[논문리뷰] Face Animation with an Attribute-Guided Diffusion Model (FADM)
arXiv 2023. [Paper] [Github]
Bohan Zeng, Xuhui Liu, Sicheng Gao, Boyu Liu, Hong Li, Jianzhuang Liu, Baochang Zhang
Beihang University | Shenzhen Institutes of Advanced Technology | University of Chinese Academy of Sciences | Zhongguancun Laboratory
6 Apr 2023

Introduction
가이드 영상에서 제공되는 포즈와 표정으로 정지된 얼굴을 애니메이션화하는 얼굴 애니메이션은 점점 더 많은 관심을 받고 있다. GAN과 같은 생성 모델의 발전으로 최근의 얼굴 애니메이션 방법은 충실도가 높은 말하는 얼굴을 합성하는 데 있어 인상적인 성능을 달성했다. 그러나 여전히 생성된 결과에서 바람직하지 않은 아티팩트와 왜곡이 발생한다.
기존의 얼굴 애니메이션 방식은 대부분 GAN 모델을 기반으로 하며, 주로 생성 과정을 워핑(warping)과 렌더링(rendering)으로 나눈다. 워핑과 렌더링은 소스 이미지와 가이드 동영상 간의 표정과 포즈의 차이를 활용하여 motion flow를 계산하고 인코딩된 소스 feature의 추가 워핑 프로세스를 가이드할 수 있다. 그 후 워핑된 feature는 최종 결과를 렌더링하고 합성하기 위해 디코딩 모듈에 공급된다. 이러한 방법은 크게 model-free, 랜드마크 기반, 3D 구조 기반의 세 가지 카테고리로 분류할 수 있다. 이러한 방법들은 소스의 identity(신원)와 외관을 보존하는 유망한 성능을 얻고 가이드 동영상에서 비교적 정확한 모션을 생성한다. 그러나 충실도 높은 외모 재구성에 대한 adversarial learning(적대적 학습)의 제한된 능력으로 인해 이러한 GAN 기반 방법은 얼굴 분포에 더 중점을 두지만 얼굴의 디테일에는 그다지 집중하지 않으므로 부자연스러운 아티팩트와 왜곡을 생성할 수 있다.
최근 컴퓨터 비전에서 DDPM의 큰 성공은 생성 task에서 뛰어난 능력을 나타낸다. 일련의 diffusion step을 통해 매우 복잡한 데이터 분포를 모델링할 수 있다. Diffusion model은 GAN에서 발생하는 왜곡 문제를 효과적으로 방지하고 충실도 높은 얼굴 디테일을 생성할 수 있다. 그러나 기존 diffusion model은 특정 속성 제한 없이 이미지를 임의의 고분산의 latent space로 인코딩하는 경향이 있으며, 이는 얼굴 모양, 포즈 및 표정에 대한 명시적인 요구 사항이 있는 얼굴 애니메이션에는 적합하지 않다.
본 논문에서는 정확한 애니메이션 속성을 보장하면서 왜곡과 부자연스러운 아티팩트를 수정하기 위해 반복적인 denoising diffusion process로 얼굴 애니메이션을 생성하며, Face Animation framework with a Diffusion Model (FADM)이라는 얼굴 애니메이션 프레임워크를 제안한다. 구체적으로, diffusion process를 위한 저해상도 feature를 제공하는 예비 애니메이션 결과를 얻기 위해 Coarse Generative Module (CGM)을 도입한다. Diffusion model의 높은 가변성을 완화하기 위해 Attribute-Guided Conditioning Network (AGCN)를 설계하여 외형 및 모션 조건을 반복적인 개선 프로세스에 통합한다. 한편으로는 인코더 네트워크를 활용하여 가이드 프레임과 coarse feature에서 외형 코드를 추출하고 이를 align하기 위해 MSE loss를 도입한다. 또한 3D 재구성 모듈을 활용하여 소스와 가이드 프레임의 포즈와 표정을 예측한다. 이를 기반으로 AGCN은 MLP를 사용하여 다중 해상도 feature에 대해 서로 다른 신뢰 값을 할당하고 coarse feature의 표현된 비율을 적응적으로 조정하며 모션 조건으로 효과적으로 융합한다.
