[논문리뷰] Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
CVPR 2025. [Paper] [Page]
Jianing Yang, Alexander Sax, Kevin J. Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, Matt Feiszli
Meta | University of Michigan
23 Jan 2025
Introduction
SfM이나 MVS와 같은 3D 재구성 분야의 파이프라인 패러다임과 달리, 최근 RGB 이미지에서 3D 구조를 직접 예측하는 DUSt3R가 제안되었다. DUSt3R는 쌍별 재구성 문제를 pointmap 회귀 문제로 바꾸어 일반적인 카메라 모델의 제약을 완화하고 어려운 시점에서 인상적인 robustness를 제공한다. 이는 end-to-end로 학습 가능한 솔루션이 파이프라인 패러다임의 오차 누적에 덜 취약하면서도 더 간단하기 때문이다.
반면, DUSt3R의 근본적인 한계는 두 개의 이미지 입력으로 제한된다는 것이다. 두 개 이상의 이미지를 처리하기 위해 DUSt3R은 $\mathcal{O}(N^2)$ 쌍의 pointmap을 계산하고 global alignment 최적화 절차를 수행한다. 이 프로세스는 계산 비용이 많이 들며 이미지의 개수가 많아짐에 따라 확장성이 떨어진다. 예를 들어, 48개의 뷰만 주어지더라도 A100 GPU에서 메모리가 부족하다. 게다가, 이러한 프로세스는 여전히 근본적으로 쌍으로 진행되어 모델의 컨텍스트를 제한하고, 이는 궁극적인 정확도에 영향을 미친다.
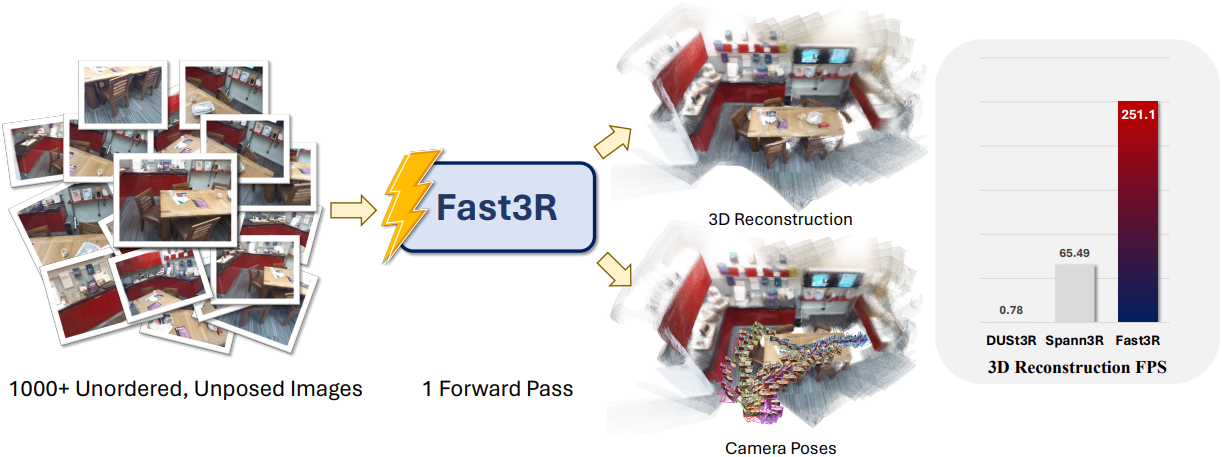
본 논문은 이러한 한계를 극복하도록 설계된 새로운 멀티뷰 재구성 프레임워크인 Fast3R을 제안하였다. DUSt3R를 기반으로 Fast3R는 여러 이미지를 병렬로 처리하는 Transformer 기반 아키텍처를 활용하여 한 번의 forward pass에서 $N$개의 이미지를 재구성할 수 있다. 순차적 또는 쌍별 처리의 필요성을 없앰으로써 재구성 중에 다른 모든 프레임을 동시에 처리할 수 있어 오차 누적이 크게 줄어든다. 놀랍게도 Fast3R는 시간도 상당히 적게 걸린다.
Method
1. Problem definition
$N$개의 순서 없고 포즈가 지정되지 않은 RGB 이미지 $\textbf{I} \in \mathbb{R}^{N \times H \times W \times 3}$을 입력으로 취하는 Fast3R는 해당 pointmap $\textbf{X} \in \mathbb{R}^{N \times W \times H \times 3}$을 예측하여 장면의 3D 구조를 재구성한다. Pointmap은 이미지 $\textbf{I}$의 픽셀로 인덱싱된 3D 위치들의 집합으로, 카메라 포즈, 깊이, 3D 구조를 도출할 수 있다.
