[논문리뷰] FlexiViT: One Model for All Patch Sizes
CVPR 2023. [Paper] [Github]
Lucas Beyer, Pavel Izmailov, Alexander Kolesnikov, Mathilde Caron, Simon Kornblith, Xiaohua Zhai, Matthias Minderer, Michael Tschannen, Ibrahim Alabdulmohsin, Filip Pavetic
Google Research
15 Dec 2022
Introduction
ViT는 이미지를 겹치지 않는 패치로 자르고 이러한 패치에서 생성된 토큰에 대한 모든 계산을 수행한다. 이 “패치화” 절차는 이미지가 작은 로컬 필터와 일반적으로 겹치는 필터를 사용하여 처리되는 이전의 주요 CNN 접근 방식에서 상당한 변화를 나타낸다. 패치화를 통해 이미지 패치 토큰의 랜덤 삭제, 새로운 task를 위한 특수 토큰 추가, 이미지 토큰을 다른 modality의 토큰과 혼합하는 등의 새로운 기능을 사용할 수 있다.
ViT 모델에 대한 패치화의 중요성에도 불구하고 패치 크기의 역할은 거의 주목을 받지 못했다. 원본 ViT 논문은 세 가지 패치 크기 (32$\times$32, 16$\times$16, 14$\times$14)로 작동하지만 많은 후속 연구들에서는 패치 크기를 16$\times$16 픽셀로 수정하였다. 본 논문에서는 패치 크기가 모델 parameterization을 변경하지 않고도 모델의 계산 및 예측 성능을 변경할 수 있는 간단하고 효과적인 수단을 제공한다는 것을 보여준다. 예를 들어 ViT-B/8 모델은 156 GFLOPs와 8500만 개의 파라미터를 사용하여 ImageNet1k에서 85.6%의 top-1 정확도를 달성하는 반면, ViT-B/32 모델은 8.6 GFLOPs와 8700만 개의 파라미터를 사용하여 79.1% 정확도만을 달성한다. 성능과 컴퓨팅의 주요 차이점에도 불구하고 이러한 모델은 본질적으로 동일한 parameterization을 갖는다. 그러나 표준 ViT 모델은 학습된 패치 크기에서만 제대로 작동한다. 따라서 패치 크기를 조정하려면 모델을 완전히 재학습해야 한다.
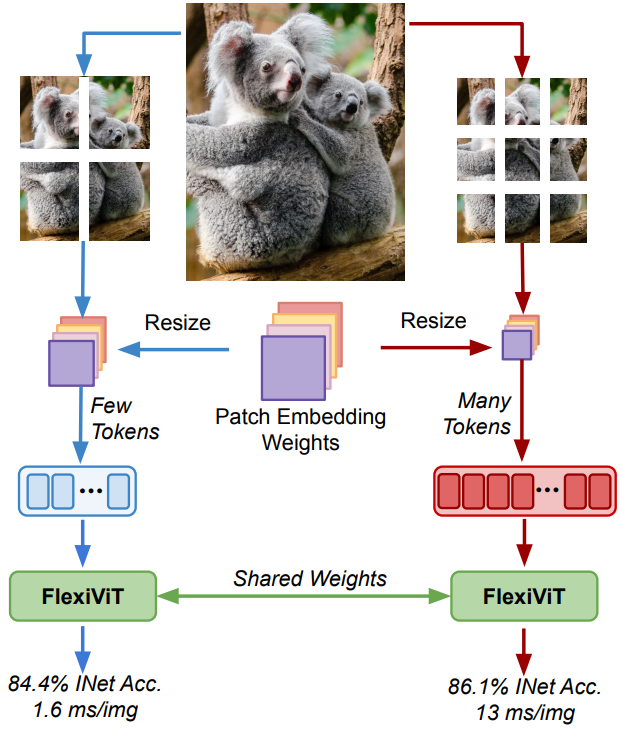
본 논문은 이러한 한계를 극복하기 위해 추가 비용 없이 광범위한 패치 크기에 걸쳐 표준 고정 패치 ViT와 일치하거나 그보다 뛰어난 성능을 제공하는 유연한 ViT인 FlexiViT를 제안한다. 위 그림과 같이 FlexiViT를 학습시키기 위해 학습 중에 패치 크기를 무작위로 지정하고 각 패치 크기에 맞게 위치 및 패치 임베딩 파라미터를 resizing한다. 이러한 간단한 수정은 이미 강력한 성능을 발휘하기에 충분하지만 본 논문은 더 나은 결과를 달성하는 최적화된 resizing 연산과 knowledge distillation에 기반한 학습 절차도 제안하였다.
