[논문리뷰] Proper Reuse of Image Classification Features Improves Object Detection
CVPR 2022. [Paper]
Cristina Vasconcelos, Vighnesh Birodkar, Vincent Dumoulin
Google Research
1 Apr 2022
Introduction
Transfer learning은 특히 타겟 task의 데이터셋이 더 작은 경우 딥러닝에서 널리 채택되는 방식이다. 모델은 먼저 더 많은 양의 데이터를 사용할 수 있는 업스트림 task에 대해 사전 학습된 다음 타겟 task에 맞게 fine-tuning된다. ImageNet 또는 더 크거나 레이블이 약한 데이터셋의 transfer learning은 다양한 비전 task, 아키텍처, 학습 절차 전반에 걸쳐 성능을 향상시키는 것으로 나타났다.
Object detection의 경우 ImageNet과 같은 이미지 classification task에 대한 사전 학습을 통해 얻은 가중치 값으로 모델의 backbone을 초기화하는 것이 일반적이다. 전통적으로 backbone은 다른 detector 구성 요소를 처음부터 학습하는 동안 fine-tuning된다. 최근 두 가지 연구들에서 object detection을 위한 transfer learning에 대해 모순되는 관찰을 했다. Revisiting unreasonable effectiveness of data in deep learning era 논문은 object detector가 사전 학습에 사용되는 classification 데이터의 양으로부터 이점을 얻는다는 것을 보여주었다. 반면, 최근 여러 논문들에서는 사전 학습된 backbone으로 초기화하는 것과 더 작은 in-domain 데이터셋을 사용하여 처음부터 backbone을 학습하는 것 사이의 성능 격차가 학습 시간이 길어지면 사라진다고 보고했다.
저자들은 detection 학습 중에 사전 학습된 초기화 값이 고정되는 가장 간단한 형태로 transfer learning을 다시 살펴보았다. 이를 통해 fine-tuning으로 인한 방해 요인 없이 사전 학습된 표현의 유용성을 더 잘 이해할 수 있다. 이 접근 방식에는 많은 장점이 있다. 간단하고 리소스가 절약되며 복제가 쉽다. 또한, 이 접근 방식을 사용하면 다음 두 가지 관찰을 할 수 있다.
- 더 긴 학습은 사전 학습된 표현의 유용성을 조사하는 데 방해 요소다. 왜냐하면 fine-tuning된 backbone의 가중치가 사전 학습된 초기화 값에서 더 멀리 이동하기 때문이다.
- 업스트림 classification task에서 학습된 표현이 더 작은 in-domain 데이터셋을 사용하여 object detection task 자체에 대해 처음부터 fine-tuning하거나 학습하여 얻은 표현보다 object detection에 더 낫다.
Backbone을 고정하여 사전 학습된 표현을 보존하면 더 큰 데이터셋에 대한 사전 학습을 통해 일관된 성능 향상이 관찰된다. Backbone 이후의 detector 구성 요소에 충분한 용량이 있는 경우 고정된 backbone으로 학습된 모델은 fine-tuning된 모델이나 처음부터 학습하는 모델의 성능을 훨씬 능가한다.
제안된 업스트림 task 지식 보존은 메모리 측면과 계산량 측면(FLOP) 모두에서 계산 리소스의 필요성을 크게 줄이면서 유사하거나 우수한 성능으로 기존 object detection 모델을 학습할 수 있게 한다. 성능 개선은 클래스나 사용 가능한 주석의 수로 결과를 계층화할 때 더욱 명확해진다. 또한 모델 재사용은 롱테일 객체 인식에서 발견되는 것과 같이 주석 수가 적은 클래스에 분명히 긍정적인 영향을 미친다.
Methodology
본 논문의 주요 가설은 대규모 이미지 classification에 대하여 학습된 feature가 비교적 작은 in-domain 데이터셋에서 얻은 feature보다 object detection에 더 좋다는 것이다. 저자들이 고려한 classification 데이터셋(ImageNet(1.2M), JFT300M(300M))에는 MSCOCO(118K)나 LVIS(100K)와 같은 일반적인 detection 데이터셋보다 훨씬 더 많은 이미지가 포함되어 있다. 핵심 통찰력은 classification task에서 학습된 가중치를 고정하고 detection 관련 feature를 학습할 수 있는 충분한 용량을 갖도록 나머지 구성 요소를 선택하는 것이다.
