[논문리뷰] Fast Segment Anything (FastSAM)
arXiv 2023. [Paper] [Github]
Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu, Min Li, Ming Tang, Jinqiao Wang
University of Chinese Academy of Sciences | Objecteye Inc. | Wuhan AI Research
21 Jun 2023
Introduction
최근에 Segment Anything Model (SAM)이 제안되었으며, 다양한 사용자 상호 작용 프롬프트에 따라 이미지 내의 모든 개체를 분할할 수 있다. SAM은 광범위한 SA-1B 데이터셋에서 학습된 Transformer 모델을 활용하여 광범위한 장면과 개체를 능숙하게 처리할 수 있는 기능을 제공한다. SAM은 Segment Anything이라는 흥미로운 새 task의 문을 열었다. 이 task는 일반화 가능성과 잠재력으로 인해 광범위한 미래 비전 task의 초석이 될 수 있다.
그러나 이러한 발전과 SAM 및 후속 모델이 segment anything task를 처리하는 데 있어 유망한 결과에도 불구하고 실제 적용은 여전히 어렵다. 눈에 띄는 문제는 SAM 아키텍처의 주요 부분인 Transformer (ViT) 모델과 관련된 상당한 컴퓨팅 리소스 요구 사항이다. Convolution을 사용하는 모델과 비교할 때 ViT는 특히 실시간 애플리케이션에서 실제 배포에 장애물을 제공하는 과도한 계산 리소스 요구로 두드러진다. 이 제한은 결과적으로 segment anything task의 진행과 잠재력을 방해한다.
본 논문에서는 segment anything task를 위한 실시간 솔루션인 FastSAM을 디자인한다. Segment anything task를 all-instance segmentation과 prompt-guided selection이라는 두 개의 순차적 단계로 분리한다. 첫 번째 단계는 CNN 기반 detector의 구현에 달려 있다. 이미지의 모든 인스턴스에 대한 분할 마스크를 생성한다. 그런 다음 두 번째 단계에서 프롬프트에 해당하는 관심 영역을 출력한다. CNN의 계산 효율성을 활용하여 성능 품질을 크게 손상시키지 않고 모든 모델의 실시간 분할을 달성할 수 있다.
