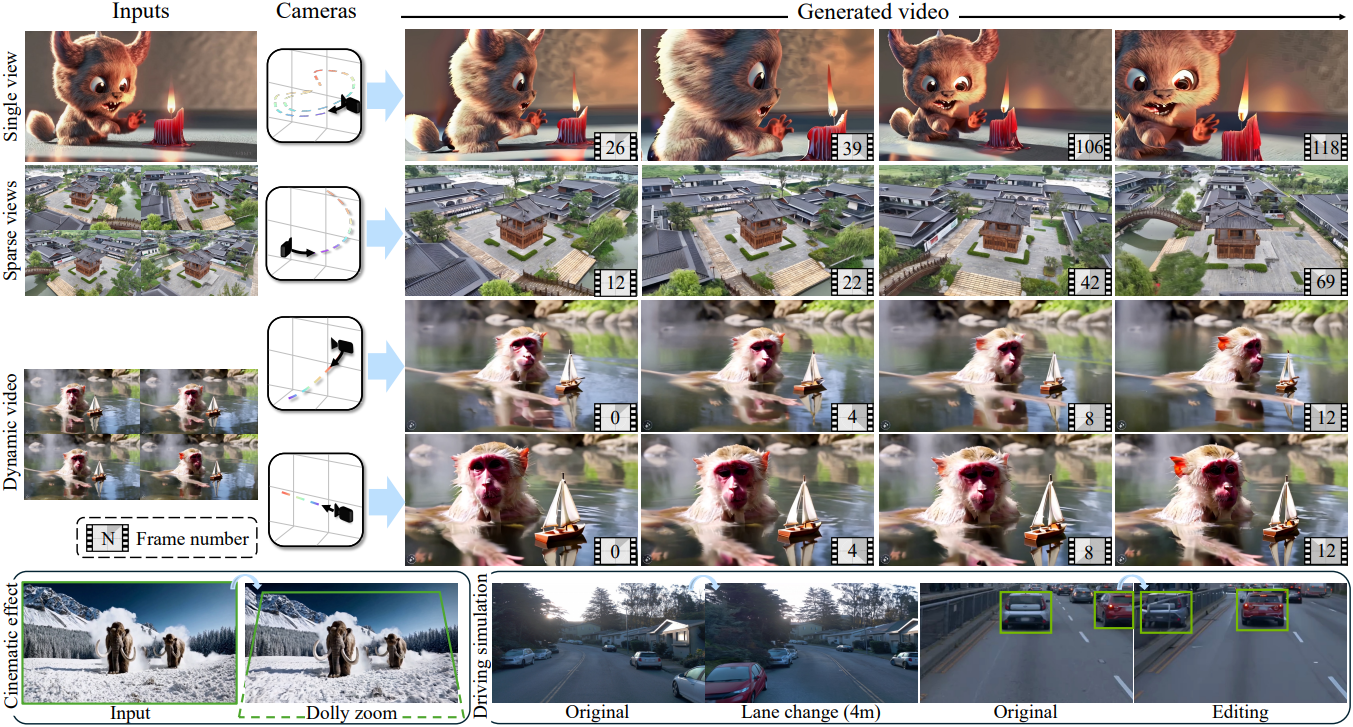
Introduction
그래픽스 파이프라인의 제어 가능성과 일관성은 근본적으로 3D 형상을 명시적으로 모델링하고 이를 2D 뷰로 렌더링하는 데 기반을 두고 있다. 본 논문에서는 동영상 생성 모델에 대한 이러한 통찰력을 구축하기 위한 첫 번째 단계로, 정확한 카메라 제어를 갖춘 일관성 있는 동영상 생성 모델인 GEN3C를 제안하였다. 핵심은 사용자가 제공한 이미지에서 구성된 근사화된 3D 형상이며, 동영상 생성을 가이드하기 위해 모든 카메라 궤적에 정확하게 projection할 수 있어 시각적 일관성을 위한 강력한 컨디셔닝을 제공한다. 또한 동영상 생성 모델을 사용한 렌더링은 사전 학습된 대형 모델의 풍부한 prior를 활용하여 sparse view 설정에서의 novel view synthesis (NVS)를 가능하게 한다.
