[논문리뷰] FlexCap: Describe Anything in Images in Controllable Detail
NeurIPS 2024. [Paper] [Page]
Debidatta Dwibedi, Vidhi Jain, Jonathan Tompson, Andrew Zisserman, Yusuf Aytar
Google DeepMind | Carnegie Mellon University
18 Mar 2024

Introduction
기존의 image captioning 모델은 이미지의 요점을 포착하는 데 능숙하지만 종종 특정 물체나 속성을 정확히 파악하는 데 어려움을 겪는다. 반면 object detection 모델은 위치를 결정하는 데는 뛰어나지만 이를 포괄적으로 설명할 어휘가 부족할 수 있다. Dense captioning은 여러 영역에 대한 캡션을 생성하여 이러한 격차를 메우려 하지만 기존 데이터셋에 의해 표현력이 제한된다.
본 논문의 FlexCap은 관심 영역과 예측 캡션의 단어 수 측면에서 원하는 수준의 디테일을 지정하여 공간적으로 정확하고 의미적으로 풍부한 캡션을 생성할 수 있다. 이를 통해 image captioning, object detection, dense captioning의 장점을 하나의 모델로 통합할 수 있다.
FlexCap을 학습시키려면 많은 bounding box에 짧고 긴 설명이 레이블링된 이미지 데이터셋이 필요하다. 저자들은 이미지, 이미지 내의 제안된 영역, 특정 길이의 캡션으로 구성된 세 개의 텍스트를 생성하는 방법을 제안하였다. 이는 open-vocabulary object detector를 사용하여 이미지-텍스트 쌍 데이터셋의 캡션에서 영역에 레이블링하여 수행한다. 저자들은 YFCC100M에 대한 2억 개의 triplet과 WebLI에 대한 320억 개의 triplet을 구성하였다. 이러한 데이터셋에서 FlexCap을 학습시키면 모델이 물체, 물체의 속성, 맥락적으로 변화하는 설명에 초점을 맞춘 공간적, 의미적으로 풍부한 표현을 생성할 수 있다.
FlexCap
Length Conditioning
이미지의 동일한 영역에 대해 여러 개의 유효한 캡션이 있을 수 있다. 본 논문은 length conditioning이라는 아이디어를 활용하여 원하는 길이의 출력을 생성하는 능력을 모델에 제공하였다. 출력 캡션의 원하는 길이를 나타내는 추가 토큰을 사용하여 입력을 컨디셔닝한다. Length conditioning을 사용한 학습은 세 가지 주요 이유에서 유용하다.
- 설명하는 데 사용되는 단어 수는 종종 정보량에 비례한다. 원하는 길이를 고려하면서 시퀀스의 다음 단어를 예측하도록 모델을 학습시키면, 모델은 생성된 텍스트의 정보량을 조절하는 방법을 학습한다.
- 사용자는 모델의 출력을 제어할 수 있으므로 다양한 task에 하나의 모델을 사용할 수 있다.
- Length prefix는 captioner에게 더 나은 초기 상태를 제공한다.
동일한 bounding box에 GT 캡션 <sos> dog <eos>와 <sos> dog playing with a frisbee <eos>가 있다고 하자. 첫 번째 캡션을 GT로 사용하고 단어 <sos> dog를 입력 텍스트로 사용하면 next-word prediction loss로 인해 모델이 <eos> 토큰에 대한 점수를 높이고 playing에 대한 점수를 낮추도록 한다.
이것이 문제가 될지 여부는 데이터셋 통계에 따라 달라진다. 이러한 문제가 생기는 비율을 정량화하기 위해 저자들은 통계를 계산하였다. 각 bounding box에 대해 모든 캡션 쌍을 고려하고 접두사 단어를 공유하는 쌍의 비율을 측정하였다.
저자들이 추후 설명할 방법으로 생성한 WebLI 캡션 데이터셋에 있는 모든 이미지를 조사한 결과, 모든 캡션 쌍의 30.8%가 접두사를 공유하였다. <sos> 대신 length conditioning 토큰을 사용하면 접두사 일치 확률이 30.8%에서 11.1%로 감소한다. Length conditioning은 모델이 동일한 접두사를 가진 캡션을 구별하는 데 도움이 되는 동시에 모델에 새로운 능력을 제공한다.
