[논문리뷰] Progressive Compositionality In Text-to-Image Generative Models
ICLR 2025 (Spotlight). [Paper] [Page] [Github]
Xu Han, Linghao Jin, Xiaofeng Liu, Paul Pu Liang
Yale University | University of Southern California | MIT
22 Oct 2024

Introduction
최근의 diffusion model들은 입력 텍스트 프롬프트에서 전달되는 semantic 정보를 더 잘 포착하기 위해 diffusion model 내의 attention 메커니즘을 최적화하는 데 중점을 두고 있다. 이러한 방법들은 여전히 attribute binding 문제나 물체 관계를 완전히 다루기에 부족하다.
본 논문에서는 커리큘럼 학습이 diffusion model에 조합성(compositionality)에 대한 기본적인 이해를 제공하는 데 필수적이라고 주장한다. 기존 모델은 종종 기본적인 프롬프트 (ex. “Two cats are playing”)에도 어려움을 겪기 때문에 fine-tuning 중에 더 복잡한 조합 시나리오를 점진적으로 도입한다. 이 단계적 학습 전략은 모델이 복잡한 사례를 다루기 전에 견고한 기반을 구축한 다음 광범위한 task에서 성능을 개선하는 데 도움이 된다.
조합적 생성(compositional generation)을 데이터셋은 많지만, 단순한 샘플에서 복잡한 샘플로 자연스럽고 논리적인 맥락에서 점진적으로 발전하는 데이터를 제공하는 데이터셋은 여전히 부족하다. 게다가, 고품질의 대조 이미지 데이터셋을 만드는 것은 비용이 많이 들고 노동 집약적이며, 특히 조합적 생성 모델의 현재 한계를 감안할 때 더욱 그렇다. 이를 해결하기 위해, 본 논문은 충실한 대조 이미지 쌍을 생성하는 자동 파이프라인을 제안하는데, 이는 모델이 조합적 불일치에 집중하도록 가이드하는 데 중요하다.
DataA Construction: ConPair
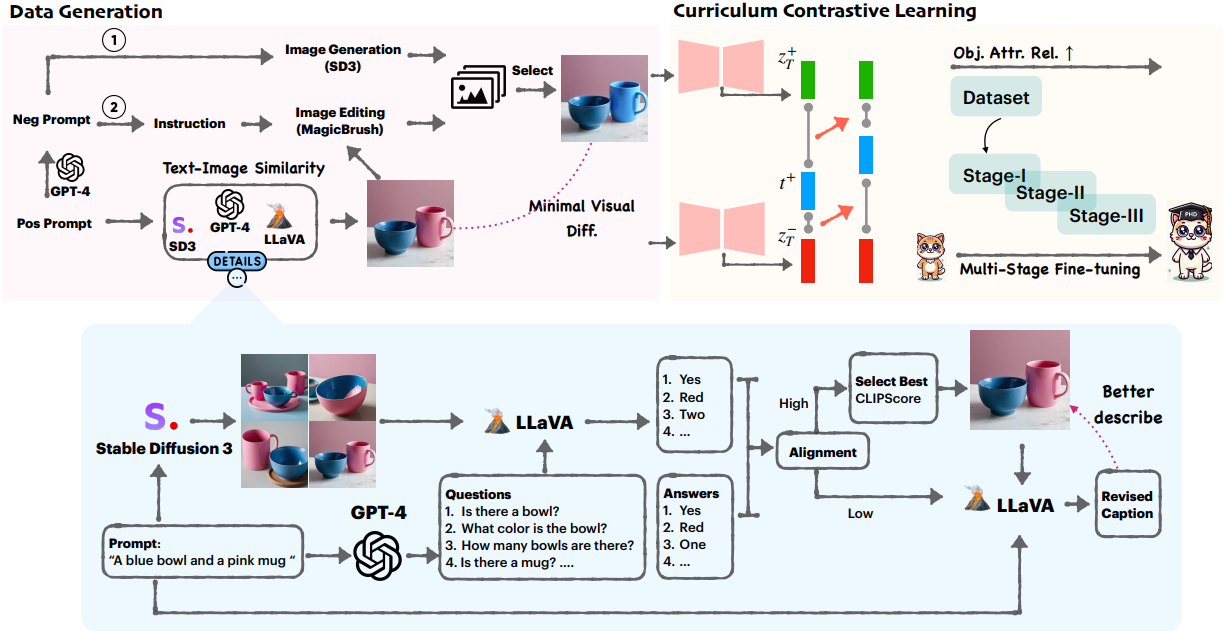
본 논문은 attribute binding과 조합적 생성을 다루기 위해 새로운 고품질 대조 데이터셋인 ConPair를 제안하였다. ConPair의 각 샘플은 positive 캡션 $t^{+}$와 연관된 한 쌍의 이미지 $(x^{+}, x^{−})$로 구성된다.