Method
GAN은 복잡한 얼굴 구조와 모션을 모델링하는 능력이 제한되어 있기 때문에 기존 방법은 종종 본질적인 왜곡과 부자연스러운 아티팩트를 겪는다. 이 문제를 해결하기 위해 diffusion model 사용한 얼굴 애니메이션 프레임워크를 제안한다. 이 프레임워크는
- 대략적인(coarse) 생성 모듈
- 3D 얼굴 재구성 모델
- 속성 기반 컨디셔닝 네트워크
- Diffusion 렌더링 모듈
로 구성된다. FADM의 개요는 아래 그림에 나와 있다.
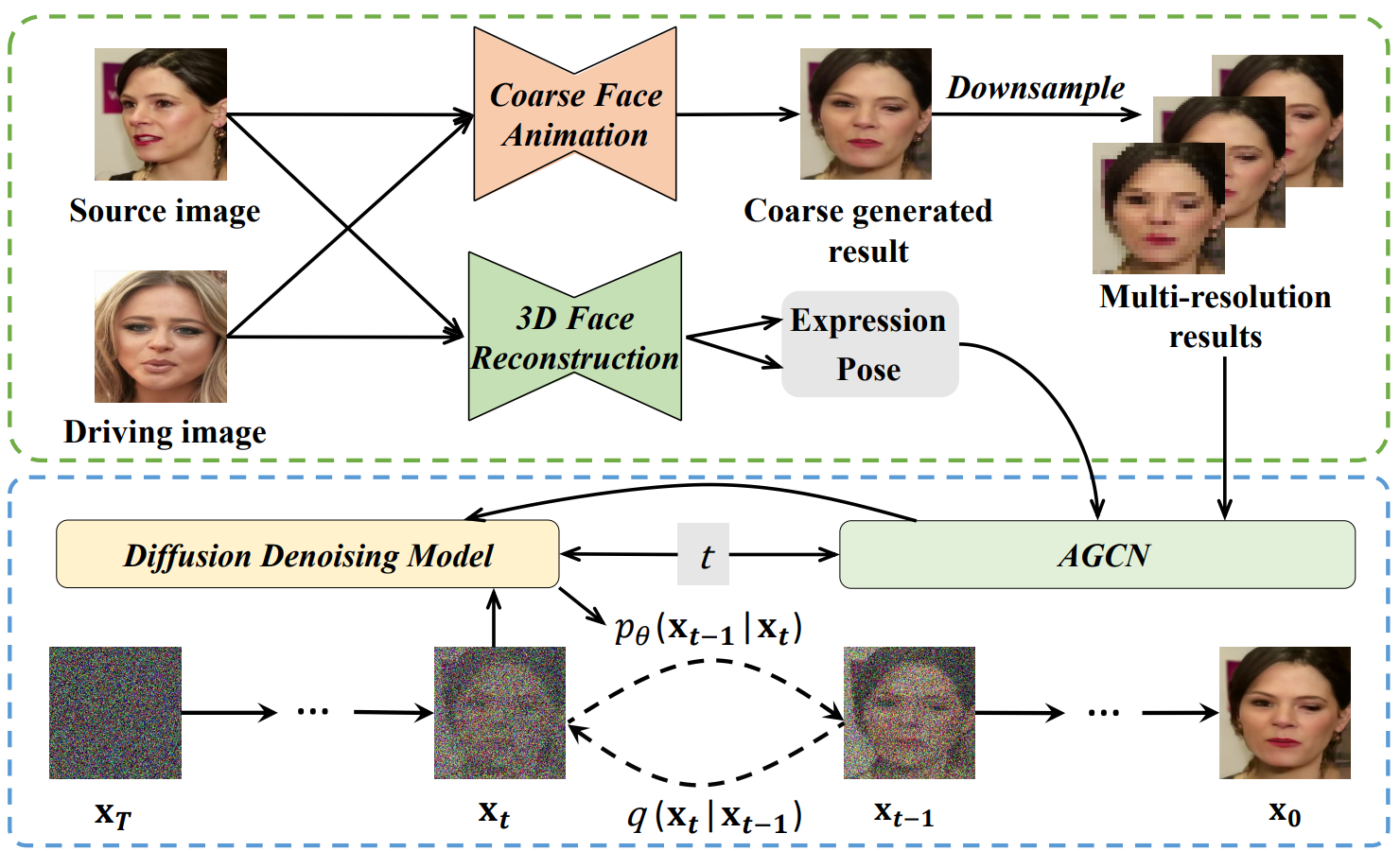
1. Coarse Generative Module
FADM에서는 먼저 FOMM 또는 Face vid2vid와 같은 Coarse Generative Module (CGM)을 사용하여 대략적인(coarse) 애니메이션 이미지를 생성한다. 원본 이미지 $s$와 가이드 프레임 $d$가 주어지면 CGM의 목적은 $s$의 모양 정보를 유지하면서 $d$에서 파생된 표정 및 포즈 정보로 $s$를 변형하는 것이다. 가이드 프레임의 표정과 포즈에 따라 소스 feature를 먼저 워핑한 다음 워핑된 feature를 렌더링하여 최종 애니메이션 이미지를 얻는 두 단계를 포함한다. 직관적으로 대략적인 애니메이션 결과 $g$를 생성하는 일반적인 프로세스는 다음과 같다.
\[\begin{equation} g = G(\textrm{Warp}(s, exp_d, pose_d)) \end{equation}\]여기서 $G$는 생성 모델을 나타내고 $exp_d$와 $pose_d$는 $d$의 표현과 포즈를 나타낸다. 대략적인 결과는 $s$의 모양을 보존하고 $d$의 모션을 전달하는 데 유망한 성능을 갖지만 얼굴 디테일과 얼굴 너머의 배경 영역에 바람직하지 않은 왜곡이 종종 존재한다. 이 문제를 완화하기 위해 명확한 조건으로 diffusion process를 활용하여 대략적인 결과를 개선한다.
