[Technical Report 리뷰] Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Introduction
본 논문은 Gemini 시리즈의 최신 멀티모달 모델인 Gemini 1.5 Pro를 선보인다. 이것은 새로운 mixture-of-experts(MoE) 아키텍처와 효율성, 추론, 긴 컨텍스트에 대한 성능의 한계를 뛰어넘을 수 있는 고성능 멀티모달 모델의 새로운 제품군인 Gemini 1.5의 첫 번째 릴리스이다. Gemini 1.5 Pro는 매우 긴 컨텍스트를 처리하도록 제작되었다. 최대 1천만 개 이상의 토큰에서 세분화된 정보를 회상하고 추론할 수 있는 능력이 있다. 이 규모는 최신 LLM에서는 전례가 없는 수준이며 여러 문서들, 몇 시간 길이의 동영상, 거의 하루 길이의 오디오를 포함하는 긴 형식의 혼합 입력을 처리할 수 있다. Gemini 1.5 Pro는 Gemini 1.0 Pro를 능가하며 다양한 벤치마크에서 1.0 Ultra와 유사한 수준의 성능을 발휘하는 동시에 학습에 훨씬 적은 컴퓨팅을 필요로 한다.
점점 더 길어지는 컨텍스트의 데이터를 모델링하는 능력은 5개의 토큰을 사용하는 1990년대의 n-gram 모델에서, 수백 개의 토큰을 효과적으로 컨디셔닝할 수 있는 2010년대의 RNN 언어 모델, 수십만 개의 토큰을 컨디셔닝할 수 있는 최신 Transformer에 이르기까지 보다 일반적이고 유능한 언어 모델의 개발과 함께 해왔다. Gemini 1.5 Pro는 언어 모델의 컨텍스트 길이를 10배 이상 확장하여 이러한 추세를 이어간다. 수백만 개의 토큰으로 확장하면 예측 성능이 지속적으로 향상되고, 검색 task에서 거의 완벽한 recall(>99%)이 나타나고, 전체 긴 문서에서의 in-context learning과 같은 놀라운 새 능력이 많이 생긴다.
저자들은 모델의 long-context 능력의 효율성을 측정하기 위해 합성 task와 실제 task 모두에 대한 실험을 수행하였다. 모델이 산만한 상황에서 정보를 얼마나 안정적으로 기억할 수 있는지 조사하는 “needle-in-a-haystack” (NIAH, 건초 더미 속에서 바늘 찾기) task에서 Gemini 1.5 Pro는 텍스트, 동영상, 오디오 등 모든 형식에 대해 최대 수백만 개의 “건초 더미” 토큰에서 상거의 완벽하게(>99%) “바늘”을 회상한다. 또한, 텍스트 형식에서 1천만 개의 토큰으로 확장할 때에도 이 회상 성능을 유지한다. 컨텍스트의 여러 부분에 대한 검색 및 추론이 필요한 보다 현실적인 멀티모달 long-context 벤치마크(ex. 긴 문서 또는 긴 동영상에 대한 질문의 답변)에서 Gemini 1.5 Pro는 모든 입력 형식에서 모든 경쟁 모델보다 성능이 뛰어났으며, 심지어 외부 검색 방법으로 보강된 경쟁 모델보다도 성능이 뛰어났다.
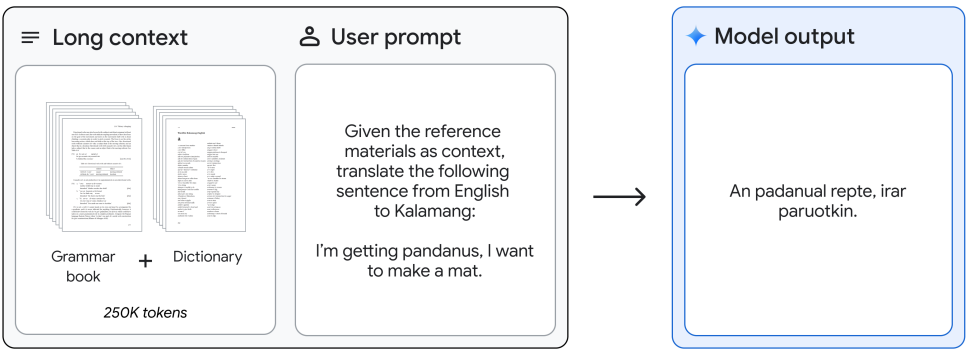
또한 본 논문은 매우 긴 컨텍스트를 통해 가능해진 Gemini 1.5 Pro의 in-context learning 능력을 정성적으로 보여준다. 예를 들어, 언어 문서들에서 새로운 언어를 번역하는 방법을 학습하였다. Gemini 1.5 Pro는 교육 자료(500페이지의 언어 문서, 사전, 약 400개의 병렬 문장)가 모두 컨텍스트로 제공되므로 영어에서 200명 미만이 사용하는 언어인 Kalamang으로 번역하는 방법을 학습할 수 있다. 또한 그 번역의 질이 동일한 자료를 통해 배운 사람의 번역의 질과 비슷하다.