1. Generating Text Prompts
텍스트 프롬프트는 색상, 모양, 질감, 카운팅, 공간 관계, 비공간 관계, 장면, 복합성이라는 8가지 조합성의 카테고리를 포괄한다. 프롬프트를 얻기 위해 LLM의 in-context learning 기능을 활용한다. 저자들은 수작업으로 만든 시드 프롬프트를 예시와 미리 정의된 템플릿으로 제공한 다음 GPT-4에 유사한 텍스트 프롬프트를 생성하도록 요청한다.
ex. “A {color} {object} and a {color} {object}.”
저자들은 추가로 프롬프트 길이, 반복 금지 등을 지정하는 instruction을 포함시켰으며, 총 15,400개의 positive 프롬프트를 생성하였다.
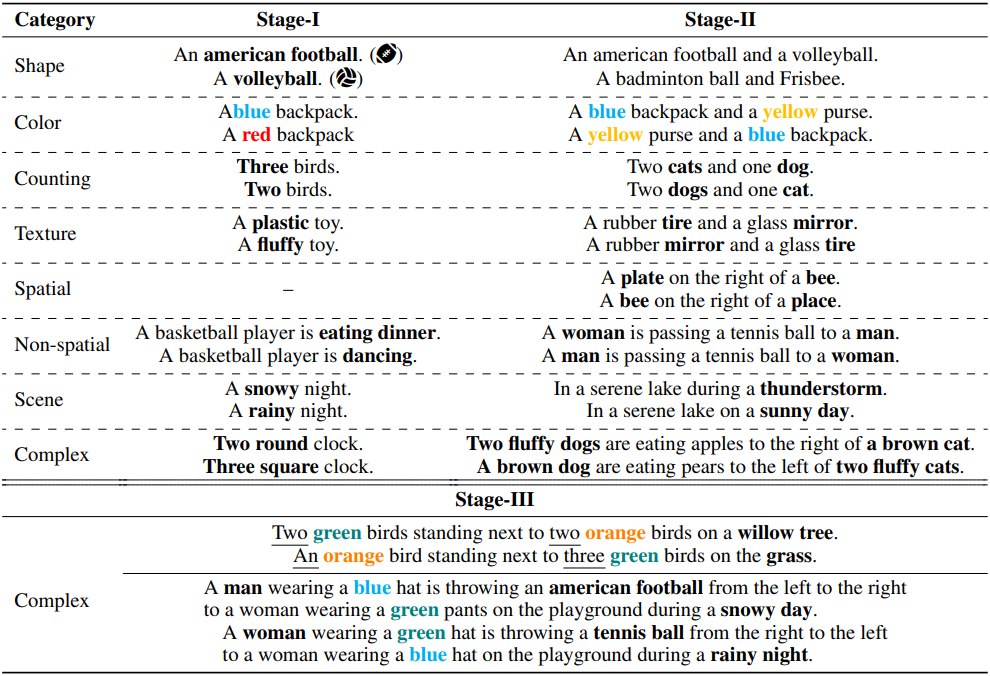
Negative 프롬프트 $t^{-}$를 생성하기 위해 GPT-4를 사용하여 1단계 데이터에 대한 물체의 지정된 속성 또는 관계를 교란시킨다. 2단계에서는 주어진 맥락에서 물체와 속성 중에 어느 옵션이 더 의미가 있는지에 따라 물체 또는 속성을 바꾼다. 복잡한 문장의 경우 GPT-4가 문장 내의 속성 또는 관계를 변경하여 대조 샘플을 구성하도록 프롬프팅한다. 아래 표는 대조 텍스트 프롬프트의 예시이다.