2. Diffusion Rendering Module
CGM으로 인한 왜곡 문제를 처리하기 위해 FADM에서 diffusion 렌더링 모듈을 설계하여 대략적인 부분에서 디테일한 부분까지의 반복적인 diffusion process를 통해 사실적인 이미지를 합성한다. 여기에서는 먼저 diffusion model의 사전 정보를 제공한 다음 얼굴 애니메이션에 대한 이 모듈을 설명한다.
Diffusion Rendering for Face Animation
Diffusion model의 고분산 인코딩과 얼굴 애니메이션의 명시적 속성 요구 사항 사이의 불일치를 피하기 위해 diffusion model은 가이드 프레임의 포즈와 표정을 가지고 소스의 모양과 엄격하게 일치하는 렌더링 얼굴 프레임을 생성해야 한다. 따라서 diffusion 렌더링 모델의 inference 프로세스는 다음과 같다.
\[\begin{equation} p_d (x_{0:T}) = p (x_T) \prod_{t=1}^T p_d (x_{t-1} \vert x_t, a, m) \\ p_d (x_{t-1} \vert x_t, a, m) = \mathcal{N} (x_{t-1}; \mu_d (x_t, t, a, m), \Sigma_d (x, t, a, m)) \end{equation}\]여기서 $a$는 소스 이미지의 외형 코드이고 $m$은 소스 이미지와 가이드 프레임의 포즈 및 표정 간의 변화에서 파생된 모션 조건이다. 결과적으로 diffusion 렌더링 모델의 최적화 목적 함수는 조건부 diffusion loss $\mathcal{L}_d$로 정의된다.