Architecture
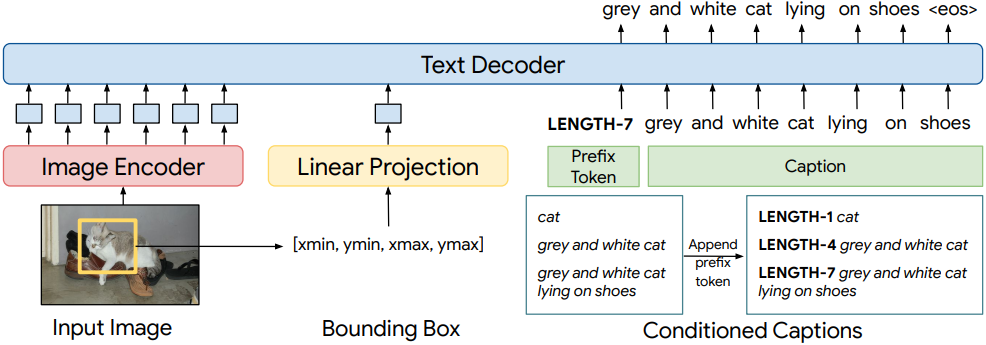
모델은 이미지, 관심 영역의 bounding box 좌표, 조건 토큰을 입력으로 받고, bounding box가 차지하는 영역에 대한 원하는 길이의 텍스트 설명을 출력한다. 모델은 크게 이미지 인코더인 SOViT-400M/14와 transformer 기반 텍스트 디코더로 구성된다.
입력 이미지는 비전 모델에 전달되어 $n \times d$의 비전 토큰을 생성한다 ($n$은 패치 수, $d$는 임베딩 크기). Bounding box 좌표(1$\times$4)는 linear layer에 전달되어 $1 \times d$의 좌표 토큰을 생성한다. 비전 토큰과 정규화된 좌표 토큰은 concat되어 $(n + 1) \times d$의 입력을 형성하여 텍스트 디코더에 전달된다.
텍스트 디코더는 $L$개의 transformer layer의 스택으로 구성되며 decoder-only 아키텍처를 사용한다. 모든 비전 토큰과 좌표 feature는 마스킹되지 않은 상태로 유지되지만, 텍스트 토큰은 인과적(causal) 방식으로 마스킹되어 next-token prediction 학습이 가능하다. 저자들은 768차원의 self-attention transformer layer 12개와 attention head 12개로 구성된 텍스트 디코더를 학습시켰다.
FlexCap은 총 5.9억 개의 파라미터를 가지고 있으며, 그 중 4.28억 개는 이미지 인코더(SOViT)이고 나머지는 텍스트 디코더에 있다. Linear layer는 비전 인코더의 1152차원 출력을 텍스트 디코더의 768차원 입력으로 변환한다. 저자들은 WebLI의 웹 스케일 비전-텍스트 쌍을 사용하여 학습된 이미지 인코더인 SigLIP 가중치로 비전 인코더를 초기화하였다. 학습하는 동안 비전 인코더는 고정되지 않고 함께 학습된다.
Loss
FlexCap을 학습시켜 텍스트의 다음 토큰을 예측한다. 텍스트 토큰은 원하는 캡션 길이로 prefix를 붙이고 캡션의 끝을 나타내는 end of sentence 토큰 <eos>를 추가한다. 타겟 텍스트 토큰은 패딩된 텍스트를 1만큼 이동하여 얻는다.
Loss는 vocabulary에 있는 모든 단어에 대한 classification loss이며, 패딩된 토큰에 대한 loss는 무시된다. 데이터 샘플을 이미지 $X$, bounding box $B$, 캡션 \(W = \{\textrm{LENGTH-K, w_1, \ldots, w_k}\}\)로 구성된 triplet $T = (X, B, W)$로 표현하자. Batch 학습을 가능하게 하기 위해 tokenize된 캡션을 고정된 크기 $M$으로 패딩한다. 주어진 데이터 triplet에 대하여 다음과 같은 log-likelihood를 최대화하도록 학습시킨다.
