[논문리뷰] A Strong and Reproducible Object Detector with Only Public Datasets (Focal-Stable-DINO)
arXiv 2023. [Paper]
Tianhe Ren, Jianwei Yang, Shilong Liu, Ailing Zeng, Feng Li, Hao Zhang, Hongyang Li, Zhaoyang Zeng, Lei Zhang
International Digital Economy Academy (IDEA) | Microsoft Research
25 Apr 2023
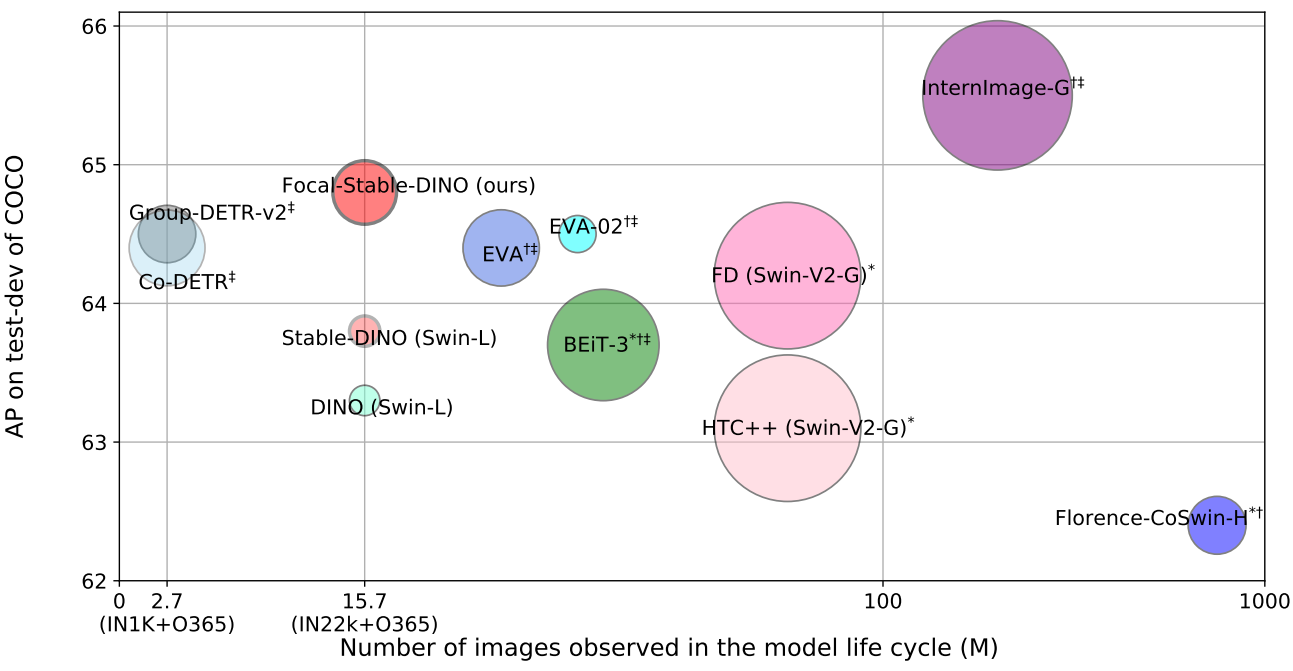
Introduction
Object detection는 주로 모델 구조, 데이터 규모, 학습 전략의 개선에 힘입어 최근 몇 년 동안 크게 발전했다. 모델 레벨에서는 다양한 연구에서 더 나은 결과를 위해 모델 설계를 향상시키는 데 중점을 두었다. 마찬가지로, 모델 표현을 개선하기 위해 masked image modeling이나 image-text contrastive learning과 같은 고급 학습 전략이 채택되었다.
모델 디자인과 학습 전략이 정체기에 도달한 후, 최근 연구에서는 더 큰 규모의 사전 학습된 모델과 더 광범위한 데이터 볼륨, 특히 비공개 데이터셋을 사용하여 모델 성능을 지속적으로 향상시키는 방법을 모색하기 시작했다. 예를 들어 EVA, BEiT, InternImage-DINO와 같은 작업은 COCO 2017 val2017과 test-dev에서 새로운 SOTA 결과를 달성하기 위해 매우 큰 backbone과 충분한 학습 데이터를 활용했다. 불행하게도 이러한 발전의 진행은 비공개 학습 데이터의 제한된 접근성으로 인해 방해를 받아 보고된 강력한 결과를 복제하는 것이 어려워졌다. 또한 복잡한 데이터 큐레이션 파이프라인 (ex. 여러 데이터셋 병합)과 정교하게 설계된 사전 학습 방법 (ex. masked image modeling, contrastive learning)으로 인해 연구자가 비공개 데이터와 코드에 액세스하지 않고는 이러한 기술을 재현하기가 어렵다.