1. Preserving classification features
Classification 중에 학습한 지식을 보존하기 위해 classification 네트워크(backbone)의 가중치를 고정하는 가장 자연스럽고 분명한 전략을 사용한다. 연구들의 일반적인 관행은 backbone으로 초기화된 모델의 모든 가중치를 학습시키는 것이다. 대신 저자들은 모든 backbone 가중치를 고정하는 대체 전략을 고려하였다. 이는 컴퓨팅 비용을 절감하고 학습 속도를 높일 뿐만 아니라, 많은 최신 detection 아키텍처의 성능을 향상시킨다.
2. Detection-specific capacity
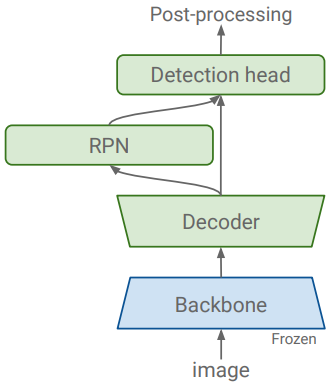
Detection task에 classification 네트워크를 적용하려면 일반적으로 Region Proposal Network (RPN), Feature Pyramid Network, Detection Cascades와 같은 detection을 위한 구성 요소를 추가해야 한다. 저자들은 특히 classification task에서 초기화할 때 detection 구성 요소의 용량이 네트워크의 일반화 능력에 큰 역할을 한다는 것을 관찰했다. Detection 관련 구성 요소의 용량이 충분할 때 classification task에서 초기화하고 해당 가중치를 고정하는 것이 fine-tuning이나 처음부터 학습하는 것보다 더 나은 성능을 발휘한다. 또한, 보다 다양한 classification 데이터셋을 사전 학습하면 성능이 향상된다.
3. Data augmentation