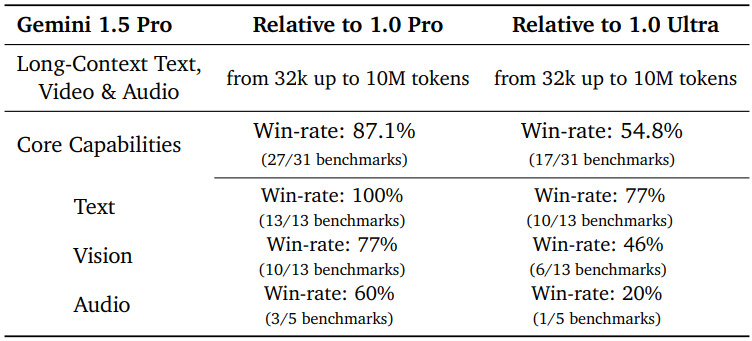
중요한 점은 이러한 long-context 성능의 도약이 모델의 핵심 멀티모달 능력을 희생하면서 발생하지 않는다는 것이다. 전반적으로 Gemini 1.5 Pro는 Gemini 1.0 Pro를 크게 능가하여 대부분의 벤치마크(27/31)에서 더 나은 성능을 발휘하고 특히 수학, 과학 및 추론(+28.9%), 다국어(+22.3%), 동영상 이해(+11.2%), 코드(+8.9%)에 대한 성능이 크게 증가했다. 그러나 더욱 눈에 띄는 비교는 다양한 능력을 갖춘 SOTA 모델인 Gemini 1.0 Ultra와의 비교이다. Gemini 1.5 Pro는 훨씬 적은 학습 컴퓨팅을 사용하고 서비스 효율성이 더 높음에도 불구하고 벤치마크의 절반 이상(16/31), 특히 텍스트 벤치마크(10/13)와 다수의 비전 벤치마크(6/13)에서 더 나은 성능을 보였다.
Model Architecture
Gemini 1.5 Pro는 Gemini 1.0의 연구 발전과 멀티모달 능력을 기반으로 하는 sparse mixture-of-expert(MoE) Transformer 기반 모델이다. 또한 Gemini 1.5 Pro는 Google의 오랜 MoE 연구 역사와 더 광범위한 언어 모델 연구를 기반으로 하였다. MoE 모델은 학습된 라우팅 함수를 사용하여 처리를 위해 모델 파라미터의 부분집합에 입력을 보낸다. 이러한 형태의 조건부 계산을 통해 모델은 주어진 입력에 대해 활성화되는 파라미터 수를 일정하게 유지하면서 전체 파라미터 수를 늘릴 수 있다.
거의 전체 모델 스택(아키텍처, 데이터, 최적화, 시스템)에 걸쳐 이루어진 다양한 개선을 통해 Gemini 1.5 Pro는 Gemini 1.0 Ultra와 비슷한 품질을 달성하는 동시에 훨씬 적은 학습 컴퓨팅을 사용하고 서비스 효율성이 훨씬 더 높아졌다. 또한 성능 저하 없이 최대 1천만 개의 토큰 입력에 대한 long-context 이해를 가능하게 하는 일련의 중요한 아키텍처 변경 사항을 통합하였다. 실제 데이터로 변환된 이 컨텍스트 길이를 통해 거의 하루 분량의 오디오 녹음(22시간), 1440페이지 분량의 책 “War and Peace” 전체(587,287단어)의 10배 이상, Flax 전체 코드 베이스(41,070줄의 코드), 1FPS의 3시간 분량의 동영상을 쉽게 처리할 수 있다. 또한 모델은 기본적으로 멀티모달이고 다양한 형식의 데이터 인터리빙을 지원하므로 동일한 입력 시퀀스에서 오디오, 비전, 텍스트, 코드 입력의 혼합을 지원할 수 있다.
Training Infrastructure and Dataset
Gemini 1.0 Ultra와 Gemini 1.0 Pro와 마찬가지로 Gemini 1.5 Pro는 여러 데이터 센터에 분산된 Google TPUv4 가속기의 여러 4096-chip 포드와 다양한 멀티모달 및 다국어 데이터에서 학습을 받았다. 사전 학습 데이터셋에는 웹 문서 및 코드를 포함하여 다양한 도메인에 걸친 데이터가 포함되어 있으며 이미지, 오디오, 동영상 콘텐츠가 통합되어 있다. 명령 튜닝 단계에서 인간 선호도 데이터를 기반으로 멀티모달 데이터 컬렉션(명령 쌍과 적절한 응답들)에 대해 Gemini 1.5 Pro를 fine-tuning했다. (자세한 내용은 Gemini 1.0 technical report를 참조)
Long-context Evaluation
기존 평가들은 대규모 멀티모달 모델의 새롭고 빠르게 발전하는 능력으로 인해 점점 더 어려워지고 있다. 일반적으로 개별 모달리티에 초점을 맞추거나 컨텍스트 길이가 더 짧은 task로 제한된다. 따라서 현실의 긴 혼합 모달리티의 미묘한 요구 사항에 대한 벤치마크의 필요성이 증가하고 있다. 이 중에서 저자들은 혼합 모달리티의 긴 시퀀스에 대한 추론 능력에 대한 정량적 평가를 핵심 과제로 강조하였다.
