[논문리뷰] FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis
IJCAI 2022. [Paper] [Page]
Rongjie Huang, Max W. Y. Lam, Jun Wang, Dan Su, Dong Yu, Yi Ren, Zhou Zhao
Zhejiang University | Tencent AI Lab
21 Apr 2022
Introduction
최근 심층 생성 모델이 개발되면서 음성 합성이 놀라운 발전을 보였다. 기존의 음성 합성 방법 중 WaveNet은 autoregressive 방식으로 고충실도 오디오 샘플을 생성하지만 엄청나게 비싼 계산 비용으로 어려움을 겪는다. 반면 만족스러운 속도로 음성 오디오를 생성하기 위해 flow 기반 모델과 GAN 기반 모델과 같은 non-autoregressive 접근법도 제안되었다. 그러나 이러한 모델은 제한된 샘플 품질 또는 샘플 다양성과 같은 다른 문제에 대해 여전히 비판을 받았다. 음성 합성에서 본 논문의 목표는 주로 두 가지이다.
- 고품질: 고품질 음성을 생성하는 것은 특히 오디오의 샘플링 속도가 높을 때 어려운 문제이다. 매우 가변적인 패턴의 파형에 대해 서로 다른 시간 스케일에서 디테일을 재구성하는 것이 중요하다.
- 빠름: 실시간 음성 합성을 고려할 때 높은 생성 속도가 필수적이다. 이것은 모든 고품질 합성 모델에 대한 도전 과제이다.
DDPM은 이미지와 오디오 합성 모두에서 최고의 성능을 달성할 수 있는 능력을 입증하였다. 그러나 현재 음성 합성에서 DDPM의 개발은 두 가지 주요 문제로 인해 방해를 받았다.
- 기존의 다른 생성 모델과 달리 diffusion model은 생성된 오디오와 레퍼런스 오디오의 차이를 직접적으로 최소화하도록 학습되지 않고 최적의 기울기가 주어진 noisy한 샘플을 denoise한다. 이것은 실제로 호흡 등을 포함한 자연스러운 음성 특성이 제거되는 많은 샘플링 단계 후에 지나치게 denoise된 음성으로 이어질 수 있다.
- DDPM은 본질적으로 기울기 기반 모델이지만 높은 샘플 품질을 보장하려면 일반적으로 수백에서 수천 step의 denoising step을 거쳐야 한다. 샘플링 step을 줄이면 인지할 수 있는 배경 잡음으로 인해 품질이 명백히 저하된다.
본 논문에서는 고품질 음성 합성을 위한 빠른 조건부 diffusion model인 FastDiff를 제안한다. 오디오 품질을 개선하기 위해 FastDiff는 다양한 receptive field 패턴의 time-aware location-variable convolution 스택을 채택하여 적응적 조건으로 장기 시간 의존성을 효율적으로 모델링한다. Inference 절차를 가속화하기 위해 FastDiff에는 noise schedule predictor도 포함되어 있어 짧고 효과적인 noise schedule을 도출하고 denoising step을 크게 줄인다. 또한 저자들은 FastDiff를 기반으로 하는 end-to-end phoneme-to-waveform 합성 모델인 FastDiff-TTS를 소개한다. 이는 TTS 생성 파이프라인을 단순화하고 짧은 inference 대기 시간을 위해 중간 feature나 특수한 loss function이 필요하지 않다.
FastDiff는 공개적으로 사용 가능한 최고의 모델보다 더 높은 MOS 점수를 달성했으며 강력한 WaveNet 보코더를 능가하는 것으로 나타났다. FastDiff는 효과적인 샘플링 프로세스를 제공하며 엔지니어링 커널 없이 V100 GPU에서 실시간보다 58배 더 빠른 고충실도 음성을 합성하는 데 4번의 iteration만 필요하다. FastDiff는 낮은 계산 비용으로 인터랙티브한 실제 음성 합성 애플리케이션에 처음으로 적용할 수 있으며 이전과 비슷한 샘플링 속도를 가지는 최초의 diffusion model이다. FastDiff-TTS는 TTS 생성 파이프라인을 성공적으로 단순화하고 경쟁 아키텍처를 능가한다.
