[논문리뷰] Eureka: Human-Level Reward Design via Coding Large Language Models
ICLR 2024. [Paper] [Page] [Github] [Blog]
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, Anima Anandkumar
NVIDIA | UPenn | Caltech | UT Austin
19 Oct 2023

Introduction
LLM은 로봇 task를 위한 high-level semantic planner로서 뛰어난 성과를 거두었지만, LLM을 사용하여 펜 돌리기와 같은 복잡한 low-level task를 학습할 수 있는지 여부는 여전히 미해결 문제이다. 기존의 시도들은 task 프롬프트를 구성하거나 간단한 기술만 학습하기 위해 상당한 도메인 전문 지식이 필요하여 인간 수준의 능숙성을 달성하는 데 상당한 격차가 있다.
반면, 강화 학습(RL)은 인간이 원하는 행동에 대한 학습 신호를 정확하게 체계화하고 제공하는 reward function을 신중하게 구성할 수 있다면 많은 도메인에서 인상적인 성과를 거두었다. 마찬가지로 많은 실제 RL task는 학습하기 어려운 sparse reward를 허용하므로 점진적인 학습 신호를 제공하는 reward 형성이 필요하다.
하지만, reward function은 실제로 설계하기 어려운 것으로 악명 높다. 최근 실시한 설문 조사에 따르면 RL 연구자와 실무자의 92%가 reward 설계에 시행착오를 겪었으며, 89%는 설계된 reward가 최적이 아니며 의도치 않은 행동으로 이어진다고 한다.
본 논문은 reward 설계의 중요성을 감안할 때, GPT-4와 같은 SOTA 코딩 LLM을 사용하여 보편적인 reward 프로그래밍 알고리즘을 개발할 수 있는지 묻는다. 코딩 LLM은 코드 작성, zero-shot 생성, in-context learning에서 뛰어난 능력을 가지고 있어 효과적인 프로그래밍 에이전트이다. 이상적으로, 이 reward 설계 알고리즘은 광범위한 task에 확장되는 인간 수준의 reward 생성 능력을 달성하고, 인간의 supervision 없이 시행착오 절차를 자동화하면서도 인간의 supervision과 호환되어야 한다.
본 논문은 LLM을 코딩하여 구동되는 새로운 reward 설계 알고리즘인 Evolution-driven Universal REward Kit for Agent (EUREKA)를 소개한다. 본 논문의 기여는 다음과 같다.
- Reward 설계에서 인간 수준의 성과를 달성하였다.
- 수동 reward 엔지니어링으로는 실행 불가능했던 정교한 조작 task를 해결하였다.
- RLHF에 대하여 gradient가 필요 없는 새로운 in-context learning 접근 방식을 가능하게 한다.
L2R은 LLM을 사용하여 reward를 설계하였지만, L2R과 달리 EUREKA는 task별 프롬프트, reward 템플릿, 몇 가지 간단한 예제가 전혀 필요 없으며, 형식이 없는 표현력 있는 reward 프로그램을 생성하는 능력 덕분에 L2R보다 상당히 우수한 성과를 보였다.
EUREKA의 일반성은 세 가지 핵심 알고리즘 설계 선택으로 가능해졌다.
- Environment 소스 코드를 컨텍스트로 사용: EUREKA는 코딩 LLM (GPT-4)에서 실행 가능한 reward function을 zero-shot으로 생성할 수 있다.
- Evolutionary search: LLM의 context window 내에서 가장 유망한 reward 후보들을 반복적으로 제안하고 세밀하게 다듬는다.
- Reward reflection: Policy 학습 통계를 기반으로 한 reward 품질의 텍스트 요약을 제공하여 자동화되고 타겟팅된 reward 수정을 가능하게 한다.
EUREKA가 reward 검색을 최대한 확장할 수 있도록 하기 위해, EUREKA는 IsaacGym에서 GPU 가속 분산 강화 학습을 사용하여 중간 reward를 평가한다. 이는 policy 학습 속도를 최대 1,000배까지 증가시켜, EUREKA가 더 많은 컴퓨팅 리소스를 활용할수록 자연스럽게 확장된다.