1. Qualitative Examples of Multimodal Long-Context Capabilities
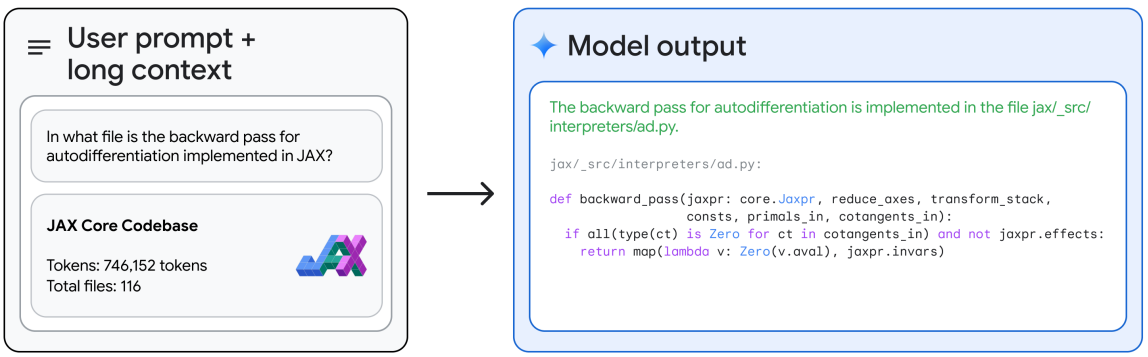
- JAX와 같은 대규모 코드베이스 전체를 수집하고 이에 대한 매우 구체적인 쿼리에 응답할 수 있다. 전체 746,152개의 토큰 JAX 코드베이스에서 핵심 자동 미분법의 특정 위치를 식별할 수 있다.
- 레퍼런스 문법 책과 단어 목록(사전)이 제공되면 동일한 자료에서 배운 인간과 비슷한 품질로 영어에서 Kalamang으로 번역할 수 있다.
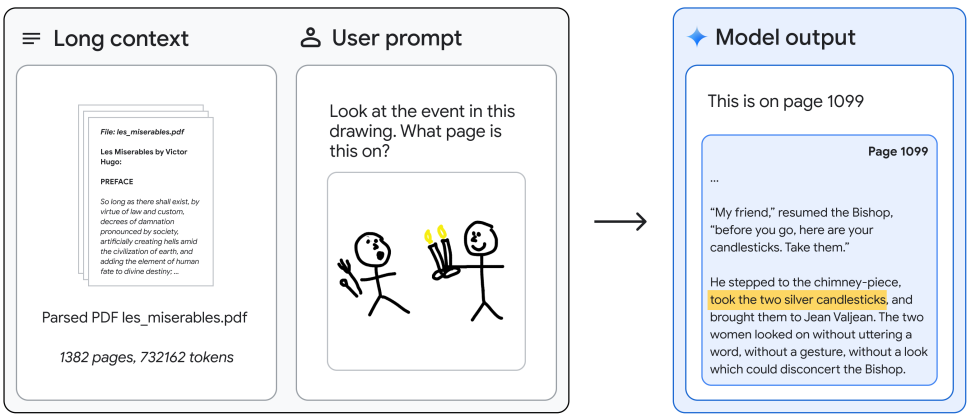
- 레미제라블의 전체 텍스트(1382 페이지, 73.2만 토큰)를 바탕으로 이미지 쿼리에 응답할 수 있으며, 멀티모달을 사용하여 손으로 그린 스케치에서 유명한 장면을 찾을 수 있다.
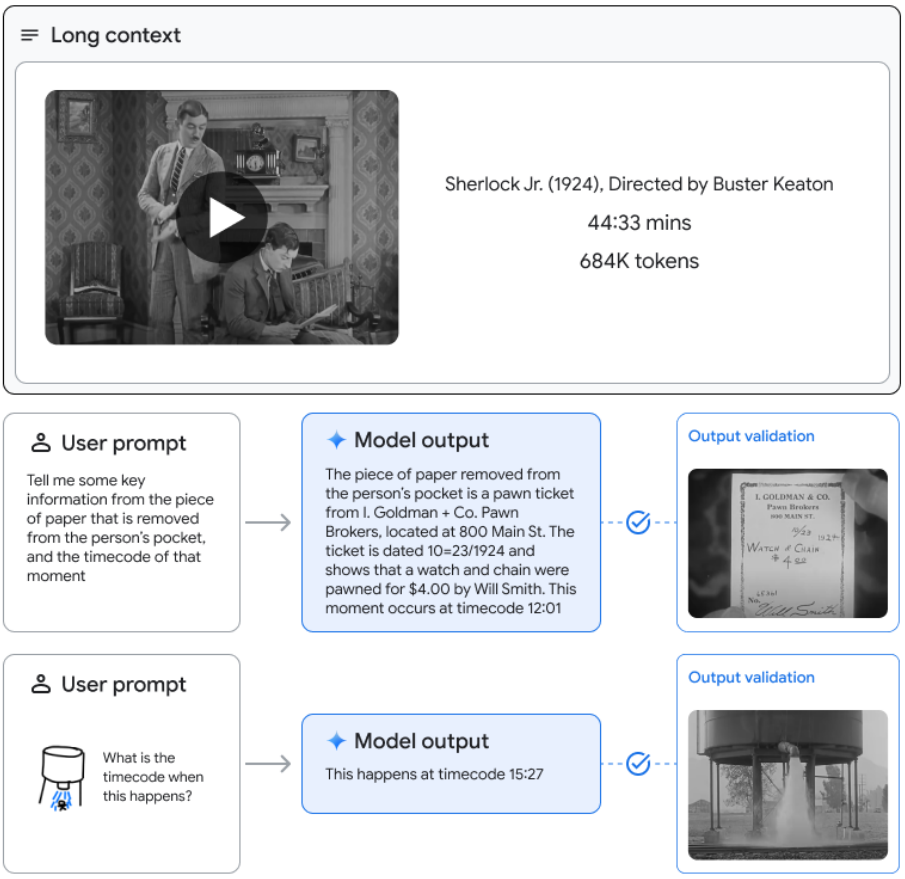
- 45분짜리 전체 영화에 대해 질문하면 특정 프레임에서 텍스트 정보를 검색 및 추출하고 해당 타임스탬프를 제공한다.