2. Generating Contrastive Images
최소한의 시각적 차이
핵심 아이디어는 시각적 표현에서 최소한으로 다른 대조적인 이미지를 생성하는 것이다. “최소한”이란 변경된 속성/관계를 제외하고 이미지의 다른 요소가 일관되거나 유사하게 유지된다는 것을 의미한다. 실제로 저자들은 두 가지 방법으로 negative 이미지 샘플을 얻었다.
- Diffusion model에 negative 프롬프트를 입력하여 negative 이미지를 생성한다.
- 그림 2의 왼쪽에 표시된 것처럼 MagicBrush를 사용하여 positive 이미지를 편집한다.
텍스트-이미지 정렬
ConPair의 목표는 최소한의 시각적 차이가 있음에도 불구하고 해당 negative 이미지가 positive 텍스트와 일치하지 않는 반면, positive 텍스트를 충실히 준수하는 positive 이미지를 생성하는 것이다. Diffusion model에서 생성된 이미지의 품질은 상당히 다르므로 먼저 프롬프트당 10~20개의 후보 이미지를 생성한다. 그러나 가장 충실한 이미지를 선택하는 방법은 어렵다. CLIPScore와 같은 기존의 자동 메트릭은 시각적으로 유사할 때 이미지의 충실도를 비교하는 데 항상 효과적이지 않다.
이를 해결하기 위해 LLM을 사용하여 각 텍스트 프롬프트를 여러 질문들로 분해하고 VQA 모델의 능력을 활용하여 정렬 점수에 따라 후보 이미지에 순위를 매긴다. 정답은 프롬프트에서 직접 추출할 수 있다. 직관적으로 모든 답변이 정확하거나 복잡함과 같은 특정 범주에 대한 정렬이 \(\theta_\textrm{align}\)보다 큰 경우 이미지를 성공으로 간주한다. 정렬된 이미지를 얻은 후 CLIPScore를 통해 가장 적합한 이미지를 선택한다.
저자들은 이 절차가 특히 프롬프트가 복잡해질 때 충실한 이미지를 생성하지 못한다는 것을 발견했는데, 이는 기존 생성 모델의 조합적 이해에 의해 제한되기 때문이다. 이러한 경우, 즉 모든 후보 이미지의 정렬 점수가 낮은 경우, 역정렬 전략을 도입하였다. 정렬이 낮은 이미지를 단순히 버리는 대신, VLM을 활용하여 생성된 이미지의 내용을 기반으로 텍스트 프롬프트를 동적으로 수정한다. 이를 통해 원래 설명을 보존하면서 이전의 부정확성을 수정하는 새로운 캡션을 생성하여 텍스트와 이미지 간의 정렬을 개선한다.
이미지-이미지 유사도
각 positive 샘플이 주어지면, 20개의 negative 이미지를 생성하고 해당 positive 이미지와 가장 유사성이 높은 이미지를 선택하여 positive 이미지와 negative 이미지 쌍 사이의 변화가 최소화되도록 한다. 색상과 질감의 경우, 생성보다는 이미지 편집을 사용하는데, 이는 두 속성에 대해 더 나은 성능을 제공하기 때문이다. 인간의 피드백은 모델 성능을 향상시키는 데 중요한 역할을 하기 때문에, 3명의 주석자가 데이터셋의 쌍을 무작위로 수동으로 검토하고 명백히 유효하지 않은 647개의 쌍을 필터링했다.

EvoGen: Curriculum Contrastive Fine-tuning
1. Curriculum Fine-tuning
혼합된 난이도의 데이터로 모델을 학습시키는 데 있어 일반적인 과제는 데이터가 모델을 압도하고 최적이 아닌 학습으로 이어질 수 있다는 것이다. 따라서 데이터셋을 세 단계로 나누고 간단하지만 효과적인 다단계 fine-tuning 패러다임을 도입하여 모델이 더 간단한 조합 task에서 더 복잡한 task로 점진적으로 진행될 수 있도록 한다.
