[논문리뷰] FiffDepth: Feed-forward Transformation of Diffusion-Based Generators for Detailed Depth Estimation
ICCV 2025. [Paper] [Page] [Github]
Yunpeng Bai, Qixing Huang
The University of Texas at Austin
1 Dec 2024

Introduction
기존 monocular depth estimation (MDE) 방법들은 사전 학습된 diffusion model을 채택해 왔는데, 주요 아이디어는 사전 학습된 RGB 이미지 diffusion model을 이미지 조건에 맞춰 depth map 생성 모델로 직접 fine-tuning하는 것이었다. 그러나 이러한 방법은 MDE 모델이 다양성보다 확실성을 요구하기 때문에 이상적이지 않을 수 있다. 생성 과정 중에 noise나 불확실성이 도입되는 것은 최적의 결과를 가져오지 못한다. 이와 대조적으로, 본 논문에서는 denoising 모듈을 feed-forward 방식으로 사용하는 것이 더 나은 안정적인 결과를 제공함을 관찰했다. 이 방법은 이미지 diffusion model의 궤적을 깊이 도메인으로 확장함으로써 생성 모델 기반 깊이 추정 방법의 정확성과 효율성을 크게 향상시켰다.
구체적으로, 본 논문에서는 MDE에 최적화된 diffusion 궤적을 사용한다. Diffusion model을 MDE 모델로 fine-tuning할 때 원래 생성 학습 궤적을 보존하여 원래 생성 모델의 디테일한 feature를 최대한 유지한다. 또한, 저자들은 fine-tuning된 diffusion model이 다양한 실제 이미지에서 robustness를 유지하는 데 한계가 있음을 인지하였으며, 특히 예측된 깊이의 부정확성은 주로 저주파 성분에서 발생하였다. 따라서 디테일이 부족함에도 불구하고 정확한 저주파 깊이 예측에 탁월한 DINOv2 기반 모델의 장점을 활용한다. 구체적으로, diffusion model 자체를 사용하여 부정확한 예측을 개선하는 필터를 학습시켜 DINOv2의 예측과 유사한 수준의 디테일을 가진 저주파 출력을 생성함으로써 DINOv2의 결과와 일치시키고 출력의 저주파 성분을 최적화한다. 이를 통해 생성 모델의 디테일 보존을 희생하지 않고도 대량의 실제 이미지 데이터를 학습에 활용할 수 있으며, 동시에 DINOv2의 강력한 일반화 능력을 활용하여 MDE 모델의 전반적인 robustness와 정확도를 향상시킬 수 있다.
Method
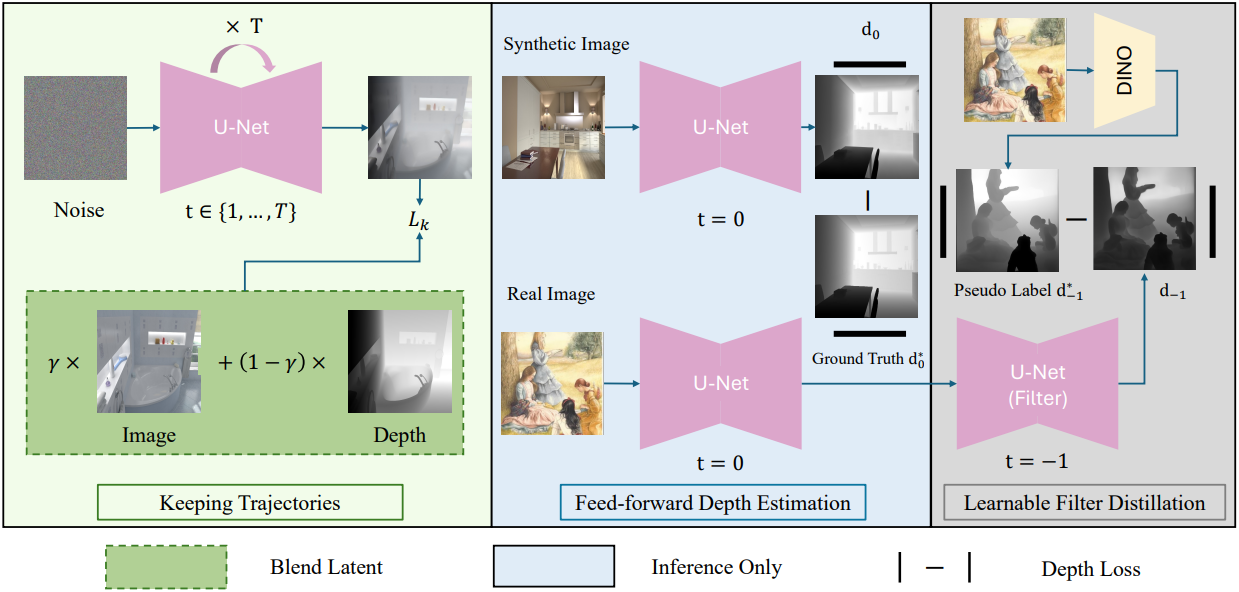
1. Overview
근본적으로 생성형 모델은 latent space와 데이터 공간 사이의 매핑을 구축한다. 이러한 매핑은 이미지 데이터에서 해당 레이블로의 정확한 매핑이 필수적인 깊이 추정 task와 밀접하게 관련되어 있다. 깊이 추정 task에서 레이블이 있는 데이터의 부족은 학습된 모델의 정확도를 제한하는 경우가 많다. 반면 대규모 데이터셋으로 학습된 생성형 모델은 robust한 매핑을 학습할 수 있다.