Making ViT flexible
본 논문은 표준 ViT 모델이 유연하지 않음을 보여주고 supervised 이미지 분류 설정에서 FlexiViT 모델과 학습 절차를 소개하였다. 모든 실험은 ImageNet-21k 데이터셋에서 수행되었으며 기본 (ViT-B) 규모 모델과 How to train your ViT? 논문의 unregularized light2 설정을 사용하고 ConvNeXt 논문을 따라 90 epochs 동안 모델을 학습시켰다.
1. Standard ViTs are not flexible
먼저 다양한 패치 크기에서 사전 학습된 표준 ViT 모델을 평가하면 성능이 저하된다는 것을 보여준다. 패치 크기를 변경하려면 간단히 bilinear interpolation을 사용하여 패치 임베딩 가중치 $\omega$와 위치 임베딩 $\pi$를 크기 조정하면 된다. 위치 임베딩의 경우 이 크기 조정 접근 방식은 더 높은 해상도에서 fine-tuning하기 위해 원본 ViT 논문에서 이미 제안되었다.
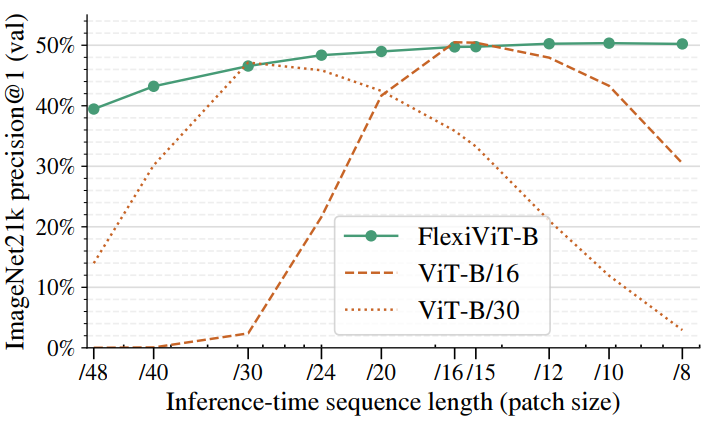
결과는 위 그림에 나와 있다. Inference 시에 패치 크기가 학습 중에 사용된 크기에서 벗어나면 표준 ViT 모델의 성능이 급격히 저하되는 것을 볼 수 있다.
2. Training flexible ViTs
위 그림에서는 학습 패치 크기로 평가했을 때 ViTB/16과 ViT-B/30 모두와 일치하고 다른 모든 패치 크기에 비해 훨씬 뛰어난 FlexiViT-B 모델의 성능도 보여준다. 이 모델은 ViTB/16, ViT-B/30 모델과 동일한 설정에서 학습되었다. 단, 각 학습 단계에서 패치 크기는 사전 정의된 패치 크기 집합에서 랜덤하게 균일하게 선택되었다. 그러기 위해서는 모델과 학습 코드에 두 가지 작은 변화가 필요하다.
첫째, 모델은 $\omega$와 $\pi$에 대한 기본 파라미터 형태를 정의해야 한다. 학습 가능한 파라미터는 해당 모양을 가지며 모델의 forward pass의 일부로 즉석에서 resizing된다. 학습 가능한 파라미터의 정확한 형태는 크게 중요하지 않으며, 저자들은 모든 실험에서 패치에는 32$\times$32, 위치 임베딩에는 7$\times$7의 기본 크기를 사용하였다.