저자들은 EfficientNet으로 최상의 결과를 얻기 위해 모든 실험에 Large Scale Jittering (LSJ)를 사용하고 Copy-and-paste augmentation을 사용한다. 제안된 방법들은 이러한 데이터 augmentation 전략을 모두 보완한다. 또한 고정된 backbone을 사용한 실험의 경우 데이터 augmentation 기술은 detection 관련 구성 요소에 도움을 주어야만 결과를 향상시킬 수 있다.
Experiments
- 데이터셋: MSCOCO 2017, LVIS 1.0
1. Revisiting ResNet reuse for object detection
다음은 다양한 detection 모델에 대하여 backbone을 고정할 때의 성능 변화를 비교한 표이다.
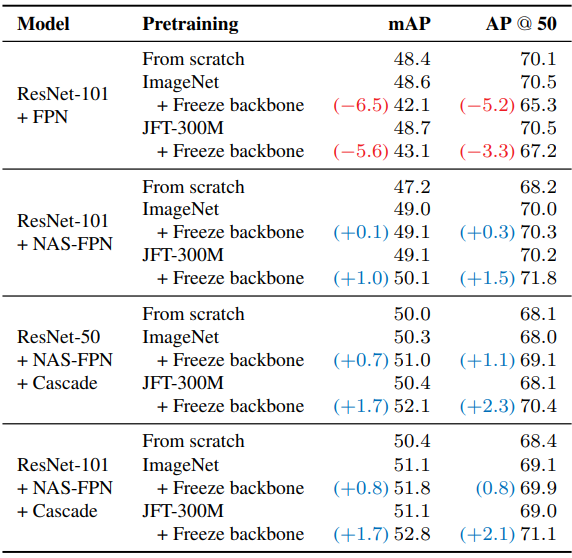
다음은 이전 연구들의 결과와 비교한 표이다. (ResNet-101 + NAS-FPN)

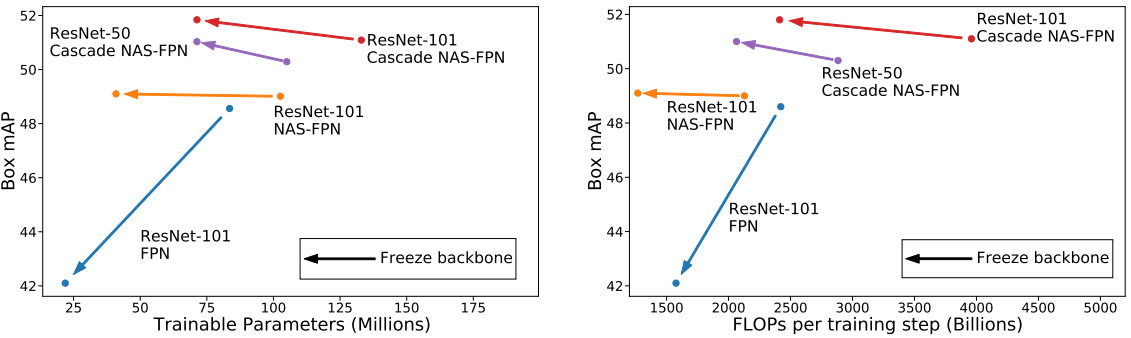
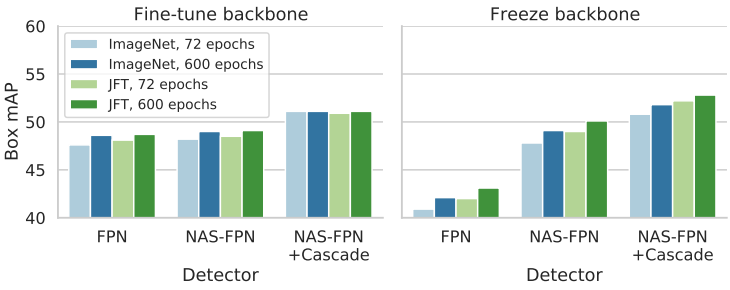
다음은 ResNet-101 backbone을 사용할 때 여러 종류의 detector에 대한 결과를 비교한 그래프이다.
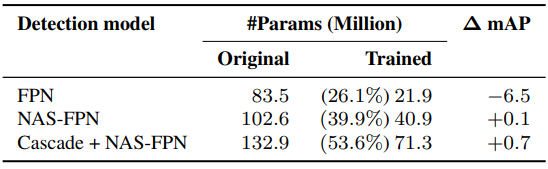
다음은 다양한 detection 모델에 대하여 backbone을 고정한 상태를 유지할 때 학습되는 파라미터 수이다. (ResNet-101)
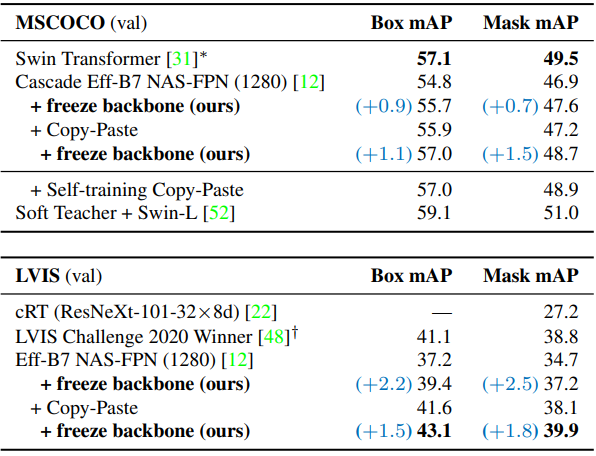
2. EfficientNet-B7’s reuse for object detection
다음은 MSCOCO와 LVIS에서의 성능을 비교한 표이다.
