[논문리뷰] Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation
arXiv 2022. [Paper] [Github]
Yixuan Wei, Han Hu, Zhenda Xie, Zheng Zhang, Yue Cao, Jianmin Bao, Dong Chen, Baining Guo
Tsinghua University | Microsoft Research Asia
27 May 2022
Introduction
사전 학습 및 fine-tuning 패러다임은 컴퓨터 비전 분야의 딥러닝 방법 개발에 핵심적인 역할을 해왔다. 2006년에 오토인코더 기반 사전 학습은 딥러닝의 폭발적인 촉발을 촉발한 선구적인 연구였다. 또한 AlexNet이 2012년 ImageNet-1K 이미지 분류에서 혁신적인 인식 정확도를 달성한 이후 이미지 분류 task를 사용한 모델 사전 학습은 object detection과 semantic segmentation을 포함한 다양한 다운스트림 컴퓨터 비전 task에 대한 표준 관행이 되었다.
컴퓨터 비전의 표현 학습을 위해 두 가지 주목할만한 접근 방식, 즉 instance contrastive learning과 image-text alignment 방법이 매우 성공적이었다. 전자는 self-supervised 방식으로 표현을 학습하고 이미지 분류에 대한 인상적인 선형 평가 성능을 달성하였다. CLIP 접근 방식으로 대표되는 후자는 zero-shot 인식 분야를 개척하여 시각적 인식 모델이 거의 모든 카테고리를 분류할 수 있게 하는 것으로 유명하다. 그러나 다운스트림 비전 task를 fine-tuning하면 일반적으로 성능이 다른 방법보다 우수하지 않으므로 폭넓은 채택이 제한된다.
최근 Masked Image Modeling (MIM)은 fine-tuning 평가에서 놀라운 성능을 발휘하여 광범위한 관심을 끌었다. MIM의 성공은 왜 MIM이 fine-tuning에서 훨씬 더 나은 성능을 발휘하는가에 대한 의문을 제기하였다. 즉, fine-tuning에서 MIM만큼 성공하기 위해 다른 사전 학습 접근 방식에 추가할 수 있는 핵심 요소가 있는가에 대한 의문을 제기하였다.
본 논문에서는 간단한 feature distillation 방법이 일반적으로 DINO와 EsViT와 같은 contrastive 기반 self-supervised 접근 방식, CLIP과 같은 비전-언어 모델, DeiT와 같은 이미지 분류 방법 등을 포함하여 다양한 사전 학습 방법의 fine-tuning 성능을 향상시킬 수 있음을 보여주었다. Feature distillation 방법에서는 이미 학습된 표현을 처음부터 학습되는 새로운 feature로 증류한다. 증류 타겟의 경우, 본 논문은 logit 대신 feature map을 사용한다. 이를 통해 임의의 사전 학습 방법으로 얻은 feature를 처리하고 더 나은 fine-tuning 정확도를 얻을 수 있다. 또한 화이트닝된 distillation 타겟, 공유 상대 위치 바이어스, 비대칭 drop path rate를 포함하여 연속적인 fine-tuning 프로세스에 도움이 되는 유용한 디자인을 제안하였다.
이러한 접근 방식과 신중한 디자인을 통해 DINO나 EsViT와 같은 contrastive 기반 self-supervised 사전 학습 접근 방식은 MIM 접근 방식에 따라 fine-tuning 평가에서 경쟁력을 갖거나 심지어 성능이 약간 더 향상된다. CLIP 사전 학습된 ViT-L 모델은 ImageNet-1K 이미지 분류에서 89.0%의 top-1 정확도를 달성하여 ViT-L의 새로운 SOTA를 달성하였다. 30억 파라미터의 SwinV2-G 모델의 fine-tuning 정확도는 ADE20K semantic segmentation과 COCO object detection에서 각각 +1.5mIoU/+1.1mAP만큼 개선되어 61.4mIoU/64.2mAP로 향상되었으며, 두 벤치마크 모두에서 새로운 기록을 세웠다.