Object detection에서 detector는 일반적으로 backbone과 detection head라는 두 가지 주요 구성 요소로 구성된다. 본 논문의 전략에는 간단한 파이프라인에서 공개적으로 사용 가능한 리소스를 모으는 것이 포함된다. 최근 6.89억 개의 파라미터를 갖춘 FocalNet-Huge는 ImageNet-22K에서만 사전 학습되었으며 object detection에 대한 강력한 전달성을 나타내는 공개적으로 사용 가능한 모델이다. Stable-DINO는 DINO의 여러 디코더 레이어에서 매칭 안정성 문제를 완화하기 위해 position-supervised loss와 position-modulated cost를 제안하여 하나의 최적화 경로만 사용할 수 있도록 하여 다중 최적화 경로 문제를 완화한다.
위의 분석을 바탕으로 본 논문은 masked image modeling이나 비공개 데이터 또는 이미지-텍스트 쌍의 통합과 같은 복잡한 학습 방법에 의존하지 않고 Focal-Stable-DINO라는 강력한 object detector를 개발하였다. Focal-Stable-DINO는 강력할 뿐만 아니라 재현성이 뛰어나 연구 커뮤니티가 지속적으로 개선할 수 있는 강력한 모델이다. 이는 강력한 Focal-Huge backbone 기반과 고성능 Stable-DINO detector의 통합 덕분이다.
Swin-L backbone을 갖춘 Stable-DINO는 COCO test-dev 데이터셋에서 63.8이라는 인상적인 AP (average precision)를 달성하였다. Swin-L backbone을 Focal-Huge backbone으로 교체함으로써 Focal-Stable-DINO는 더욱 향상될 수 있으며 test time augmentation와 같은 테스트 기술 없이도 COCO val2017에서 64.6 AP, COCO test-dev에서 64.8 AP를 달성하였다.
Method
Architecture
본 논문은 모델 파라미터가 6.89억 개에 불과한 대형 모델 중에서 탁월한 능력을 나타내는 FocalNet-Huge를 backbone으로 채택했다. 또한 Stable-DINO를 detector로 활용한다. Stable-DINO는 DETR 변형의 학습 안정성을 크게 향상시킬 수 있는 position-supervised loss를 제안하고 대형 모델에서도 놀라운 결과를 얻었다.
최종 결과에 대한 모든 리소스는 공개적으로 접근 가능하며, 이는 아래 표에 요약되어 있다.
Experiments
- 데이터셋
- Objects365: 사전 학습에 사용
- COCO: 사전 학습된 모델의 fine-tuning에 사용
- 구현 디테일
- DINO & FocalNet과 동일한 hyperparameter 사용
- fine-tuning 시 1.5배 해상도 사용
- denoising query: 1000개
- 상대적으로 작은 noise 비율
- position-supervised loss의 classification 가중치: 6.0
Comparison with state-of-the-art models on COCO
다음은 COCO val2017 (val)과 test-dev (test)에서 SOTA 모델과 비교한 표이다. TTA는 test time augmentation이고 “w/ Mask”는 detector를 fine-tuning할 때 마스크 주석을 사용함을 의미한다. 사용된 데이터셋은 다음과 같다.