\[\begin{equation} \mathcal{L}_d = \mathbb{E}_{x_0, (a, m), z \sim \mathcal{N}(0,1, t)} [\|z - z_d (x_t, t, (a, m))\|_2^2] \end{equation}\]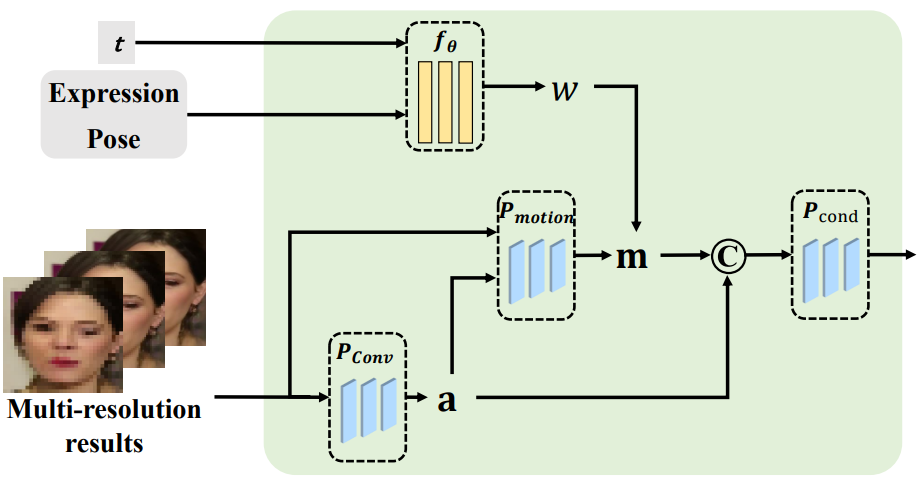
$(a, m)$으로 $\mathcal{L}_d$를 최소화하기 위해 Attribute-Guided Conditioning Network (AGCN)을 설계하여 적절한 외형과 모션 조건을 추출하고 위 그림과 같이 diffusion process를 탐색하기 위해 적응적으로 융합한다. 외형 조건은 소스 이미지의 충실한 특성으로 diffusion process를 제공하도록 사용되는 반면, 모션 조건은 생성된 포즈와 표정에 제한을 가하고 얼굴 디테일을 동적으로 수정할 수 있다.
Appearance Condition
소스와 가이드 프레임의 동일한 identity를 사용하는 현재 학습 스타일을 고려할 때 가이드 프레임은 후속 diffusion process에 대한 충실한 외형 정보를 제공하는 가장 적절한 조건이며, inference 프로세스중에 대략적인 애니메이션 결과만 사용할 수 있다. 외형 코드 $a$를 추출하기 위해 CNN 인코더 \(P_\textrm{Conv}\)를 설계한다.
\[\begin{equation} a = \begin{cases} P_\textrm{conv} (\downarrow_\ast (d)) & \quad \textrm{in training} \\ P_\textrm{conv} (\downarrow_\ast (g)) & \quad \textrm{in inference} \end{cases} \end{equation}\]여기서 $\downarrow_\ast$는 다운샘플링 연산이다. 위에서 언급한 바와 같이 거친 애니메이션 결과는 예상치 못한 외형에 대한 간섭을 포함할 수 있으므로 간섭을 완화하고 inference 중에 제공되는 신뢰성을 보장하는 것을 목표로 한다. 구체적으로 가이드 프레임과 대략적인 애니메이션 결과를 각각 \(P_\textrm{Conv}\)에 입력한 다음 MSE loss \(\mathcal{L}_\textrm{color}\)를 통해 $d$와 $g$에서 예측된 외형 조건을 다음과 같이 align한다.
\[\begin{equation} \mathcal{L}_\textrm{color} = \textrm{MSE} (P_\textrm{conv} (\downarrow_\ast (d)), P_\textrm{conv} (\downarrow_\ast (g))) \end{equation}\]여기서 $d$와 $g$는 모두 $t$와 무관한 고정된 feature이다. \(\mathcal{L}_\textrm{color}\)는 $g$에서 가장 가치 있는 외형 정보를 추출하기 위해 \(P_\textrm{Conv}\)를 용이하게 함으로써 작동한다. 결과적으로 \(P_\textrm{Conv}\)는 inference 중에 충실한 외형 조건을 제공할 수 있으며, 이는 학습 과정에서 $d$가 제공하는 것과 유사하다.