본 논문은 향후 연구가 최적화 친화성에 선점되지 않고 학습된 표현의 일반성과 확장성에 더 많은 관심을 집중할 수 있는 방법을 제공한다. 일반성과 확장성은 사전 학습을 광범위한 비전 task에 적합하게 만들 뿐만 아니라 학습된 네트워크가 더 큰 모델 용량과 더 큰 데이터를 최대한 활용할 수 있도록 하기 때문에 매우 중요하다. 기존 연구에서는 일반성과 확장성의 목표가 최적화 친화성 목표와 얽혀 있는 경우가 많다. Feature distillation 접근 방식은 이 두 가지 목표를 어떻게 분리할 수 있는지를 조명하고 일반성과 확장성이라는 중요한 문제에 더 많은 노력을 기울일 수 있도록 해준다.
A Feature Distillation Method
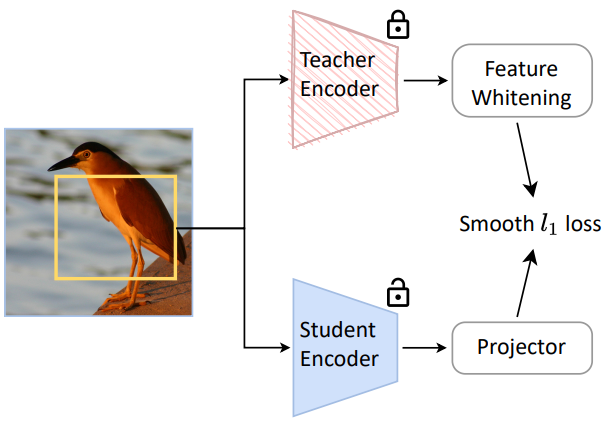
본 논문은 이미 사전 학습된 모델에서 지식을 추출하는 동시에 fine-tuning에 더 친숙한 새로운 표현을 얻는 것이 목표이다. 위 그림에 설명된 것처럼 feature distillation 방법을 통해 이를 달성한다. 이 방법에서는 이미 사전 학습된 모델이 teacher 역할을 하고 새 모델이 student 역할을 한다. 본 논문은 이 방법을 일반적이고 효과적으로 만들기 위해 다음과 같은 디자인을 고려하였다.
일반화되도록 feature map을 증류
대부분의 이전 distillation 연구처럼 logit을 증류하는 대신 사전 학습된 모델의 출력 feature map을 distillation 타겟으로 채택한다. Feature map을 distillation 타겟으로 사용하면 logit 출력이 없을 수 있는 사전 학습된 모델로 작업할 수 있다. 보다 일반적인 것 외에도 feature map을 추출하는 것은 logit이나 축소된 단일 feature 벡터를 사용하는 것보다 더 높은 fine-tuning 정확도를 보여준다.
Teacher와 student의 feature map을 비교 가능하게 만들기 위해 각 원본 이미지에 대해 동일한 augmentation view를 채택한다. 또한 student 네트워크 위에 1$\times$1 convolution layer를 적용하여 teacher와 student 간의 출력 feature map의 다양한 차원을 허용함으로써 이 방법을 더욱 일반화할 수 있다.
Distillation을 위한 teacher feature의 화이트닝
다양한 사전 학습된 모델은 feature 크기의 순서가 매우 다를 수 있으며, 이로 인해 다양한 사전 학습 접근 방식에 대한 hyperparameter 튜닝이 어려워진다. 이 문제를 해결하기 위해 스케일링과 바이어스 없이 non-parametric layer 정규화 연산자로 구현되는 화이트닝 연산을 통해 teacher 네트워크의 출력 feature map을 정규화한다.
Distillation에서는 student과 teacher feature map 간에 smooth $\ell_1$ loss를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{distill} (s, t) = \begin{cases} \frac{1}{2} (g(s) - \textrm{whiten} (t))^2 / \beta, & \quad \vert g(s) - \textrm{whiten} (t) \vert \le \beta \\ (\vert g(s) - \textrm{whiten} (t) \vert - \frac{1}{2} \beta), & \quad \textrm{otherwise} \end{cases} \end{equation}\]여기서 $\beta$는 default로 2.0으로 설정된다. $s$와 $t$는 각각 student와 teacher 네트워크의 출력 feature 벡터이다. $g$는 1$\times$1 convolution layer이다.
