[논문리뷰] FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
ICLR 2021. [Paper] [Page]
Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu
Zhejiang University | Microsoft Research Asia | Microsoft Azure Speech
8 Jun 2020
Introduction
신경망 기반 TTS는 급속한 발전을 이루었고 최근 몇 년 동안 많은 관심을 끌었다. 이전의 신경망 기반 TTS 모델은 먼저 텍스트에서 autoregressive하게 mel-spectrogram을 생성한 다음 별도로 학습된 보코더를 사용하여 생성된 mel-spectrogram에서 음성을 합성하였다. 그들은 일반적으로 느린 inference 속도와 robustness (단어 건너뛰기 및 반복) 문제로 어려움을 겪었다. 최근 몇 년 동안 non-autoregressive TTS 모델은 이러한 문제를 해결하도록 설계되어 매우 빠른 속도로 mel-spectrogram을 생성하고 robustness 문제를 방지하는 동시에 이전 autoregressive model과 비슷한 음성 품질을 달성하였다.
이러한 non-autoregressive TTS 방법 중 FastSpeech는 가장 성공적인 모델 중 하나이다. FastSpeech는 일대다 매핑 문제를 완화하기 위한 두 가지 방법을 설계한다.
- Autoregressive teacher model에서 생성된 mel-spectrogram을 학습 타겟으로 사용하여 타겟 측의 데이터 분산을 줄인다 (즉, knowledge distillation)
- Mel-spectrogram 시퀀스의 길이와 일치하도록 텍스트 시퀀스를 확장하기 위해 duration 정보 (teacher 모델의 attention map에서 추출)를 도입한다.
FastSpeech의 이러한 설계는 TTS의 일대다 매핑 문제 학습을 용이하게 하지만 몇 가지 단점도 있다.
- 2단계 teacher-student 학습 파이프라인은 학습 프로세스를 복잡하게 만든다.
- 생성된 mel-spectrogram에서 합성된 오디오의 품질이 일반적으로 ground-truth보다 좋지 않기 때문에 teacher 모델에서 생성된 타겟 mel-spectrogram은 ground-truth에 비해 약간의 정보 손실이 있다.
- Teacher model의 attention map에서 추출한 duration이 정확하지 않다.
본 논문에서는 FastSpeech의 문제를 해결하고 non-autoregressive TTS에서 일대다 매핑 문제를 더 잘 처리하기 위해 FastSpeech 2를 제안하였다. 학습 파이프라인을 단순화하고 teacher-student distillation에서 데이터 단순화로 인한 정보 손실을 방지하기 위해 teacher의 단순화된 출력 대신 ground-truth 타겟으로 FastSpeech 2 모델을 직접 학습한다. 입력(텍스트 시퀀스)과 타겟 출력(mel-spectrograms) 사이의 정보 격차를 줄이고 (타겟을 예측하기 위한 모든 정보가 입력에 포함되어 있지 않음) non-autoregressive TTS 모델 학습에 대한 일대다 매핑 문제를 완화하기 위해, FastSpeech에 음조, energy, 보다 정확한 duration을 포함하여 음성의 일부 변형 정보를 도입한다.
학습 시에는 타겟 음성 파형에서 duration, pitch, energy를 추출하고 조건부 입력으로 직접 가져온다. Inference에서는 FastSpeech 2 모델과 함께 학습된 예측 변수에 의해 예측된 값을 사용한다. 음성의 운율에서 pitch가 중요하고 시간에 따른 큰 변동으로 인해 예측하기 어려운 점을 고려하여 continuous wavelet transform을 사용하여 pitch contour를 pitch spectrogram으로 변환하고 예측한다. 또한 예측 pitch의 정확도를 향상시킬 수 있는 주파수 도메인에서 pitch를 예측한다.
음성 합성 파이프라인을 더욱 단순화하기 위해 mel-spectrogram을 중간 출력으로 사용하지 않고 inference에서 텍스트로부터 음성 파형을 직접 생성하여 inference에서 낮은 대기 시간을 갖는 FastSpeech 2s를 도입한다. LJSpeech 데이터셋에 대한 실험 결과는 다음과 같다.
