[논문리뷰] Feature 3DGS: Supercharging 3D Gaussian Splatting to Enable Distilled Feature Fields
CVPR 2024. [Paper] [Page] [Github]
Shijie Zhou, Haoran Chang, Sicheng Jiang, Zhiwen Fan, Zehao Zhu, Dejia Xu, Pradyumna Chari, Suya You, Zhangyang Wang, Achuta Kadambi
University of California | University of Texas at Austin | DEVCOM ARL
6 Dec 2023
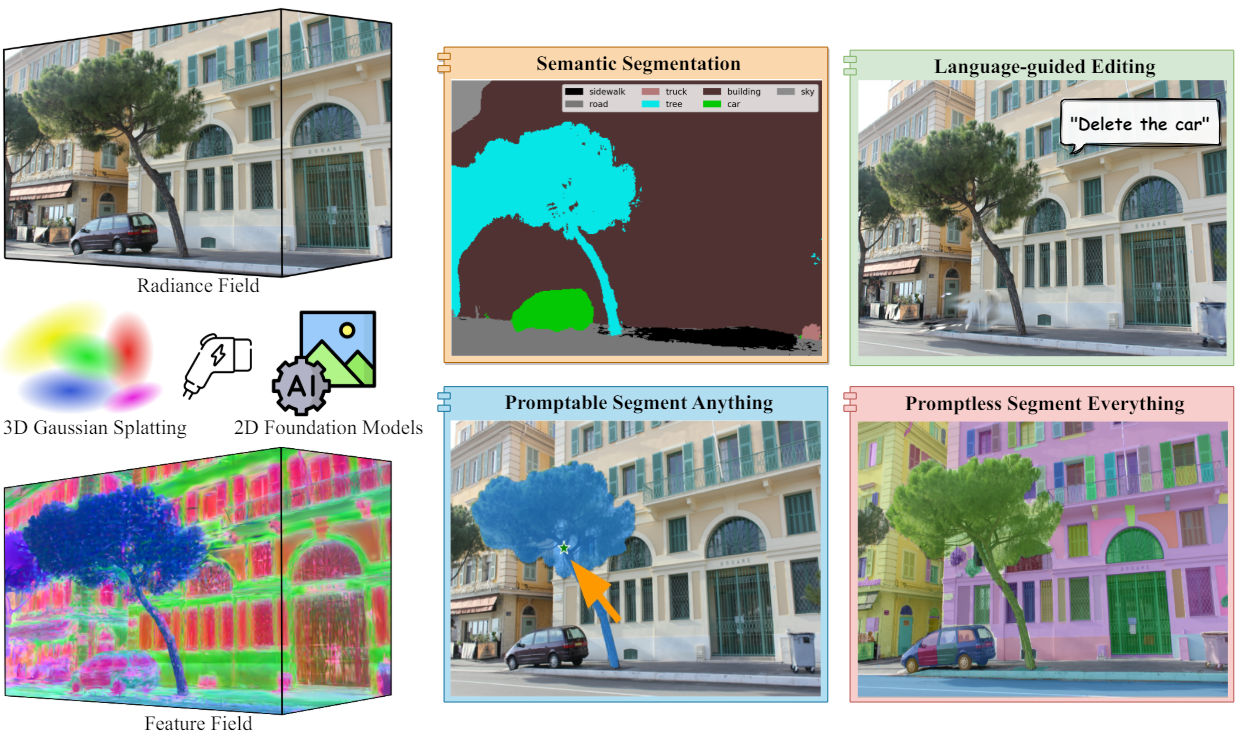
Introduction
NeRF는 렌더링 방정식을 사용하여 2D 이미지에서 supervise되는 3D field를 implicit하게 표현하도록 학습한다. 이러한 방법은 novel view synthesis에 큰 가능성을 보여주었다. 그러나 implicit function은 모든 3D 위치에 로컬한 radiance 정보를 저장하도록 설계되었기 때문에 3D field에 포함되는 정보는 다운스트림 애플리케이션의 관점에서 제한된다.
