[논문리뷰] FreeU: Free Lunch in Diffusion U-Net
arXiv 2023. [Paper] [Page] [Github]
Chenyang Si, Ziqi Huang, Yuming Jiang, Ziwei Liu
S-Lab, Nanyang Technological University
20 Sep 2023

Introduction
VAE, GAN, vector-quantized 접근 방식과 같은 다른 종류의 생성 모델과 달리 diffusion model은 새로운 생성 패러다임을 도입하였다. Diffusion model은 고정 Markov chain을 사용하여 latent space를 매핑함으로써 데이터셋 내의 구조적 복잡성을 포착하는 복잡한 매핑을 용이하게 한다. 최근에는 높은 수준의 디테일부터 생성된 이미지의 다양성에 이르기까지 인상적인 생성 능력을 통해 이미지 합성, 이미지 편집, image-to-image translation, text-to-video 생성 등 다양한 컴퓨터 비전 애플리케이션에서 획기적인 발전을 이루었다.
Diffusion model은 diffusion process와 denoising process로 구성된다. Diffusion process에서 입력 데이터에 Gaussian noise가 점진적으로 추가되고 결국에는 거의 순수한 Gaussian noise로 손상된다. Denoising process에서 원래 입력 데이터는 학습된 일련의 inverse diffusion 연산을 통해 noise 상태에서 복구된다. 일반적으로 U-Net은 각 denoising step에서 제거할 noise를 반복적으로 예측하도록 학습된다. 기존 연구들은 다운스트림 애플리케이션을 위해 사전 학습된 diffusion U-Net을 활용하는 데 중점을 두는 반면, diffusion U-Net의 내부 속성은 아직 충분히 연구되지 않았다.