Fast3R는 $N$개의 RGB 이미지를 로컬 pointmap \(\textbf{X}_L\), 글로벌 pointmap \(\textbf{X}_G\), 그리고 각각에 대한 신뢰도 맵 \(\Sigma_L\)과 \(\Sigma_G\)에 매핑한다. ($\Sigma \in \mathbb{R}^{N \times H \times W}$)
\[\begin{equation} \textrm{Fast3R} \, : \, \textbf{I} \, \rightarrow \, (\textbf{X}_L, \Sigma_L, \textbf{X}_G, \Sigma_G) \end{equation}\]MASt3R와 마찬가지로 글로벌 pointmap \(\textbf{X}_G\)는 첫 번째 카메라의 좌표 프레임에 있고 \(\textbf{X}_L\)은 해당 카메라의 좌표 프레임에 있다.
2. Training Objective
Fast3R의 \((\hat{\textbf{X}}_L, \hat{\Sigma}_L, \hat{\textbf{X}}_G, \hat{\Sigma}_G)\) 예측은 DUSt3R의 pointmap loss의 일반화된 버전을 사용하여 학습된다.
총 loss는 로컬 및 글로벌 pointmap에 대한 pointmap loss의 조합이다.
\[\begin{equation} \mathcal{L}_\textrm{total} = \mathcal{L}_{\textbf{X}_G} + \mathcal{L}_{\textbf{X}_L} \end{equation}\]Normalized 3D pointwise regression loss
$\textbf{X}$에 대한 정규화된 regression loss는 DUSt3R 또는 monocular depth 추정의 멀티뷰 버전이다. 이는 정규화된 예측 pointmap과 정규화된 타겟 pointmap 사이의 $L_2$ loss이며, 원점까지의 평균 유클리드 거리로 재조정된다.
\[\begin{equation} \ell_\textrm{regr} (\hat{\textbf{X}}, \textbf{X}) = \| \frac{1}{\hat{z}} \hat{\textbf{X}} - \frac{1}{z} \textbf{X} \|_2, \quad z = \frac{1}{\vert \textbf{X} \vert} \sum_{x \in \textbf{X}} \| x \|_2 \end{equation}\]예측값과 타겟은 원점까지의 평균 유클리드 거리에 따라 독립적으로 정규화된다.
Pointmap loss
DUSt3R에서와 같이, 모델에서 예측한 신뢰도 점수 \(\hat{\Sigma}\)를 사용하여 위의 loss의 신뢰도 조정 버전을 사용한다. Pointmap에 대한 총 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textbf{X} (\hat{\Sigma}, \hat{\textbf{X}}, \textbf{X}) = \frac{1}{\vert \textbf{X} \vert} \sum \hat{\Sigma}_{+} \cdot \ell_\textrm{regr} (\hat{\textbf{X}}, \textbf{X}) + \alpha \log (\hat{\Sigma}_{+}) \end{equation}\]신뢰도 점수가 양수여야 하므로 $4\hat{\Sigma}_{+} = 1 + \exp(\hat{\Sigma})$$로 설정한다. Fast3R는 DUSt3R와 마찬가지로 기본 pointmap 레이블에 오차가 포함된 실제 스캔에서 학습되며, 신뢰도 가중치는 모델이 레이블 노이즈를 처리하는 데 도움이 된다.