- FastSpeech 2가 FastSpeech보다 훨씬 간단한 학습 파이프라인 (학습 시간 3배 감소)을 가지면서 빠르고 강력하며 제어 가능한 (pitch 및 energy에서 훨씬 더 제어 가능한) 음성 합성의 장점을 계승한다는 것을 보여준다. FastSpeech 2s는 훨씬 더 빠른 inference 속도를 보여준다.
- FastSpeech 2와 FastSpeech 2s는 음성 품질에서 FastSpeech를 능가하며 FastSpeech 2는 autoregressive model을 능가할 수도 있다.
FastSpeech 2 and 2s
1. Motivation
TTS는 일반적인 일대다 매핑 문제이다. pitch, duration, 사운드 볼륨, 운율과 같은 음성의 변화로 인해 가능한 여러 음성 시퀀스가 텍스트 시퀀스에 해당할 수 있기 때문이다. Non-autoregressive TTS에서 유일한 입력 정보는 음성의 분산을 완전히 예측하기에 충분하지 않은 텍스트이다. 이 경우 모델은 학습 세트의 타겟 음성 변형에 overfitting되기 쉬워 일반화 능력이 저하된다. FastSpeech는 일대다 매핑 문제를 완화하기 위해 두 가지 방법을 설계하였지만 복잡한 학습 파이프라인, 타겟 mel-spectrogram의 정보 손실, 충분히 정확하지 않은 ground-truth duration 등 다양한 문제점을 가지고 있다.
2. Model Overview
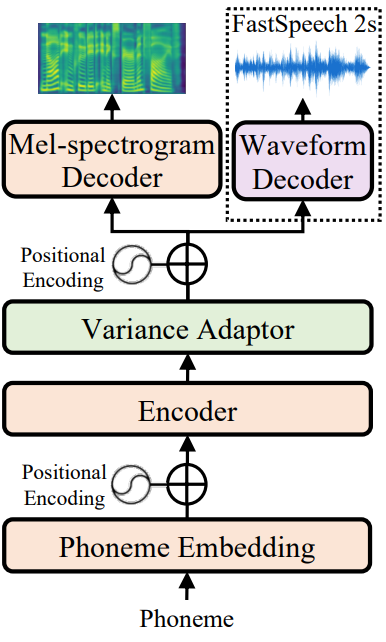
FastSpeech 2의 전체 모델 아키텍처는 위 그림에 나와 있다. 인코더가 음소 임베딩 시퀀스를 음소 hidden 시퀀스로 변환한 다음, variance adaptor가 duration, pitch, energy와 같은 다양한 분산 정보를 hidden 시퀀스에 추가하고, 마지막으로 mel-spectrogram 디코더는 적응된 hidden 시퀀스를 mel-스펙트로그램 시퀀스로 변환한다. 병행하여. 인코더와 mel-spectrogram 디코더의 기본 구조로 FastSpeech에서와 같이 self-attention layer와 1D-convolution의 스택인 feed-forward Transformer 블록을 사용한다.
Teacher-student distillation 파이프라인과 teacher model의 음소 길이에 의존하는 FastSpeech와 달리 FastSpeech 2는 몇 가지 개선 사항을 제공한다.
- Teacher-student distillation 파이프라인을 제거하고 모델 학습의 타겟으로 ground-truth mel-스펙트로그램을 직접 사용하여 distill된 mel-spectrogram의 정보 손실을 방지하고 음성 품질의 상한선을 높일 수 있다.
- 둘째, variance adaptor는 duration predictor뿐만 아니라 pitch 및 energy predictor로 구성된다. 여기서 duration predictor는 강제 정렬을 통해 얻은 음소 duration을 학습 타겟으로 사용하므로 autoregressive teacher의 attention map에서 추출한 것보다 더 정확하다. 추가 pitch 및 energy predictor는 더 많은 분산 정보를 제공할 수 있으며, 이는 TTS에서 일대다 매핑 문제를 완화하는 데 중요하다.