본 논문에서는 diffusion model의 적용을 넘어 denoising process에 대한 diffusion U-Net의 효율성을 조사하는 데 관심이 있다. Denoising process를 더 잘 이해하기 위해 먼저 푸리에 도메인으로의 패러다임 전환을 제시하여 제한된 사전 조사를 받은 연구 분야인 diffusion model의 생성 프로세스를 살펴본다. 위 그림의 맨 위 행은 점진적인 denoising process의 연속적인 iteration을 통해 생성된 이미지이다. 아래 두 행은 역 푸리에 변환 후 각 step에 맞춰 연관된 저주파 및 고주파 공간 도메인 정보를 나타낸다. 위 그림에서 분명한 것은 저주파 성분의 점진적인 변조로 인해 부드러운 변화율을 보이는 반면, 고주파 성분은 denoising process 전반에 걸쳐 더욱 뚜렷한 역동성을 나타낸다.
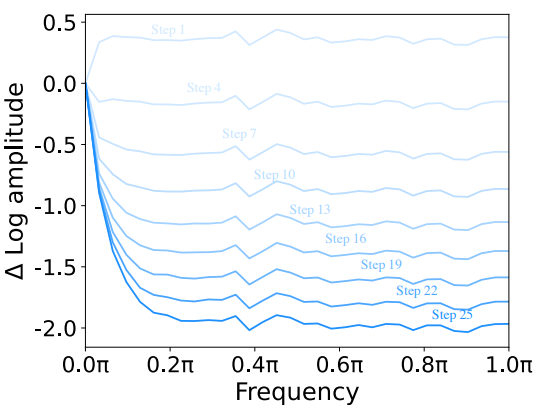
이러한 결과는 위 그림에서 더욱 확증된다. 이는 직관적으로 설명할 수 있다. 저주파 성분은 본질적으로 글로벌 레이아웃과 부드러운 색상을 포함하는 이미지의 글로벌 구조와 특성을 구현한다. 저주파 성분은 이미지의 본질과 표현을 구성하는 기본 글로벌 요소를 캡슐화한다. 빠른 변화는 일반적으로 denoising process에서 불합리한다. 저주파 성분을 대폭 변경하면 이미지의 본질이 근본적으로 바뀔 수 있으며, 이는 일반적으로 denoising process의 목표와 양립할 수 없는 결과다.
반대로 고주파 성분은 가장자리와 텍스처 등 이미지의 급격한 변화를 담고 있다. 이러한 미세한 디테일은 noise에 현저히 민감하며, 이미지에 noise가 도입되면 랜덤 고주파 정보로 나타나는 경우가 많다. 결과적으로, denoising process에서는 필수 불가결하고 복잡한 디테일을 유지하면서 noise를 제거해야 한다.
저자들은 denoising process에서 저주파 성분과 고주파 성분 간의 이러한 관찰을 고려하여 diffusion 프레임워크 내에서 U-Net 아키텍처의 특정 기여를 확인하기 위해 조사를 확장하였다. U-Net 디코더의 각 step에서는 skip connection의 skip feature와 backbone feature가 함께 concat된다. 저자들의 조사에 따르면 U-Net의 주요 backbone은 주로 denoising에 기여하는 것으로 나타났다. 반대로, skip connection은 디코더 모듈에 고주파 feature를 도입하는 것으로 관찰되었다. Skip connection은 세분화된 semantic 정보를 전파하여 입력 데이터를 더 쉽게 복구할 수 있도록 한다. 그러나 이러한 전파의 의도하지 않은 결과는 inference 단계 동안 backbone의 고유한 denoising 능력이 약화될 수 있다는 것이다. 이로 인해 비정상적인 이미지 디테일이 생성될 수 있다.
이러한 사실을 바탕으로 본 논문은 추가 학습이나 fine-tuning으로 인한 계산 오버헤드 없이 샘플 품질을 향상시킬 수 있는 잠재력을 지닌 FreeU라는 새로운 전략을 도입하였다. inference 단계에서는 U-Net 아키텍처의 기본 backbone과 skip connection의 feature 기여 균형을 맞추도록 설계된 두 가지 특수 변조 factor를 사용한다. Backbone feature factor라고 불리는 첫 번째 factor는 backbone의 feature map을 증폭하여 denoising process를 강화하는 것을 목표로 한다. 그러나 backbone feature scaling factor를 포함하면 상당한 개선이 이루어지지만 때로는 바람직하지 않은 텍스처가 oversmoothing될 수 있음을 발견했다. 이 문제를 완화하기 위해 두 번째 factor인 skip feature scaling factor를 도입하여 텍스처의 oversmoothing 문제를 완화하는 것을 목표로 한다.
FreeU 프레임워크는 text-to-image 생성과 text-to-video 생성과 같은 애플리케이션을 포괄하는 기존 diffusion model과 통합될 때 원활한 적응성을 보여준다. 저자들은 벤치마크 비교를 위한 기본 모델로 Stable Diffusion, DreamBooth, ReVersion, ModelScope, Rerender를 사용하여 본 논문의 접근 방식에 대한 포괄적인 실험적 평가를 수행하였다. Inference 단계에서 FreeU를 사용하면 모델들의 출력 품질이 눈에 띄게 향상되었다.
Methodology
1. How does diffusion U-Net perform denoising?
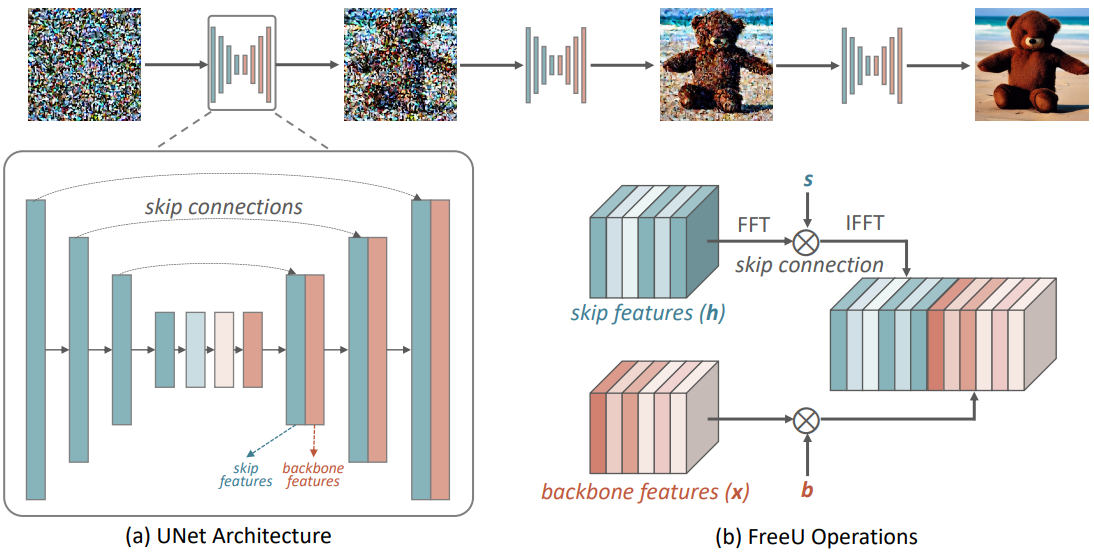
본 논문은 denoising process 전반에 걸쳐 저주파 성분과 고주파 성분 사이에 관찰된 주목할만한 차이를 기반으로 denoising process 내에서 U-Net 아키텍처의 특정 기여를 설명하기 위해 조사를 확장하고, denoising network의 내부 속성을 탐색하였다. 위 그림에 표시된 것처럼 U-Net 아키텍처는 인코더와 디코더를 모두 포함하는 기본 backbone 네트워크와 인코더와 디코더의 해당 레이어 간의 정보 전송을 용이하게 하는 skip connection으로 구성된다.
The backbone of U-Net