FastDiff
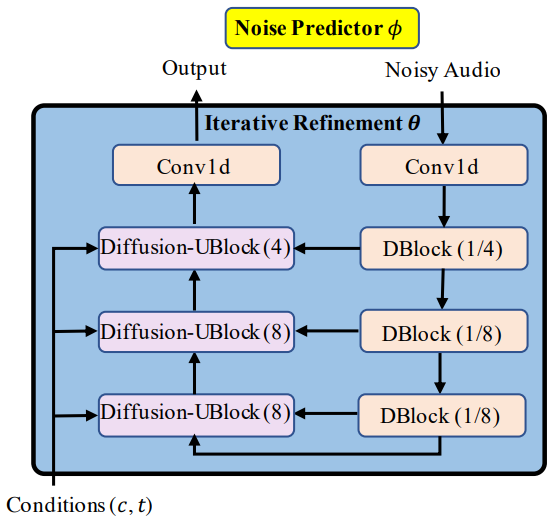
1. Motivation
DDPM은 고품질 음성 샘플을 합성하는 데 높은 잠재력을 보였지만 몇 가지 과제가 남아 있다.
- 기존의 생성 모델과 달리 diffusion model은 깨끗한 오디오 대신 잡음이 많은 오디오에서 동적 의존성을 포착하여 spectrogram 변동에 더해 더 많은 변형 정보 (즉, noise level)를 가져온다.
- 제한된 receptive field 패턴으로 reverse iteration을 줄일 때 뚜렷한 성능 저하가 나타날 수 있어 diffusion model을 가속화하기 어렵게 만든다. 결과적으로 수백 또는 수천 개의 iteration이 필요하다.
FastDiff에서는 위의 문제를 보완하기 위해 두 가지 주요 구성 요소를 제안한다.
- FastDiff는 동적 의존성에서 noisy한 샘플의 디테일을 포착하기 위해 time-aware location-variable convolution을 채택한다. Convolution 연산은 diffusion step과 spectrogram 변동을 포함하여 음성의 동적 변화으로 컨디셔닝되며 모델에 다양한 receptive field 패턴을 제공하고 diffusion model의 robustness를 촉진한다.
- Inference 절차를 가속화하기 위해 FastDiff는 noise schedule predictor를 채택하여 reverse iteration 횟수를 줄이고 수백 또는 수천 번의 iteration에서 diffusion model을 해방시킨다. 이로 인해 FastDiff는 처음으로 낮은 계산 비용으로 인터랙티브한 실제 애플리케이션에 적용할 수 있다.
2. Time-Aware Location-Variable Convolution
기존 convolution network와 비교하여 location-variable convolution은 오디오의 장기 의존성을 모델링하는 데 효율성을 보여주고 상당한 수의 dilated convolution layer에서 자유로운 신경망을 얻는다. 이에 영감을 받아 diffusion model에서 timestep에 민감한 Time-Aware Location-Variable Convolution을 도입한다. Timestep $t$에서 step 인덱스를 128차원 위치 인코딩 (PE) 벡터 $e_t$에 삽입하기 위해 Attention Is All You Need 논문을 따른다.
\[\begin{aligned} e_t = \bigg[ & \sin \bigg( 10^{\frac{0 \times 4}{63}} t \bigg), \cdots, \sin \bigg( 10^{\frac{64 \times 4}{63}} t \bigg), \\ & \cos \bigg( 10^{\frac{0 \times 4}{63}} t \bigg), \cdots, \cos \bigg( 10^{\frac{64 \times 4}{63}} t \bigg) \bigg] \end{aligned}\]Time-aware location-variable convolution에서 FastDiff는 입력 시퀀스의 관련 간격들에서 convolution 연산을 수행하기 위해 예측된 변동에 민감한 여러 커널이 필요하다. 이러한 커널은 diffusion step과 acoustic feature (즉, mel-spectrogram)을 포함하여 noisy한 오디오의 변화에 대해 시간을 인식하고 민감해야 한다.