최근에는 NeRF 기반 방법에서 3D field를 사용하여 radiance 이외에 장면에 대한 추가 설명 feature를 저장하려고 시도했다. 이러한 feature들은 feature 이미지로 렌더링될 때 장면에 대한 추가 semantic 정보를 제공하여 편집, 분할 등과 같은 다운스트림 task에 사용할 수 있다. 그러나 이러한 방법을 통한 feature field distillation은 기본적으로 학습 및 inference 속도가 느리다는 단점이 있다. 이는 모델 용량 문제로 인해 더욱 복잡해진다.
NeRF의 대안으로 3D Gaussian Splatting (3DGS)이 제안되었다. 3D Gaussian을 사용하여 field가 명시적으로 표현되기 때문에 NeRF 기반 방법과 비교할 때 우수한 학습 속도와 렌더링 속도를 갖는 동시에 렌더링된 이미지의 품질과 비슷하거나 더 나은 품질을 유지한다. 그러나 3DGS 프레임워크는 기본적으로 각 Gaussian에서 semantic feature의 공동 학습을 지원하지 않는다.
본 논문에서는 3DGS 프레임워크를 기반으로 한 최초의 feature field distillation 기술인 Feature 3DGS를 제시하였다. 구체적으로, 색상 정보 외에도 각 3D Gaussian의 semantic feature를 학습할 것을 제안하였다. 그런 다음 feature 벡터를 미분 가능하게 splatting하고 rasterization함으로써 2D foundation model을 사용한 feature field의 추출이 가능하다. 각 Gaussian에서 학습된 feature의 차원이 증가함에 따라 학습 및 렌더링 속도가 급격히 떨어지기 때문에 빠르고 고품질의 feature field 추출하는 것은 간단한 일이 아니다. 따라서 본 논문은 rasterization 프로세스가 끝날 때 lightweight convolutional decoder를 사용하여 나중에 업샘플링되는 저차원 feature field를 학습할 것을 제안하였다. 이를 통해 semantic segmentation, 언어 기반 편집, promptable/promptless instance segmentation 등을 포함한 다양한 애플리케이션이 가능해진다.
Method
NeRF에서 3DGS로의 전환은 단순히 RGB 이미지와 feature map을 독립적으로 rasterization하는 것만큼 간단하지 않다. 일반적으로 feature map에는 RGB 이미지와 다른 고정된 크기가 있다. 타일 기반 rasterization 절차와 이미지와 feature map 간의 공유 속성으로 인해 이미지를 독립적으로 렌더링하는 것이 문제가 될 수 있다. 간단한 접근 방식은 이를 별도로 rasterization하는 2단계 학습 방법을 채택하는 것이다. 그러나 이 접근 방식은 RGB의 공유 속성과 semantic feature의 고차원 상관 관계를 고려할 때 RGB 이미지와 feature map 모두에 대해 좋지 못한 품질을 초래할 수 있다.
본 논문에서는 3D Gaussian이 radiance field와 feature field를 모두 명시적으로 표현할 수 있도록 하는 고차원 feature 렌더링 및 feature field distillation을 위한 새로운 파이프라인을 도입하였다. 병렬 $N$차원 Gaussian rasterizer와 속도 향상(speed-up) 모듈은 앞서 언급한 문제를 효과적으로 해결할 수 있으며 임의 차원의 semantic feature map을 렌더링할 수 있다. 본 논문의 방법의 개요는 위 그림에 나와 있다. 본 논문의 방법은 일반적이며 모든 2D foundation model과 호환돤다.
1. High-dimensional Semantic Feature Rendering
다양한 종류의 2D foundation model에 대처하기 위해 임의의 크기와 임의의 feature 차원의 2D feature map을 렌더링할 수 있어야 한다. 이를 위해 3DGS의 렌더링 파이프라인을 기반으로 사용한다. 3DGS와 동일하게 Structure from Motion을 사용하여 Gaussian을 초기화한다. 기존의 Gaussian 속성에 semantic feature $f \in \mathbb{R}^N$을 통합한다. 여기서 $N$은 feature의 latent 차원을 나타내는 임의의 숫자다. 따라서 $i$번째 3D Gaussian의 경우 최적화 가능한 속성은 \(\Theta_i = \{x_i, q_i, s_i, \alpha_i, c_i, f_i\}\)이다.