- IN-1K: ImageNet-1K (1M)
- IN-22K: ImageNet-22K (14M)
- IN-22K-ext: ImageNet-22K-ext (70M, 비공개)
- O365: Objects365 (1.7M)
- merged dataa: FourODs + INBoxes+ GoldG + CC15M + SBU
- merged datab: IN-22K (14M) + Image-Text (35M) + Text (160GB)
- merged-30M: IN-22K (14M) + CC12M + CC3M + COCO + ADE20K + Objects365
- merged-38M: IN-22K (14M) + CC12M + CC3M + COCO + ADE20K + Objects365 + OpenImage
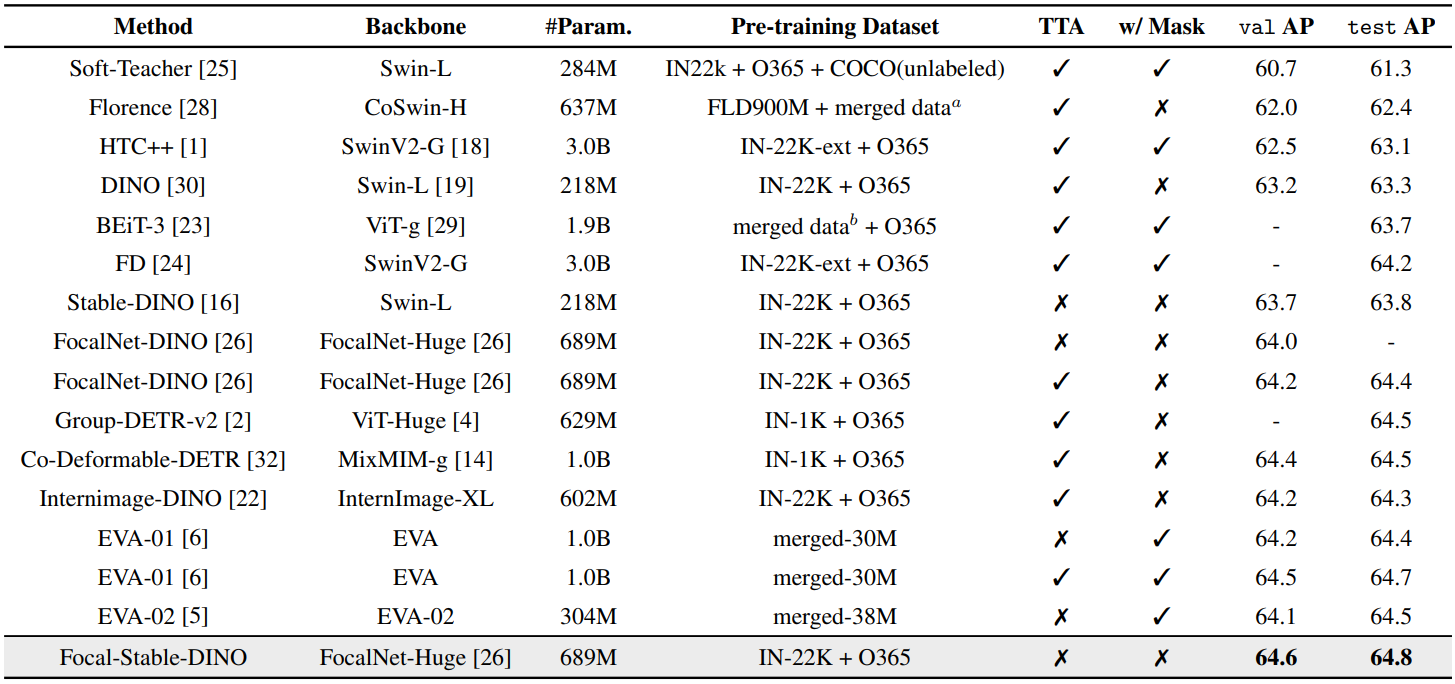
Main results on COCO
다음은 공개 데이터셋으로만 학습한 Focal-Stable-DINO의 COCO val2017 (상단)과 test-dev (하단)에서의 결과이다. (test time augmentation을 활용하지 않음)


Analysis
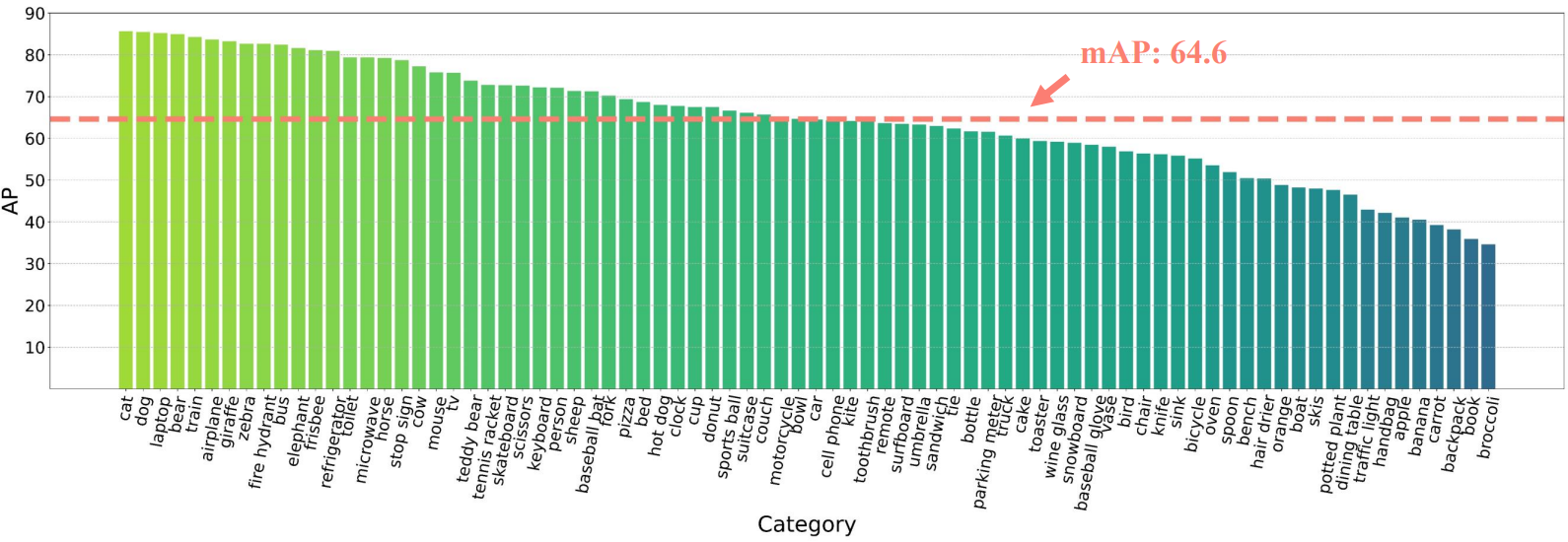