Motion Condition
FADM이 대략적인 애니메이션 결과의 품질을 개선하는 것을 목표로 한다는 점을 고려할 때 모션 조건으로 간주하는 것이 diffusion process에 대해 직관적으로 효과적인 선택인 것 같다. 그럼에도 불구하고 diffusion process에서 왜곡을 가져올 수도 있다. 경험적으로 대략적인 결과는 소스와 가이드 프레임 사이에서 모션이 극적으로 변할 때 극심한 왜곡을 겪는다. 이 경우 해상도가 높은 feature는 더 많은 왜곡을 포함하는 경향이 있는 반면 해상도가 낮은 feature는 왜곡을 약화시킬 수 있다. 즉, 고해상도 feature와 비교하여 저해상도 feature는 diffusion process가 왜곡을 보상하기 위해 더 풍부한 얼굴 디테일을 합성할 수 있도록 한다. 이를 기반으로 이 문제를 적응형 방식으로 처리하고, 다중 해상도의 대략적인 애니메이션 결과를 모션 조건으로 융합하는 균형을 찾고, 정확한 애니메이션 속성을 보장함을 기반으로 왜곡을 완화하고 얼굴 디테일을 풍부하게 한다.
구체적으로 먼저 다운샘플링 연산을 활용하여 대략적인 애니메이션 결과를 해상도가 다른 세 가지 coarse feature로 처리한다. 한편, 고급 3D 얼굴 재구성 모델 DECA를 활용하여 소스와 가이드 프레임에서 얼굴 포즈 $pose$와 표정 $exp$를 추출하고 모션 상태로 concat한다. 그런 다음 모션 측정 함수로 MLP $f_\theta$를 도입하여 원본 이미지와 가이드 프레임 간의 모션 진폭 변화를 모델링하여 모션 가중치 $w$를 얻는다. 프로세스는 다음과 같이 표현된다.
\[\begin{equation} w = f_\theta (\textrm{Concat} (exp_s, pose_s) - \textrm{Concat} (exp_d, pose_d), t) \end{equation}\]여기서 $t$는 diffusion process의 임의의 timestep이다.
초기 가중치를 사용하여 움직임이 크게 변경될 때 저해상도 feature에 더 큰 값을 할당한다. 움직임이 많이 변하지 않는다면 고해상도 feature에 더 큰 가중치를 할당하여 높은 충실도의 생성을 보장해야 한다. 모션 조건 $m$을 다음과 같이 계산한다.
\[\begin{aligned} w_i &= \frac{K-i}{K} \cdot \exp(w - \alpha) + \frac{i}{K} \cdot \exp (-w + \alpha) \\ m &= \sum_{i=1}^K w_i \cdot P_\textrm{motion} (g_i, a) \end{aligned}\]여기서 $\alpha$는 hyperparameter, $g_i$는 대략적으로 생성된 영상, $w_i$는 해상도가 다른 정제된 영상에 대한 모션 가중치, $K$는 해상도의 개수, \(P_\textrm{motion}\)은 모션 조건을 서로 다른 해상도로 생성하는 CNN이다. 본 논문에서는 $\alpha = 0.3$으로 설정했다.