본 논문이 제안하는 FastSAM은 YOLACT를 활용하는 instance segmentation 분기가 장착된 object detector인 YOLOv8-seg를 기반으로 한다. 또한 SAM에서 게시한 광범위한 SA-1B 데이터셋을 채택한다. SA-1B 데이터셋의 2%에서만 이 CNN detector를 직접 학습함으로써 SAM과 비슷한 성능을 달성하지만 계산 및 리소스 요구가 크게 감소하여 실시간 적용이 가능하다.
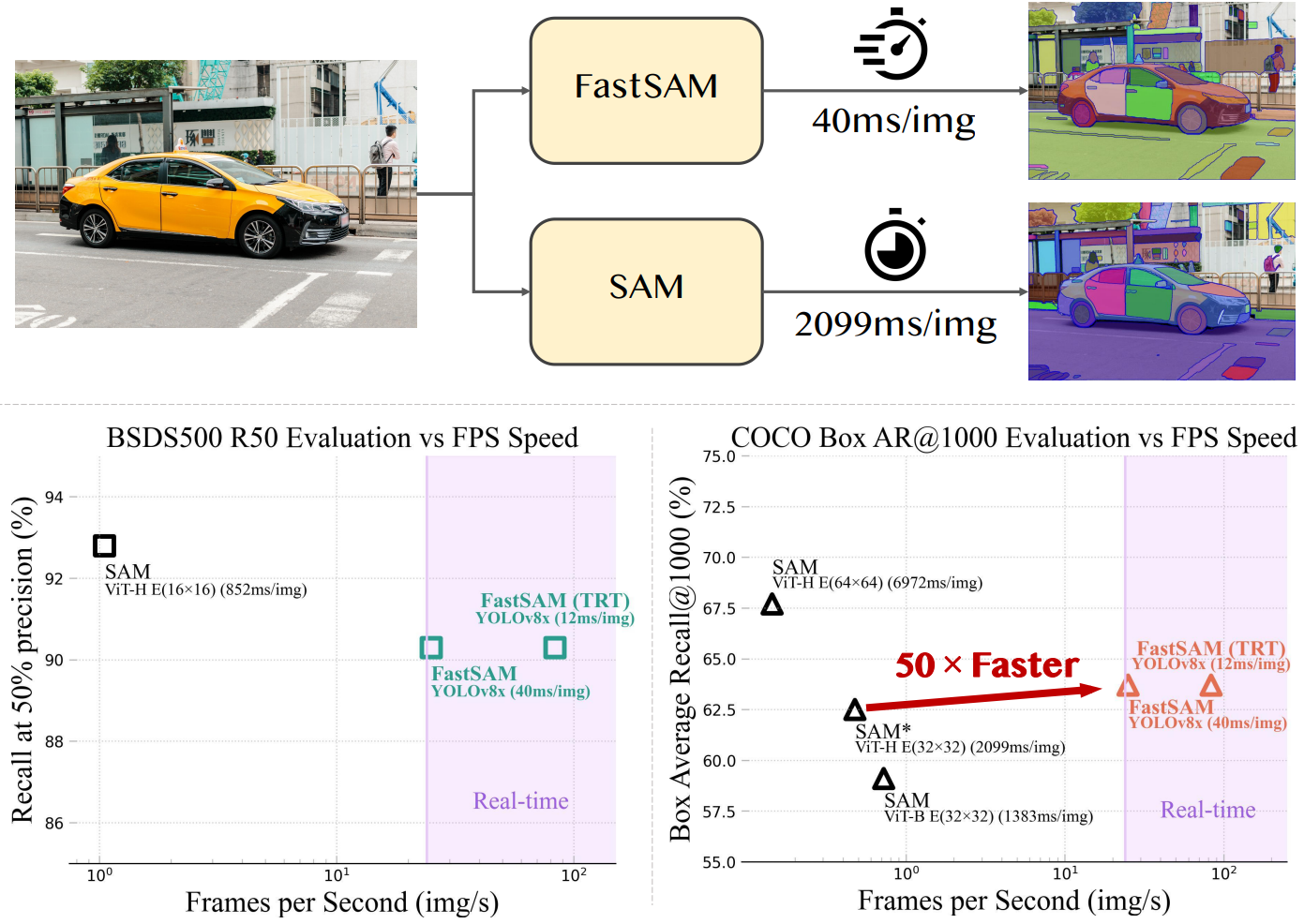
실시간 segment anything 모델은 산업용 애플리케이션에 유용하며 많은 시나리오에 적용할 수 있다. 제안된 접근 방식은 수많은 비전 task를 위한 새롭고 실용적인 솔루션을 제공할 뿐만 아니라 현재 방법보다 수십 또는 수백 배 더 빠른 속도로 수행한다.
또한 일반적인 비전 task를 위한 대형 모델 아키텍처에 대한 새로운 시점을 제공한다. 특정 task의 경우 특정 모델이 여전히 이점을 활용하여 더 나은 효율성과 정확도를 절충한다. 그런 다음 모델 압축의 의미에서 본 논문의 접근 방식은 구조에 인공적인 prior를 도입하여 계산 노력을 크게 줄일 수 있는 경로의 실현 가능성을 보여준다.
Methodology
1. Overview
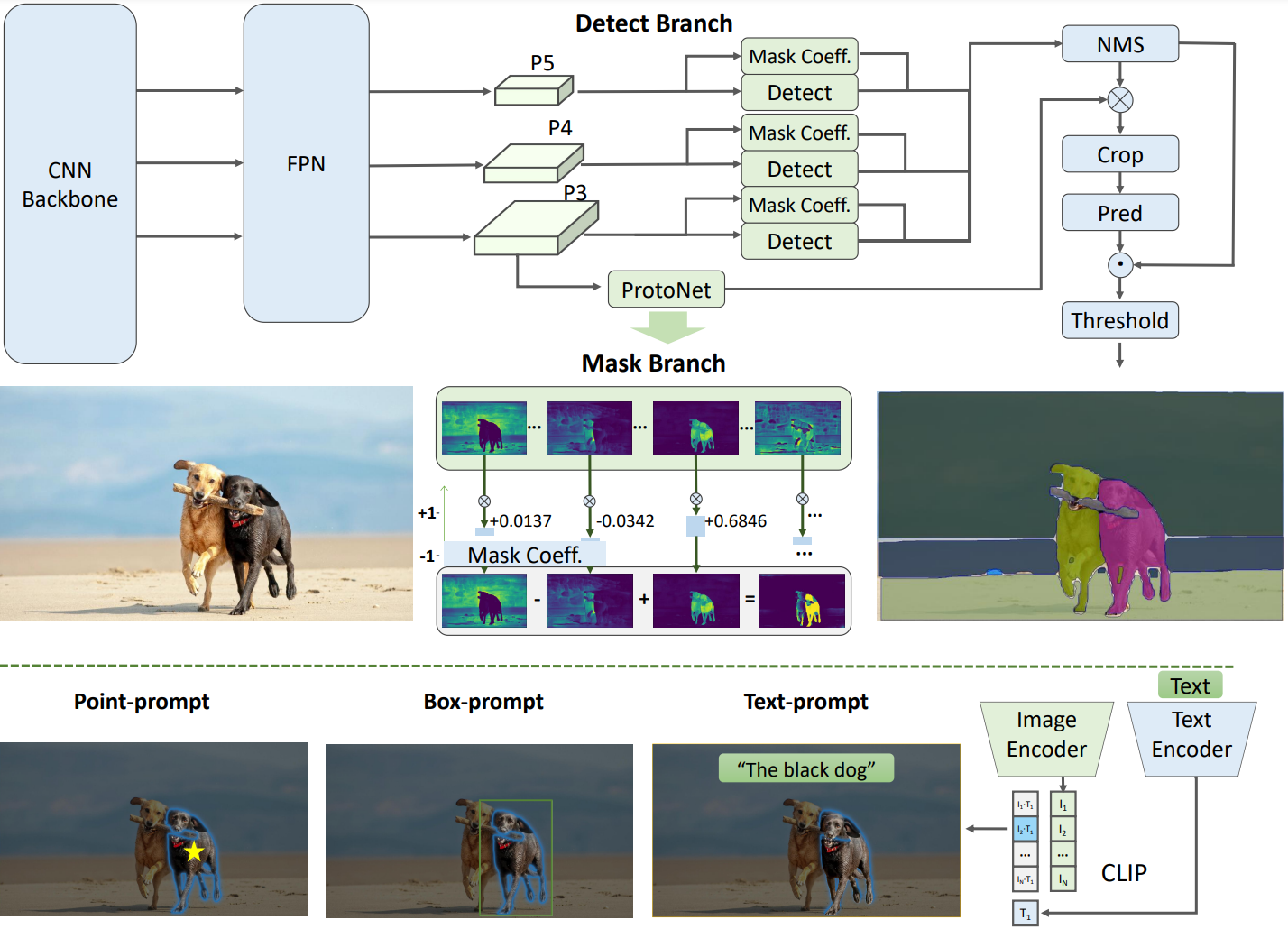
그림 2는 제안하는 방법인 FastSAM의 개요를 보여준다. 이 방법은 All-instance Segmentation과 Prompt-guided Selection의 두 단계로 구성된다. 앞의 단계는 기본이고 두 번째 단계는 본질적으로 task 중심의 후처리이다. End-to-end Transformer와 달리 전체 방법은 convolution의 로컬 연결과 receptive field 관련 개체 할당 전략과 같은 vision segmentation task와 일치하는 많은 인간 prior를 도입한다. 이를 통해 vision segmentation task에 맞게 조정되고 더 적은 수의 파라미터에서 더 빠르게 수렴할 수 있다.