구체적으로, 본 논문에서는 잘 학습된 Stable Diffusion (SD) 모델을 fine-tuning하여 모델을 구축하였다. 깊이 추정에서 이미지에서 깊이 레이블로의 매핑은 이상적으로는 deterministic해야 한다. 생성 모델 내에서 robust하고 사전 학습된 매핑을 활용함으로써, 학습 과정에서 이미지-레이블 매핑을 여러 step으로 분해할 필요가 없다. 대신, 기존 diffusion model의 매핑 궤적을 깊이 도메인으로 직접 확장하여 학습된 diffusion process를 deterministic한 1-step feed-forward network처럼 작동하도록 할 수 있다. 본 논문의 MDE 모델은 확장을 위해 diffusion 궤적을 기반으로 구축되었으므로, 이 feed-forward step에서 timestep 입력값을 $t = 0$으로 설정한다.
\[\begin{equation} \textbf{d}_0 = \hat{\epsilon}_\theta (\textbf{x}_0, t = 0) \end{equation}\](\(\textbf{x}_0\)는 RGB 이미지의 latent 표현, \(\textbf{d}_0\)는 깊이 이미지의 latent 표현)
\(\textbf{d}_0\)는 SD의 VAE를 사용하여 오차가 거의 없이 depth map으로 재구성할 수 있다.
2. Keeping Diffusion Trajectories
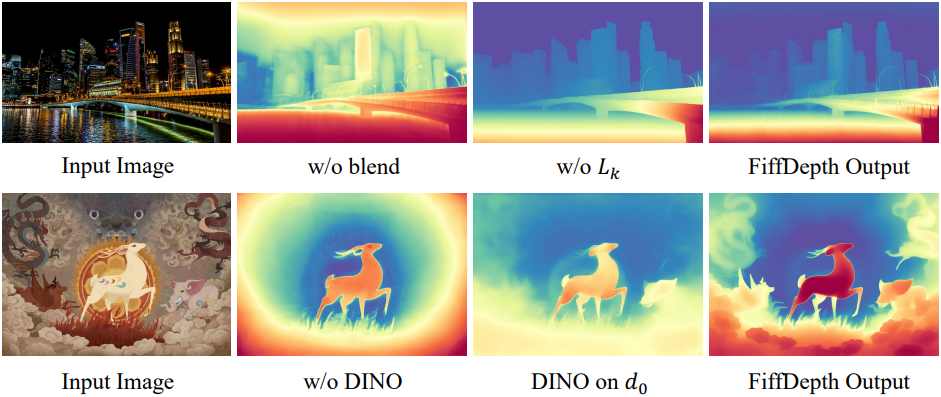
본 논문에서 제시하는 접근 방식은 diffusion model의 궤적을 활용하기 때문에 학습 과정에서 이 궤적이 저하되는 것을 방지하는 것이 매우 중요하다. 이를 위해 diffusion model을 fine-tuning하는 과정에서, 기존 diffusion model의 feed-forward step과 그 이전의 denoising 학습 step을 동시에 유지한다. 이 궤적은 원래 이미지 생성을 위해 개발되었지만, 이를 그대로 깊이 도메인에 적용하는 것은 최적의 전환을 어렵게 한다. 따라서 순수하게 이미지 기반의 latent를 예측하는 대신, 타겟 latent를 이미지와 깊이 표현이 혼합된 형태로 수정한다.