마지막으로 외형 조건 $a$와 모션 조건 $m$을 융합하는 CNN \(P_\textrm{cond}\)를 도입한다. 일반적으로 diffusion model의 목적 함수는 다음과 같이 다시 쓸 수 있다.
\[\begin{equation} \mathcal{L}_d = \mathbb{E}_{x_0, (a, m), z \sim \mathcal{N}(0,1), t} [\| z - z_d (x_t, t, P_\textrm{cond} (a, m, t)) \|_2^2] \end{equation}\]여기서 $z_d$는 diffusion denoising model을 나타낸다. DDIM을 따라 반복적으로 noise를 제거하고 100개의 timestep에서 높은 충실도의 타겟 얼굴을 합성하도록 최적화된 denoising model로 U-net 아키텍처를 사용한다.
첫 번째 프레임을 원본 이미지로 설정하여 기존 애니메이션 동영상의 시각적 품질을 개선하는 데 FADM을 직접 사용할 수 있어 실제로 매우 편리하다.
Experiments
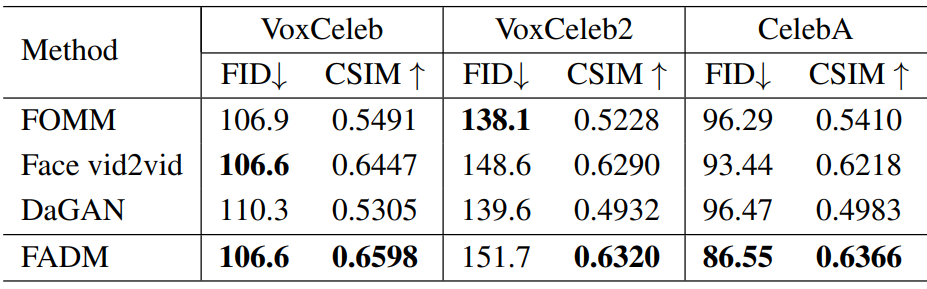
- 데이터셋: VoxCeleb, VoxCeleb2, CelebA
- Training Details
- 사전 학습된 FOMM이나 Face vid2vid를 사용하여 대략적인 얼굴 애니메이션 생성
- 그런 다음 epoch당 75회 반복되는 동영상의 이미지를 사용하여 약 100 epoch 동안 FADM을 학습
- Adam optimizer, learning rate $2 \times 10^{-4}$, $(\beta_1, \beta_2) = (0.5, 0.9)$
- 4개의 24GB NVIDIA 3090 GPU로 학습
- Evalution Metrics
- $\mathcal{L}_1$, PSNR, SSIM
- LPIPS, FID
- Average Keypoint Distance (AKD), Average Euclidean Distance (AED)
- identity preservation cosine similarity (CSIM)
1. Comparison with State-of-the-Art Methods
Same-Identity Reconstruction
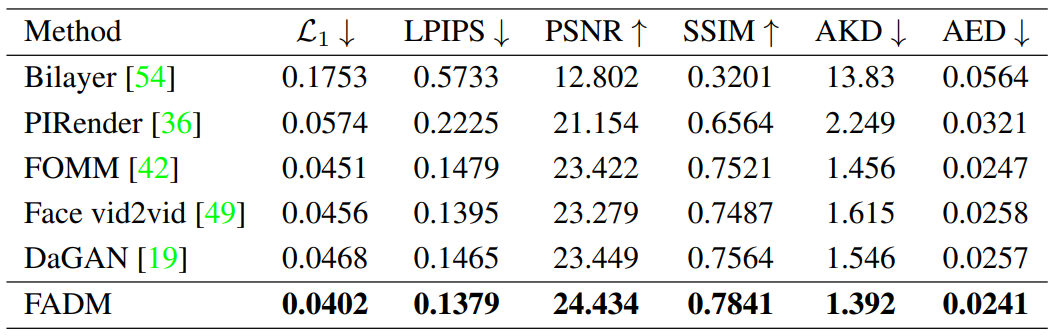
다음은 VoxCeleb에서 같은 사람으로 재구성한 결과를 비교한 것이다.

Cross-Identity Reenactment
다음은 다른 사람으로 재연한 결과를 비교한 것이다.

2. Ablation Study
다음은 VoxCeleb에서의 same-identity reconstruction에 대한 ablation study 결과이다.