2. All-instance Segmentation
Model Architecture
YOLOv8의 아키텍처는 이전 버전인 YOLOv5에서 개발되어 YOLOX, YOLOv6, YOLOv7과 같은 최신 알고리즘의 주요 디자인을 통합한다. YOLOv8의 backbone 네트워크와 neck 모듈은 YOLOv5의 C3 모듈을 C2f 모듈로 대체한다. 업데이트된 헤드 모듈은 분리된 구조를 수용하여 classification 헤드와 detection 헤드를 분리하고 Anchor-Based에서 Anchor-Free로 전환한다.
Instance Segmentation
YOLOv8-seg는 instance segmentation을 위해 YOLACT 규칙을 적용한다. Backbone 네트워크와 다양한 크기의 feature를 통합하는 Feature Pyramid Network (FPN)를 통해 이미지에서 feature 추출로 시작한다. 출력은 detection 분기와 segmentation 분기로 구성된다.
Detection 분기는 카테고리와 boundary box를 출력하는 반면 segmentation 분기는 $k$개의 마스크 계수와 함께 $k$개의 프로토타입 (FastSAM에서 32로 기본 설정됨)을 출력한다. Segmentation task와 detection task는 병렬로 계산된다. Segmentation 분기는 고해상도 feature map을 입력하고 공간 디테일을 보존하며 semantic 정보도 포함한다. 이 map은 convolution layer를 통해 처리되고 업스케일링된 다음 두 개의 convolution layer를 더 거쳐 마스크를 출력한다. Detection 헤드의 classification 분기와 유사한 마스크 계수의 범위는 -1에서 1 사이이다. Instance segmentation 결과는 마스크 계수를 프로토타입과 곱한 다음 합산하여 얻는다.
