[논문리뷰] FreeCustom: Tuning-Free Customized Image Generation for Multi-Concept Composition
CVPR 2024. [Paper] [Page] [Github]
Ganggui Ding, Canyu Zhao, Wen Wang, Zhen Yang, Zide Liu, Hao Chen, Chunhua Shen
Zhejiang University
22 May 2024

Introduction
대규모의 사전 학습된 diffusion model은 text-to-image 생성에서 전례 없는 진전을 이루었다. 사전 학습된 모델의 능력을 활용하여 커스터마이징된 생성이 가능해졌으며 광범위한 응용 분야로 인해 점점 더 주목을 받고 있다.
DreamBooth, Textual Inversion, BLIP Diffusion과 같은 기존의 커스터마이징 방법은 하나의 개념을 커스터마이징하는 데에 상당한 진전을 보였지만 여러 개념이 포함된 보다 복잡한 시나리오를 처리할 때 어려움을 겪는다. 여러 개념이 포함된 시나리오에서 하나의 개념을 다루는 방법들은 overfitting되기 쉽고 여러 개념을 결합할 때 이미지의 자연스러움을 유지하고 identity를 보존하는 데 있어 성능이 저하된다. 또한 3~5개의 이미지를 사용하여 fine-tuning하거나 대규모 데이터셋에서 재학습해야 하는 시간 소모적인 학습 프로세스가 필요하다.
이러한 한계를 해결하기 위해, 본 논문은 개념당 하나의 이미지만 입력으로 사용하여 여러 개념을 합성하는 튜닝이 필요 없는 방법인 FreeCustom을 제안하였다. 구체적으로, 이중 경로 아키텍처를 사용하여 입력된 여러 개념의 feature를 추출하고 결합한다. 그런 다음, 원래의 self-attention을 확장하여 레퍼런스 개념의 feature에 액세스하고 쿼리하는 새로운 multi-reference self-attention (MRSA) 메커니즘을 도입한다. 입력 개념을 강조하고 관련 없는 정보를 제거하기 위해 MRSA가 주어진 개념에 더 집중하도록 지시하는 가중 마스크 전략을 사용한다. 또한, 입력 개념의 컨텍스트 상호 작용이 다중 개념 합성에 매우 중요하며, MRSA 메커니즘은 입력 이미지의 글로벌 컨텍스트를 효과적으로 포착한다. 결과적으로, 학습 필요 없이 텍스트와 정확하게 일치하고 레퍼런스 개념과의 일관성을 유지하는 고충실도 이미지를 빠르게 생성할 수 있다.
Method
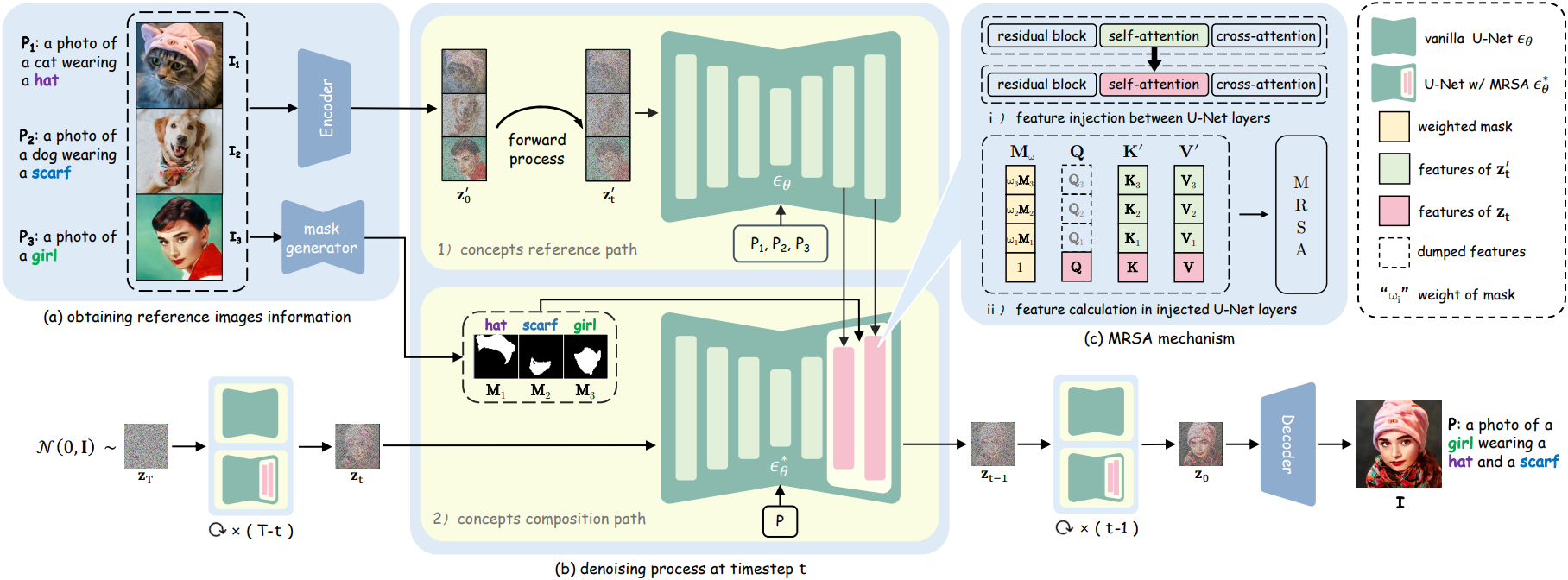
1. Multi-Reference Self-Attention
- 입력
- 레퍼런스 개념을 나타내는 $N$개의 이미지 \(\mathcal{I} = \{I_1, \ldots, I_N\}\)
- 각 개념에 해당하는 프롬프트 \(\mathcal{P} = \{P_1, \ldots, P_N\}\)
- 타겟 프롬프트 $P$
- 출력: 여러 개념을 결합하고 $P$와 일치하는 커스터마이징된 이미지 $I$
레퍼런스 이미지들의 정보 추출
추가 처리를 위해 $\mathcal{I}$의 정보를 먼저 얻는다. 먼저, VAE 인코더 $\textrm{Enc}$를 사용하여 $\mathcal{I}$를 latent space로 변환하여 \(z_0^\prime = \textrm{Enc}(\mathcal{I})\)를 얻는다. 그런 다음, segmentation model $\Phi$를 사용하여 입력 이미지의 레퍼런스 개념에 해당하는 마스크 \(\mathcal{M} = \{\textbf{M}_1, \ldots, \textbf{M}_N\}\)을 추출한다.