3DGS에서 각 픽셀의 색상을 알파 블렌딩하는 방법과 동일하게 feature map의 각 픽셀의 값 $F_s$를 계산한다.
\[\begin{equation} F_s = \sum_{i \in \mathcal{N}} f_i \alpha_i T_i, \quad T_i = \prod_{j=1}^{i-1} (1 - \alpha_j) \end{equation}\]여기서 $N$은 주어진 픽셀과 겹치는 정렬된 Gaussian 집합이고, $T_i$는 투과율이다. $F_s$의 아래 첨자 $s$는 “student”를 나타내며, 이는 렌더링된 feature가 “teacher” feature $F_t$에 의해 픽셀 단위로 supervise됨을 나타낸다. $F_t$는 2D foundation model의 인코더를 사용하여 ground truth 이미지를 인코딩하여 얻은 latent 임베딩이다. 본질적으로 미분 가능한 볼륨 렌더링을 통해 대규모 2D teacher model을 작은 3D student 명시적 장면 표현 모델로 추출한다고 볼 수 있다.
Rasterization 단계에서는 RGB 이미지와 feature map을 독립적으로 rasterization하는 것이 아니라 공동으로 최적화한다. 이미지와 feature map 모두 동일한 타일 기반 rasterization 절차를 사용한다. 여기서 화면은 16$\times$16 타일로 나뉘며 각 스레드는 하나의 픽셀을 처리한다. 그 후, 3D Gaussian은 view frustum과 각 타일 모두에 대해 선별된다. Feature map과 RGB 이미지는 모두 동일한 해상도로 rasterization되지만 차원은 다르다. 이 접근 방식을 사용하면 feature map의 충실도가 RGB 이미지의 충실도만큼 높게 렌더링되어 픽셀당 정확도가 유지된다.
2. Optimization and Speed-up
Loss function은 photometric loss와 feature loss의 결합이다.
\[\begin{aligned} \mathcal{L} &= \mathcal{L}_\textrm{rgb} + \gamma \mathcal{L}_f \\ \mathcal{L}_\textrm{rgb} &= (1 - \lambda) \mathcal{L}_1 (I, \hat{I}) + \lambda \mathcal{L}_\textrm{D-SSIM} (I, \hat{I}) \\ \mathcal{L}_f &= \| F_t (I) - F_s (\hat{I}) \|_1 \end{aligned}\]여기서 $F_t (I)$는 2D foundation model에서 얻은 ground truth 이미지 $I$에 대한 feature map이고, $F_s (\hat{I})$는 렌더링된 feature map이다. 픽셀당 \(\mathcal{L}_1\) loss 계산에 대해 동일한 해상도 $H \times W$를 보장하기 위해 bilinear interpolation을 적용하여 $F_s (\hat{I})$의 크기를 적절하게 조정한다. 실제로 $\gamma = 1.0$, $\lambda = 0.2$를 사용한다.
렌더링된 feature map $F_s (\hat{I}) \in \mathbb{R}^{H \times W \times N}$과 teacher feature map $F_t (I) \in \mathbb{R}^{H \times W \times M}$ 사이의 차이를 최소화하기 위해 이상적으로는 $N = M$으로 최소화한다. 그러나 2D foundation model의 높은 latent 차원으로 인해 (LSeg는 $M = 512$, SAM은 $M = 256$) 실제로 $M$은 매우 큰 수이므로 이러한 고차원 feature map을 직접 렌더링하는 데 많은 시간이 소요된다. 이 문제를 해결하기 위해 rasterization 프로세스 마지막에 속도 향상(speed up) 모듈을 도입한다. 이 모듈은 kernel size $1 \times 1$로 feature 채널을 업샘플링하는 lightweight convolution decoder로 구성된다. 결과적으로 임의의 $N \ll M$을 사용하여 $f \in \mathbb{R}^N$을 초기화하고 이 학습 가능한 디코더를 사용하여 feature 채널을 일치시키는 것이 가능하다. 이를 통해 다운스트림 task의 성능을 저하시키지 않으면서 최적화 프로세스의 속도를 크게 높일 수 있다.