구체적으로, 입력 이미지 또는 이전에 생성된 동영상 프레임의 깊이 추정치를 unprojection하여 포인트 클라우드로 표현되는 3D 캐시를 구성한다. 사용자로부터 카메라 궤적을 얻은 다음, 3D 캐시를 렌더링하고 렌더링된 동영상을 동영상 모델의 컨디셔닝 입력으로 사용한다. 동영상 모델은 불완전하게 렌더링된 동영상을 고품질 동영상으로 변환하도록 fine-tuning되어 3D unprojection-projection 프로세스에서 비롯된 모든 아티팩트를 수정하고 누락된 정보를 채운다.
이런 방식으로 카메라를 정밀하게 제어하고 생성된 동영상이 시간에 대한 일관성을 유지하도록 한다. 여러 뷰가 제공되는 경우, 각 개별 뷰에 대해 별도의 3D 캐시를 유지하고 동영상 모델을 활용하여 뷰 간의 잠재적인 오정렬 및 집계를 처리한다. 3D 캐시는 3D 포인트 클라우드이기 때문에 단순히 수정하기만 하면 장면 조작이 가능하다.
Method
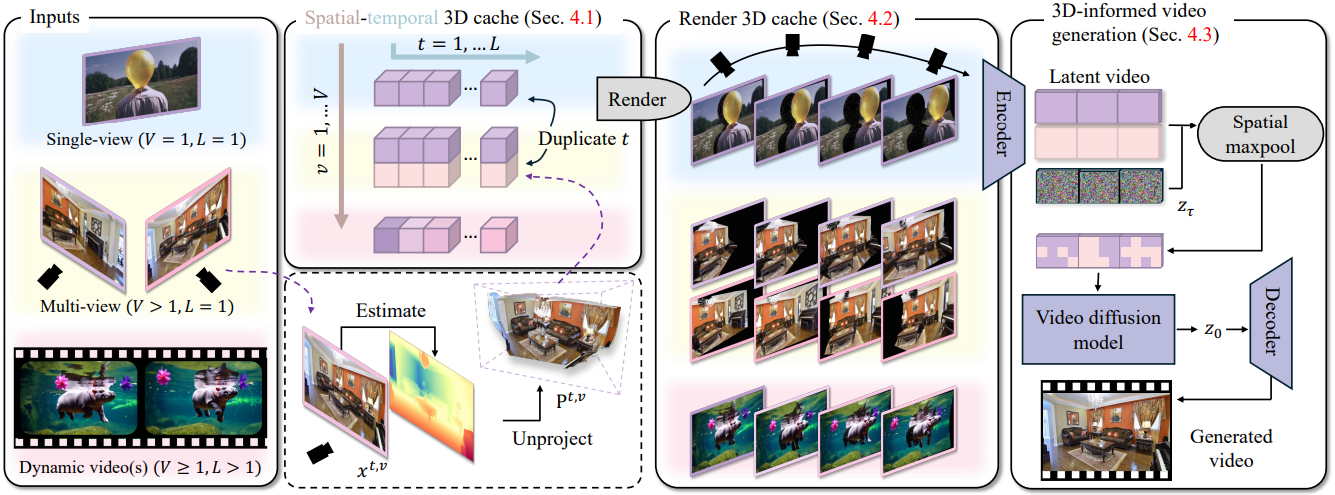
1. Building a Spatiotemporal 3D Cache
다양한 애플리케이션과 호환되고 다양한 장면에 일반화되는 적절한 3D 캐시를 선택하는 것이 가장 중요한 고려 사항이다. 최근 깊이 추정 방법들은 다양한 도메인에서 상당한 진전을 이루었다. 따라서 저자들은 RGB 이미지의 깊이 추정 결과를 unprojection한 RGB 포인트 클라우드를 3D 캐시로 선택하였다.
구체적으로, 시공간적 3D 캐시를 유지한다. 시간 $t$에서 카메라 시점 $v$에서 본 RGB 이미지에 대해, 이 RGB 이미지의 깊이 추정 결과를 unprojection하여 포인트 클라우드 $\textbf{P}^{t,v}$를 생성한다. 카메라 뷰의 수를 $V$, 시간 차원의 길이를 $L$이라고 하면, 3D 캐시는 $L \times V$ 포인트 클라우드 배열이다.
저자들은 다운스트림 애플리케이션에 따라 시공간적 3D 캐시를 구축하였다.