YOLOv8은 다양한 object detection task에 사용할 수 있다. Instance segmentation 분기를 통해 YOLOv8-Seg는 객체 카테고리에 관계없이 이미지의 모든 객체 또는 영역을 정확하게 감지하고 분할하는 것을 목표로 하는 segmentation anything task에 적합하다. 프로토타입과 마스크 계수는 prompt guidance를 위해 많은 확장성을 제공한다. 간단한 예로 다양한 프롬프트와 이미지 feature 임베딩을 입력으로, 마스크 계수를 출력으로 사용하여 간단한 프롬프트 인코더 및 디코더 구조가 추가로 학습된다. FastSAM에서는 all-instance segmentation 단계에 YOLOv8-seg 방법을 직접 사용한다.
3. Prompt-guided Selection
YOLOv8을 사용하여 이미지의 모든 객체 또는 영역을 성공적으로 분할한 후 segment anything task의 두 번째 단계는 다양한 프롬프트를 사용하여 관심 있는 특정 객체를 식별하는 것이다. 주로 포인트 프롬프트, 박스 프롬프트, 텍스트 프롬프트를 활용한다.
Point prompt
포인트 프롬프트는 선택한 포인트를 첫 번째 단계에서 얻은 다양한 마스크와 일치시키는 것으로 구성된다. 포인트가 위치한 마스크를 결정하는 것이 목표이다. SAM과 유사하게 전경/배경 지점을 프롬프트로 사용한다. 전경점이 여러 마스크에 있는 경우 배경점을 활용하여 task와 관련 없는 마스크를 걸러낼 수 있다. 전경/배경 점 집합을 사용하여 관심 영역 내에서 여러 마스크를 선택할 수 있다. 이러한 마스크는 관심 대상을 완전히 표시하기 위해 단일 마스크로 병합된다. 또한 마스크 병합 성능을 개선하기 위해 형태학적 연산을 활용한다.
Box prompt
박스 프롬프트에는 선택한 박스와 첫 번째 단계의 다양한 마스크에 해당하는 boundary box 간에 IoU 일치를 수행하는 작업이 포함된다. 선택한 박스로 IoU 점수가 가장 높은 마스크를 식별하여 관심 개체를 선택하는 것이 목표이다.
Text prompt
텍스트 프롬프트의 경우 CLIP 모델을 사용하여 텍스트의 해당 텍스트 임베딩을 추출한다. 그런 다음 각각의 이미지 임베딩이 결정되고 유사성 메트릭을 사용하여 각 마스크의 고유 feature와 일치한다. 그러면 텍스트 프롬프트의 이미지 임베딩에 대한 유사성 점수가 가장 높은 마스크가 선택된다.
이러한 prompt-guided selection 기술을 신중하게 구현함으로써 FastSAM은 분할된 이미지에서 관심 있는 특정 개체를 안정적으로 선택할 수 있다. 위의 접근 방식은 실시간으로 segmentation task를 수행하는 효율적인 방법을 제공하므로 복잡한 image segmentation task에 대한 YOLOv8 모델의 유용성을 크게 향상시킨다.
Experiments
- 구현 디테일
- 입력 크기가 1024인 YOLOv8-x 모델을 아키텍처의 주요 부분으로 사용
- SA-1B 데이터셋의 2%에서 학습을 수행
- 큰 인스턴스를 예측하기 위해 boundary box 회귀 모듈의 reg 최대값이 16에서 26으로 변경된다는 점을 제외하고는 기본 hyperparameter를 사용
- 100 epoch 동안 모델을 학습
1. Run-time Efficiency Evaluation
다음은 FastSAM의 segmentation 결과이다.

다음은 다양한 포인트 프롬프트 수에 따른 SAM과 FastSAM의 속도 (ms/이미지)를 측정한 표이다. E는 SAM의 Everything 모드이다.