공유 상대 위치 바이어스
원래 ViT에서는 상대 위치 바이어스 (RPB)가 절대 위치 인코딩 (APE)에 비해 어떤 이점도 나타내지 않았으므로 일반적으로 ViT 아키텍처에는 APE가 사용된다.
Feature distillation 프레임워크에서는 APE와 RPB를 포함하여 student 아키텍처의 위치 인코딩 구성 효과를 재검토하였다. 또한 모든 레이어가 동일한 상대 위치 바이어스 행렬을 공유하는 공유 RPB 구성을 고려하였으며, 실험을 통해 공유 RPB가 전반적으로 가장 좋은 성능을 발휘한다는 것을 발견했다. 저자들은 공유 RPB가 head들의 attention 거리를 다양화할 수 있으며, 특히 더 깊은 레이어에 대해 약간 더 나은 fine-tuning 정확도를 달성할 수 있음을 발견했다.
비대칭 drop path rate
Feature distillation 프레임워크의 2가지 방식을 사용하면 teacher와 student 네트워크에 비대칭 정규화를 사용할 수 있다. 저자들은 비대칭 drop path rate 전략이 더 나은 표현을 학습하는 데 도움이 된다는 것을 발견했다. 특히, ViT-B에서는 student 분기에 0.1-0.3의 drop path rate를 적용하고 teacher 분기에는 drop path 정규화를 적용하지 않는 전략이 가장 잘 작동한다.
Representations before and after Feature Distillation
저자들은 head당 평균 attention 거리, head들의 attention map 간 평균 코사인 유사도, 각 레이어에 대한 평균 attention map, 정규화 loss등을 포함한 일련의 attention 및 최적화 관련 진단 도구를 통해 feature distillation 메커니즘을 자세히 살펴보았다. 저자들은 50,000개의 ImageNet-1K validation 이미지를 사용하여 이러한 분석을 수행하고 distillation 방법을 적용하기 전과 후에 모델을 진단하였다. Feature distillation 전후에 학습된 표현의 다양한 속성 동작이 관찰되었다.
Feature distillation은 attention head들을 다양화한다
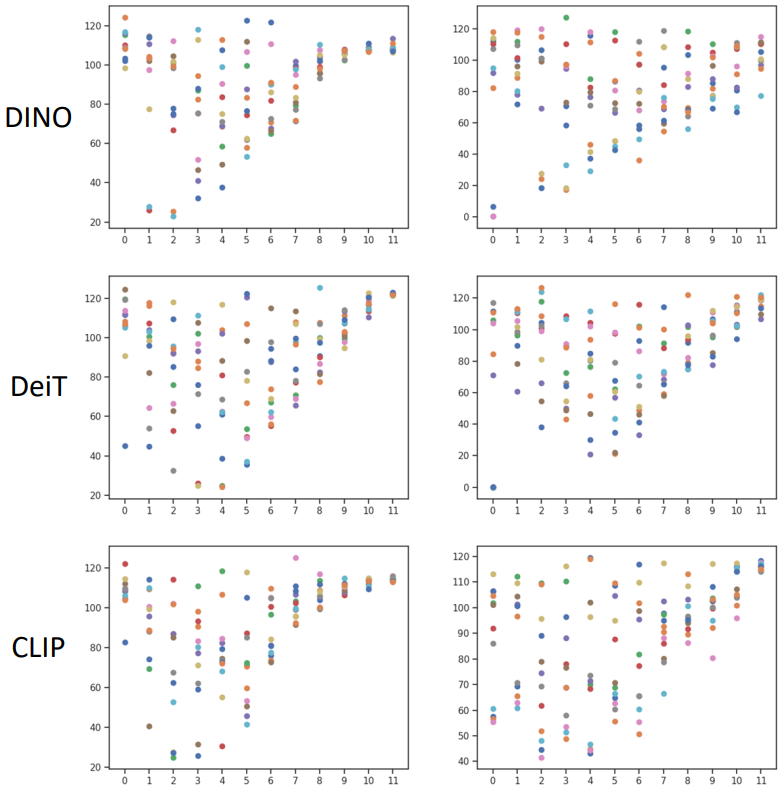
저자들은 head들의 attention 다양성을 조사하였다. 위 그림은 각각 DINO, DeiT, CLIP으로 사전 학습된 ViT-B 아키텍처를 사용하여 head별 평균 attention 거리와 레이어 깊이를 보여준다. 왼쪽은 feature distillation 전이고 오른쪽은 후이다. 평균 attention 거리는 attention 가중치에 따라 계산된 각 attention head에 대한 receptive field 크기를 부분적으로 반영할 수 있다.