- 학습 파이프라인을 더욱 단순화하고 완전한 end-to-end 시스템으로 만들기 위해 계단식 mel-spectrogram 생성 (acoustic model)과 파형 생성(보코더) 없이 텍스트에서 직접 파형을 생성하는 FastSpeech 2s를 제안한다.
3. Variance Adaptor
Variance adaptor는 TTS의 일대다 매핑 문제에 대한 변형 음성을 예측할 수 있는 충분한 정보를 제공할 수 있는 음소 hidden 시퀀스에 분산 정보 (ex. duration, pitch, energy 등)를 추가하는 것을 목표로 한다. 분산 정보는 다음과 같다.
- 음소 duration: 음성이 얼마나 오래 들리는지를 나타낸다.
- pitch: 감정을 전달하는 핵심 feature로 운율에 큰 영향을 미친다
- energy: mel-스펙트로그램의 프레임 수준 크기를 나타내고 음성의 볼륨과 운율에 직접적인 영향을 미친다
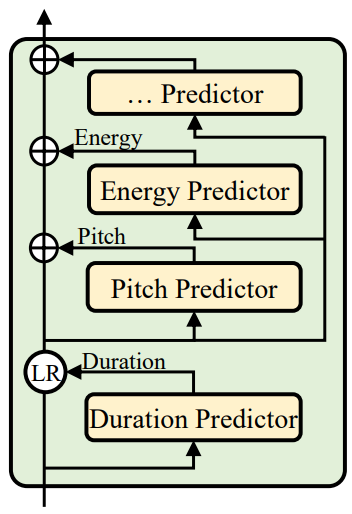
이에 따라 variance adaptor는 위 그림과 같이
- Duration predictor (FastSpeech에서 사용되는 length regulator)
- Pitch predictor
- Energy predictor
로 구성된다. 학습 시에는 타겟 음성을 예측하기 위해 hidden 시퀀스에 대한 입력으로 녹음에서 추출된 duration, pitch, energy의 ground-truth 값을 취한다. 동시에 타겟 음성을 합성하기 위한 inference에 사용되는 duration, pitch, energy predictor 예측자를 학습하기 위해 ground-truth duration, pitch, energy를 타겟으로 사용한다.
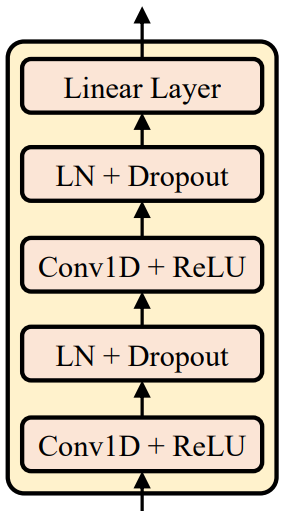
위 그림에서 볼 수 있듯이 duration, pitch, energy predictor는 유사한 모델 구조 (모델 파라미터는 다름)를 공유하며, 이는 ReLU가 포함된 2-layer 1D convolution network로 구성되며 각각 layer normalization과 dropout layer가 뒤따른다. 또한 hidden state를 출력 시퀀스에 project하는 추가 linear layer가 뒤따른다.
Duration Predictor
Duration predictor는 음소 hidden 시퀀스를 입력으로 사용하고 각 음소의 duration (이 음소에 해당하는 mel frame 수)을 예측하고 쉽게 예측할 수 있도록 로그 도메인으로 변환한다. Duration predictor는 평균 제곱 오차 (MSE) loss로 최적화되어 추출된 duration을 학습 타겟으로 삼는다. FastSpeech에서 사전 학습된 autoregressive TTS 모델을 사용하여 음소 길이를 추출하는 대신, 정렬 정확도를 개선하고 따라서 모델 입력과 출력 사이의 정보 격차를 줄인다.