둘째, 이미지를 완벽하게 타일링하는 다양한 패치 크기를 갖기 위해 240$\times$240의 이미지 해상도를 사용한다. 이는 패치 크기 $p \in$ {240, 120, 60, 48, 40, 30, 24, 20, 16, 15, 12, 10, 8, 6, 5, 4, 2, 1}을 허용하며, 이 중 48과 8 사이를 모두 사용한다. 각 iteration에서 이러한 패치 크기에 대한 균일 분포 $\mathcal{P}$에서 $p$를 샘플링한다. 이는 기존 ViT 학습 절차를 유연하게 만드는 데 필요한 모든 변경 사항이다. Algorithm 1은 이를 요약한다.

패치 크기 변경은 이미지 크기 변경과 관련되어 있지만 동일하지는 않다. 패치 크기는 순전히 모델의 변경일 뿐이며, 이미지 크기를 변경하면 사용 가능한 정보가 크게 줄어들 수 있다.
3. How to resize patch embeddings
입력 이미지의 패치 $x \in \mathbb{R}^{p \times p}$와 패치 임베딩 가중치 $\omega \in \mathbb{R}^{p \times p}$를 고려하고 음수가 아닌 값을 처리할 때 간단한 시나리오를 가정해 보자. Bilinear interpolation을 사용하여 패치 가중치와 임베딩 가중치를 모두 resizing하면 결과 토큰의 크기가 크게 달라진다. 예를 들어
\[\begin{equation} \langle x, w \rangle \approx \frac{1}{4} \langle \textrm{resize}_p^{2p} (x), \textrm{resize}_p^{2p} (\omega) \rangle \end{equation}\]이다. 저자들은 토큰 norm의 이러한 극적인 변화가 ViT의 경직성과 단일 FlexiViT 학습을 방해하는 inductive bias의 일부라고 가정하였다. 이상적으로는 resizing 중에 정보 손실이 없는 한 입력 $x$와 임베딩 $\omega$를 resizing한 후 패치 임베딩 $e_i = \langle x, w \rangle$이 동일하게 유지되어야 한다.
이러한 동등성을 달성하는 한 가지 방법은 명시적으로 또는 LayerNorm 모듈을 사용하여 임베딩 직후 토큰을 정규화하는 것이다. 그러나 이 접근 방식을 사용하려면 모델 아키텍처를 변경해야 하며 기존의 사전 학습된 ViT와 호환되지 않는다. 또한 패치 임베딩을 정확하게 보존하지 않는다.
먼저 선형 resize 연산은 선형 변환으로 표현될 수 있다.
\[\begin{equation} \textrm{resize}_p^{p_\ast} (o) = B_p^{p_\ast} \textrm{vec} (o) \end{equation}\]여기서 $o \in \mathbb{R}^{p \times p}$는 임의의 입력이고 $B_p^{p_\ast} \in \mathbb{R}^{p_\ast^2 \times p^2}$이다. 다중 채널 입력 $o$의 채널 크기를 독립적으로 조정한다.
크기 조정된 패치의 토큰이 원래 패치의 토큰과 일치하도록 새로운 패치 임베딩 가중치 $\hat{\omega}$ 세트를 찾는 것이 목표이다. 즉, 다음과 같은 최적화 문제를 해결해야 한다.
\[\begin{equation} \hat{w} \in \underset{\hat{\omega}}{\arg \min} \mathbb{E}_{x \sim \mathcal{X}} [(\langle x, \omega \rangle - \langle Bx, \hat{\omega} \rangle)^2] \end{equation}\]여기서 $B = B_p^{p_\ast}$이고 $\mathcal{X}$는 패치에 대한 어떤 분포이다. 패치 크기를 늘리는 경우 (ex. $p_\ast \ge p$), $\hat{\omega} = P \omega$를 사용할 수 있다. 여기서 $P = B(B^\top B)^{-1} \omega = (B^\top)^\dagger$는 $B^\top$의 pseudo-inverse이다.
\[\begin{equation} \langle Bx, \hat{\omega} \rangle = x^\top B^\top B (B^\top B)^{-1} \omega = x^\top \omega = \langle x, \omega \rangle \end{equation}\]이런 식으로 모든 $x$에 대해 패치 임베딩을 정확하게 일치시킨다.