\[\begin{equation} l(X, B, W) = \sum_{i=1}^M \log p(w_i \vert w_{<i}, X, B) \end{equation}\]데이터 집합 \(\mathcal{D} = \{T_1, \ldots, T_N\}\)이 있다고 가정하면, 전체 loss는 다음과 같다.
\[\begin{equation} L(D) = \sum_{j=1}^N l (X_j, B_j, W_j) = \sum_{j=1}^N \sum_{i=1}^M \log p((w_j)_i \vert (w_j)_{<i}, X_j, B_j) \end{equation}\]Inference
Inference 시에는 이미지, bounding box, 원하는 길이를 입력으로 제공한다. 그런 다음, <eos>에 도달하거나 최대 디코딩 step 수에 도달할 때까지 autoregressive 방식으로 디코딩하며, greedy decoding을 사용한다. (다른 샘플링 기술도 사용 가능)
Localized Captions Dataset
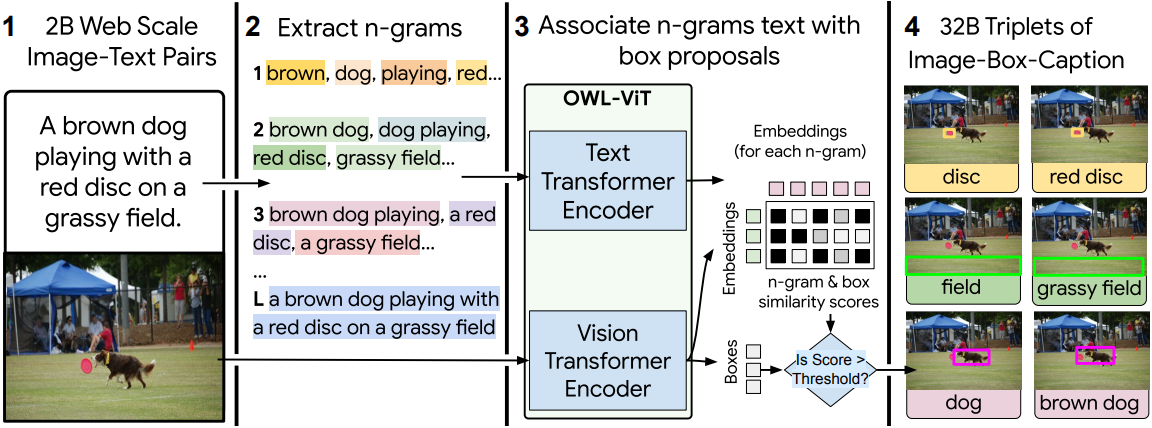
저자들은 FlexCap 모델을 학습시키기 위해 다양한 길이의 이미지 영역 설명에 대한 대규모 데이터셋을 구축하였다. 저자들은 WebLI와 YFCC100M 같은 웹 기반 이미지-캡션 쌍 데이터셋을 활용하여 데이터셋을 생성하였다.
- 이미지 캡션에서 n-gram을 사용하여 텍스트 쿼리를 생성한다. (\(n = \{1, \ldots, 8\}\))
- “with a red, “dog playing with”과 같은 불완전한 캡션을 필터링한다.
- 필터링된 n-gram을 사전 학습된 region proposal model OWL-ViT에 대한 텍스트 쿼리로 사용하여 bounding box를 추출한다.
- 유사도 점수에 따라 각 텍스트 쿼리마다 bounding box를 선택한다. (0.1 보다 크면 선택)
여러 n-gram이 bounding box에 일치할 수 있으며, 이는 이미지에서 bounding box를 설명하는 여러 가지 방법으로 이어진다.
WebLI
WebLI 데이터셋에 대한 이 데이터 수집 기법은 새로운 주석 없이도 20억 개의 이미지에서 320억 개의 (이미지, bounding box, 캡션) triplet을 생성한다. 캡션은 이미지의 컨텍스트에서 물체를 설명하는 데 사용되는 일반적인 언어에 가까운 풍부한 어휘를 보여준다. MS-COCO의 vocabulary를 사용하면 데이터셋의 모든 사람이 ‘사람’으로 레이블링된다. 그러나 제안된 방식으로 vocabulary를 구축하면 아기, 간호사, 경찰관, 소방관과 같은 더 많은 정보가 포함된 캡션을 얻게 된다.