- 단일 이미지에서 동영상 생성: 주어진 이미지에 대해 하나의 캐시 요소만 생성하고 ($V = 1$), 시간 차원을 따라 $L$번 복제하여 길이 $L$의 동영상을 생성한다.
- 정적 NVS: 사용자가 제공한 $V$개의 이미지 각각에 대해 하나의 캐시 요소를 생성하고, 시간 차원을 따라 $L$번 복제한다.
- 동적 NVS: 사용자가 제공하거나 다른 동영상 모델에서 생성한 길이 $L$의 초기 동영상에서 캐시를 구축한다.
카메라 포즈가 이미지 또는 동영상과 함께 제공된다고 가정한다. 그렇지 않은 경우 DROID-SLAM을 사용하여 카메라 포즈를 추정한다.
선택적으로, 구축한 3D 캐시는 물체를 제거하거나 추가하는 등 편집하거나 시뮬레이션할 수 있다.
2. Rendering the 3D Cache
포인트 클라우드는 모든 카메라 궤적을 따라 쉽고 효율적으로 렌더링할 수 있다. 이러한 렌더링 함수 $\mathcal{R}$은 $\textbf{P}^{t,v}$를 카메라 $\textbf{C}^t$에서 본 RGB 이미지 $I^{t,v}$와, 렌더링할 때 덮이지 않은 픽셀을 표시하는 마스크 $M^{t,v}$에 매핑한다.
\[\begin{equation} (I^{t,v}, M^{t,v}) := \mathcal{R} (\textbf{P}^{t,v}, \textbf{C}^t) \end{equation}\]마스크 $M^{t,v}$는 이미지 $I^{t,v}$의 채워야 하는 영역을 식별한다.
사용자가 입력한 새로운 카메라 포즈의 시퀀스 \(\textbf{C} = (\textbf{C}_1, \ldots, \textbf{C}_L)\)에 대해, 모든 \(\textbf{P}^{t,v}\)를 렌더링하고 $V$개의 동영상 $(\mathcal{R} (\textbf{P}^{1,v}, \textbf{C}^1), \ldots, \mathcal{R} (\textbf{P}^{L,v}, \textbf{C}^L))$를 얻는다. 렌더링된 이미지 $(I^{1,v}, \ldots, I^{L,v})$와 마스크 $(M^{1,v}, \ldots, M^{L,v})$를 카메라 뷰 $v$에 대한 시간 차원을 따라 concat하여, 이미지와 마스크에 대한 동영상 $\textbf{I}^v \in \mathbb{R}^{L \times 3 \times H \times W}$과 $\textbf{M}^v \in \mathbb{R}^{L \times 1 \times H \times W}$를 얻는다.
3. Fusing and Injecting the 3D Cache
3D 캐시의 렌더링으로 동영상 diffusion model을 컨디셔닝할 때 가장 중요한 과제는 3D 캐시가 불완전한 깊이 예측이나 일관되지 않은 조명으로 인해 다양한 카메라 시점에서 일관되지 않을 수 있다는 것이다. 따라서 $V = 1$인 경우에 모델은 일관된 예측을 위해 정보를 집계해야 한다. 사전 학습된 동영상 diffusion model은 방대한 인터넷 데이터로 학습되었기 때문에 새로운 파라미터가 일반화되지 않을 수 있으므로, 모듈은 추가 학습 가능한 파라미터의 도입을 최소화하여야 한다.
구체적으로, image-to-video diffusion model의 forward process를 수정한다.
- 고정된 VAE 인코더 $\mathcal{E}$를 사용하여 렌더링된 동영상 $\textbf{I}^v$를 인코딩하여 latent 동영상 $\textbf{z}^v = \mathcal{E} (\textbf{I}^v)$를 얻는다.
- 마스크 $\textbf{M}^v$에 따라 3D 캐시로 덮이지 않은 영역을 마스킹한다.
- 마스킹된 latent 동영상과 타겟 동영상 $\textbf{x}$의 noisy latent \(\textbf{z}_\tau = \alpha_t \mathcal{E}(\textbf{x}) + \sigma_t \epsilon\)을 latent space에서 채널 차원을 따라 concat하여 동영상 diffusion model에 공급한다.
- 여러 시점의 정보를 융합하기 위해, 각 시점을 diffusion model의 첫 번째 레이어 $\textrm{In-Layer}$에 별도로 공급하고 모든 시점에 대한 max-pooling을 적용하여 최종 feature map을 얻는다.