개념 레퍼런스 경로 & 개념 합성 경로
Gaussian 분포 $\mathcal{N}(0, \textbf{I})$에서 latent \(\textbf{z}_T\)를 무작위로 샘플링하여 시작하고 \(\textbf{z}_0\)까지 \(\textbf{z}_T\)를 점진적으로 denoise한다. 이 프로세스는 개념 레퍼런스 경로와 개념 합성 경로의 두 경로로 구성된다.
- 개념 레퍼런스 경로: Timestep $t$에 대하여, 먼저 \(\textbf{z}_0^\prime\)에 기존 forward process를 적용하여 \(\textbf{z}_t^\prime\)를 얻는다. 다음으로, \(\textbf{z}_t^\prime\)와 $\mathcal{P}$를 U-Net \(\epsilon_\theta\)에 입력하여 각 attention layer의 key \(\mathcal{K} = [\textbf{K}_1, \ldots, \textbf{K}_N]\)과 value \(\mathcal{V} = [\textbf{V}_1, \ldots, \textbf{V}_N]\)을 추출한다. \(\epsilon_\theta\)의 출력은 활용하지 않는다.
- 개념 합성 경로: \(\epsilon_\theta\)를 수정하여 self-attention 모듈을 MRSA 모듈 \(\epsilon_\theta^\ast\)로 대체한다. Latent \(\textbf{z}_t\)와 타겟 프롬프트 $P$를 \(\epsilon_\theta^\ast\)에 공급한 다음 각 attention layer의 query $\textbf{Q}$, key $\textbf{K}$, value $\textbf{V}$를 계산한다. 최종적으로 \(\textbf{z}_0\)는 VAE 디코더 $\textrm{Dec}$를 사용하여 이미지 공간으로 다시 변환되어 최종적으로 커스터마이징된 이미지 \(I = \textrm{Dec}(\textbf{z}_0)\)를 생성한다.
MSRA 메커니즘
\(\epsilon_\theta^\ast\)의 self-attention 모듈의 feature들은 \(\epsilon_\theta\)의 모듈에 주입되므로, MRSA는 자신의 feature뿐만 아니라 레퍼런스 이미지에서 얻은 feature도 인식한다. 각 attention layer에 대하여, $\mathcal{K}$와 $\textbf{K}$를 concat하여 $\textbf{K}^\prime$를 얻고, $\mathcal{V}$와 $\textbf{V}$를 concat하여 \(\textbf{V}^\prime\)를 얻는다.
\[\begin{aligned} \textbf{K}^\prime &= [\textbf{K}, \textbf{K}_1, \ldots, \textbf{K}_N] \\ \textbf{V}^\prime &= [\textbf{V}, \textbf{V}_1, \ldots, \textbf{V}_N] \end{aligned}\]MRSA의 연산은 다음과 같다.