Pitch Predictor
Pitch 예측 기능이 있는 이전의 신경망 기반 TTS 시스템은 종종 pitch contour 직접 예측하였다. 그러나 ground-pitch의 변동이 크기 때문에 예측된 pitch 값의 분포는 ground-truth 분포와 매우 다르다. Pitch contour의 변화를 더 잘 예측하기 위해 continuous wavelet transform (CWT)을 사용하여 일련의 연속적인 pitch를 pitch spectrogram으로 분해하고 pitch spectrogram을 MSE loss로 최적화된 pitch predictor의 학습 타겟으로 사용한다. Inference에서 pitch predictor는 inverse continuous wavelet transform (iCWT)를 사용하여 pitch contour로 다시 변환되는 pitch spectrogram을 예측한다. 학습과 inference 모두에서 pitch contour를 입력으로 사용하기 위해 각 프레임의 pitch $F_0$ (각각 학습/inference에 대한 ground-truth/예측값)을 로그 스케일에서 256개의 가능한 값으로 양자화하고 이를 pitch 임베딩 벡터 $p$로 추가 변환한 후 확장된 hidden 시퀀스에 더한다.
Energy Predictor
각 short-time Fourier transform (STFT) 프레임 진폭의 L2-norm을 에너지로 계산한다. 그런 다음 각 프레임의 에너지를 256개의 가능한 값으로 균일하게 양자화하고 enregy 임베딩 $e$로 인코딩하고 pitch와 유사하게 확장된 hidden 시퀀스에 추가한다. Energy predictor를 사용하여 양자화된 값 대신 enregy의 원래 값을 예측하고 MSE loss로 energy predictor를 최적화한다.
4. FastSpeech 2s
완전한 end-to-end text-to-waveform 생성을 가능하게 하기 위해 FastSpeech 2를 FastSpeech 2s로 확장한다. FastSpeech 2는 계단식 mel-spectrogram 생성 (acoustic model) 및 파형 생성 (보코더) 없이 텍스트에서 직접 파형을 생성한다. FastSpeech 2s는 중간 hidden에서 파형 컨디셔닝을 생성하여 mel-spectrogram 디코더를 버리고 계단식 시스템과 비슷한 성능을 달성함으로써 inference를 더 간결하게 만든다.
Challenges in Text-to-Waveform Generation
TTS 파이프라인을 완전한 end-to-end 프레임워크로 추진할 때 몇 가지 문제가 있다.
- 파형에는 mel-spectrogram보다 더 많은 분산 정보 (ex. 위상)가 포함되어 있으므로 입력과 출력 사이의 정보 격차가 text-to-spectrogram 생성보다 크다.
- 매우 긴 파형 샘플과 제한된 GPU 메모리로 인해 전체 텍스트 시퀀스에 해당하는 오디오 클립에서 학습하기 어렵다.
결과적으로 부분 텍스트 시퀀스에 해당하는 짧은 오디오 클립에 대해서만 학습할 수 있다. 이는 모델이 다양한 부분 텍스트 시퀀스에서 음소 간의 관계를 캡처하기 어렵게 만들며 따라서 텍스트 feature 추출에 해를 끼친다.
Our Method
위의 문제를 해결하기 위해 파형 디코더에서 여러 가지 설계를 한다.
- Variance predictor를 사용하여 위상 정보를 예측하기 어려운 점을 고려하여 파형 디코더에서 적대적 학습을 도입하여 자체적으로 위상 정보를 암시적으로 복구하도록 한다.
- FastSpeech 2의 mel-spectrogram 디코더를 활용한다. 이는 텍스트 feature 추출을 돕기 위해 전체 텍스트 시퀀스에 대해 학습된다.