Stage-I: 단일 물체
첫 번째 단계에서 샘플은 특정 속성, 특정 동작 또는 간단한 정적 장면 내의 하나의 물체로 구성된다. 해당 positive 이미지와 negative 이미지 간의 차이는 명확하고 눈에 띄도록 설계되었다.
ex. “A man is walking” vs. “A man is eating”
Stage-II: 물체 조합
두 번째 단계에서는 지정된 상호작용과 공간적 관계를 가진 두 물체를 조합한다.
ex. “A woman chases a dog” vs. “A yellow dog chases a woman.”
Stage-III: 복잡한 조합
시나리오를 더욱 복잡하게 만들기 위해 속성, 물체, 장면의 복잡한 조합을 가진 프롬프트를 제안한다. 이 단계의 데이터는 다음과 같은 특징 중 적어도 하나를 가지고 있다.
- 두 개 이상의 물체를 포함한다.
- 각 물체에 두 개 이상의 속성을 할당한다.
- 물체 간의 복잡한 관계를 포함한다.
2. Framework
궁극적으로, 본 논문의 목표는 조합적 생성을 할 수 있는 능력을 모델에 부여하는 것이다. Positive 텍스트 프롬프트 $t$, 생성된 positive 이미지 $x^{+}$, 대응되는 negative 이미지 $x^{-}$가 주어지면 프레임워크는 다음 세 가지 주요 구성 요소로 구성된다.
Diffusion Model
오토인코더는 positive 이미지와 negative 이미지를 latent space로 변환하여 각각 $z_0^{+}$와 $z_0^{-}$가 된다. Noise estimator $\epsilon_\theta$의 인코더는 각각의 feature map $z_\textrm{et}^{+}$와 $z_\textrm{et}^{-}$를 추출하는 데 사용된다.
Projection head
Contrastive loss가 적용되는 공간에 이미지 표현을 매핑하는 작은 projection head $g(\cdot)$를 적용한다. 구체적으로, hidden layer가 하나인 MLP를 사용한다.
\[\begin{equation} h_t = g(z_\textrm{et}) = W^{(2)} \sigma (W^{(1)} (z_\textrm{et})) \end{equation}\]Contrastive loss
Contrastive loss로는 널리 사용되는 InfoNCE loss의 변형을 활용한다. 이 loss는 positive 이미지와 해당 텍스트 프롬프트 간의 유사성을 최대화하고 negative 이미지와 동일한 텍스트 프롬프트 간의 유사성을 최소화하도록 설계되었다. Positive-negative 이미지 쌍에 대한 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = - \log \frac{\exp (\textrm{sim} (h_t^{+}, f(t)) / \tau)}{\exp (\textrm{sim} (h_t^{+}, f(t)) / \tau) + \exp (\textrm{sim} (h_t^{-}, f(t)) / \tau)} \end{equation}\]($\tau$는 temperature parameter, $f(\cdot)$는 CLIP 텍스트 인코더, $\textrm{sim}$은 cosine similarity)
Experiments
- 구현 디테일
- VQA 모델: LLaVA v1.5
- SD v2.1와 SD3-Medium를 fine-tuning
1. Alignment Assessment
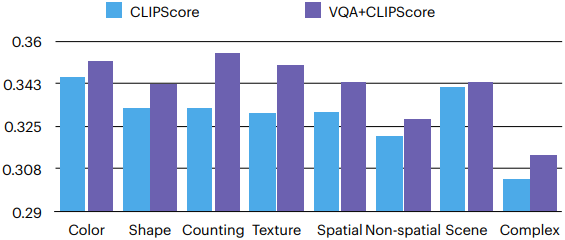
다음은 CLIP 점수를 기반으로 바로 최고의 이미지를 선택하는 것과 VQA 모델을 사용하는 본 논문의 파이프라인을 CLIP 유사도로 비교한 결과이다.
2. Benchmark Results
다음은 T2I-CompBench에서 정렬 정도를 비교한 결과이다.