2. Long-context Evaluations
Perplexity
다음은 긴 문서 및 코드 데이터에서 토큰 위치에 따른 누적 평균 negative log-likelihood (NLL)이다. 값이 낮을수록 더 나은 예측을 나타낸다.
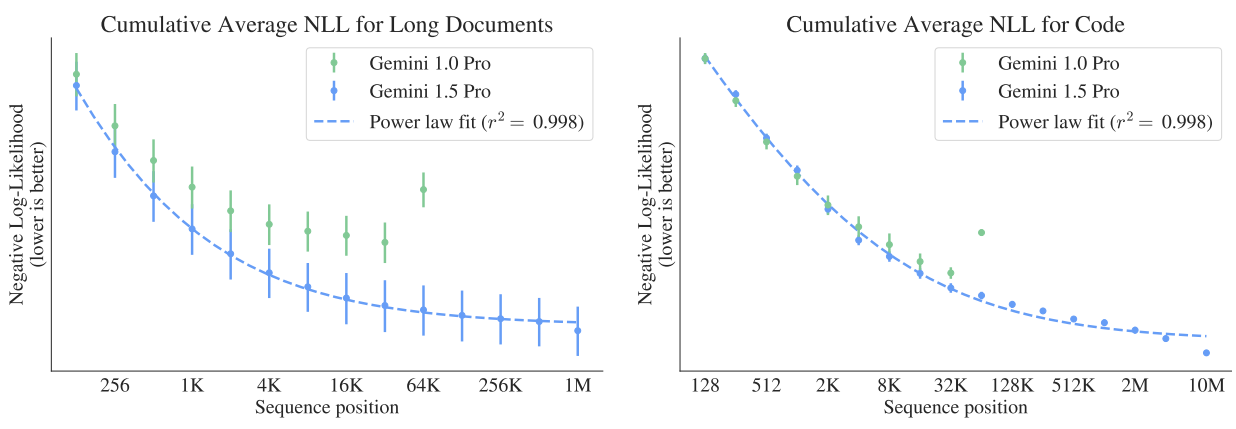
Gemini 1.5 Pro는 긴 문서의 경우 최대 100만 개의 토큰, 코드의 경우 최대 1000만 개의 토큰까지 향상된 예측을 보여주는 반면, Gemini 1.0 Pro는 최대 32,000개의 토큰만 향상된다. NLL은 100만 토큰(문서)과 200만 토큰(코드)까지 power-law 추세를 따르며 1000만 토큰에서는 추세를 벗어난다.
Text-Haystack
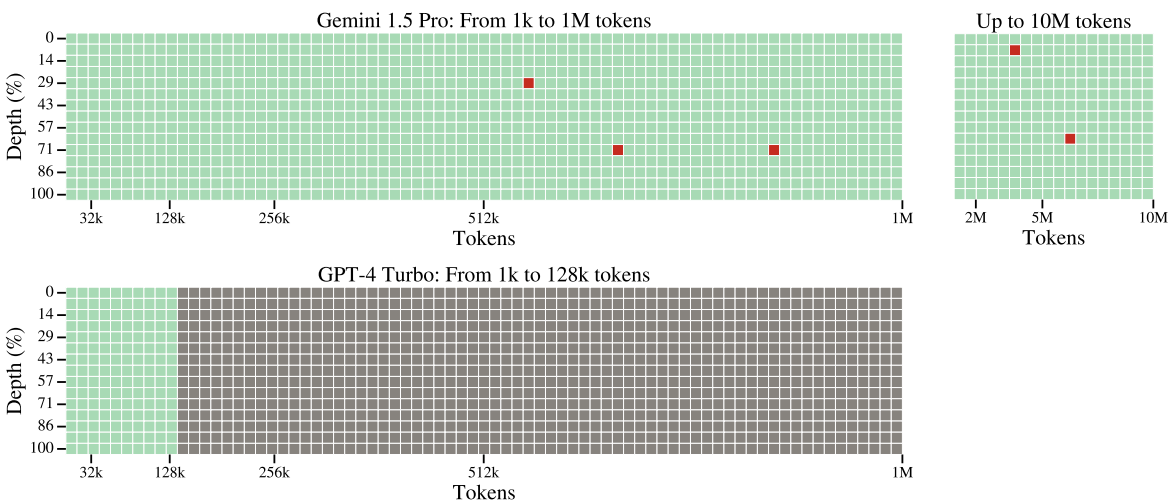
저자들은 시퀀스(건초 더미)의 다양한 위치에 삽입된 텍스트(바늘)를 검색하는 모델의 능력을 테스트하는 needle-in-a-haystack 평가를 사용하여 long-context recall을 테스트하였다. 원하는 문맥 길이를 채우기 위해 Paul Graham이 작성한 일련의 에세이들을 사용하였다. 컨텍스트의 처음부터 끝까지 선형 간격으로 바늘을 삽입한다. 여기서 바늘은 The special magic {city} number is: {number}이다. 여기서 city와 number는 각 쿼리에 대해 다양하다. 모델에게 Here is the magic number:라는 프롬프트를 입력한다.