YFCC100M
또한, 저자들은 YFCC100M 이미지를 사용하여 데이터셋을 만들었다. 구체적으로는 CLIP 논문과 동일한 1,400만 개의 이미지를 사용하였으며, 최종적으로 적어도 하나의 유효한 bounding box가 있는 약 1,100만 개의 이미지가 사용되었다. 평균적으로 각 이미지에는 bounding box가 20개 있어 이 데이터셋의 크기는 약 2억 개의 (이미지, bounding box, 캡션) triplet이다. YFCC100M triplet의 수는 WebLI에서 생성된 데이터셋보다 160배 작다.
OWL-ViT와 YFCC100M의 CLIP 이미지들은 모두 공개적으로 사용 가능하므로, 데이터셋은 오픈소스 모델과 공개 데이터셋으로 생성할 수 있다. WebLI 데이터셋은 아직 공개적으로 사용할 수 없다.
Experiments
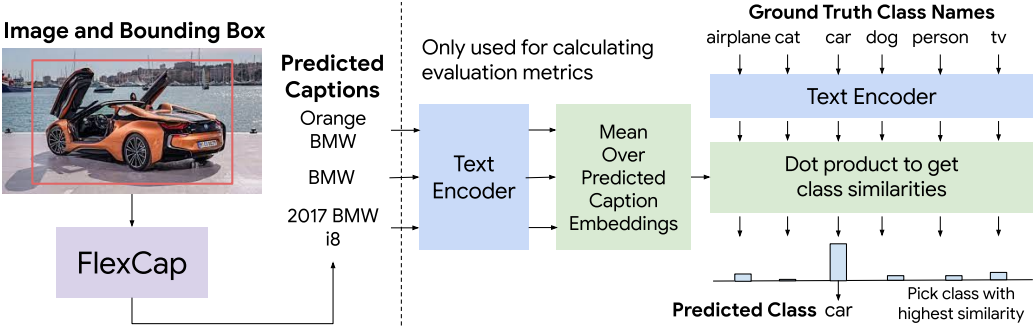
1. Correctness and Compliance of Generated Captions
다음은 FlexCap에서 얻은 캡션을 CLIP 텍스트 인코더로 평가한 예시이다.
다음은 MS-COCO region classification 성능을 비교한 표이다.

다음은 FlexCap으로 생성된 캡션들의 예시들이다.

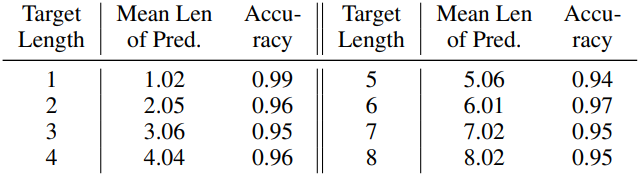
다음은 목표 길이에 따른 생성된 캡션 길이를 평가한 표이다.
2. Visual Question Answering (VQA)
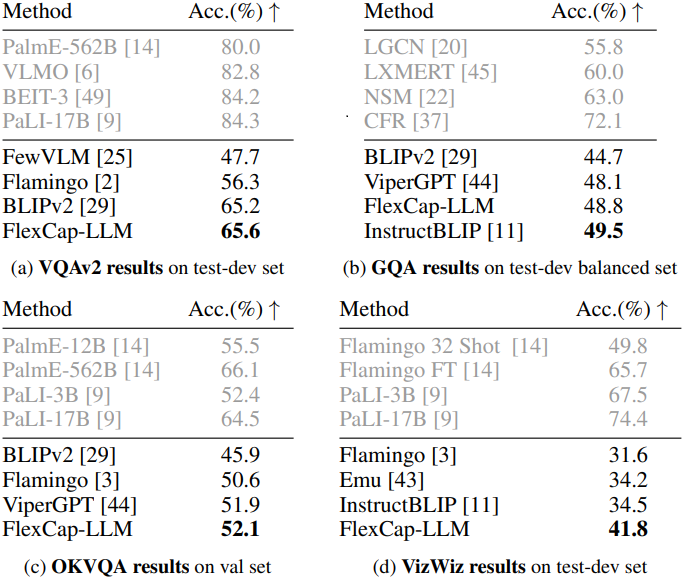
다음은 zero-shot 이미지 QA 결과이다.