다운샘플링의 경우, 즉 $p_\ast < p$인 경우 최적화 문제에 대한 솔루션은 일반적으로 패치 분포 $\mathcal{X}$에 따라 달라진다. $\mathcal{X} = \mathcal{N} (0, I)$인 경우, pseudo-inverse $\hat{\omega} = P \omega = (B^\top)^\dagger \omega$를 최적 솔루션으로 복구한다. 요약하면 PI-resize (pseudo-inverse resize)를 다음과 같이 정의한다.
\[\begin{equation} \textrm{PI-resize}_p^{p_\ast} (\omega) = ((B_p^{p_\ast})^\top)^\dagger \textrm{vec} (\omega) = P_p^{p_\ast} \textrm{vec} (\omega) \end{equation}\]여기서 $P_p^{p_\ast} \in \mathbb{R}^{p_\ast^2 \times p^2}$는 PI-resize 변환에 해당하는 행렬이다. PI-resize 연산은 패치 임베딩 가중치의 크기를 조정하여 bilinear resize 연산의 inverse 역할을 한다.

저자들은 PI-resize의 효과를 실험적으로 검증하고 이를 표준 linear resize를 포함한 여러 휴리스틱과 비교하기 위해 사전 학습된 ViT-B/8 모델을 로드하고 이미지와 모델 모두 크기 조정한 후 이를 평가하여 시퀀스 길이 $s = (224/8)^2 = 784$를 보존한다. 위 그래프에 표시된 결과는 PI-resize가 업샘플링 시 거의 일정한 성능을 유지하고 다운샘플링 시 점진적으로 성능이 저하됨을 보여준다. 전반적으로 PI-resize뿐만 아니라 휴리스틱도 잘 작동하지 않는다.
4. Connection to knowledge distillation
Knowledge distillation은 일반적으로 더 작은 student 모델이 일반적으로 더 큰 teacher 모델의 예측을 모방하도록 학습되는 인기 있는 기술이다. 이는 표준 label-supervised 학습에 비해 student 모델의 성능을 크게 향상시킬 수 있다.
Knowledge distillation는 표준 supervised 학습보다 훨씬 더 어려운 최적화 문제에 해당하며 teacher 가까이에 student를 초기화하면 이 문제가 완화된다는 것이 최근에 밝혀졌다. 불행하게도 teacher는 일반적으로 student보다 더 큰 아키텍처를 갖기 때문에 이 솔루션은 실용적이지 않다. 그러나 FlexiViT를 사용하면 강력한 ViT teacher의 가중치로 student FlexiViT를 초기화하고 distillation 성능을 크게 향상시킬 수 있다.
따로 명시하지 않는 한, 나머지 실험에 사용된 모델은 강력한 ViT-B/8 모델에서 초기화되고 추출된 FlexiViT-B이다. 초기화 시에 teacher의 패치 임베딩 가중치를 32$\times$32로 PI-resize하고 위치 임베딩을 7$\times$7로 bilinear하게 재샘플링하였다. 그런 다음 FunMatch 접근 방식에 따라 student 모델을 학습시켜 teacher의 예측과 랜덤 패치 크기를 갖춘 student FlexiViT의 예측 사이의 KL divergence를 최소화한다.
\[\begin{equation} \mathbb{E}_{x \in \mathcal{D}} \mathbb{E}_{p \sim \mathcal{P}} \textrm{KL} (f_\textrm{FlexiViT} (x, p) \; \| \; f_\textrm{ViT-B/8}(x)) \end{equation}\]여기서 $f_\textrm{FlexiViT} (x, p)$는 패치 크기가 $p$인 입력 $x$에 대한 FlexiViT 모델의 클래스에 대한 분포이며, $f_\textrm{ViT-B/8}(x)$는 정확히 동일한 입력에 대한 teacher의 예측 분포이다. $\mathcal{D}$는 random flips, crops, mixup이 포함된 학습 데이터 분포이며, $\mathcal{P}$는 FlexiViT 모델 학습에 사용되는 패치 크기에 대한 분포이다.