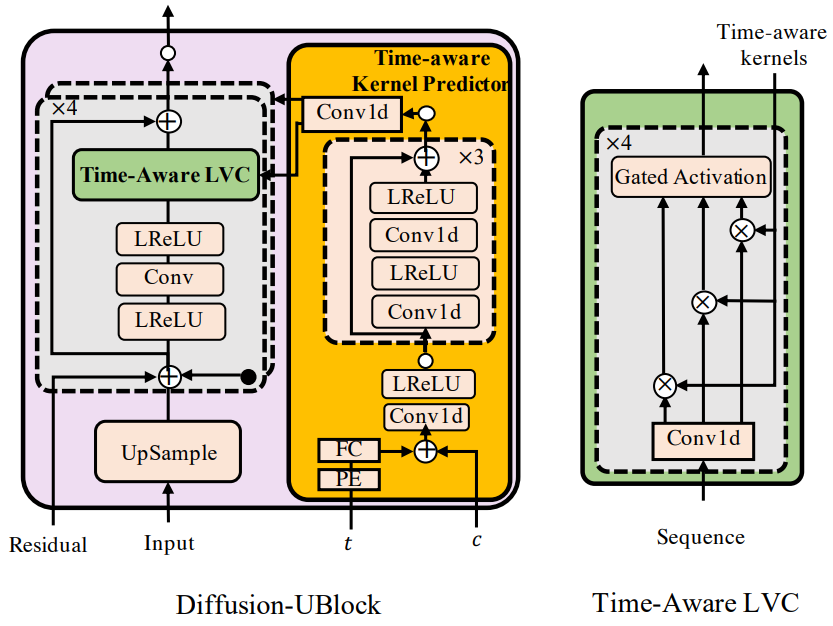
따라서 저자들은 위 그림과 같이 kernel predictor와 결합된 time-aware location-variable convolution (LVC) 모듈을 제안한다.
$q$번째 time-aware LVC layer의 경우 각 $x_t^k \in \mathbb{R}^M$가 있는 $K$개의 세그먼트를 생성하기 위해 $3^q$ dilation의 길이 $M$인 window를 사용하여 입력 $x_t \in \mathbb{R}^D$를 분할한다.
\[\begin{equation} \{x_t^1, \cdots, x_t^K\} = \textrm{split} (x_t; M, q) \end{equation}\]다음으로, kernel predictor $\alpha$에 의해 생성된 커널을 사용하여 입력 시퀀스의 관련 간격들에 대해 convolution 연산을 수행한다.
\[\begin{aligned} \{F_t, G_t\} &= \alpha (t, c) \\ z_t^k &= \textrm{tanh} (F_t \ast x_t^k) \odot \sigma (G_t \ast x_t^k) \\ z_t &= \textrm{concat} (\{z_t^1, \cdots, z_t^K\}) \end{aligned}\]여기서 $F_t$, $G_t$는 각각 $x_t^i$에 대한 filter와 gate kernel을, $\ast$는 1d convolution을, $\odot$은 element-wise product을, $\textrm{concat}(\cdot)$은 벡터 간의 concatenation을 나타낸다. Time-aware kernel은 noise level에 적응하고 acoustic feature에 따라 달라지므로 FastDiff는 noisy한 신호 입력이 주어진 경우 우수한 속도로 denoising 기울기를 정확하게 추정할 수 있다.
3. Accelerated Sampling
Noise Predictor
수백에서 수천 step의 샘플링을 피하기 위해 FastDiff는 bilateral denoising diffusion model (BDDM)의 noise scheduling 알고리즘을 채택하여 학습에 사용된 noise schedule보다 훨씬 짧은 샘플링 noise schedule을 예측한다. 이 스케줄링 방법은 다른 샘플링 가속 방법 (ex. WaveGrad의 grid search 알고리즘과 DiffWave의 빠른 샘플링 알고리즘)보다 우수한 것으로 밝혀졌다. Noise predictor는 반복적으로 연속적인 noise schedule $\hat{\beta} \in \mathbb{R}^{T_m}$을 도출한다.
Schedule Alignment
FastDiff에서는 DDPM과 유사하게 학습 중에 discrete timestep $T = 1000$을 사용한다. 따라서 샘플링 중에 $t$에 대해 컨디셔닝해야 하는 경우 $N \ll T$로 $T_m$ step의 샘플링 noise schedule $\hat{\beta}$를 $T$ step의 학습 noise schedule $\beta$에 정렬하여 $T_m$개의 discrete한 시간 인덱스를 근사화해야 한다.
4. Training, Noise Scheduling and Sampling



FastDiff는 두 가지 모듈로 개별적으로 parameterize된다.
- Score function의 VLB를 최소화하는 반복적인 정제 모델 $\theta$
- 더 엄격한 evidence lower bound를 위해 noise schedule을 최적화하는 noise predictor $\phi$.