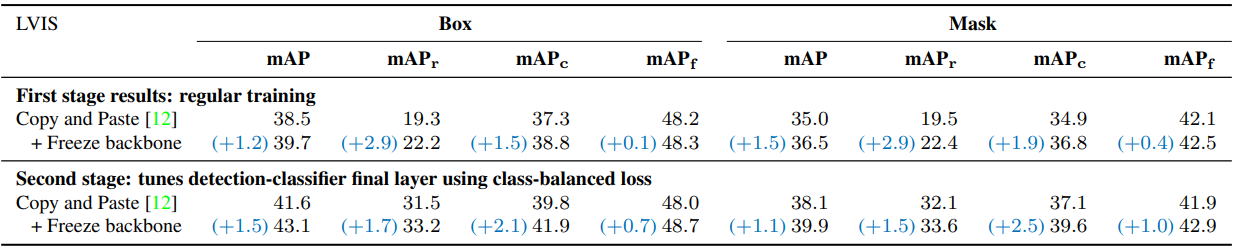
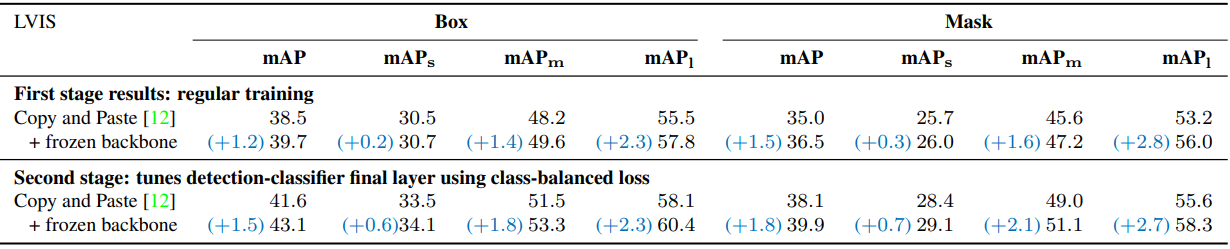
다음은 LVIS에서 얻은 결과를 주석의 수(위)와 객체 크기(아래)로 계층화한 표이다. (EfficientNet-B7 + NAS-FPN)
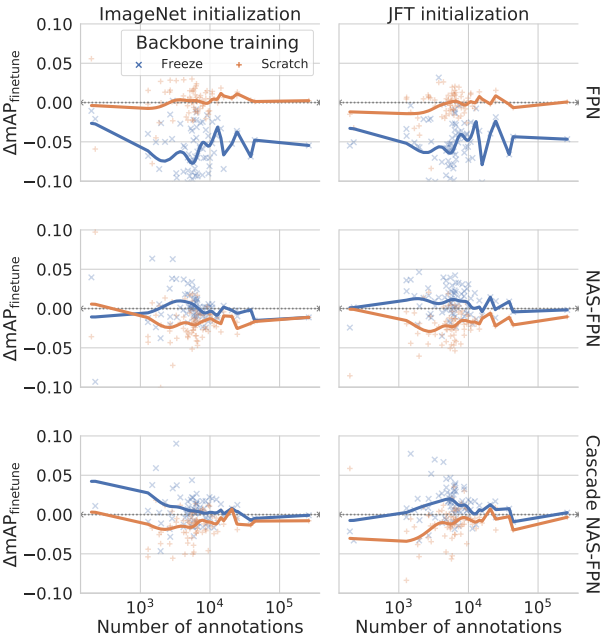
3. How does preserving pre-trained representations help?
다음은 backbone을 fine-tuning하는 것에 비해 얼마나 클래스별 mAP가 변하는 지를 학습 주석 수의 함수로 나타낸 그래프이다.
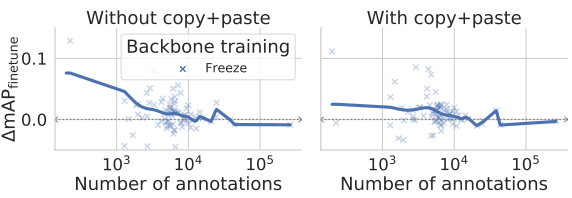
4. Beyond backbone freezing
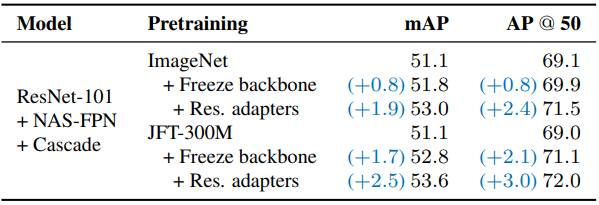
다음은 고정된 backbone에 residual adapter를 추가하고 detector 구성 요소와 함께 학습한 결과로, 추가 성능 증가를 가져올 수 있다.