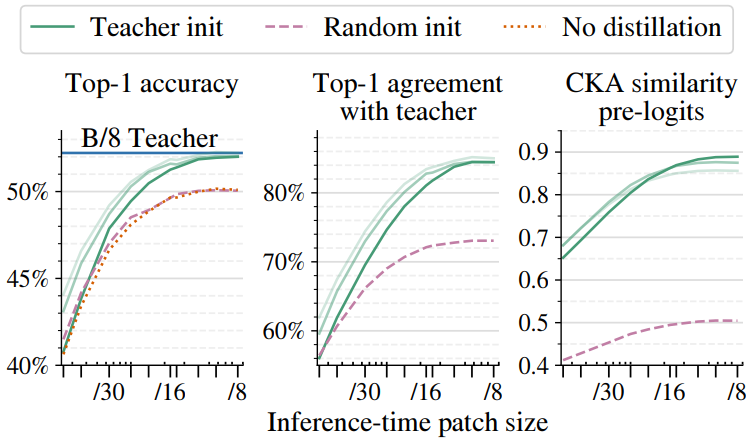
위 그래프는 teacher 초기화를 사용한 distillation 효과를 랜덤 초기화와 레이블을 사용한 supervised 학습과 비교한 그래프이다. 비교는 90 epochs에 대해 수행되었으며 FlexiViT의 고유한 초기화 능력의 상당한 이점을 보여준다. Distillation에는 시간이 필요하기 때문에 저자들은 위 그래프에서 연한 녹색 곡선으로 표시된 것처럼 300 epochs 또는 1000 epochs 동안 추가로 실험을 진행하였다. FlexiViT는 작은 패치 크기에서 teacher의 성과를 일치시키고 teacher 초기화는 가장 큰 패치 크기에서 정확성을 크게 향상시킨다.
5. FlexiViT’s internal representation
FlexiViT는 패치 크기가 다른 입력을 유사한 방식으로 처리하는가?
저자들은 모델의 내부 표현을 분석하여 이를 조사하였다. 신경망 내부 표현과 신경망 사이의 표현을 비교하기 위해 널리 사용되는 접근 방식인 minibatch centered kernel alignment (CKA)을 적용하였다. 시각화 목적으로 아크코사인 변환을 적용하여 CKA/코사인 유사도를 적절한 메트릭으로 변환한 다음 t-SNE를 수행하였다.
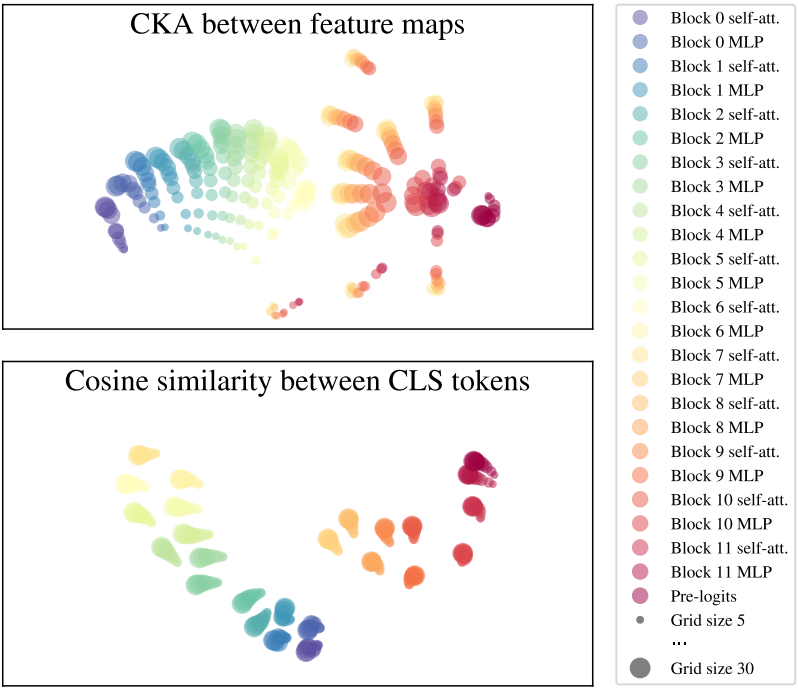
결과는 위 그림에 나와 있다. Feature map 표현은 첫 번째 레이어부터 Block 6의 MLP 하위 레이어까지 그리드 크기 전체에서 유사하다. Block 6의 MLP 하위 레이어에서 레이어 표현은 최종 블록에서 다시 수렴되기 전에 분기된다. 이와 대조적으로 CLS 토큰 표현은 그리드 크기에 따라 정렬된 상태로 유지된다. 따라서 FlexiViT의 상당 부분에 대한 내부 표현은 그리드 크기에 따라 다르지만 출력 표현은 일반적으로 정렬된다.