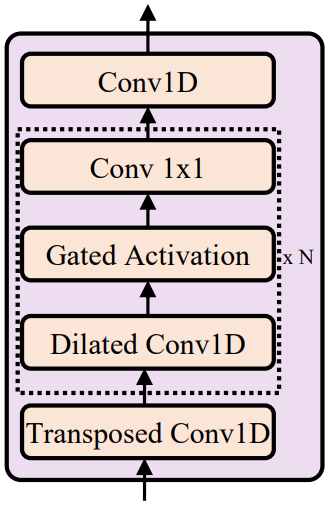
위 그림에서 볼 수 있듯이 파형 디코더는 non-causal convolution과 gated activation을 포함하는 WaveNet 구조를 기반으로 한다. 파형 디코더는 짧은 오디오 클립에 해당하는 슬라이스된 hidden 시퀀스를 입력으로 사용하고 오디오 클립의 길이와 일치하도록 transposed 1D-convolution으로 업샘플링한다. 적대적 학습의 discriminator는 Parallel WaveGAN에서 동일한 구조를 채택한다. 이 구조는 leaky ReLU가 있는 non-causal dilated 1-D convolution의 10개로 구성된다. 파형 디코더는 Parallel WaveGAN에 따른 다중 해상도 STFT loss와 LSGAN discriminator loss에 의해 최적화된다. Inference에서는 mel-spectrogram 디코더를 버리고 파형 디코더만 사용하여 음성 오디오를 합성한다.
Experiments
- 데이터셋: LJSpeech
1. Model Performance
다음은 오디오 품질을 비교한 표이다.
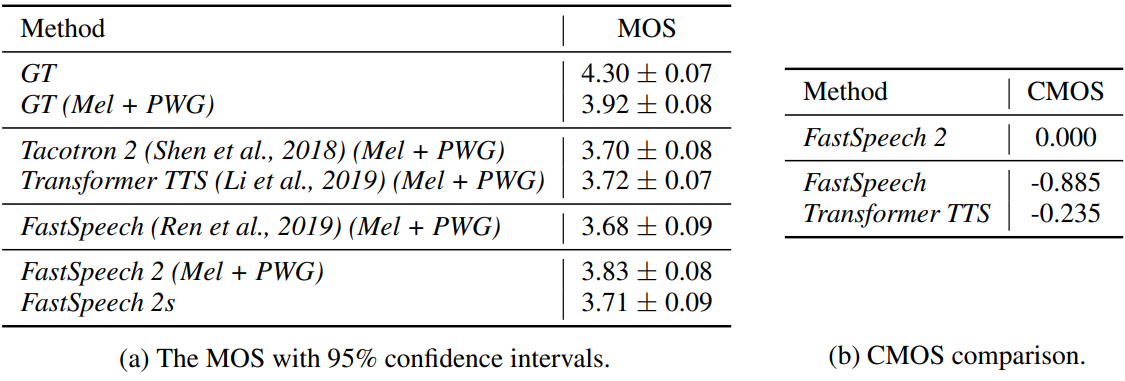
다음은 파형 합성에 대한 학습 시간과 inference 지연 시간을 비교한 표이다.

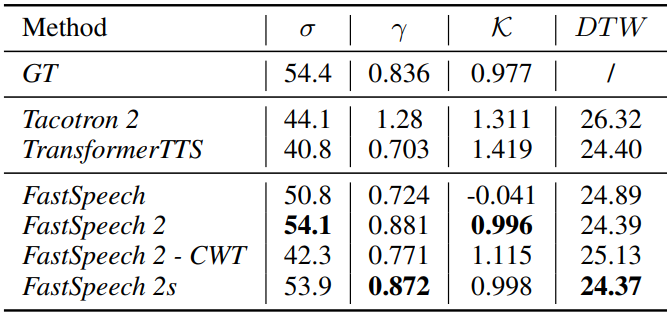
2. Analyses on Variance Information
다음은 pitch의 표준 편차 ($\sigma$), skewness ($\gamma$), kurtosis ($\mathcal{K}$), 평균 DTW 거리 (DTW)를 비교한 표이다.
다음은 합성된 음성 오디오의 에너지의 평균 절대 오차(MAE)이다.

다음은 teacher model과 MFA의 duration을 비교한 표이다.

3. Ablation Study
다음은 ablation study 결과이다.