\[\begin{equation} \textbf{b}_0 = \gamma \textbf{x}_0 + (1 - \gamma) \textbf{d}_0 \\ \textbf{b}_t = \sqrt{\vphantom{1} \bar{\alpha}_t} \textbf{b}_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon \end{equation}\]이 과정에서 v-prediction re-parameterization을 사용하여 loss를 정의한다.
\[\begin{equation} \textbf{v}_t = \sqrt{\vphantom{1} \bar{\alpha}_t} \epsilon - \sqrt{1 - \bar{\alpha}_t} \textbf{b}_0 \\ L_k = \| \textbf{v}_t - \hat{\epsilon}_\theta (\textbf{b}_t, t) \|_2^2 \end{equation}\]직관적으로, 이 접근 방식은 diffusion model이 이미지 생성 작업과 깊이 추정 작업 간의 공통 feature를 보존하도록 강제하며, 이러한 feature는 혼합된 타겟에 포착된다. 따라서 diffusion model은 필수적인 생성적 feature를 유지하면서 깊이 추정에 더욱 자연스럽게 적응할 수 있다. 결과적으로, fine-tuning 과정에서 모델은 깊이 예측의 정확도와 디테일을 향상시키는 feature를 유지한다. 이 부분은 학습 과정에서만 사용되며, inference 시에 모델은 완전히 deterministic한 프레임워크로 작동한다.
3. Learnable Filter Distillation
기존 방법들을 따라, 학습 과정에는 고품질의 GT 깊이를 제공하는 합성 데이터만을 사용한다. 그러나 합성 데이터셋만으로 학습된 SD 기반 MDE 모델은 실제 데이터에 대한 일반화 성능이 떨어지는 경우가 많다. 그럼에도 불구하고, 이 경우 SD 기반 MDE 모델이 생성한 예측 결과는 최종 출력에서 보존해야 할 디테일을 유지한다. 따라서 모델의 robustness를 향상시킨다는 것은 본질적으로 실제 이미지에서 모델 출력의 저주파 성분 정확도를 개선하는 것을 의미한다.
저자들은 합성 데이터로 학습된 DINOv2 기반 모델이 실제 이미지에 효과적으로 일반화될 수 있음을 확인했다. 그러나 DINOv2 기반 모델의 깊이 추정치는 종종 디테일이 부족하다. Depth Anything v2는 fine-tuning된 DINOv2-G 깊이 모델을 사용하여 pseudo label을 생성하고 학습 데이터셋을 확장하는 방법을 사용하였다. 그러나 DINOv2의 깊이 예측은 디테일이 부족하기 때문에, 이러한 pseudo label을 feed-forward 출력 \(\textbf{d}_0\)에 직접 통합하면 모델에 내재된 디테일한 feature를 무시할 위험이 있다.
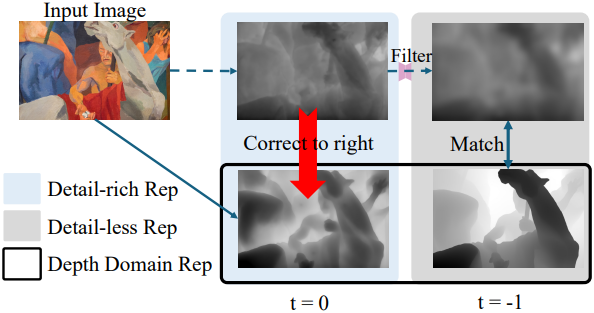
이 문제를 해결하기 위해, 저자들은 출력에서 고주파 디테일을 제거하는 필터 \(F(\textbf{d}_0)\)를 학습시키는 것을 제안하였다. 이 필터링은 DINOv2와 유사한 수준의 디테일을 제공하므로, 정확도가 낮은 저주파 성분에만 집중하여 supervised learning을 수행할 수 있다.