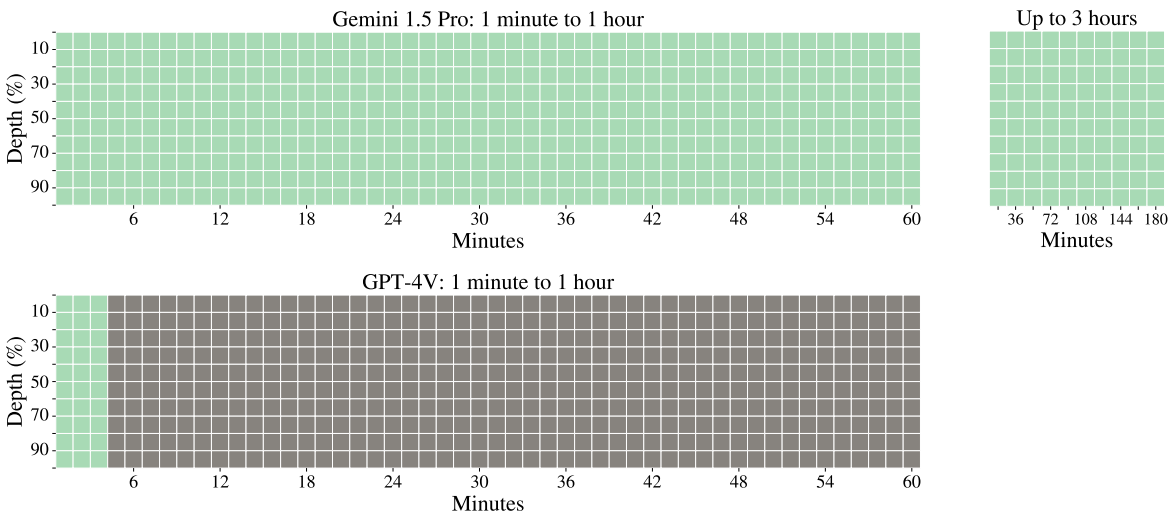
다음은 텍스트 needle-in-a-haystack task에 대해 Gemini 1.5 Pro와 GPT-4 Turbo를 비교한 그림이다. 녹색 셀은 모델이 비밀번호를 성공적으로 검색했음을 나타내고, 회색 셀은 API 오류를 나타내며, 빨간색 셀은 모델 응답에 비밀번호가 포함되지 않았음을 나타낸다. x축은 컨텍스트 길이이고 y축은 깊이 백분율이다. 예를 들어 100%의 깊이는 입력 맨 끝에 바늘이 삽입되는 것이며 0%의 깊이는 맨 처음 삽입되는 것이다.
Video-Haystack
Gemini 1.5 Pro는 기본적으로 멀티모달이므로 long-context 능력을 다른 모달리티로 직접 변환하여 몇 시간의 동영상에서 특정 정보를 검색할 수 있다. 3시간 길이의 동영상(건초 더미)에서 무작위 프레임(바늘)에 포함된 정보를 검색하도록 모델에 요청한다. 초당 1프레임으로 샘플링된다. 구체적으로 전체 AlphaGo 다큐멘터리의 두 복사본을 연속해서 연결하여 구성된 3시간 54초 동영상(총 10856 프레임, 280만 토큰)의 무작위로 샘플링된 동영상 프레임에 The secret word is “needle”이라는 텍스트를 오버레이한다. 비디오를 제공한 후 모델에게 What is the secret word?라는 질문에 대답하도록 요청한다.
다음은 동영상 needle-in-a-haystack task에 대해 Gemini 1.5 Pro와 GPT-4V를 비교한 그림이다.
Audio-Haystack
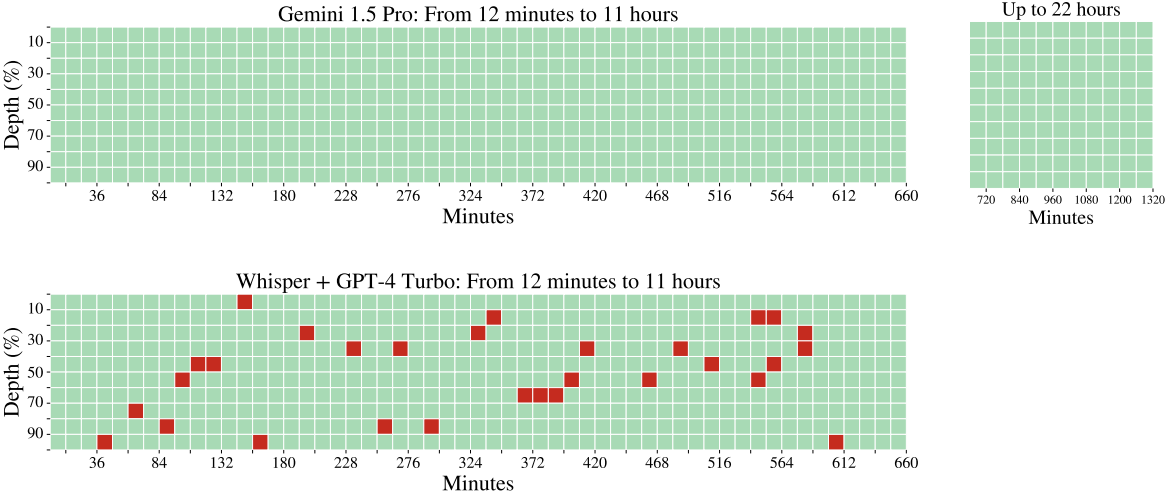
다음은 오디오 needle-in-a-haystack task에 대해 Gemini 1.5 Pro와 Whisper + GPT-4V Turbo를 비교한 그림이다. 저자들은 the secret keyword is needle이라고 말하는 몇 초 동안 지속되는 매우 짧은 오디오 클립을 12분에서 최대 22시간의 오디오 신호 내에 숨겼다.