Inference의 경우, 먼저 FastDiff가 샘플링 시 몇 배 더 빠르게 달성할 수 있는 one-shot scheduling 절차를 통해 더 엄격하고 더 효율적인 noise schedule $\hat{\beta}$를 도출한다. 최소 1개의 샘플에 대해 검색된 noise schedule이 테스트셋의 모든 샘플 중에서 고품질 생성을 유지하기에 충분히 robust하다. 둘째, schedule 정렬을 사용하여 연속적인 noise schedule을 discrete한 시간 인덱스 $T_m$에 매핑한다. 마지막으로 FastDiff는 Gaussian noise를 반복적으로 정제하여 계산 효율이 높은 고품질 샘플을 생성한다.
5. FastDiff-TTS
기존의 TTS 방법은 일반적으로 2단계 파이프라인을 채택한다.
- Text-to-spectrogram 생성 모듈 (acoustic model)은 분산 예측에 따라 운율 속성을 생성하는 것을 목표로 한다.
- 조건부 파형 생성 모듈 (보코더)은 위상 정보를 추가하고 상세한 파형을 합성한다.
본 논문은 TTS 파이프라인을 더욱 단순화하기 위해 중간 feature나 특수한 loss function이 필요하지 않은 완전한 end-to-end 모델인 FastDiff-TTS를 제안한다. FastDiff-TTS는 acoustic feature (ex. mel-spectrogram)을 명시적으로 생성할 필요 없이 컨텍스트 (ex. 음소)에서 직접 파형을 생성하는 완전히 미분 가능하고 효율적인 아키텍처로 설계되었다.
Architecture
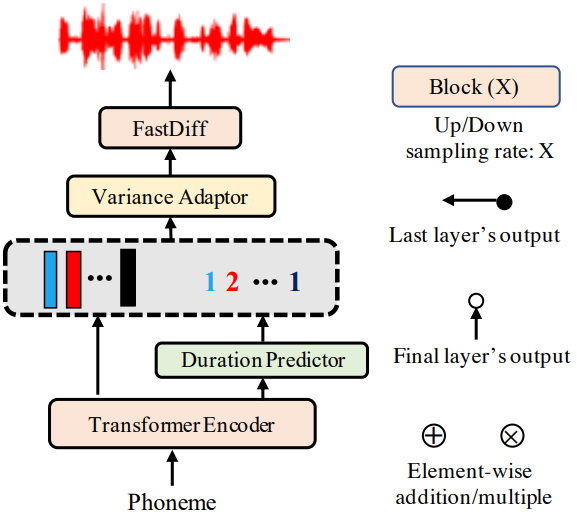
FastDiff-TTS의 아키텍처 설계는 기존 non-autoregressive TTS 모델인 FastSpeech 2를 backbone으로 참조한다. FastDiff-TTS의 아키텍처는 위 그림에 나와 있다. FastDiff-TTS에서 인코더는 먼저 음소 포함 시퀀스를 음소 hidden 시퀀스로 변환한다. 그런 다음 duration predictor는 원하는 파형 출력의 길이와 일치하도록 인코더 출력을 확장한다. 정렬된 시퀀스가 주어지면 variance adaptor는 hidden 시퀀스에 pitch 정보를 추가한다. 고충실도 파형에 대한 일반적으로 높은 샘플링 속도 (즉, 초당 24,000개 샘플)와 제한된 GPU 메모리로 인해 전체 텍스트 시퀀스에 해당하는 전체 오디오를 학습용으로 사용하기 어렵다. 따라서 FastDiff 모델로 전달하기 전에 작은 세그먼트를 샘플링하여 파형을 합성한다. 마지막으로 FastDiff 모델은 적응된 hidden 시퀀스를 보코더 task에서와 같이 음성 파형으로 디코딩한다.
Training Loss
FastDiff-TTS는 이전 연구들에서 제안한 것처럼 샘플 품질을 개선하기 위해 특수한 loss function과 및 적대적 학습이 필요하지 않다. 이는 TTS 생성을 크게 단순화한다. 최종 학습 loss는 다음과 같은 항으로 구성된다.
- Duration 예측 loss \(L_\textrm{dur}\): 로그 스케일에서 예측된 duration과 ground-truth 단어 레벨 duration 사이의 평균 제곱 오차
- Diffusion loss \(L_\textrm{diff}\): 추정된 noise과 Gaussian noise 사이의 평균 제곱 오차
- Pitch 재구성 loss \(L_\textrm{pitch}\): 예측 pitch 시퀀스와 ground-truth pitch 시퀀스 간의 평균 제곱 오차
경험적으로 \(L_\textrm{pitch}\)가 TTS 생성에서 일대다 매핑 문제를 처리하는 데 도움이 된다.