Using pre-trained FlexiViTs
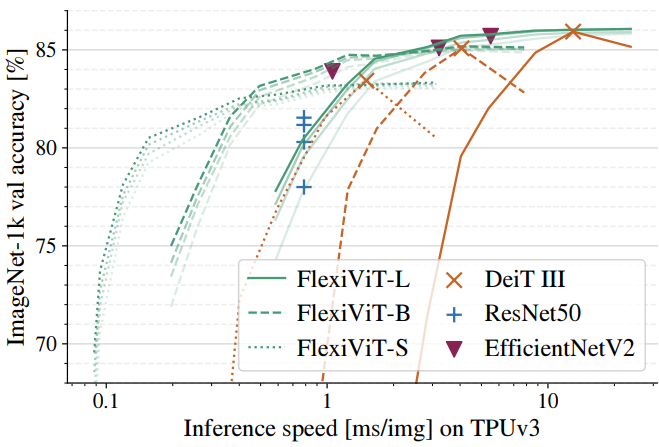
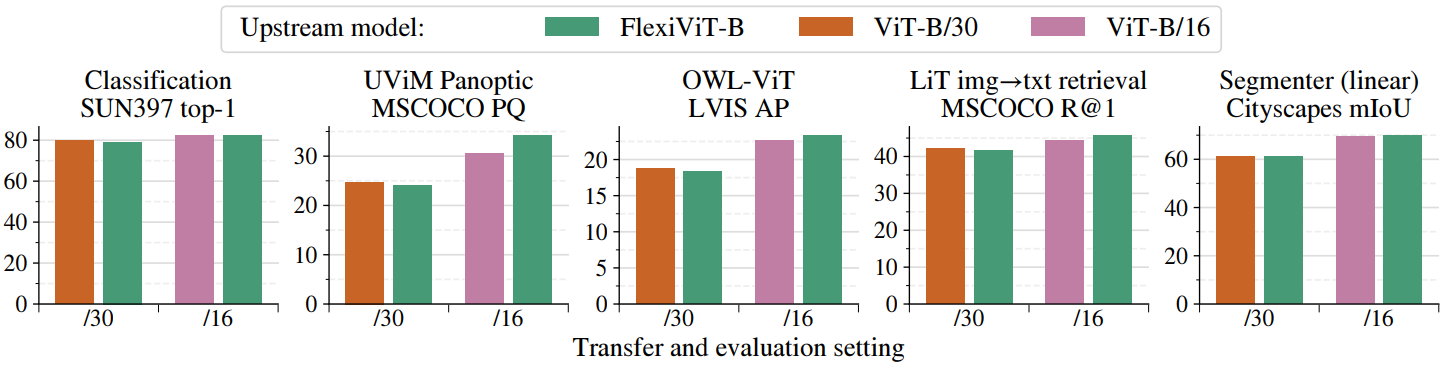
1. Results
다음은 사전 학습된 FlexiViT를 이용한 transfer 실험 결과이다.
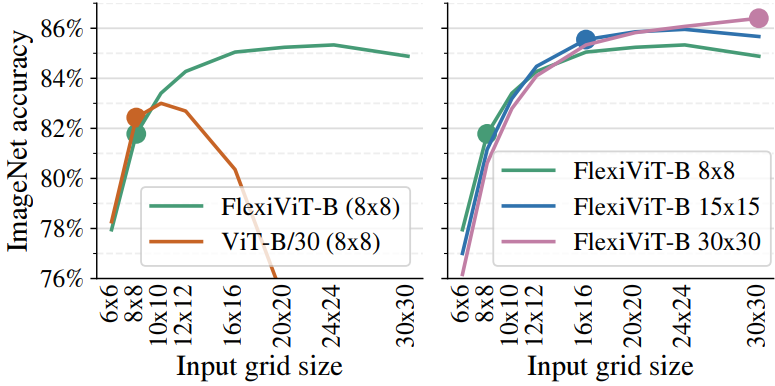
2. Resource-efficient transfer via flexibility
다음은 입력 그리드 크기에 따른 ImageNet 정확도를 비교한 그래프이다.