저자들은 backbone과 skip connection에 의해 생성된 feature map을 각각 변조하기 위해 두 개의 곱셈 scaling factor $b$와 $s$를 도입하는 제어된 실험을 concatenation 전에 수행하였다. 위 그림에서 볼 수 있듯이 backbone의 scaling factor $b$를 높이면 생성된 이미지의 품질이 뚜렷하게 향상된다는 것이 분명하다. 반대로, 측면 skip connection의 영향을 조절하는 scaling factor $s$의 변화는 생성된 이미지의 품질에 무시할 만한 영향을 미치는 것으로 보인다.

이러한 관찰을 바탕으로 저자들은 backbone feature map과 관련된 scaling factor $b$가 강화될 때 이미지 생성 품질의 향상을 설명하는 기본 메커니즘을 조사했다. 저자들의 분석에 따르면 이러한 품질 개선은 U-Net 아키텍처의 backbone에서 제공되는 증폭된 denoising 능력과 근본적으로 연결되어 있다. 위 그림에서 볼 수 있듯이, $b$의 적절한 증가는 이에 따라 diffusion model에 의해 생성된 이미지의 고주파 성분이 억제되는 결과를 가져온다. 이는 backbone feature를 강화하면 U-Net 아키텍처의 denoising 능력을 효과적으로 강화하여 충실도와 디테일 보존 측면에서 우수한 출력에 기여한다는 것을 의미한다.
The skip connections of U-Net