1. Analysis of Model Prediction Quality
다음은 COCO val2017의 각 카테고리의 AP이다.
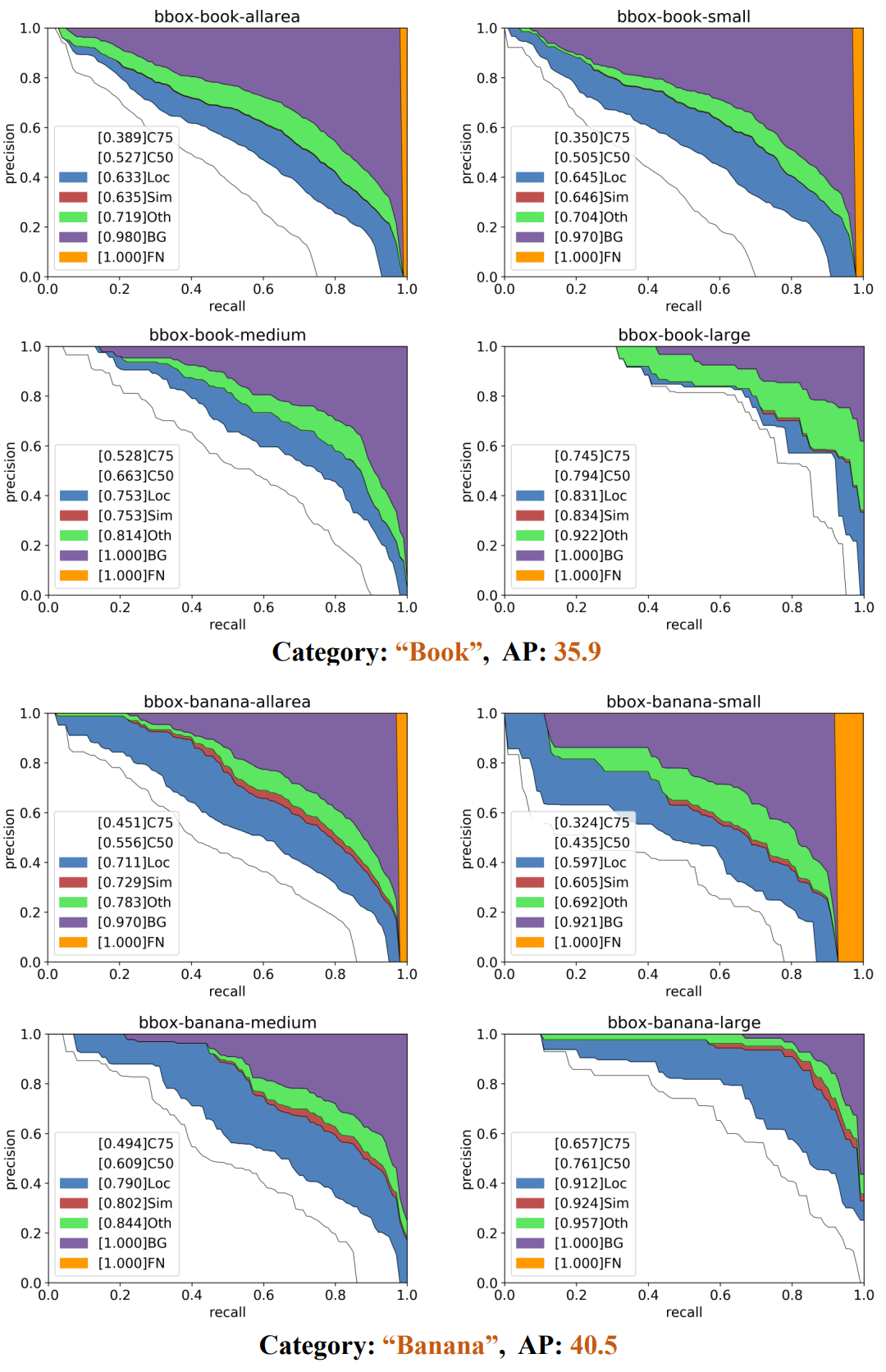
다음은 두 가지 나쁜 케이스에 대한 precision-recall 곡선이다.
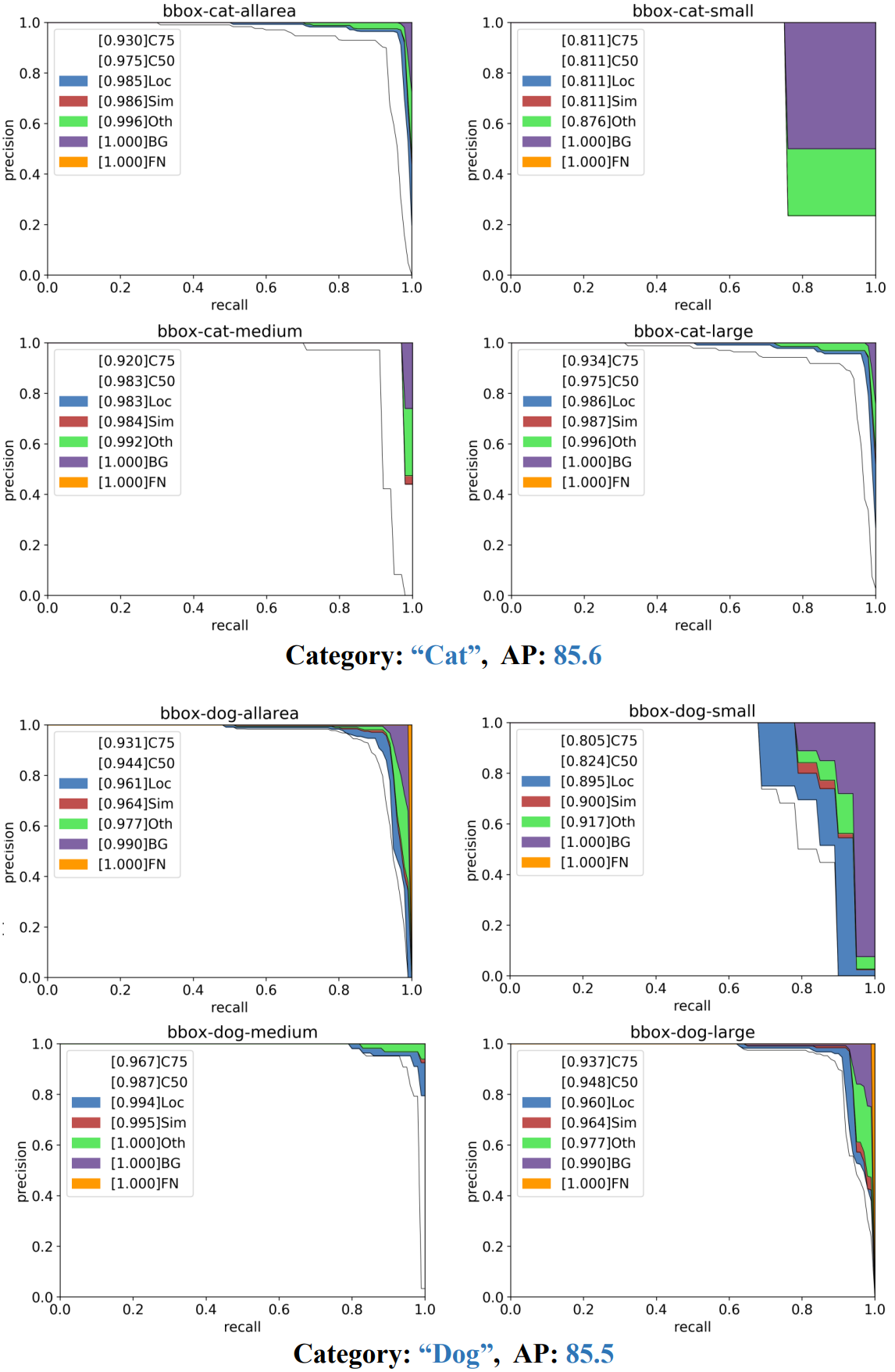
다음은 두 가지 좋은 케이스에 대한 precision-recall 곡선이다.
Visualization over special cases
다음은 카테고리 “책”과 “바나나”에 대한 누락된 예측을 시각화한 것이다.