Flexifying existing training setups
기존의 사전 학습된 모델은 다운스트림 task로 전송되는 동안 유연해질 수도 있다. 아래에서는 다양한 기존 학습 설정을 유연하게 조정한 결과를 보여준다.
1. Transfer learning
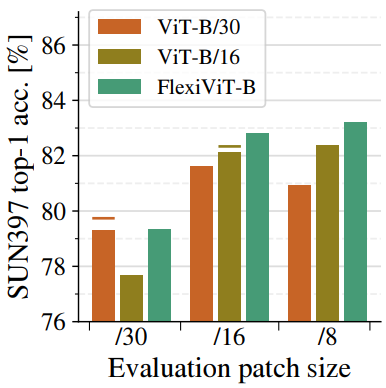
다음은 transfer 중에 패치 크기를 무작위로 지정하고 다양한 패치 크기에서 결과 모델을 SUN397 데이터셋에서 평가한 결과이다.
2. Multimodal image-text training
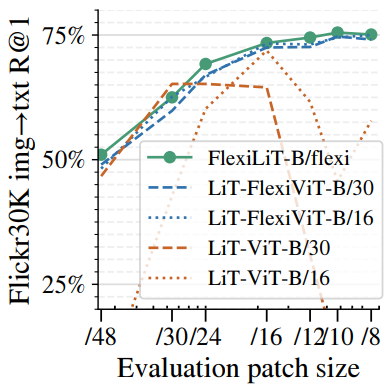
다음은 Flickr30k에서의 zero-shot image-to-text 검색 결과를 여러 패치 크기로 비교한 것이다.
3. Open-vocabulary detection
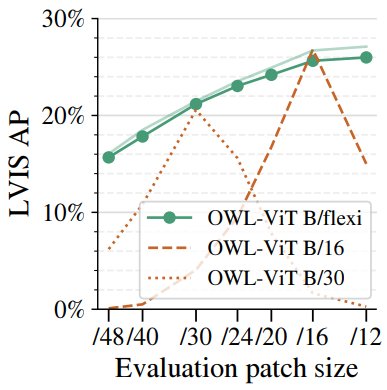
다음은 open-vocabulary detection에 대한 OWL-ViT의 성능을 여러 패치 크기로 비교한 것이다.
4. Training times and flexification
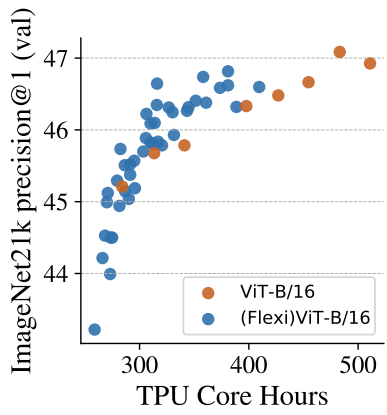
다음은 유연한 패치 크기를 사용하면 사전 학습을 가속화할 수 있음을 보여주는 그래프이다.
Analyzing FlexiViTs
다음은 패치 크기에 따른 attention relevance map을 비교한 것이다. (클래스: “fork”)

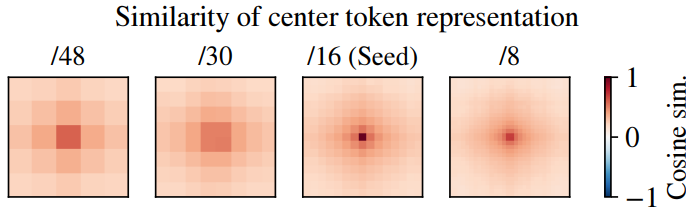
다음은 FlexiViT-B/16 feature map 중앙에 있는 시드 토큰 표현과 다른 패치 크기의 토큰 표현 간의 코사인 유사도를 나타낸 것이다.