반대로, skip connection은 인코더 블록의 이전 레이어에서 디코더로 직접 feature를 전달하는 역할을 한다. 흥미롭게도 위 그림에서 알 수 있듯이 전달되는 feature는 주로 고주파 정보를 구성한다. 이 관찰에 기반한 저자들의 추측은 U-Net 아키텍처의 학습 중에 이러한 고주파 feature의 존재가 디코더 모듈 내에서 noise 예측을 향한 수렴을 무심코 촉진할 수 있다고 가정한다. 또한 skip feature 변조의 제한된 영향은 skip feature가 디코더의 정보에 주로 기여한다는 것을 나타낸다. 결과적으로 이 현상은 inference 중에 backbone의 고유한 denoising 능력의 효율성을 의도하지 않게 약화시킬 수 있다. 따라서 이 관찰은 U-Net 프레임워크의 복합적인 denoising 성능에서 backbone과 skip connection이 수행하는 균형 조정 역할에 대한 적절한 질문을 촉발한다.
2. Free lunch in diffusion U-Net
위의 발견을 활용하여 저자들은 U-Net 아키텍처의 두 성분의 장점을 활용하여 U-Net 아키텍처의 denoising 능력을 효과적으로 강화하는 FreeU라고 하는 간단하면서도 효과적인 방법을 도입한다. 추가적인 학습이나 fine-tuning 없이도 생성 품질을 크게 향상시킨다.
U-Net 디코더의 $l$번째 블록에 대해 $x_l$을 이전 블록의 메인 backbone으로부터의 backbone feature map이라 하고, $h_l$을 해당 skip connection을 통해 전파되는 feature map이라 하자. 이러한 feature map을 변조하기 위해 두 가지 스칼라 factor를 도입한다. 하나는 $x_l$에 대한 backbone feature scaling factor $b_l$이고, 다른 하나는 $h_l$에 대한 아직 정의되지 않은 skip feature scaling factor $s_l$이다. 구체적으로, factor $b_l$은 backbone feature map $x_l$을 증폭하는 것을 목표로 하고, factor $s_l$은 skip feature map $h_l$을 감쇠하도록 설계되었다. Backbone feature의 경우, $b_l$의 곱셈을 통해 $x_l$의 모든 채널을 무분별하게 증폭하면 결과 합성 이미지에서 지나치게 부드러운 텍스처가 생성된다. 그 이유는 향상된 U-Net이 noise를 제거하면서 이미지의 고주파 디테일을 손상시키기 때문이다. 결과적으로 스케일링 연산을 다음과 같이 $x_l$의 절반 채널로 제한한다.
\[\begin{equation} x_{l, i}^\prime = \begin{cases} b_l \cdot x_{l, i} & \; \textrm{if} \; i < C/2 \\ x_{l, i} & \; \textrm{otherwise} \end{cases} \end{equation}\]여기서 $x_{l,i}$는 feature map $x_l$의 $i$번째 채널을 나타낸다. $C$는 $x_l$의 총 채널 수이다. 이 전략은 backbone의 denoising 능력을 향상시킬 뿐만 아니라 글로벌하게 적용되는 스케일링의 해로운 결과를 방지하여 noise 감소와 텍스처 보존 간의 보다 미묘한 균형에 도달한다.
Denoising 강화로 인해 텍스처가 oversmoothing되는 문제를 더욱 완화하기 위해 푸리에 도메인에서 스펙트럼 변조 (spectral modulation)를 추가로 사용하여 skip feature의 저주파 성분을 선택적으로 줄인다. 이 연산은 다음과 같이 수행된다.
\[\begin{aligned} \mathcal{F} (h_{l,i}) &= \textrm{FFT} (h_{l,i}) \\ \mathcal{F}^\prime (h_{l,i}) &= \mathcal{F} (h_{l,i}) \odot \alpha_{l,i} \\ h_{l,i}^\prime &= \textrm{IFFT} (\mathcal{F}^\prime (h_{l,i})) \end{aligned}\]여기서 $\textrm{FFT}(\cdot)$와 $\textrm{IFFT}(\cdot)$는 푸리에 변환과 역 푸리에 변환이다. $\odot$는 element-wise 곱셈을 나타내고, $\alpha_{l,i}$는 푸리에 계수의 크기의 함수로 설계된 푸리에 마스크로, 주파수에 의존하는 scaling factor $s_l$을 구현하는 데 사용된다.
\[\begin{equation} \alpha_{l,i} (r) = \begin{cases} s_l & \; \textrm{if} \; r < r_\textrm{thresh} \\ 1 & \; \textrm{otherwise} \end{cases} \end{equation}\]그런 다음, 증강된 skip feature map $h_l^\prime$은 U-Net 아키텍처의 후속 레이어에 대해 수정된 backbone feature map $x_l^\prime$과 concat된다.
놀랍게도 제안된 FreeU 프레임워크는 task별 학습이나 fine-tuning이 필요하지 않다. Backbone scaling factor와 skip scaling factor의 추가는 코드 몇 줄만으로 쉽게 구현할 수 있다. 기본적으로 아키텍처의 파라미터는 inference 단계에서 적응적으로 다시 가중치를 부여할 수 있으므로 계산 부담을 추가하지 않고도 보다 유연하고 강력한 denoising 연산이 가능하다. 이로 인해 FreeU는 기존 diffusion model에 원활하게 통합되어 성능을 향상시킬 수 있는 매우 실용적인 솔루션이 되었다.
Experiments
1. Text-to-image
다음은 FreeU 적용 유무에 따라 Stable Diffusion이 생성한 샘플들이다.