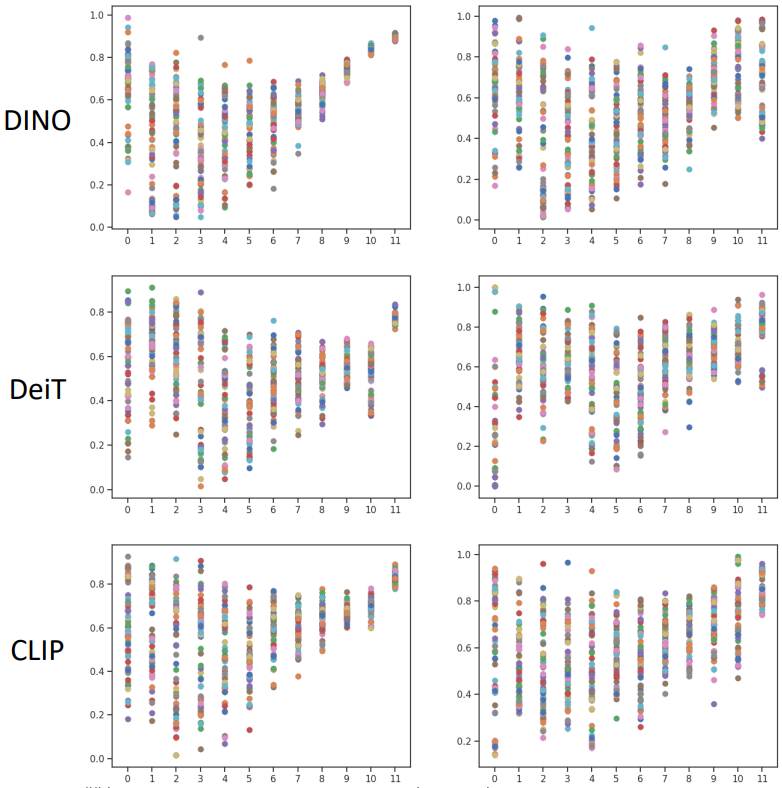
위 그림에서 다음을 관찰할 수 있다. Distillation 전에 사전 학습된 모든 표현의 경우 더 깊은 레이어에 있는 다양한 head들의 attention 거리가 붕괴되어 매우 작은 거리 범위 내에 위치한다. 이는 서로 다른 head가 매우 유사한 시각적 단서를 학습하고 모델 용량을 낭비할 수 있음을 의미한다. Feature distillation 과정이 끝나면 모든 표현은 attention 거리가 더욱 다양해지고 고르게 분포된다. 특히 더 깊은 레이어의 경우 더욱 그렇다. 이 관찰은 각 레이어의 attention head 간 평균 코사인 유사도를 계산하는 아래 그림에도 반영된다 (왼쪽이 전, 오른쪽이 후).