Improved Diagnostics
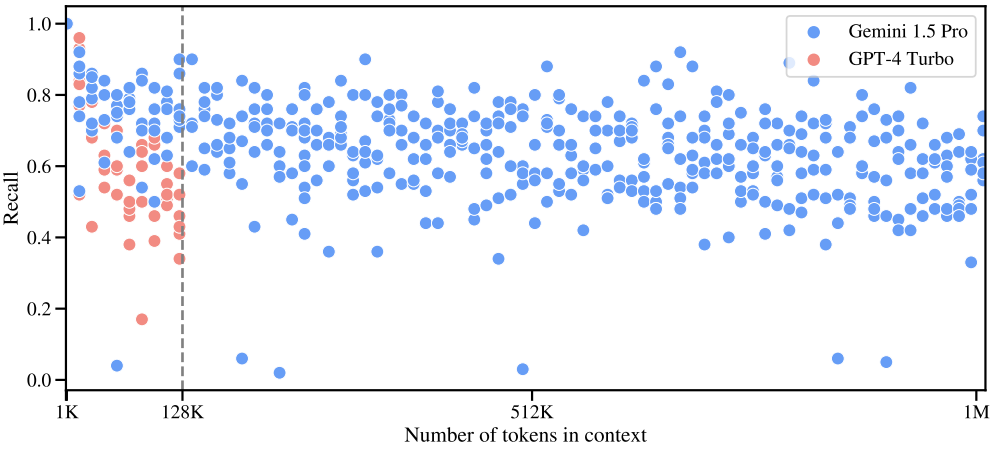
저자들은 task를 확장하기 위해 각 건초 더미의 고유한 바늘 수를 늘리고 모델이 이를 모두 검색하도록 요구하였다. 최대 100만 개 토큰의 컨텍스트 길이에 대해 100개의 서로 다른 바늘을 삽입하고 검색된 올바른 바늘의 총 수를 측정했다.
다음은 한 번에 100개의 고유한 바늘을 검색해야 하는 “multiple needles-in-haystack” task의 검색 성능을 GPT-4 Turbo와 비교한 그래프이다.
In-context language learning – Learning to translate a new language from one book
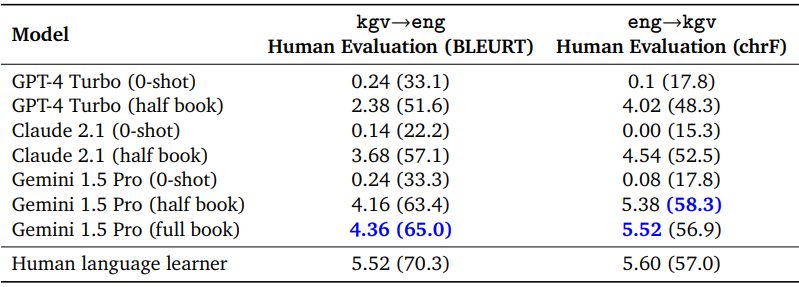
다음은 Kalamang과 영어 사이의 번역에 대한 정량적 결과를 비교한 표이다.
Long-document QA
다음은 세 가지 컨텍스트 크기에 걸쳐 대규모 텍스트 컬렉션에 대한 질문에 답하는 능력을 평가한 표이다.
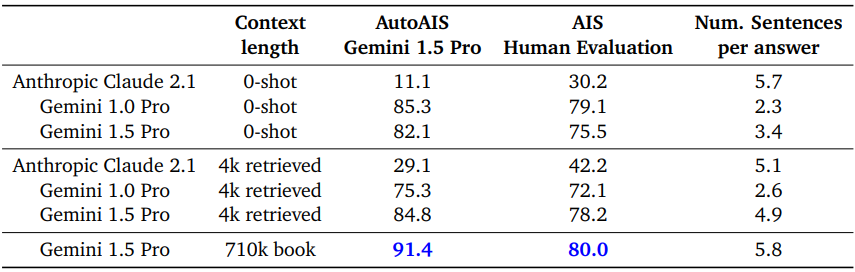
Long-context Audio
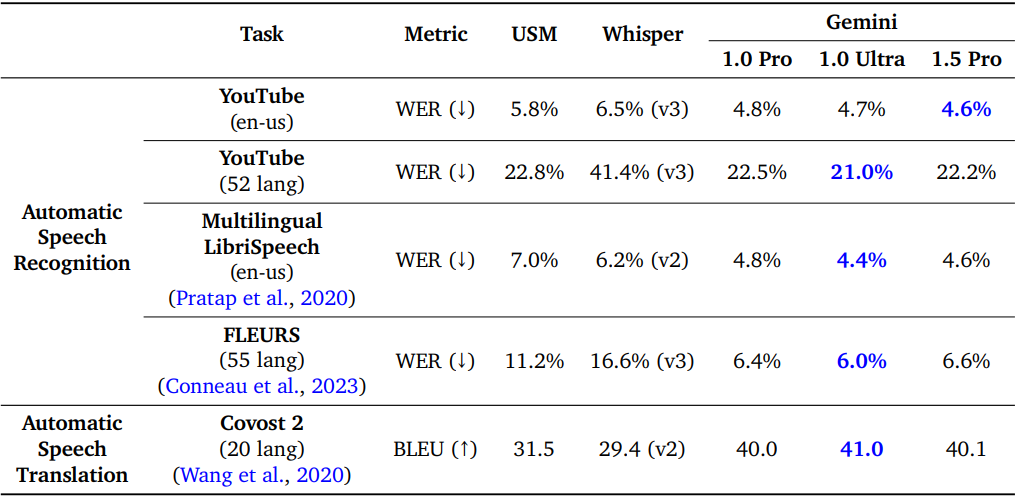
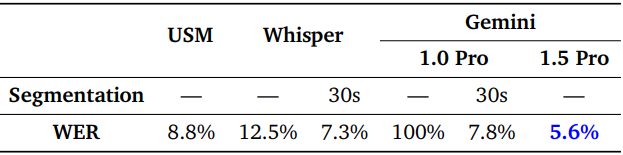
다음은 15분 동영상에서 다양한 모델의 word error rate (WER)를 평가한 표이다.