($\odot$은 element-wise multiplication, $\textbf{M}^{v, \prime}$은 $\textbf{M}^v$를 latent 차원으로 다운샘플링한 마스크)
결과 feature map $\textbf{z}^\prime$은 일관된 동영상을 생성하도록 fine-tuning된 동영상 diffusion model에서 추가로 처리된다.
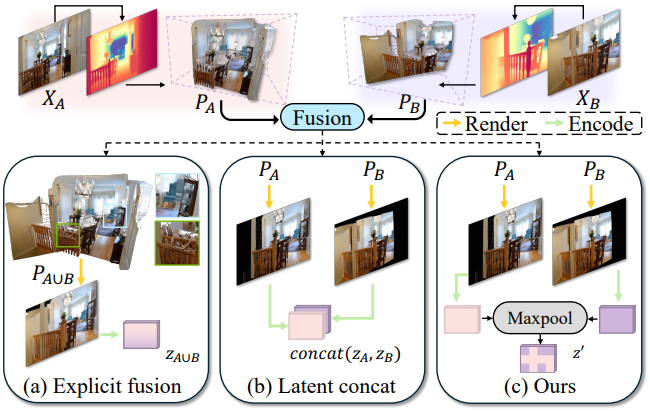
위에서 설명한 전략은 여러 뷰에서 정보를 집계하여 동영상 diffusion model에 주입하는 일반적인 메커니즘이다. 위 그림에서 설명한 것처럼, 저자들은 제안된 max-pooling 전략을 두 가지 대안들과 비교하였다.
- Explicit fusion은 3D 공간에서 포인트 클라우드를 직접 융합한다. 이 접근법은 간단하지만 깊이 정렬에 크게 의존하며 여러 시점에서 불일치가 나타날 때 아티팩트를 도입한다. 또한, 이러한 융합된 캐시에 뷰에 따른 조명 정보를 주입하는 것은 어려운 일이다. Max-pooling 전략은 모델이 뷰 정보의 집계를 처리하도록 한다.
- Concat은 채널 차원을 따라 렌더링된 캐시의 모든 latent들을 concat하는 것이다. 이 접근법은 잘 작동하지만 모델이 지원할 수 있는 최대 시점 수를 특정한 값으로 제한하고 시점에 순서를 부과해야 한다. Max-pooling 전략은 시점의 순서에 무관하다.
또 다른 핵심 디자인 선택은 마스킹 정보를 모델에 통합하는 것이다. 저자들은 처음에 마스크 채널을 latent 채널에 concat하려고 했으나, concat 연산은 추가적인 모델 파라미터를 도입하기 때문에 일반화가 잘 되지 않을 수 있다. 대신, 저자들은 마스크 값을 element-wise multiplication으로 latent 채널에 직접 적용하여 모델 아키텍처를 변경하지 않았다.
4. Model Training
3D 캐시의 렌더링을 조건 신호로 사용하여 수정된 동영상 diffusion model을 fine-tuning한다. 구체적으로, 학습 데이터에서 새 카메라 궤적을 따라, 3D 캐시의 렌더링 $\mathcal{R}(\textbf{P}^{t,v}, \cdot)$과 해당 GT RGB 동영상 $\textbf{x}$의 쌍을 만든다. 그런 다음, denoising loss와 함께 앞서 설명한 융합 전략을 사용하여 동영상 diffusion model을 fine-tuning한다.
\[\begin{equation} \mathbb{E}_{\textbf{x}_0 \sim p_\textrm{data}(\textbf{x}), \tau \sim p_\tau, \epsilon \sim \mathcal{N}(0,\textbf{I})} [\| f_\theta (\textbf{z}_\tau; \textbf{c}, \tau) - \textbf{z}_0 \|_2^2] \\ \textrm{where} \; \textbf{z}_0 = \mathcal{E} (\textbf{x}_0), \; \textbf{z}_\tau = \alpha_\tau \textbf{z}_0 + \sigma_\tau \epsilon \end{equation}\]또한 추가 조건으로 CLIP 모델을 사용하여 첫 번째 프레임을 인코딩한다.