저자들은 fine-tuning된 SD 모델 자체가 이미 효과적인 필터 역할을 한다는 것을 관찰했다. Diffusion model은 본질적으로 서로 다른 timestep 간의 미묘한 차이를 모델링하도록 설계되었기 때문이다. 따라서, 이 필터를 시뮬레이션하기 위해 feed-forward 출력 \(\textbf{d}_0\)에 추가적인 SD step을 1번 적용한다.
\[\begin{equation} \textbf{d}_{-1} = \hat{\epsilon}_\theta (\textbf{d}_0, t=-1) \end{equation}\]DINOv2가 예측한 레이블과 \(\textbf{d}_{-1}\) 사이의 loss를 구성하면 \(\textbf{d}_0\)의 디테일한 feature를 방해하지 않고 DINOv2의 robustness를 전달할 수 있다. 이 과정에서 \(\textbf{x}_0\)는 실제 이미지 데이터를 사용한다.
4. Final Objective
\(\textbf{d}_0\)와 \(\textbf{d}_{-1}\)에 대하여, MiDaS를 따라 MAE loss \(L_\textrm{MAE}\)와 gradient matching loss \(L_\textrm{GM}\)을 loss로 사용한다. 하지만 MiDaS와는 달리, 이러한 loss들을 SD의 latent space에 적용한다.
\[\begin{aligned} L_\textrm{MAE} (\textbf{d}, \textbf{d}^\ast) &= \frac{1}{M} \sum_{i=1}^M \vert \textbf{d}_i - \textbf{d}_i^\ast \vert \\ L_\textrm{GM} (\textbf{d}, \textbf{d}^\ast) &= \frac{1}{M} \sum_{i=1}^M (\vert \nabla_x R_i \vert + \vert \nabla_y R_i \vert), \quad \textrm{where} \; R_i = \textbf{d}_i - \textbf{d}_i^\ast \end{aligned}\](\(\textbf{d}^\ast\)는 GT latent, $\textbf{d}$는 모델의 예측값)
따라서 최종 loss는 다음과 같다.
\[\begin{equation} L_\textrm{final} = \sum_{t \in \{-1, 0\}} (\lambda_\textrm{MAE} L_\textrm{MAE} (\textbf{d}_t, \textbf{d}_t^\ast) + \lambda_\textrm{GM} L_\textrm{GM} (\textbf{d}_t, \textbf{d}_t^\ast)) + \lambda_k L_k \end{equation}\]\(\textbf{d}_0^\ast\)는 합성 데이터셋의 GT이고, \(\textbf{d}_{-1}^\ast\)는 실제 이미지에 대해 DINOv2 기반 모델이 생성한 pseudo label이다.
Experiments
- 데이터셋
- 합성 (74K): Hypersim, Virtual KITTI
- 실제 (200K): LAION-Art
- 구현 디테일
- DINOv2 기반 모델: Depth Anything V2-Large
- 합성 데이터와 실제 데이터는 batch의 절반씩
- $\gamma = 0.5$, \(\lambda_\textrm{MAE} = 1\), \(\lambda_\textrm{GM} = 0.5\), \(\lambda_k = 0.2\)
1. Zero-shot affine-invariant depth
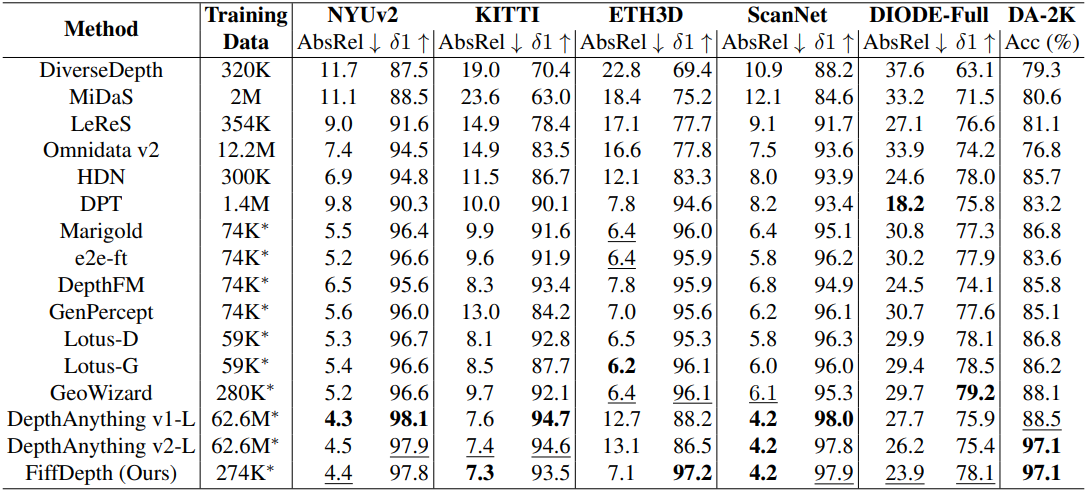
다음은 여러 zero-shot 벤치마크에 대한 성능을 비교한 결과이다.