3. Model architecture
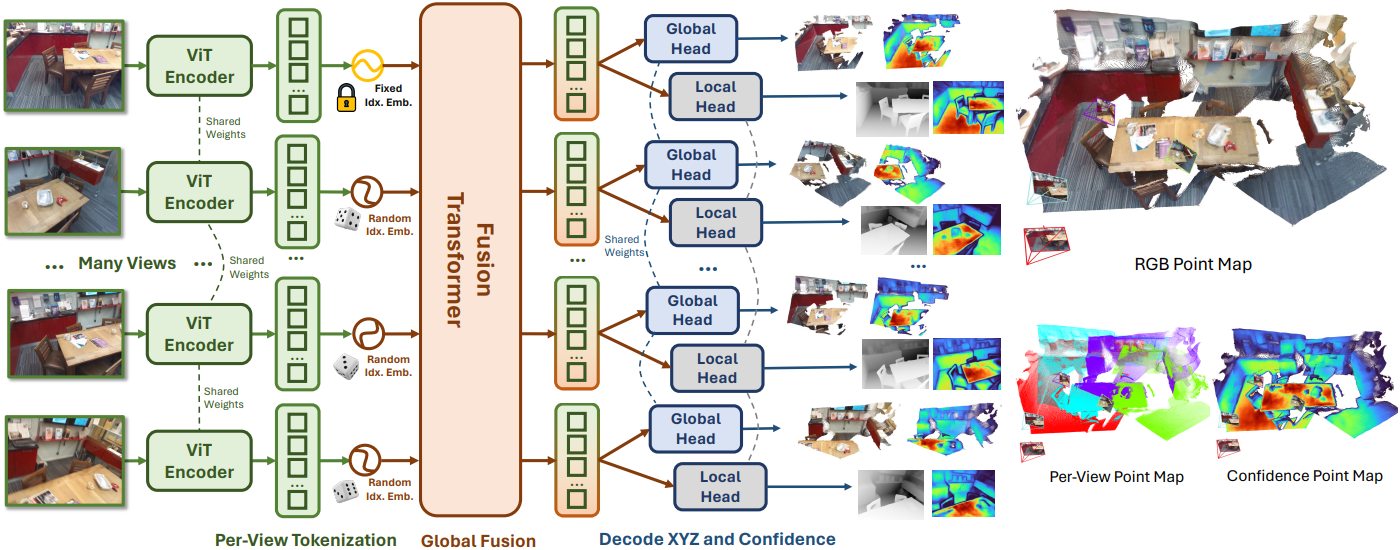
Fast3R의 아키텍처는 DUSt3R에서 영감을 받았으며, 이미지 인코딩, fusion transformer, pointmap 디코딩의 세 가지 구성 요소로 구성된다. Fast3R는 $\textbf{I}$의 이미지 순서에 대해 어떠한 가정도 하지 않으며, 모든 출력 pointmap과 신뢰도 맵 \((\textbf{X}_L, \Sigma_L, \textbf{X}_G, \Sigma_G)\)는 순차적으로가 아니라 동시에 예측된다.
Image encoder
Fast3R는 feature 추출기 $\mathcal{F}$를 사용하여 각 이미지 $I_i \in \textbf{I}$를 패치 feature $H_i$로 인코딩한다. 이는 이미지마다 독립적으로 수행되어 각 이미지에 대해 이미지 패치 feature 시퀀스 \(H_i = \{h_{i,j}\}_{j=1}^{HW/P^2}\)를 생성한다.
\[\begin{equation} H_i = \mathcal{F} (I_i), \quad i \in 1, \ldots, N \end{equation}\]저자들은 DUSt3R의 디자인을 따르고 CroCo ViT를 인코더로 사용하였지만 DINOv2도 비슷하게 작동한다는 것을 발견했다.
이미지 패치 feature $\textbf{H}$를 fusion transformer에 전달하기 전에 1차원 이미지 인덱스 위치 임베딩을 더한다. 인덱스 임베딩은 fusion transformer가 어떤 패치가 같은 이미지에서 나왔는지 판단하는 데 도움이 되며, 글로벌 좌표 프레임을 정의하는 $I_1$을 식별하는 메커니즘이다. 이는 모델이 순서와 무관한 토큰 집합의 모든 이미지에 대해 카메라 포즈를 공동으로 추론할 수 있도록 하는 데 중요하다.
Fusion transformer
Fast3R에서 대부분의 계산은 fusion transformer에서 발생한다. ViT-B 또는 BERT와 유사한 12-layer transformer를 사용하지만, 이는 scale up 될 수 있다. 이 fusion transformer는 모든 뷰에 대하여 concat된 인코딩된 이미지 패치를 가져와서 all-to-all self-attention을 수행한다. 이 연산은 Fast3R에 쌍으로만 제공되는 정보를 넘어서는 전체 컨텍스트를 제공한다.
Pointmap head
마지막으로, Fast3R는 별도의 DPT-L 디코더 head를 사용하여 토큰을 로컬 및 글로벌 pointmap (\(\textbf{X}_L\), \(\textbf{X}_G\))과 신뢰도 맵 (\(\Sigma_L\), \(\Sigma_G\))에 매핑한다.