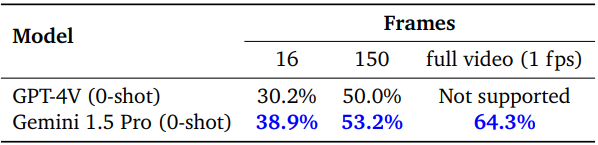
Long-context Video QA
다음은 1H-VideoQA에 대하여 GPT-4V와 비교한 표이다.
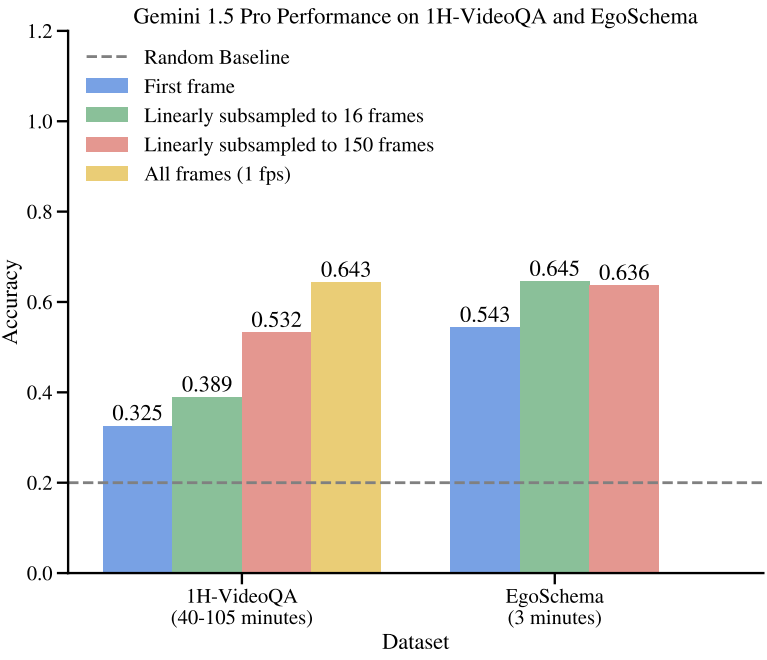
다음은 1H-VideoQA와 EgoSchema에서 1, 16, 150 프레임으로 선형 서브샘플링할 때 Gemini 1.5 Pro의 정확도를 비교한 그래프이다.
Core Capability Evaluations
다음은 코어 능력 평가 결과를 Gemini 1.0 Pro, Gemini 1.0 Ultra와 비교한 표이다.
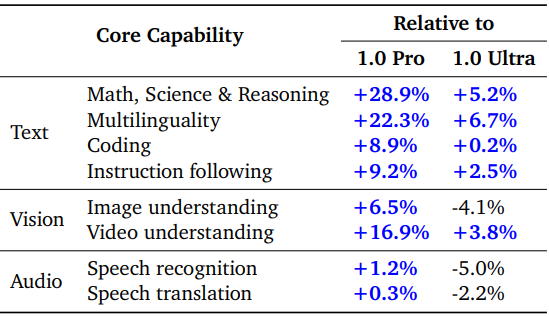
1. Core Text Evals
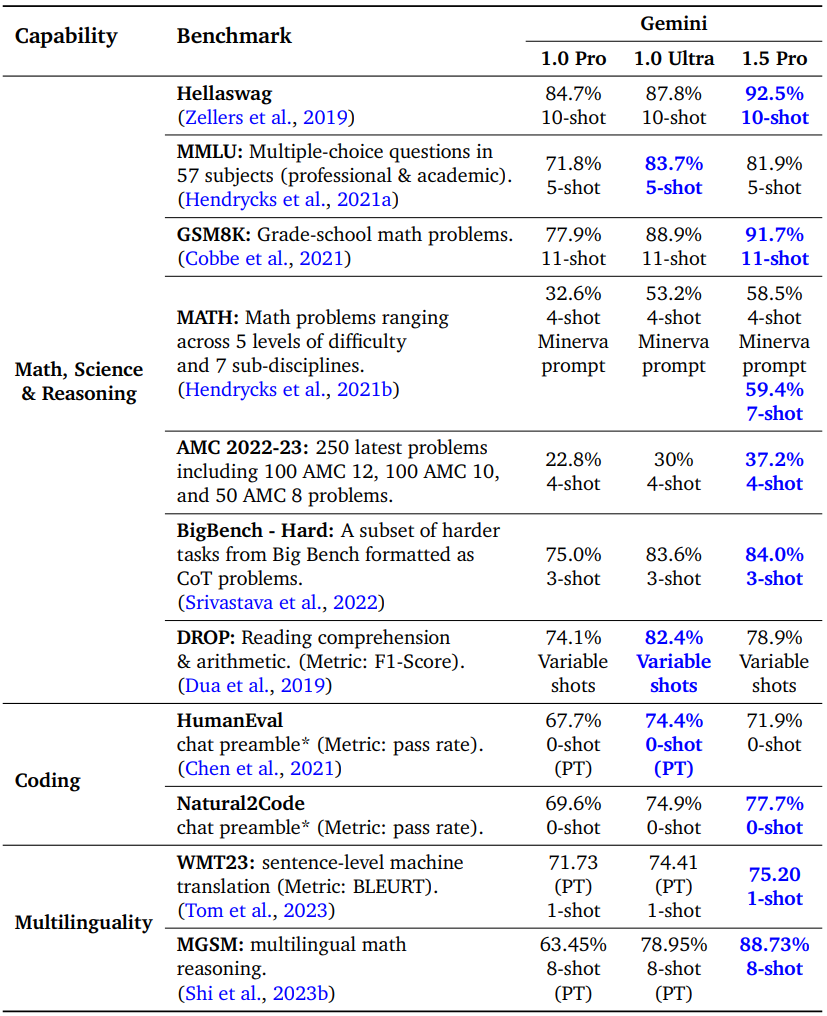
다음은 수학/과학/추론, 코딩, 다국어에 대한 성능을 비교한 표이다.