Problem Setting and Definitions
Reward 설계의 목표는 직접 최적화하기 어려울 수 있는 GT reward function에 대한 shaped reward function을 리턴하는 것이다. 이 GT reward function은 쿼리를 통해서만 접근할 수 있다.
Reward Design Problem (RDP)
RDP는 튜플 $P = \langle M, \mathcal{R}, \pi_M, F \rangle$이다.
- $M = (S, A, T)$는 state space $S$, action space $A$, transition function $T$를 갖는 월드 모델
- $\mathcal{R}$은 reward function space
- $\pi : S \rightarrow \Delta (A)$는 policy
- \(\mathcal{A}_M (\cdot) : \mathcal{R} \rightarrow \Pi\)는 MDP $(M, R)$에서 reward $R \in \mathcal{R}$을 최적화하는 $\pi$를 출력하는 학습 알고리즘
- $F : \Pi \rightarrow \mathbb{R}$은 모든 policy의 평가를 생성하는 fitness function (policy 쿼리를 통해서만 액세스할 수 있음)
RDP에서 목표는 $R \in \mathcal{R}$을 최적화하는 policy $\pi := \mathcal{A}_M (R)$이 가장 높은 fitness score $F(\pi)$를 달성하도록 reward function $R$을 출력하는 것이다.
Reward Generation Problem
RDP 내의 모든 구성 요소는 코드를 통해 명시된다. Task를 명시하는 문자열 $l$이 주어지면 reward 생성 문제의 목적은 $F(\mathcal{A}_M (R))$이 최대화되도록 reward function 코드 $R$을 출력하는 것이다.
Method
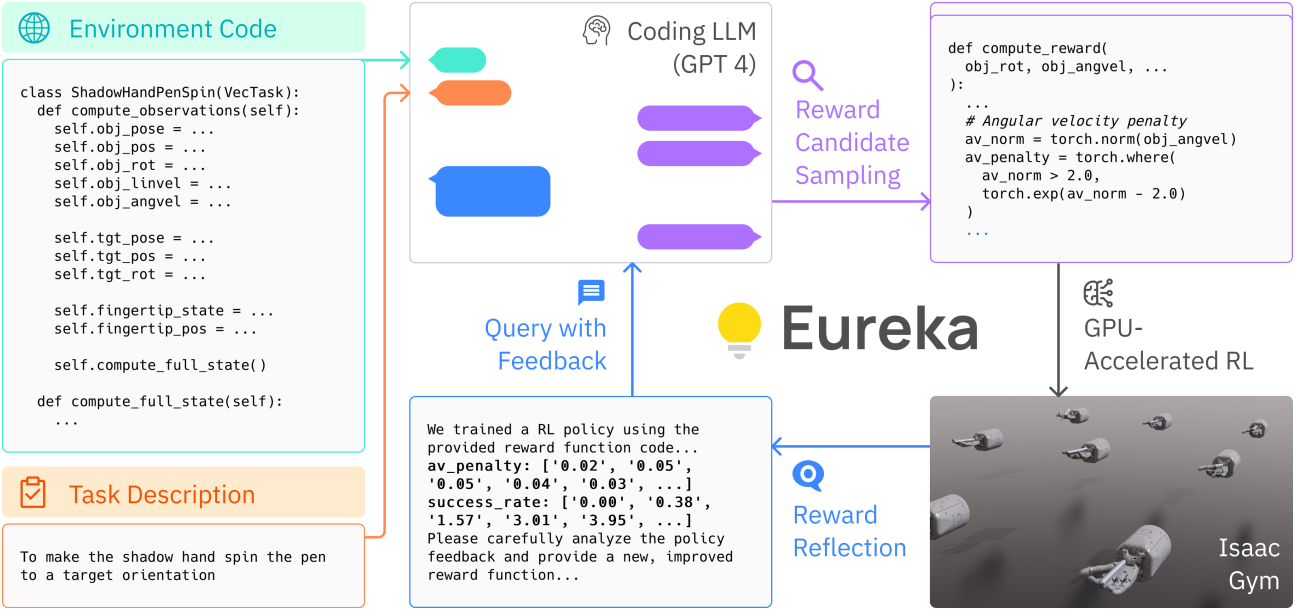

1. Environment as Context
Reward 설계에는 LLM에 environment에 대한 정보를 제공해야 한다. 저자들은 컨텍스트로 environment 소스 코드를 reward 코드 없이 직접 공급하는 것을 제안하였다. 모든 reward function이 environment의 state와 action에 대한 함수라는 점을 감안할 때, 소스 코드의 유일한 요구 사항은 이러한 state와 action을 노출한다는 것이며, 이는 충족하기 쉽다.