Image index positional embedding generalization
저자들은 Fast3R가 inference 시에 모델을 학습시키는 데 사용된 것보다 많은 뷰를 처리할 수 있기를 바랐다. Inference 중에 뷰를 임베딩하는 단순한 방법은 학습과 같은 방식으로 뷰를 임베딩하는 것이다. 즉, 학습 중에는 동일한 Spherical Harmonic 주파수를 사용하여 인덱스 \(\textrm{SH}(\{1, \ldots, N\})\)을 임베딩하고 inference 중에는 \(\textrm{SH}(\{1, \ldots, N_\textrm{test}\})\)를 임베딩한다.
저자들은 예비 실험에서 학습 중에 사용된 수를 초과하는 입력 이미지의 경우 결과 모델이 제대로 작동하지 않는다는 것을 발견했다. 따라서 Position Interpolation을 적용하여 학습 중에 $N$개의 인덱스를 더 큰 풀 $N^\prime$에서 무작위로 추출한다. 이미지는 정렬되지 않았으므로 \(N \subset \{1, \ldots, N^\prime\}\)을 무작위로 균일하게 샘플링한다. Transformer에 이 전략은 이미지를 마스킹하는 것과 동일하며, $N^\prime \gg N$은 마스킹 비율을 제어한다. 이 전략을 사용하면 Fast3R는 $N = 20$개의 이미지로만 학습하더라도 inference 중에 $N = 1000$개의 이미지를 처리할 수 있다.
4. Memory-Efficient Implementation
Fast3R는 표준 transformer 아키텍처와 single-pass inference 절차를 사용하기 때문에 학습 및 inference 시에 확장성(scalability)을 개선하도록 설계된 최신 기술을 많이 활용할 수 있다.
Fast3R 아키텍처는 이러한 기술들을 활용하도록 명시적으로 설계되었다. 저자들은 학습 및 inference 시에 DeepSpeed ZeRO stage 2 training과 FlashAttention을 활용하였다.
Experiments
- 데이터셋: CO3D, ScanNet++, ARKitScenes, Habitat
- 아키텍처 디테일
- 이미지 인코더: CroCo ViT-B (DUSt3R 가중치로 초기화)
- Fusion transformer: ViT-B (BERT 아키텍처)
- layer: 12개
- head: 12개
- 임베딩 차원 크기: 768
- FFN 차원 크기: 3,072
- 인덱스 임베딩 풀 크기: $N^\prime$ = 1000
- Pointmap 디코더: DPT-L
- 학습 디테일
- 이미지 해상도: 512$\times$512
- optimizer: AdamW
- step: 6,500
- learning rate: 0.0001 (cosine annealing)
- batch size: 총 64 (GPU당 1)
- GPU: A100 64개에서 6.13일 소요
다음은 Fast3R로 재구성한 장면의 예시들이다.

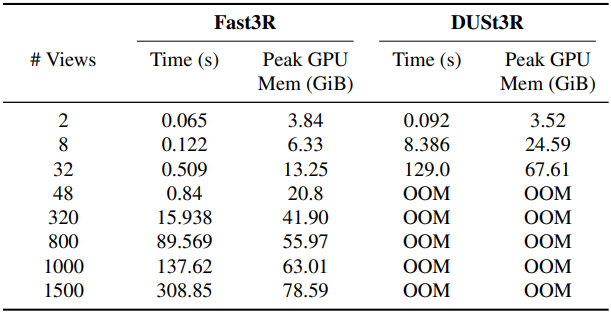
1. Inference Efficiency
다음은 A100 1개에서 Fast3R와 DUSt3R의 성능을 뷰 수에 따라 비교한 표이다.
2. Camera Pose Estimation
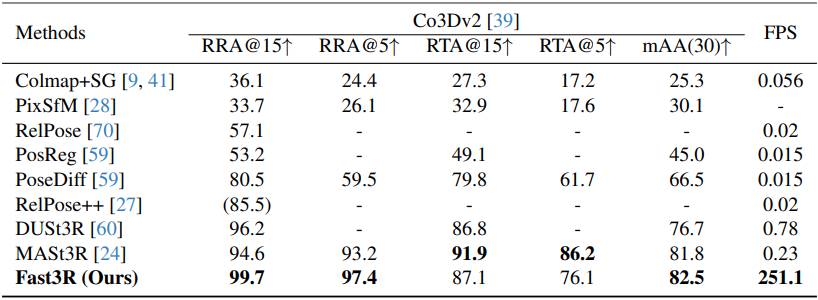
다음은 CO3Dv2 데이터셋에서의 멀티뷰 포즈 추정 결과를 비교한 표이다.