Attention 패턴의 변화
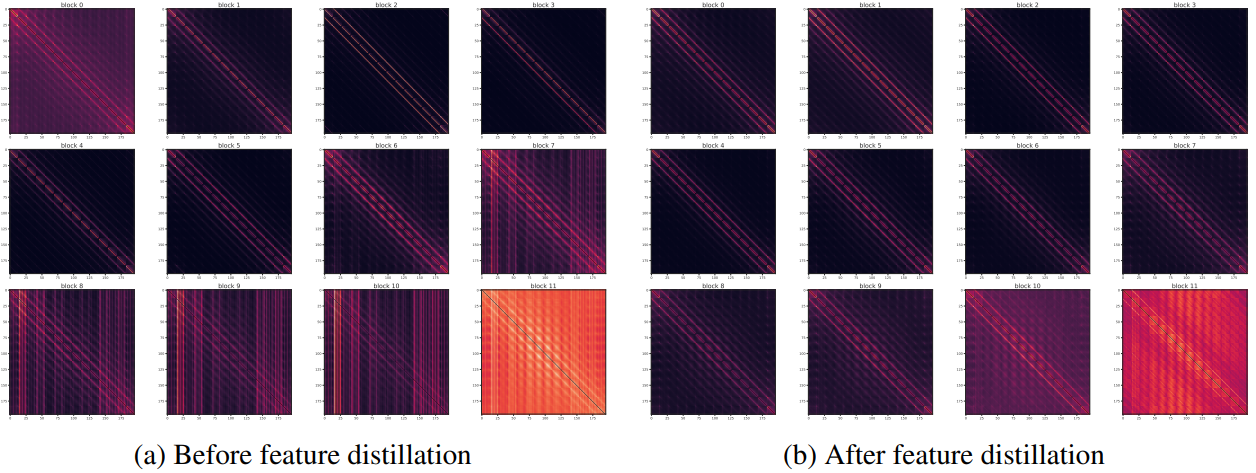
위 그림은 feature distillation 전(왼쪽)과 후(오른쪽)의 평균 attention map을 보여준다. Attention map에는 대각선(diagonal)과 열(column)이라는 두 가지 명백한 패턴이 있다. 대각선 패턴은 고정된 상대 위치의 이미지 패치 간의 관계에 해당하는 반면, 열 패턴은 특정 절대 위치의 이미지 패치가 다른 모든 위치에 미치는 영향을 나타낸다.
Feature distillation 후의 표현에는 훨씬 더 많은 대각선 패턴이 있음을 알 수 있다. 이는 모델이 상대 위치의 관계를 인코딩하는 시각적 단서에 더 많이 의존한다는 것을 의미한다. 이는 모델이 더 나은 평행이동 불변성을 가지도록 하며, 다양한 비전 task에 유용한 속성인 경우가 많다.

저자들은 student 네트워크에 공유 RPB가 포함되어 있다는 점에 주목하여 그 효과를 연구하기 위해 student 아키텍처에서 절대 위치 인코딩 (APE)을 사용하려고 시도했으며 그 attention map은 위 그림에 표시되어 있다. Feature distillation 후 표현도 레이어 0과 레이어 7과 같은 상대 위치에 더 많이 의존하며 fine-tuning 정확도도 상당히 높다. 이는 더 많은 대각선 패턴이 주로 feature distillation 알고리즘 자체에 의해 발생함을 나타낸다.
Feature distillation을 통해 loss/정확도 landscape가 더 좋아진다
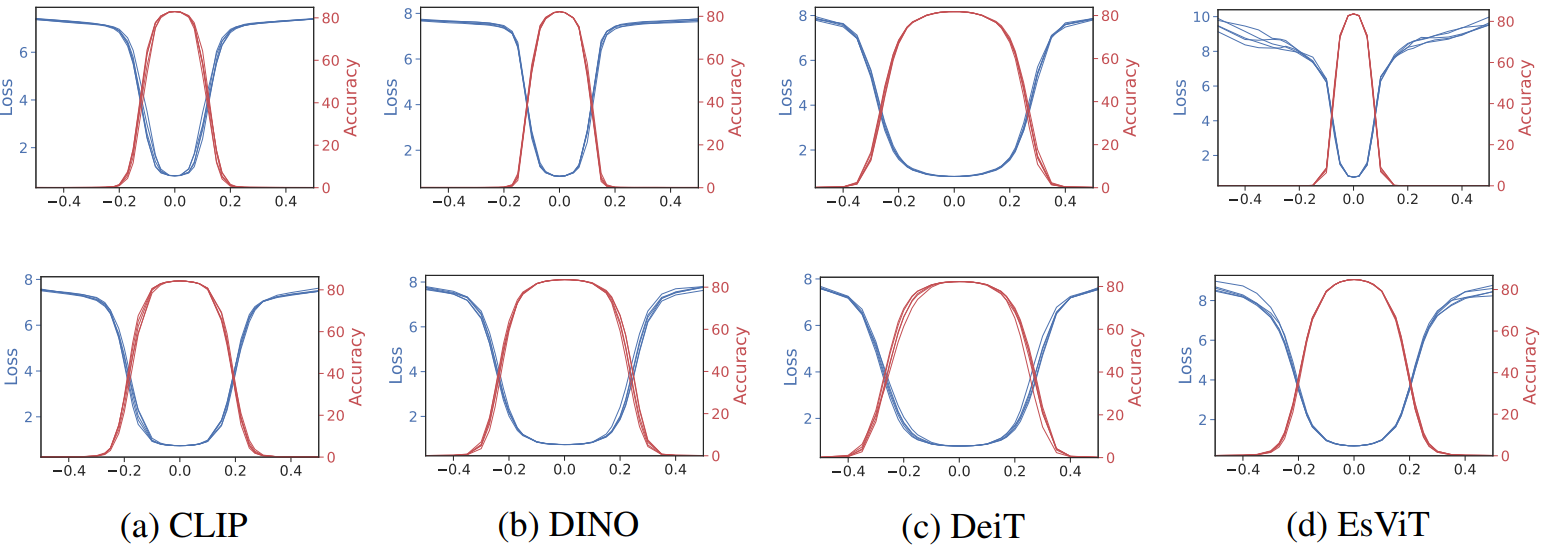