Promptable Explicit Scene Representation
Foundation model은 다양한 task 및 애플리케이션에 적용할 수 있는 기본 지식 및 기술을 제공한다. 본 논문에서는 이러한 feature들의 실용적인 3D 표현을 가능하게 하기 위해 feature field distillation 접근 방식을 사용한다. 구체적으로 저자들은 SAM (Segment Anything Model)과 LSeg라는 두 가지 기본 모델을 고려하였다. SAM은 특정 task에 대한 학습 없이도 2D에서 promptable/promptless zero-shot segmentation이 가능하다. LSeg는 zero-shot semantic segmentation에 언어 기반 접근 방식을 도입하였다. LSeg는 DPT 아키텍처가 포함된 이미지 feature 인코더와 CLIP의 텍스트 인코더를 활용하여 텍스트-이미지 연결을 2D 픽셀 레벨로 확장하였다. 본 논문은 추출된 feature field를 사용하여 점, 상자, 텍스트에 의해 프롬프팅되는 모든 2D 기능을 3D 영역으로 확장하였다.
Promptable한 명시적 장면 표현은 다음과 같이 작동한다. 타겟 픽셀과 겹치는 $N$개의 정렬된 3D Gaussian 중 $x$에 대한 프롬프트 $\tau$의 activation score는 feature space의 쿼리 $q(\tau)$와 semantic feature $f(x)$ 사이의 코사인 유사도와 softmax로 계산된다.
\[\begin{aligned} s &= \frac{f(x) \cdot q(\tau)}{\| f(x) \| \| q(\tau) \|} \\ \mathbf{p} (\tau \vert x) &= \textrm{softmax} (s) = \frac{\exp (s)}{\sum_{s_j \in \mathcal{T}} \exp (s_j)} \end{aligned}\]Score가 낮은 Gaussian들을 필터링 하고 색상 $c(x)$와 불투명도 $\alpha (x)$를 업데이트하여 물체 추출, 물체 제거, 외형 변형 등 다양한 작업을 할 수 있다.
Experiments
1. Novel view semantic segmentation
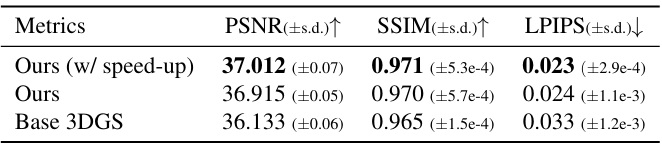
다음은 Replica 데이터셋에서의 렌더링 성능을 비교한 표이다.
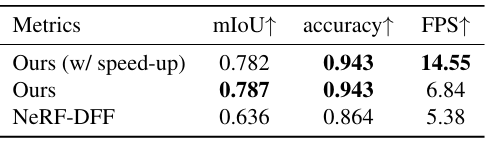
다음은 Replica 데이터셋에서의 semantic segmentation 성능을 비교한 표이다.