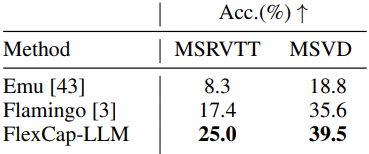
다음은 zero-shot 동영상 QA 결과이다.
3. Dense Captioning
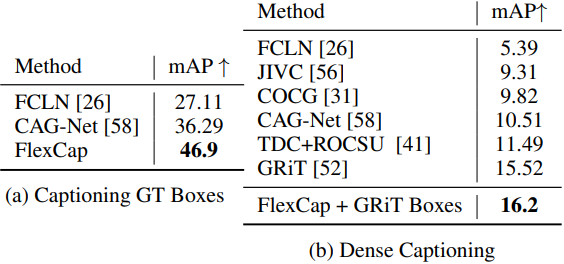
다음은 Visual Genome 데이터셋에서 캡션 생성 결과를 비교한 표이다.
4. Open-Ended Object Detection
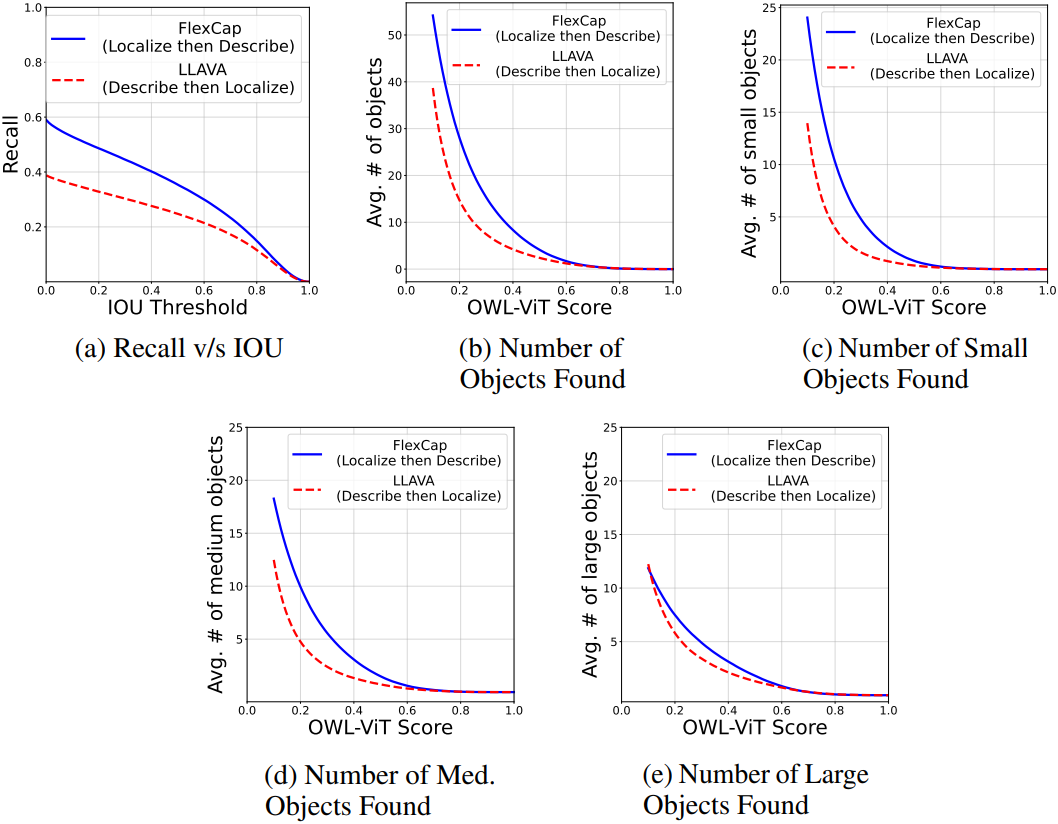
다음은 Visual Genome 데이터셋에서 open-ended object detection 결과를 LLAVA와 비교한 표이다.
5. Discussion
다음은 접두사로 FlexCap을 컨디셔닝하여 속성을 추출한 예시들이다.

다음은 접두사로 FlexCap을 컨디셔닝하여 캡션을 생성한 예시들이다.