저자들은 Visualizing the Loss Landscape of Neural Nets 논문의 방법을 사용하여 다양한 모델의 loss/정확도 landscape를 시각화하였다. 이 시각화 방법에서 모델 가중치는 다양한 정도의 일련의 Gaussian noise에 의해 교란된다. 각 noise level은 다양한 모델의 다양한 가중치 진폭 효과를 설명하기 위해 각 필터의 $\ell_2$ norm으로 정규화되어 정의된다. 위 그림은 feature distillation 전후의 여러 사전 학습된 모델의 loss/정확도 landscape를 시각화한 것이다. Feature distillation 후 대부분의 표현의 loss/정확도 landscape는 distillation 전 표현의 것보다 더 평탄해졌으며 이는 더 나은 fine-tuning 정확도와 일맥상통하다.
Masked image modeling (MIM)
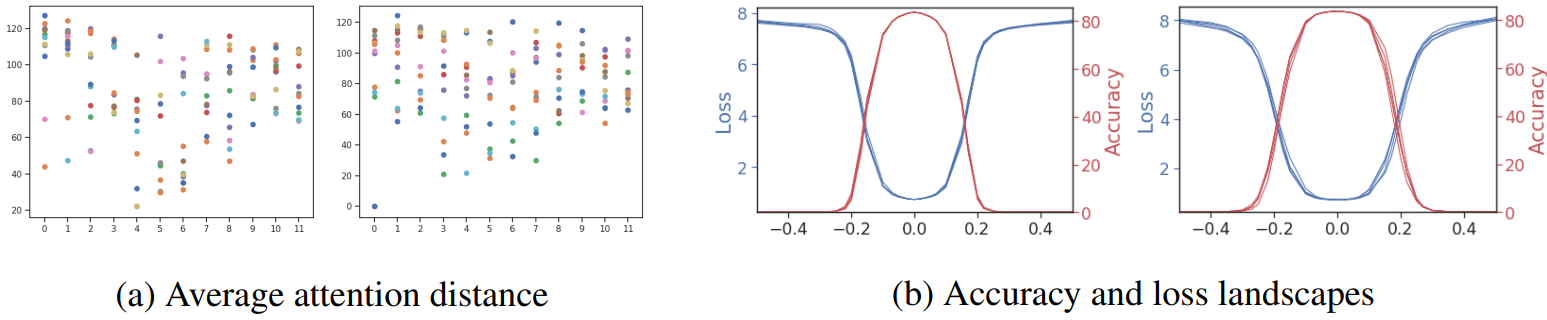
위 그림은 feature distillation 전후의 MIM 기반 접근 방식인 MAE의 평균 attention 거리와 loss/정확도 landscape를 보여준다. MAE를 사용하여 사전 학습된 표현은 여러 head들을 학습했으며 loss/정확도 landscape가 상대적으로 평탄하다는 것을 알 수 있다. 실제로 feature distillation 방법을 통해 기존 MAE 표현을 새로운 표현으로 추가 변환하면 +0.2%(83.6% $\rightarrow$ 83.8%)의 약간의 이득만 얻을 수 있다. 이러한 결과는 feature distillation 후처리를 통해 얻은 우수한 fine-tuning 성능이 MIM 방법과 기능이 어느 정도 중복된다는 것을 시사할 수 있다.