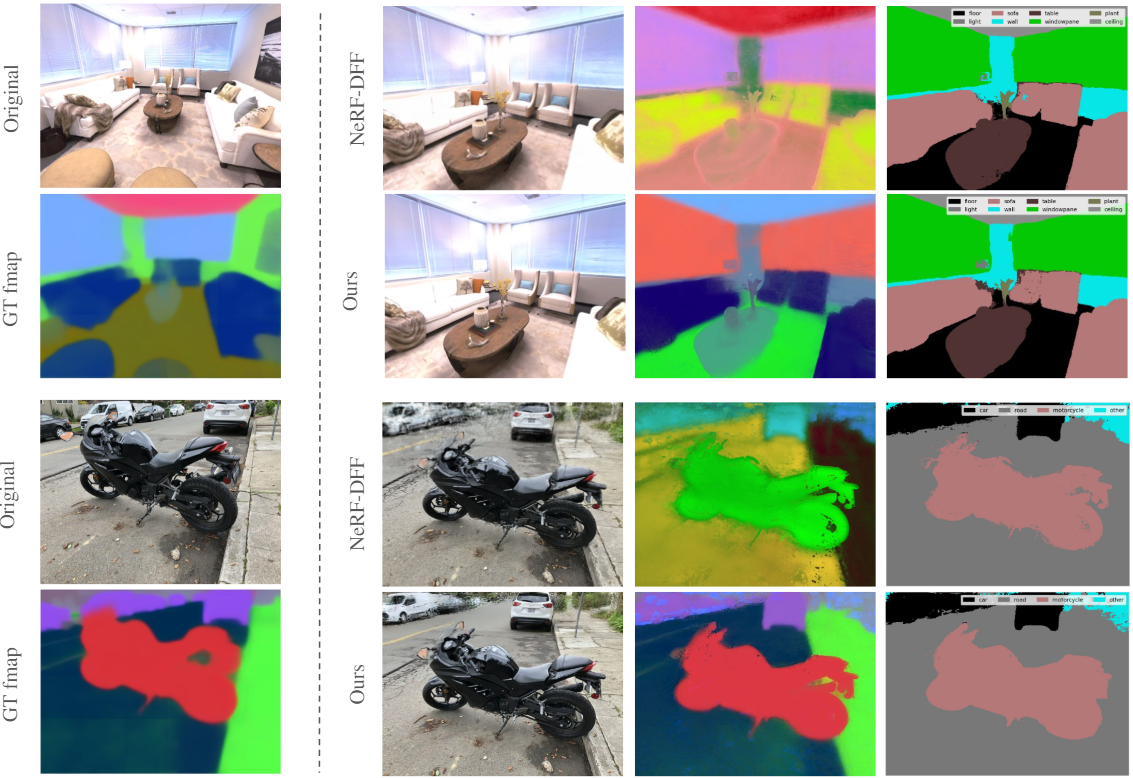
다음은 Replica 데이터셋과 LLFF 데이터셋에서 novel view semantic segmentation 결과를 비교한 것이다. (LSeg)
2. Segment Anything from Any View
다음은 (a) SAM 인코더-디코더 모듈을 novel view 렌더링 이미지에 적용한 결과와 (b) 렌더링된 feature를 직접 디코딩하여 얻은 SAM segmentation 결과를 비교한 것이다.
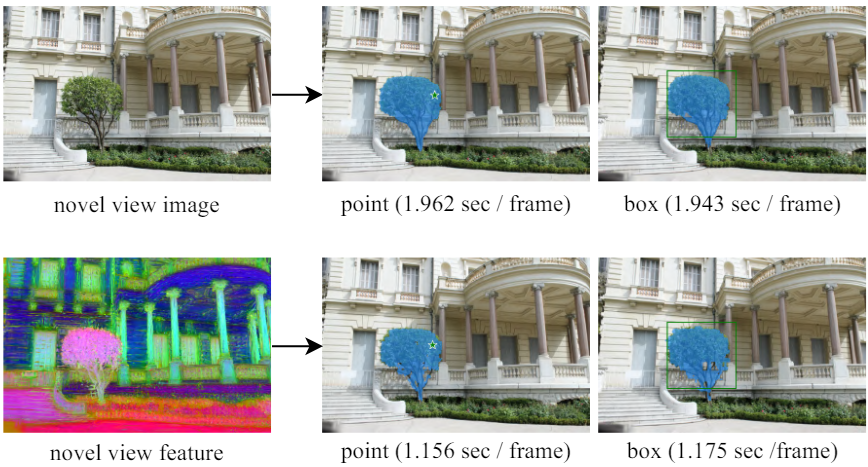
다음은 NeRF-DFF와 novel view segmentation 결과를 비교한 것이다. (SAM)

3. Language-guided Editing
다음은 NeRF-DFF와 언어 기반 편집 결과를 비교한 것이다.