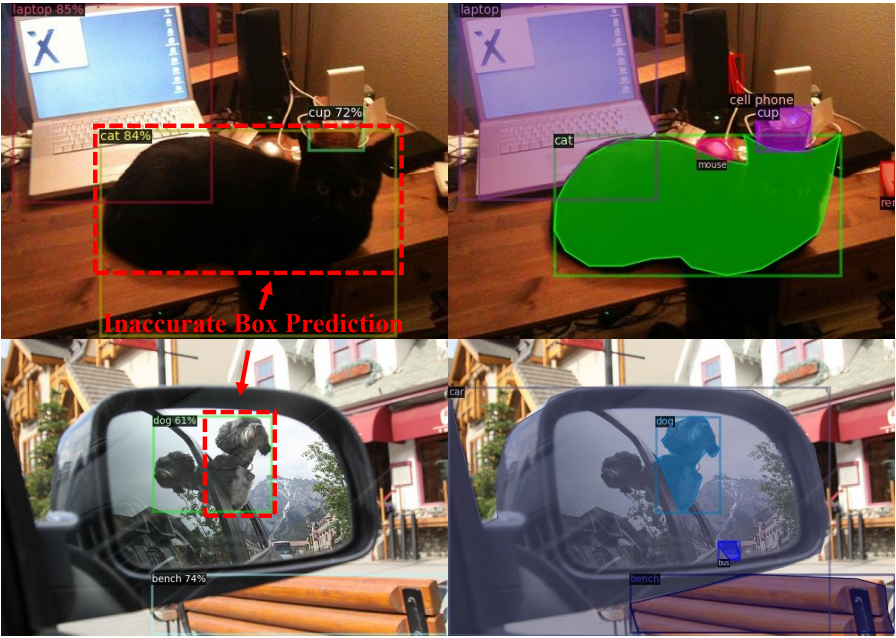
다음은 “고양이”와 “개” 카테고리에 대한 부정확한 상자 예측을 시각화한 것이다.
2. Analysis of Annotation Quality
Error annotations
다음은 데이터의 오류 주석 예시이다. 왼쪽은 예측 결과이고 오른쪽은 주석이다.

Missing labels
다음은 데이터의 누락된 레이블의 예시이다. 왼쪽은 예측 결과이고 오른쪽은 주석이다.

Inconsistency annotation standards
다음은 데이터의 불일치 주석 표준의 예시이다. 왼쪽은 예측 결과이고 오른쪽은 주석이다.