소스 코드를 사용할 수 없는 경우, 예를 들어 API를 통해 관련 state 정보를 제공할 수도 있다. 실제로 environment 코드가 LLM의 context window에 맞고 시뮬레이션 내부 정보가 누출되지 않도록 state와 action을 지정하는 environment 코드 스니펫만 추출하는 자동 스크립트를 사용한다.
주어진 environment를 컨텍스트로 하여, EUREKA는 코딩 LLM에 reward 설계 및 포맷팅 팁만 있는 실행 가능한 Python 코드를 직접 반환하도록 한다 (ex. reward의 개별 요소를 dictionary 출력으로 제공). 놀랍게도, 이러한 최소한의 명령만으로 EUREKA는 첫 번째 시도에서 다양한 environment에서 그럴듯해 보이는 reward를 zero-shot으로 생성할 수 있다.
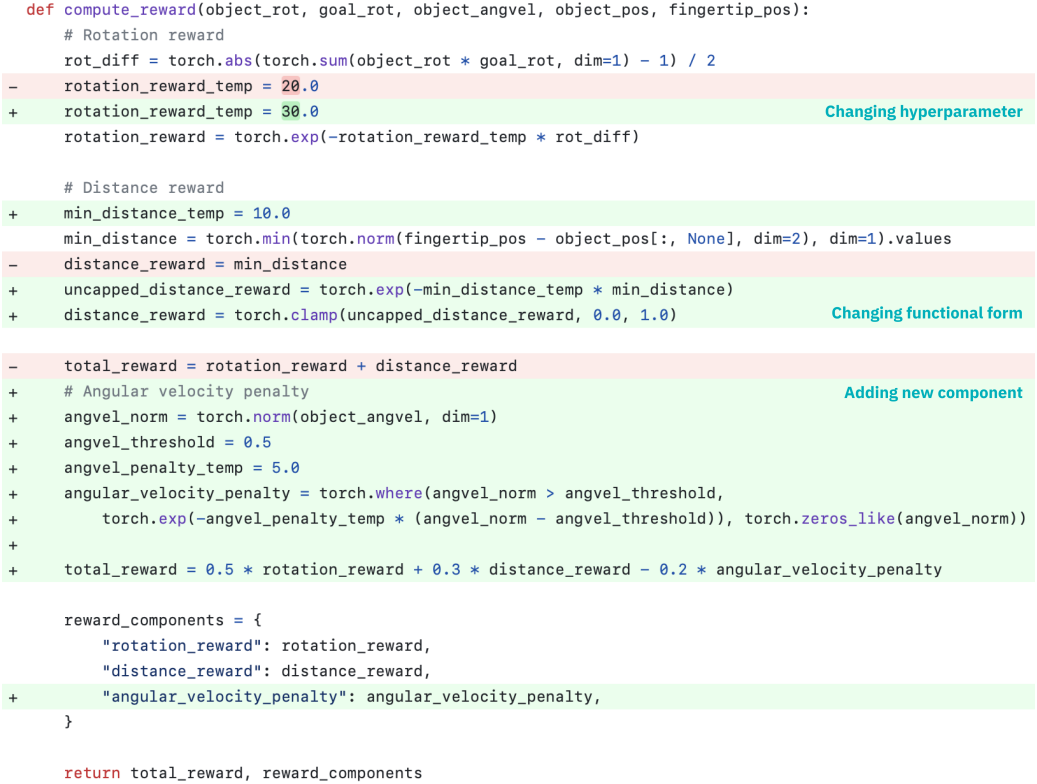
EUREKA 출력의 예시는 위 그림에 나와 있다. EUREKA는 제공된 environment 코드에서 기존 observation 변수를 능숙하게 조합하고 environment별 프롬프트 엔지니어링이나 reward 템플릿 없이도 유능한 reward 코드를 생성한다.