다음은 특수한 시나리오에 대한 비교 결과이다. (게임, 아트워크, AI 생성 컨텐츠, 영화)

2. Zero-shot boundaries
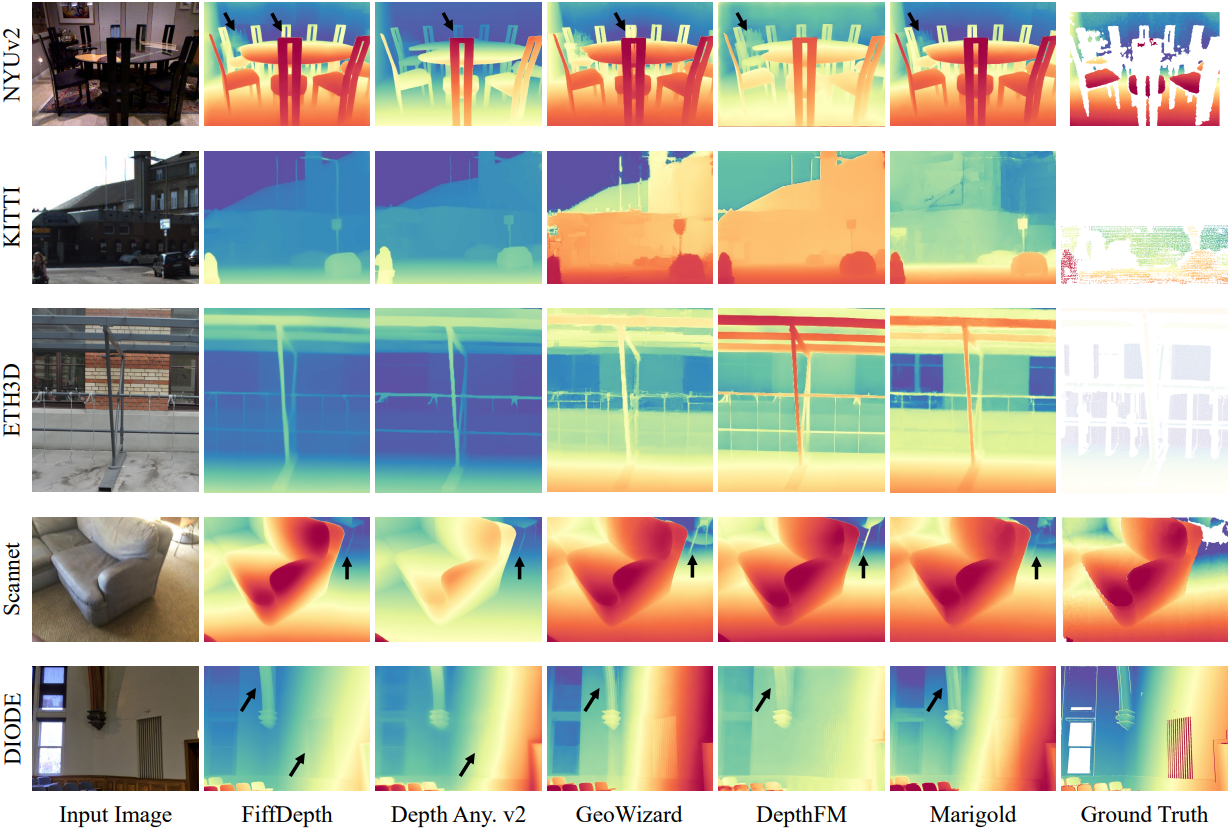
다음은 경계의 정확도를 비교한 결과이다.


3. Running time
다음은 512$\times$512 이미지에 대한 inference 시간을 비교한 결과이다. (100장 평균)

4. Ablation studies
다음은 ablation study 결과이다.