\[\begin{equation} \textrm{MRSA} (\textbf{Q}, \textbf{K}^\prime, \textbf{V}^\prime) = \textrm{Softmax} (\frac{\textbf{Q} \textbf{K}^{\prime \top}}{\sqrt{d}}) \textbf{V}^\prime \end{equation}\]이 방식은 생성된 이미지가 입력 이미지의 feature를 자연스럽게 통합할 수 있게 하지만, 관련 없는 feature도 상당 부분 유지하여 개념 혼동을 초래한다. 이 문제를 해결하기 위해 모든 마스크 \(\textbf{M}_i \in \mathcal{M}\)을 원소가 모두 1인 행렬 $\textbf{1}$과 concat하여 \(\textbf{M} = [\textbf{1}, \textbf{M}_1, \ldots, \textbf{M}_N]\)을 생성한 다음 $\textbf{M}$을 사용하여 MRSA가 관여하는 영역을 제한하여 관련 없는 내용을 효과적으로 마스킹하고 모델의 초점을 대상 개념으로 가이드한다.
\[\begin{equation} \textrm{MRSA} (\textbf{Q}, \textbf{K}^\prime, \textbf{V}^\prime, \textbf{M}) = \textrm{Softmax} (\frac{\textbf{M} \odot (\textbf{Q} \textbf{K}^{\prime \top})}{\sqrt{d}}) \textbf{V}^\prime \end{equation}\]$\textbf{M}$은 현재 feature의 해상도와 일치하도록 다운샘플링되고, $\odot$은 element-wise product이다. 이 마스킹된 MRSA 메커니즘은 입력 이미지 내의 컨텍스트 상호 작용 정보를 활용하고 이미지 생성 프로세스 중에 관련 없는 feature를 필터링할 수 있다.
2. Weighted Mask
마스크 도입이 관련 없는 feature의 문제를 해결하는 데 도움이 되기는 하지만, 현재 모델은 여전히 생성된 결과에서 대상 개념의 독특한 특성을 정확하게 보존하는 데 어려움을 겪고 있다. 정확한 디테일이 부족하여 대상 개념의 모양을 대략적으로만 표현할 수 있다. 이러한 한계를 극복하기 위해 각 마스크에 scaling factor \(\textbf{w} = \{1, \omega_1, \ldots, \omega_N\}\)을 도입하여 가중치가 적용된 마스크와 함께 대상 개념에 대한 모델의 초점을 강화한다.
\[\begin{equation} \textbf{M}_w = [\textbf{1}, \omega_1 \textbf{M}_1, \ldots, \omega_N \textbf{M}_N] \end{equation}\]그러면 MRSA는 다음과 같다.
\[\begin{equation} \textrm{MRSA} (\textbf{Q}, \textbf{K}^\prime, \textbf{V}^\prime, \textbf{M}_w) = \textrm{Softmax} (\frac{\textbf{M}_w \odot (\textbf{Q} \textbf{K}^{\prime \top})}{\sqrt{d}}) \textbf{V}^\prime \end{equation}\]저자들은 이 모델이 $\textbf{w}$의 값에 지나치게 민감하지 않다는 것을 발견했다. $\textbf{w}$에 2와 3 사이의 값을 일관되게 할당하면 다양한 시나리오에서 뛰어난 성능을 얻을 수 있다. MRSA에 개념별 가중 마스크를 통합함으로써 모델은 원하는 feature에 더 선택적으로 주의를 기울이고 관련 없는 정보의 영향을 억제하도록 장려된다. 이러한 개선을 통해 의도된 개념과 더 긴밀하게 일치하는 향상된 생성 결과가 도출된다.