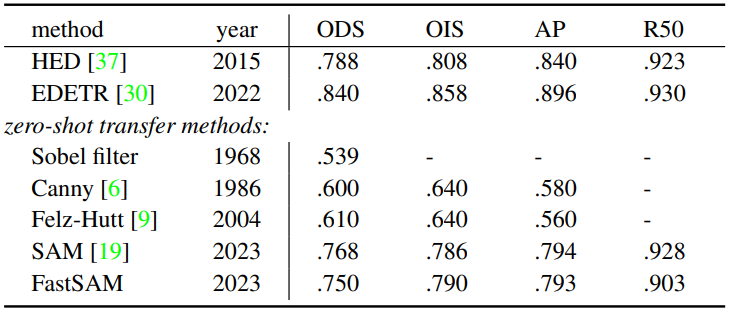
2. Zero-Shot Edge Detection
다음은 BSDS500 데이터셋에서의 zero-shot edge 예측 결과이다.

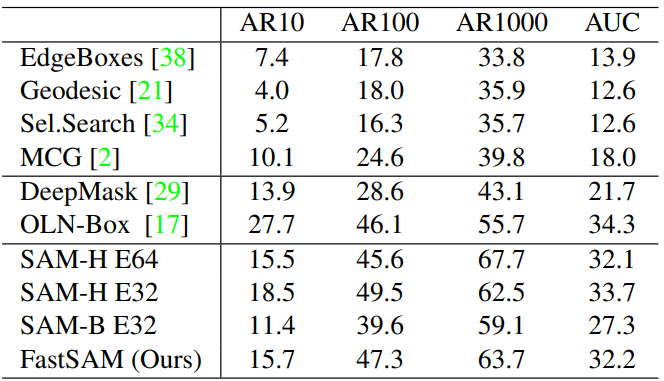
3. Zero-Shot Object Proposal Generation
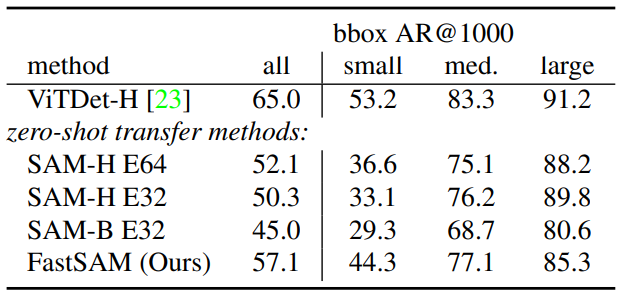
다음은 COCO의 모든 카테고리에 대하여 다양한 방법들과 비교한 표이다. (AR: 평균 recall)
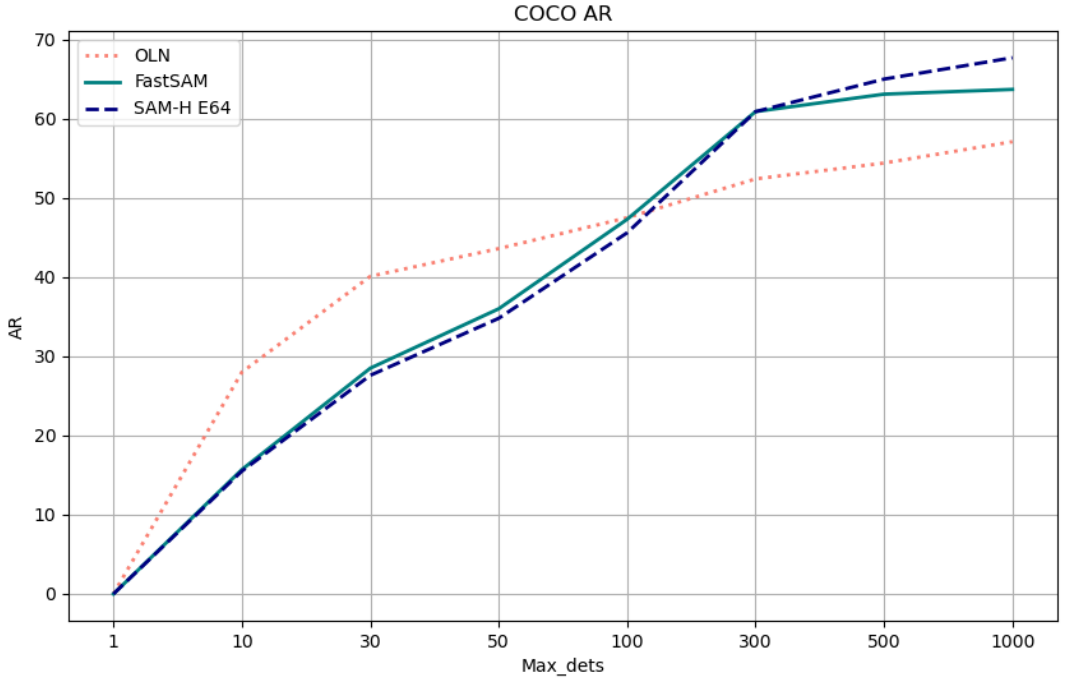
다음은 80개의 COCO 클래스에 대하여 OLN, SAM-H과 FastSAM을 비교한 그래프이다.