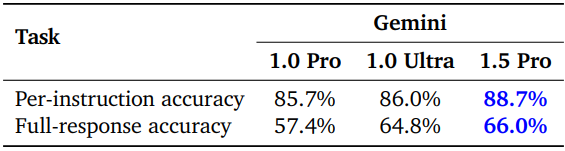
다음은 창의적인 콘텐츠 생성, 권장 사항 제공, 요약, 텍스트, 재작성, 코딩 및 논리 문제 해결 등과 같은 다양한 주제를 다루는 다양한 프롬프트 세트에 대하여 명령을 잘 따르는 지를 평가한 표이다.
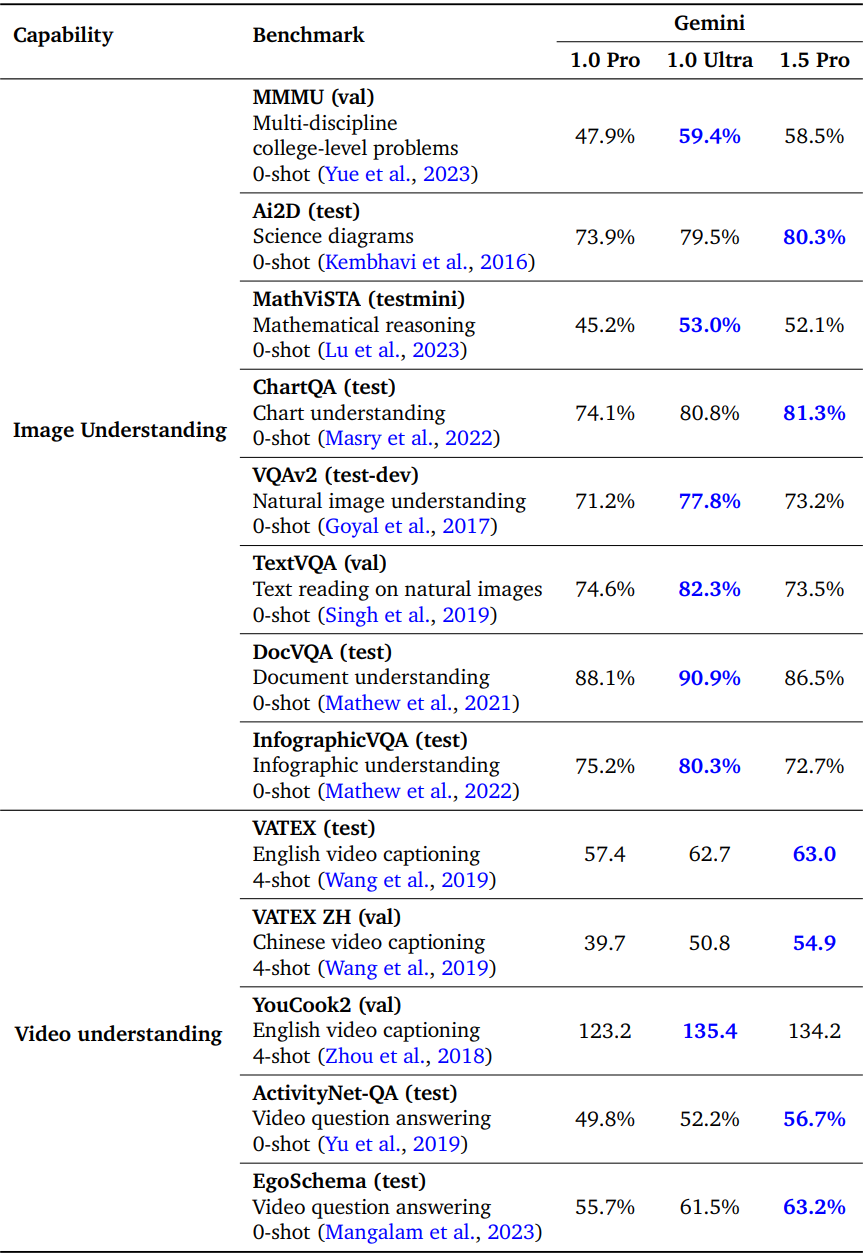
2. Core Vision Multimodal Evaluations
다음은 이미지 및 동영상 이해 능력을 비교한 표이다.
3. Core Audio Multimodal Evaluations
다음은 오디오 이해 능력을 비교한 표이다.