그러나 첫 번째 시도에서 생성된 reward는 항상 실행 가능하지 않을 수 있으며, 실행 가능하더라도 task fitness metric $F$에 대해 상당히 최적이 아닐 수 있다. Task별 서식이나 reward 디자인 힌트로 프롬프트를 개선할 수 있지만, 그렇게 하면 새로운 task에 확장되지 않고 시스템의 전반적인 일반성을 방해한다.
2. Evolutionary Search
실행 가능하지 않거나 최적이 아닌 코드에 대한 문제를 극복하기 위해, EUREKA는 각 iteration에서 LLM에서 여러 독립적인 출력을 샘플링한다. 생성이 서로 독립적이고 같은 확률분포를 가지므로 iteration에서 모든 reward function에 버그가 있을 확률은 샘플 수가 증가함에 따라 기하급수적으로 감소한다. 고려하는 모든 environment에서 적은 수의 샘플만 샘플링해도 첫 번째 iteration에서 실행 가능한 reward 코드가 하나 이상 포함되어 있다.
이전 iteration에서 실행 가능한 reward function이 주어지면, EUREKA는 in-context reward mutation을 수행하여 이전 iteration에서 가장 좋은 reward function에서 새로운 개선된 reward function을 제안한다. 구체적으로, 새로운 EUREKA iteration은 이전 iteration에서 가장 성과가 좋은 reward, reward reflection, mutation 프롬프트를 컨텍스트로 취하고 LLM에서 $K$개의 추가 reward 출력을 생성한다. 이 반복적 최적화는 지정된 반복 횟수에 도달할 때까지 계속된다. 마지막으로 더 나은 최댓값을 찾기 위해 여러 번의 랜덤 재시작을 수행한다.
모든 실험에서 EUREKA는 environment당 5개의 독립적인 실행을 수행하고 각 실행에 대해 iteration당 $K = 16$개의 샘플이 있는 5개의 iteration을 검색한다.
3. Reward Reflection
In-context reward mutation을 근거로 하기 위해 생성된 reward의 품질을 말로 표현할 수 있어야 한다. 저자들은 reward reflection을 제안했는데, 이는 policy 학습 역학을 텍스트로 요약하는 자동화된 피드백이다. 구체적으로, EUREKA reward function이 reward의 개별 요소를 출력하도록 요청받는 경우 (ex. 위 그림의 reward_components), reward reflection은 학습 내내 중간 policy 체크포인트에서 모든 reward 요소의 스칼라 값과 task fitness function을 추적한다.
이 reward reflection 절차는 구성하기 간단하지만 두 가지 이유 때문에 중요하다.
- 결과 policy에서 task fitness function $F$를 쿼리할 수 있으므로 간단한 전략은 이 점수를 reward 평가로 제공하는 것이다. $F$가 전체적인 GT 지표 역할은 하지만, reward function이 작동하는 이유에 대한 유용한 정보를 제공하지 않는다.