3. Selective MRSA Replacement
실험 결과에 따르면 모든 7개 기본 블록의 self-attention 모듈을 MRSA 모듈로 간단히 대체하면 부자연스러운 생성, 개념적 일관성 손실, 텍스트 불일치가 발생한다. 이전 연구에 따르면 U-Net의 레이어에 있는 query feature는 레이아웃 제어 및 semantic 정보 수집 기능이 있다. 따라서 MasaCtrl과 유사한 전략을 채택하여 선택된 블록 세트, 특히 U-Net의 더 깊은 블록 $\Psi$에서만 self-attention 모듈을 MRSA 모듈로 대체한다.
저자들은 경험적 관찰을 통해 $\Psi = [5, 6]$로 설정하여 더 우수한 결과를 얻었다. 이러한 결과는 생성된 이미지의 자연스럽고 사실적인 모양을 개선할 뿐만 아니라 주어진 개념의 정체성을 효과적으로 보존할 수 있는 능력을 보여준다.
4. Preparing Images with Context Interaction

이미지에서 각 개념의 컨텍스트 상호 작용이 여러 개념을 합성하는 데 중요하다. 예를 들어 입력 이미지에 “모자 쓰기”라는 컨텍스트가 제공되면 모자 개념은 잘 보존된다. 그러나 입력 이미지에 그냥 모자만 있으면 생성된 이미지가 손상된다.
위 그림에서 볼 수 있듯이 컨텍스트 상호 작용 없이 모자와 안경의 이미지만 제공되는 경우 모델은 원하는 개념을 성공적으로 유지하는 데 어려움을 겪는다. 그러나 선글라스와 모자를 쓴 고양이의 이미지가 제공되면 모델은 우수한 커스터마이징 결과를 생성할 수 있다. 간단한 복사-붙여넣기 전략도 커스터마이징에 도움이 되는 충분한 컨텍스트 정보를 제공할 수 있다. 이 전략을 활용하여 컨텍스트 상호 작용이 있는 레퍼런스 이미지를 수동으로 생성하여 충실도가 높고 텍스트와 정렬된 이미지를 생성하는 데 도움이 된다.
Experiments
1. Comparison with Existing Methods
다음은 단일 개념 커스터마이징을 비교한 결과이다.

다음은 다중 개념 커스터마이징을 비교한 결과이다.

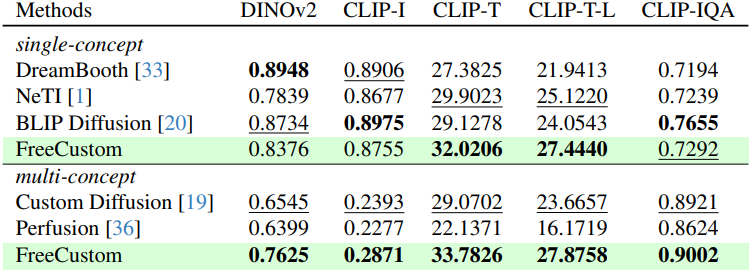
다음은 이미지 유사도 (DINOv2, CLIP-I), 이미지-텍스트 정렬 (CLIP-T, CLIP-T-L), 이미지 품질 (CLIP-IQA)을 비교한 표이다.
다음은 전처리 시간과 inference 시간을 비교한 표이다.

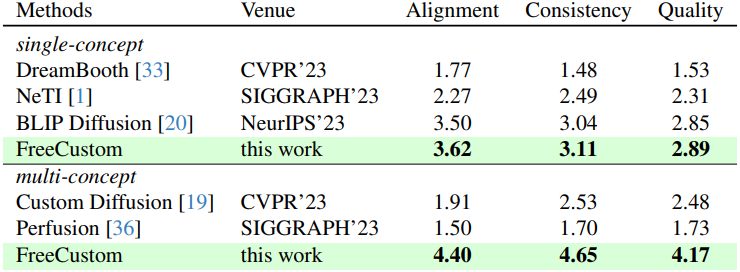
다음은 user study 결과이다.
2. Ablation Studies
다음은 가중치 마스크에 대한 ablation 결과로, attention map을 시각화한 것이다.

다음은 MRSA를 적용한 블록에 따른 생성 결과를 비교한 것이다.

3. More Applications
다음은 입력 이미지와 비슷한 외형과 재료로 다른 물체를 생성한 예시이다.

다음은 기존 방법들과 결합한 예시이다.

다음은 다른 base model에 본 논문의 방법을 적용한 예시이다.