Experiments
- 데이터셋: ImageNet-1K (이미지 128만 개)
- 구현 디테일
- epochs: 100 (system-level 비교에서만 300)
- optimizer: AdamW
- learning rate: $1.2 \times 10^{-3}$
- weight decay: 0.05
- batch size: 2048
- drop path rate: ${0.1, 0.2, 0.3, 0.4}$에서 선택
- 사전 학습 방법: DINO, EsViT, CLIP, DeiT, MAE
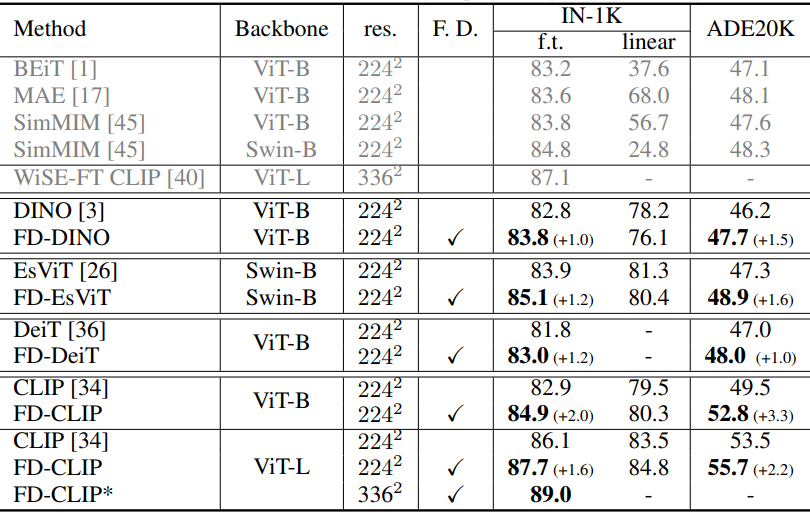
1. Main Results
다음은 feature distillation을 사용한 fine-tuning 결과이다. $\vphantom{1}^\ast$는 ImageNet-22K 이미지 분류에 대한 추가 fine-tuning 단계가 있다.
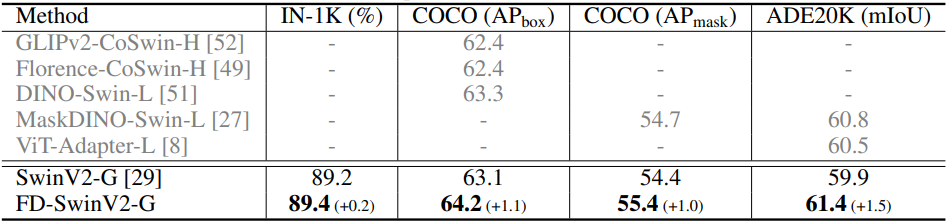
다음은 SwinV2-G 모델에 대한 feature distillation 결과이다.
2. Ablations
다음은 distillation 타겟에 대한 ablation 결과이다.
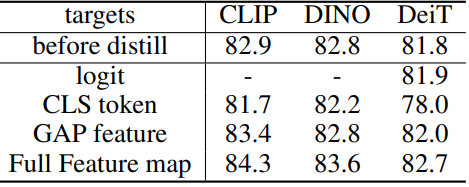
다음은 teacher feature 정규화 방법에 대한 ablation 결과이다.
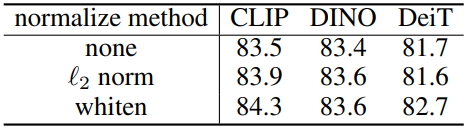
다음은 위치 인코딩에 대한 ablation 결과이다.
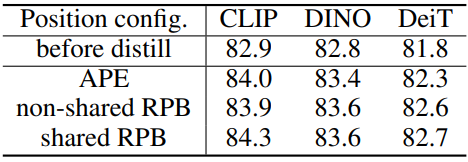
다음은 비대칭 drop path rate에 대한 ablation 결과이다.