- Reward function이 효과적인지 여부는 특정 RL 알고리즘 선택에 따라 영향을 받으며 동일한 reward가 hyperparameter 차이가 주어진 동일한 optimizer에서도 매우 다르게 수행될 수 있다. RL 알고리즘이 개별 reward 성분을 얼마나 잘 최적화하는지에 대한 자세한 설명을 제공함으로써 EUREKA가 보다 복잡하고 타겟팅된 reward 편집을 생성할 수 있도록 한다.
Experiments
- Baseline
- L2R: reward를 생성하는 two-stage LLM-prompting 방법
- Human: 벤치마크에서 주어지는 원본 shaped reward function
- Sparse: fitness function $F$와 동일
- 학습 디테일
- policy 학습: PPO
- 5개의 독립적인 PPO 학습을 진행
- 각 PPO 학습에서 고정된 간격으로 10개의 policy 체크포인트를 샘플링하고, 그 중에서 최대 metric을 계산
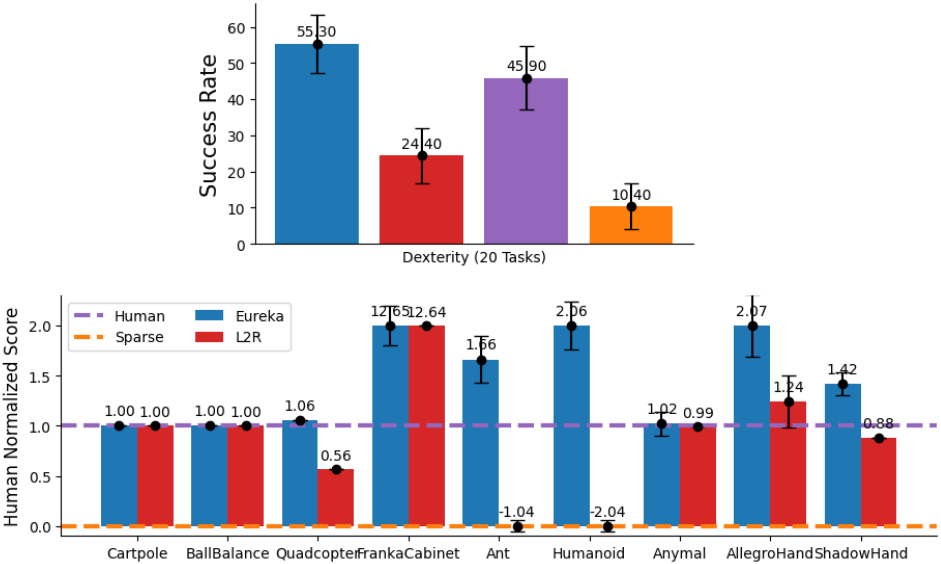
1. Results
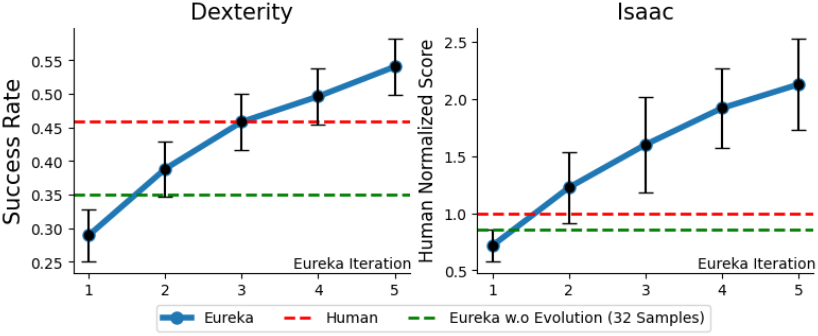
다음은 baseline들과 비교한 그래프이다. Human normalized score는 Sparse가 0, Human이 1이 되도록 정규화한 점수이다.
다음은 evolutionary search을 사용하여 더 우수한 reward를 생성하는 것을 보여주는 그래프이다.