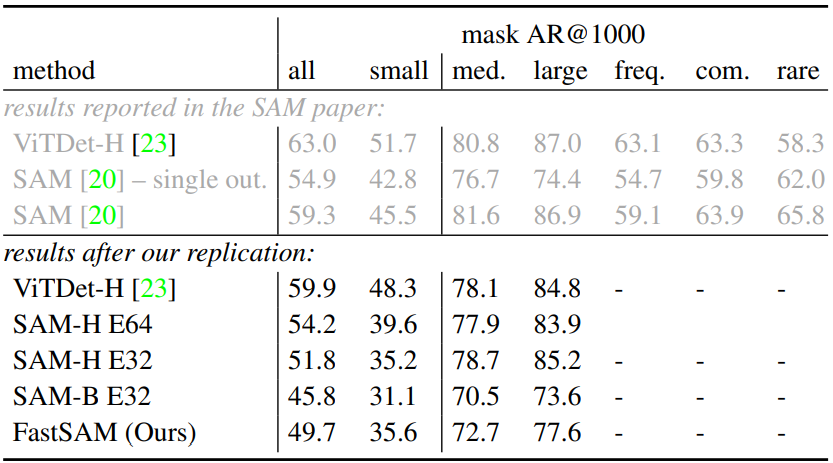
다음은 LVIS v1 데이터셋에서 object proposal generation을 비교한 표이다.
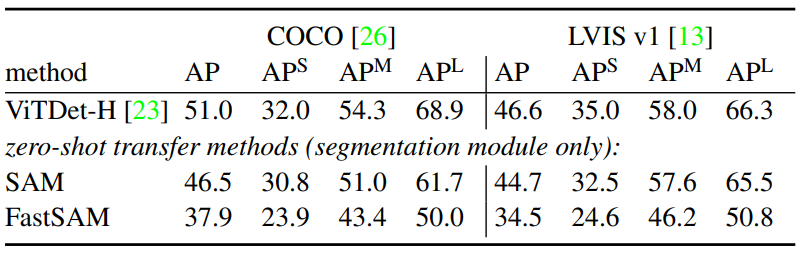
4. Zero-Shot Instance Segmentation
다음은 instance segmentation 결과이다.
5. Zero-Shot Object Localization with Text Prompts
다음은 텍스트 프롬프트를 사용한 segmentation 결과이다.

Real-world Applications
Anomaly Detection

Salient Object Segmentation

Building Extracting

Discussion
일반적으로 FastSAM은 SAM과 비슷한 성능을 달성하고 SAM (32$\times$32)보다 50배 더 빠르고 SAM (64$\times$64)보다 170배 더 빠르게 실행된다. 이 실행 속도는 도로 장애물 감지, 동영상 인스턴스 추적, 이미지 조작과 같은 산업용 애플리케이션에 적합하다. 일부 이미지에서 FastSAM은 아래 그림과 같이 큰 물체에 대해 더 나은 마스크를 생성하기도 한다.

Weakness

FastSAM의 마스크 생성 성능은 SAM보다 낮다. 위 그림에서 이러한 예시를 시각화한다. FastSAM에는 다음과 같은 특징이 있음을 알 수 있다.
- 저품질 소형 분할 마스크는 높은 신뢰도 점수를 가진다. 이는 신뢰도 점수가 YOLOv8의 bbox 점수로 정의되기 때문에 마스크 품질과 크게 관련이 없기 때문이다. 마스크 IoU 또는 기타 품질 지표를 예측하도록 네트워크를 수정하는 것이 이를 개선하는 방법이다.
- 작은 크기의 물체 중 일부의 마스크는 정사각형에 가까운 경향이 있다. 게다가 큰 물체의 마스크는 boundary box의 경계에 약간의 아티팩트가 있을 수 있다. 이것은 YOLACT의 약점이다. 마스크 프로토타입의 용량을 높이거나 마스크 generator를 재구성하면 문제가 해결될 것으로 예상된다.
또한 전체 SA-1B 데이터셋의 2%만 사용하므로 더 많은 학습 데이터를 활용하여 모델의 성능을 더욱 향상시킬 수 있다.