3. 3D Reconstruction
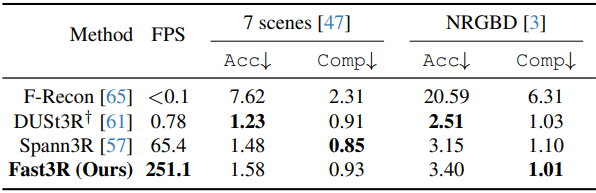
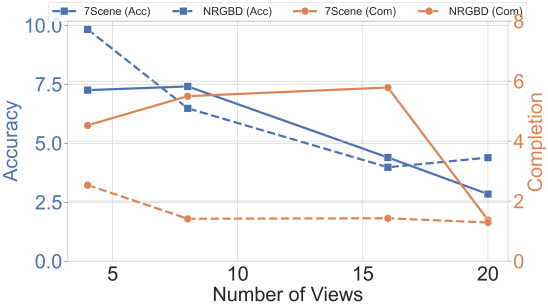
다음은 7Scenes와 Neural RGB-D 데이터셋에서의 재구성 품질을 비교한 표이다.
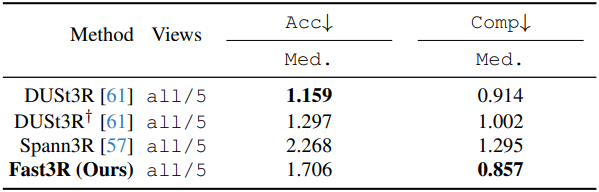
다음은 DTU 데이터셋에서의 재구성 품질을 비교한 표이다.
4. 4D Reconstruction: Qualitative Results
다음은 DAVIS의 동적 장면에 대한 4D 재구성 결과들이다.

5. Ablation Studies
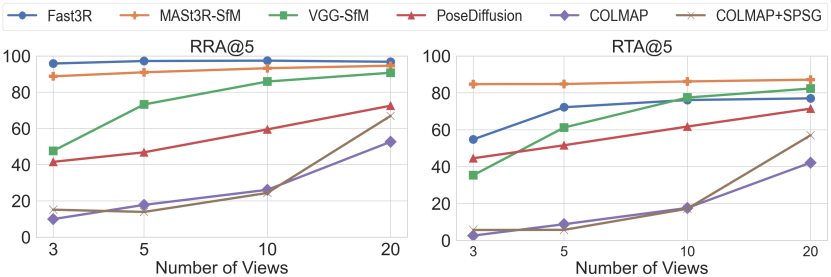
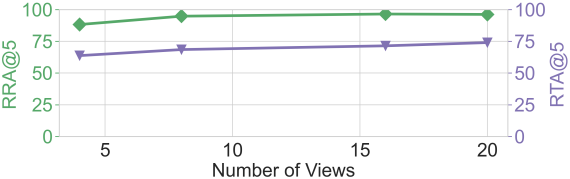
다음은 테스트 뷰 수에 따른 (위) 카메라 포즈 정확도와 (아래) 재구성 품질을 비교한 그래프이다.
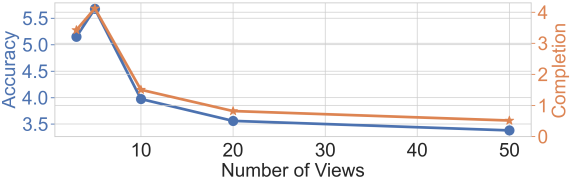
다음은 학습 뷰 수에 따른 (위) 카메라 포즈 정확도와 (아래) 재구성 품질을 비교한 그래프이다.
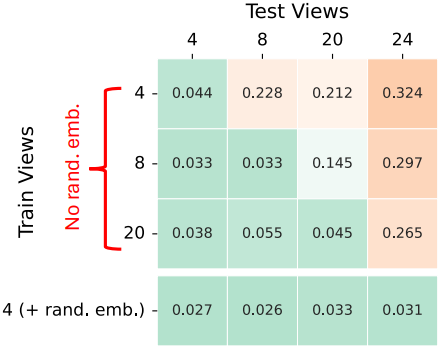
다음은 이미지 인덱스 위치 임베딩에 대한 ablation 결과이다.
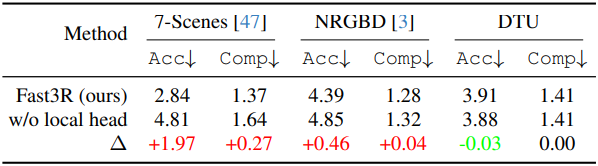
다음은 로컬 head에 대한 ablation 결과이다.