다음은 Stable Diffusion에 대한 정량적 결과이다.

2. Text-to-video
다음은 FreeU 적용 유무에 따라 ModelScope가 생성한 샘플들이다.

다음은 ModelScope에 대한 정량적 결과이다.

3. Downstream tasks
다음은 FreeU 적용 유무에 따라 DreamBooth가 생성한 샘플들이다.

다음은 FreeU 적용 유무에 따라 ReVersion이 생성한 샘플들이다.

다음은 FreeU 적용 유무에 따라 Rerender가 생성한 샘플들이다.

4. Ablation study
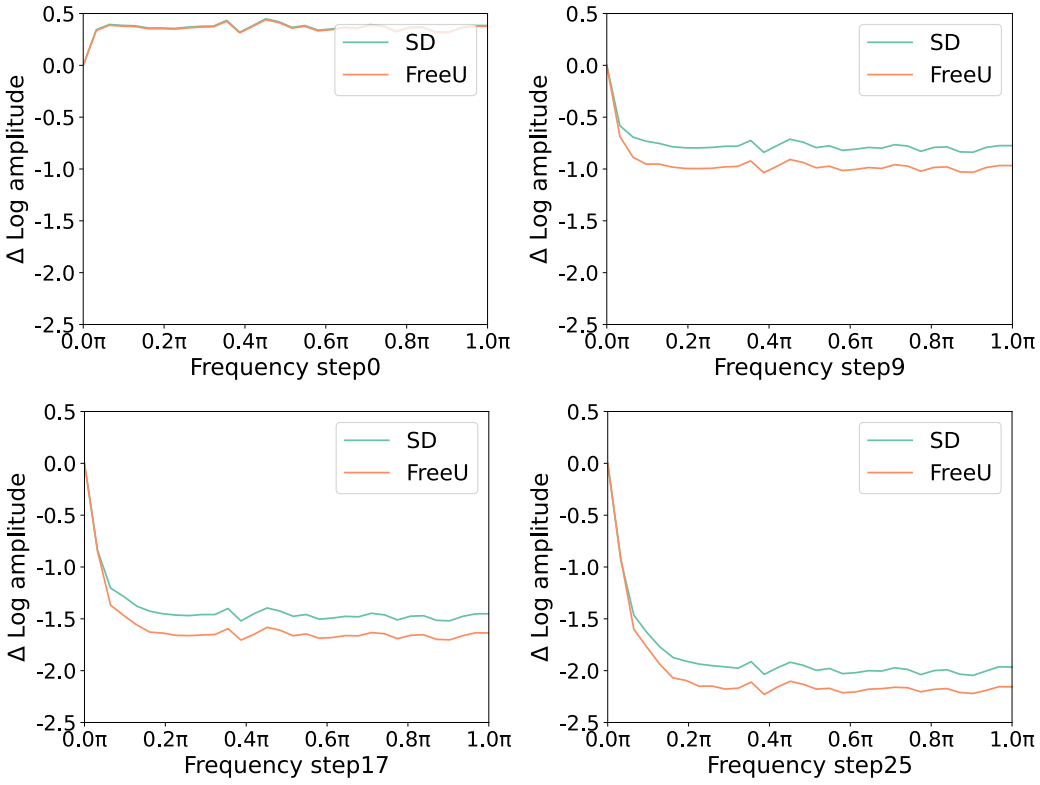
다음은 FreeU 적용 유무에 따른 Stable Diffusion의 푸리에 상대 로그 진폭을 비교한 그래프이다.
다음은 FreeU 적용 유무에 따른 Stable Diffusion의 feature map을 시각화한 것이다.

다음은 backbone scaling factor와 skip scaling factor에 대한 ablation 결과이다.