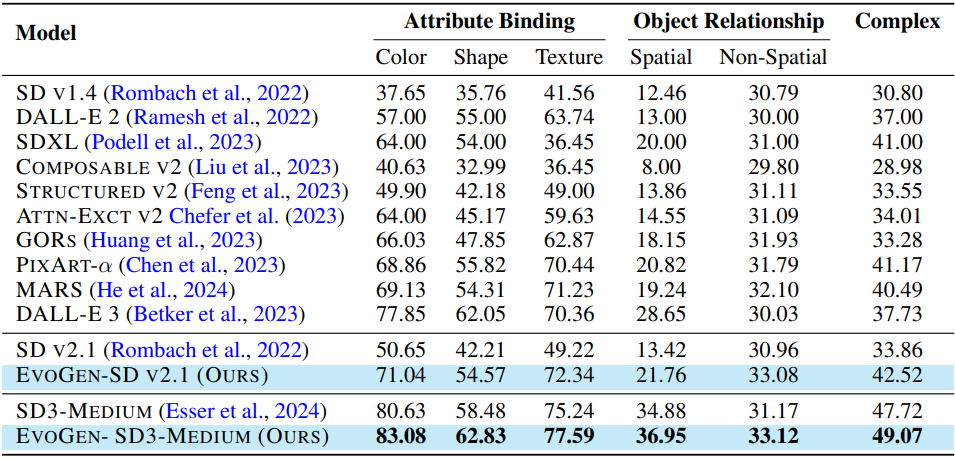
다음은 Gen-AI 벤치마크에서의 비교 결과이다.
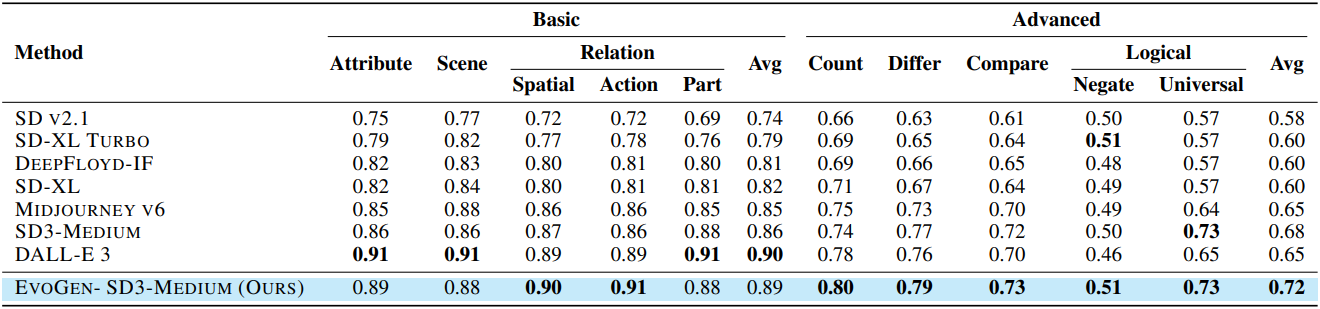
3. Ablation Study
다음은 T2I-CompBench에서의 ablation 결과이다.

4. Qualitative Evaluation
다음은 다른 SOTA text-to-image 모델들과 생성 결과를 비교한 것이다.

다음은 조합이 복잡한 정도에 따른 EvoGen의 생성 예시들이다.

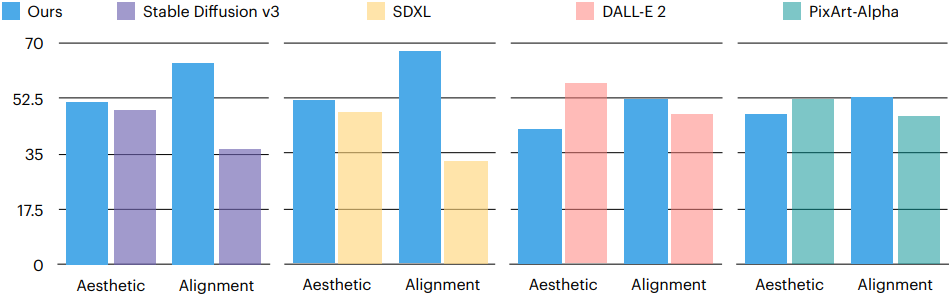
5. User Study
다음은 100개의 랜덤하게 선택된 프롬프트에 대한 user study 결과이다.