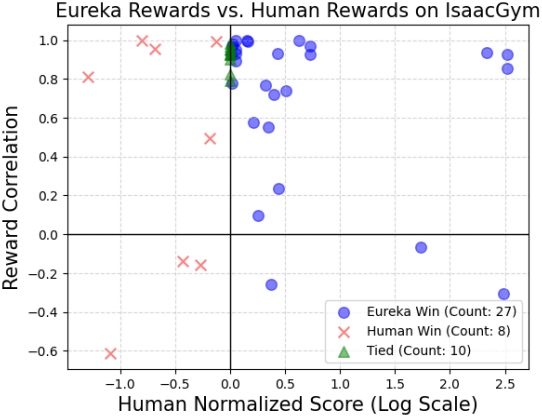
다음은 EUREKA의 reward와 인간의 reward 사이의 상관관계를 분석한 그래프이다. 두 reward 사이의 상관관계가 적으며, 특히 task가 어려워질 수록 상관관계가 더 적어진다.
다음은 curriculum learning을 EUREKA에 적용한 결과이다.
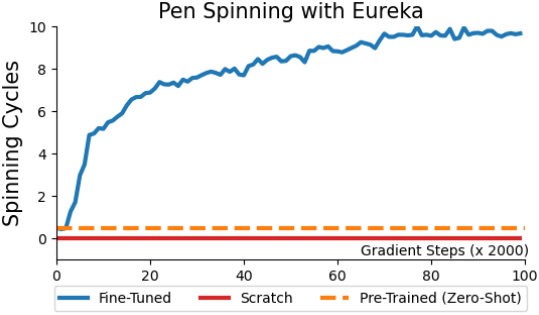
- Pre-Trained: EUREKA를 사용하여 펜을 임의의 목표 위치 및 방향으로 재배치하는 task에 대한 reward를 생성한 후, 이 reward로 학습시킨 policy
- Fine-Tuned: EUREKA reward를 통해 펜 회전 task에 Pre-Trained를 fine-tuning한 policy
- Scratch: 펜 회전 task에 EUREKA reward로 바로 학습시킨 policy
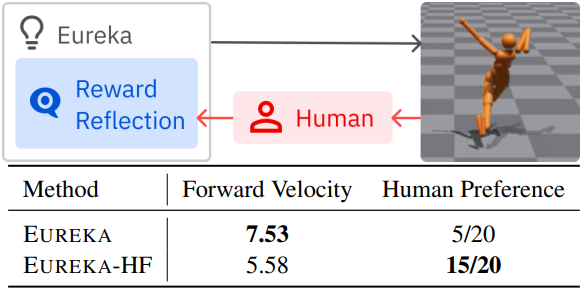
2. Eureka from Human Feedback
다음은 인간의 reward function으로 EUREKA를 초기화한 결과이다.
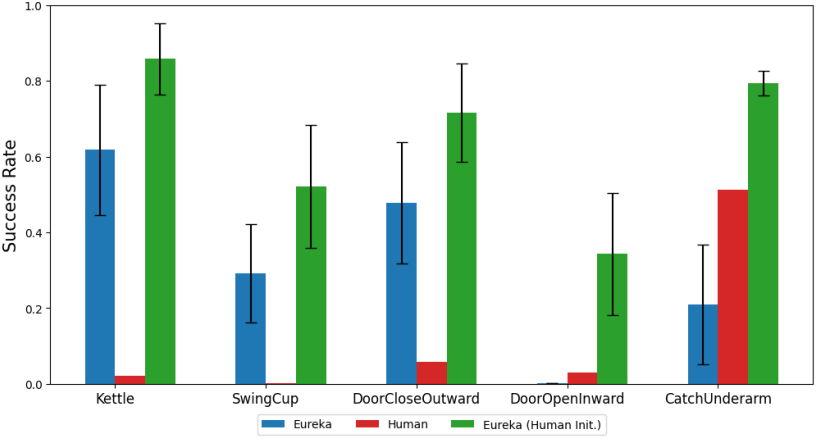
다음은 인간의 reward reflection을 통합한 결과이다.