5. Model Inference
Inference 시에는, Gaussian noise로 latent $\textbf{z}$를 초기화하고, 3D 캐시의 렌더링으로 컨디셔닝된 수정된 동영상 diffusion model를 사용하여 이 latent의 noise를 반복적으로 제거한다. 최종 RGB 동영상은 noise가 제거된 latent를 사전 학습된 VAE 디코더 $\mathcal{D}$에 입력하여 얻는다. 14프레임 동영상을 생성하는 데 하나의 A100 NVIDIA GPU에서 약 30초가 걸린다.
저자들은 길고 일관된 동영상을 생성하기 위해 3D 캐시를 점진적으로 업데이트하는 것을 제안하였다.
- 긴 동영상을 길이 $L$의 겹치는 청크로 나누고 두 연속되는 청크 사이에 한 프레임이 겹치도록 한다.
- 3D 캐시를 렌더링하고 각 청크의 프레임을 앞에서부터 순서대로 생성한다.
- 이전에 생성된 청크를 사용하여 3D 캐시를 업데이트한다.
- 청크에서 생성된 각 프레임에 대해 깊이 추정 모델을 사용하여 픽셀별 깊이를 추정한다.
- 프레임의 카메라 포즈를 알고 있으므로, reprojection error를 최소화하여 깊이 추정 결과를 기존 3D 캐시와 정렬할 수 있다.
- 정렬된 RGB-D 프레임을 3D로 unprojection하고 기존 3D 캐시와 concat한다.
- 업데이트된 3D 캐시를 사용하여 다음 프레임 청크를 예측한다.
Experiments
- 데이터셋: RE10K, DL3DV, Waymo Open Dataset (WOD)
- 깊이 추정 모델: Depth Anything V2
1. Single View to Video Generation
다음은 단일 뷰에 대한 NVS 결과이다.

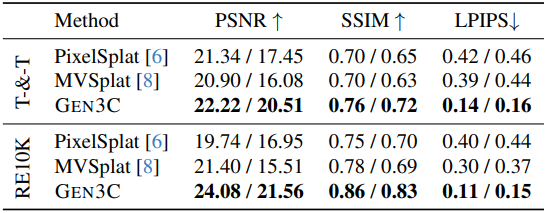
2. Two-Views Novel View Synthesis
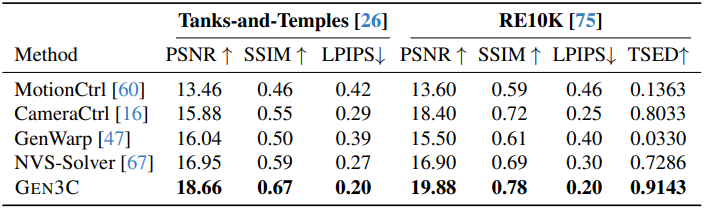
다음은 입력 뷰가 2개인 경우에 대한 NVS 결과이다. (표에서는 interpolation/extrapolation으로 비교)

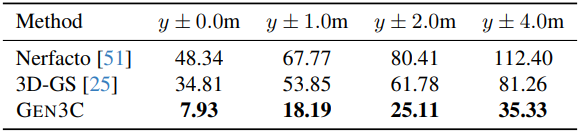
3. Novel View Synthesis for Driving Simulation
다음은 주행 장면에 대한 NVS 결과이다.

다음은 주행 장면을 편집한 예시들이다.

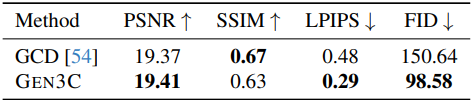
4. Monocular Dynamic Novel View Synthesis
다음은 monocular dynamic NVS에 대한 결과이다.

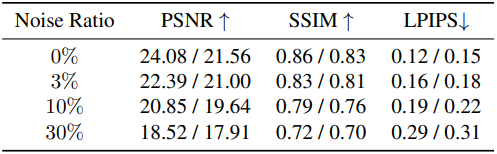
5. Ablation Study
다음은 융합 전략에 대한 ablation 결과이다.


다음은 깊이 추정에 대한 robustness 분석 결과이다. (interpolation/extrapolation)
6. Extending to Advanced Video Diffusion Model
다음은 동영상 diffusion model에 대한 영향을 비교한 예시이다. (SVD vs. Cosmos)

다음은 Cosmos를 diffusion model로 사용하였을 때의 극단적인 NVS에 대한 결과이다. (중간이 입력 뷰)