Experiments
- 데이터셋: LJSpeech
1. Comparsion with other models
다음은 다른 보코더 모델들과 품질, 합성 속도, 샘플 다양성을 비교한 표이다.
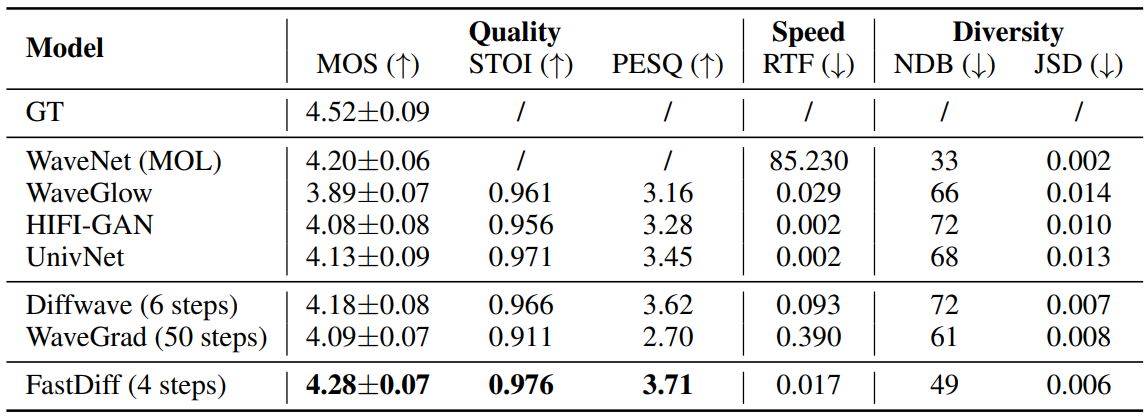
2. Ablation study
다음은 ablation study 결과이다.
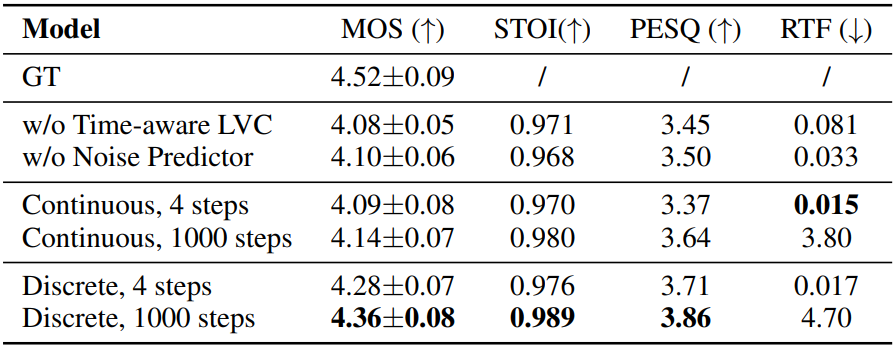
3. Generalization to unseen speakers
다음은 다른 보코더들과 처음 보는 사람에 대한 품질을 비교한 표이다.
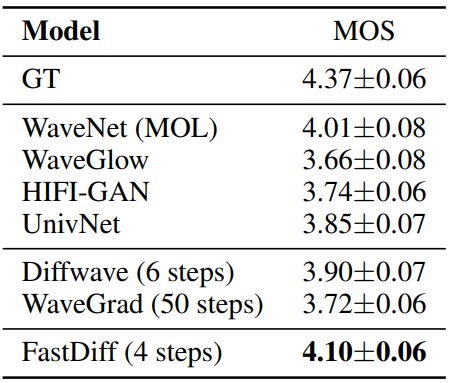
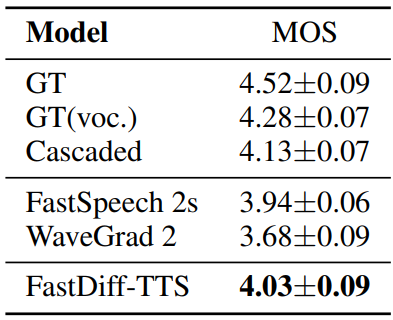
4. End-to-End Text-to-Speech
다음은 다른 TTS 모델들과 품질을 비교한 표이다.